
Graph ML News (Aug 18th)
A new blog post Designing Deep Networks to Process Other Deep Networks by Haggai Maron, Ethan Fetaya, Aviv Navon, Aviv Shamsian, Idan Achituve, and Gal Chechik applies the concepts of symmetry and invariances (common tools in Geometric DL) to the task of predicting model weights. Working in the Deep Weight Space (all parameters of neural networks), we want neural architectures to be invariant to permutations of neurons because mathematically any permutation should still encode the same function.
Two papers appeared almost simultaneously, PoseBusters by Buttenschoen et al and PoseCheck by Harris et al, providing a critical look on modern generative models (often diffusion-based) for protein-ligand docking and structure-based drug design. PoseBusters finds that generative models often have problems with physical plausibility of the generated outputs while PoseCheck finds many nonphysical features in generated molecules and poses. Huge opportunities for improving equivariant diffusion models!
The Simons Institute for the Theory of Computing held a workshop on large language models and transformers. It was not very much into graph learning but still featured a handful of talks on core topics that will be in graph ML sooner or later. Featuring talks by Chris Manning, Yejin Choi, Ilya Sutskever, Sasha Rush, and other famous researchers — the playlist with recorded talks is already on YouTube 👀
Weekend reading:
Score-based Enhanced Sampling for Protein Molecular Dynamics feat. Jian Tang - a score-based model for approximating MD calculations.
A new blog post Designing Deep Networks to Process Other Deep Networks by Haggai Maron, Ethan Fetaya, Aviv Navon, Aviv Shamsian, Idan Achituve, and Gal Chechik applies the concepts of symmetry and invariances (common tools in Geometric DL) to the task of predicting model weights. Working in the Deep Weight Space (all parameters of neural networks), we want neural architectures to be invariant to permutations of neurons because mathematically any permutation should still encode the same function.
Two papers appeared almost simultaneously, PoseBusters by Buttenschoen et al and PoseCheck by Harris et al, providing a critical look on modern generative models (often diffusion-based) for protein-ligand docking and structure-based drug design. PoseBusters finds that generative models often have problems with physical plausibility of the generated outputs while PoseCheck finds many nonphysical features in generated molecules and poses. Huge opportunities for improving equivariant diffusion models!
The Simons Institute for the Theory of Computing held a workshop on large language models and transformers. It was not very much into graph learning but still featured a handful of talks on core topics that will be in graph ML sooner or later. Featuring talks by Chris Manning, Yejin Choi, Ilya Sutskever, Sasha Rush, and other famous researchers — the playlist with recorded talks is already on YouTube 👀
Weekend reading:
Score-based Enhanced Sampling for Protein Molecular Dynamics feat. Jian Tang - a score-based model for approximating MD calculations.
NVIDIA Technical Blog
Designing Deep Networks to Process Other Deep Networks
Deep neural networks (DNNs) are the go-to model for learning functions from data, such as image classifiers or language models.
Graph ML News (Aug 25th)
The autumn edition of the Molecular ML Conference (MoML) going to take place on Nov 8th at MIT. MoML is a premier venue for bringing together graph learning and life sciences crowd including computation biology, drug discovery, computational chemistry, molecular simulation, and many more. Submit a poster until Oct 13th!
Not an official announcement, but there are rumors that the Stanford Graph Learning Seminar will return on Oct 11th as well 😉
Expect a flurry of ICLR submissions in the next weeks before the deadline, but meanwhile the weekend reading is:
UGSL: A Unified Framework for Benchmarking Graph Structure Learning by Google Research feat. Bahare Fatemi, Anton Tsitsulin and Bryan Perozzi
Simulate Time-integrated Coarse-grained Molecular Dynamics with Multi-scale Graph Networks feat. Xiang Fu, Tommi Jaakkola
Approximately Equivariant Graph Networks by Teresa Huang, Ron Levie, and Soledad Villar
Will More Expressive Graph Neural Networks do Better on Generative Tasks? (spoiler alert: nopes) feat. Pietro Liò
The Expressive Power of Graph Neural Networks: A Survey
The autumn edition of the Molecular ML Conference (MoML) going to take place on Nov 8th at MIT. MoML is a premier venue for bringing together graph learning and life sciences crowd including computation biology, drug discovery, computational chemistry, molecular simulation, and many more. Submit a poster until Oct 13th!
Not an official announcement, but there are rumors that the Stanford Graph Learning Seminar will return on Oct 11th as well 😉
Expect a flurry of ICLR submissions in the next weeks before the deadline, but meanwhile the weekend reading is:
UGSL: A Unified Framework for Benchmarking Graph Structure Learning by Google Research feat. Bahare Fatemi, Anton Tsitsulin and Bryan Perozzi
Simulate Time-integrated Coarse-grained Molecular Dynamics with Multi-scale Graph Networks feat. Xiang Fu, Tommi Jaakkola
Approximately Equivariant Graph Networks by Teresa Huang, Ron Levie, and Soledad Villar
Will More Expressive Graph Neural Networks do Better on Generative Tasks? (spoiler alert: nopes) feat. Pietro Liò
The Expressive Power of Graph Neural Networks: A Survey
MoML Conference
MoML | MIT Jameel Clinic
Molecular Machine Learning Conference | MIT Jameel Clinic
The conference brings together students, experts and leaders across areas with the goal of advancing how machine learning methods can address key scientific goals related to molecular modeling, molecular…
The conference brings together students, experts and leaders across areas with the goal of advancing how machine learning methods can address key scientific goals related to molecular modeling, molecular…
Graph ML News (Sep 2nd) - TpuGraphs Kaggle competition, EvolutionaryScale
Google launched a proper graph learning Kaggle competition ”Fast or Slow?” with a $50k prize pool. The challenge is based off a recently released TpuGraphs dataset — given a computational graph (as a DAG), predict its runtime given a certain input configuration (on node- or graph-level) and get the fastest config. Practically, it can be framed as a regression or ranking problem. TpuGraphs is pretty large: 7k nodes / 31M configuration pairs for the layout collection, and 40 nodes / 13M pairs for the tile collection. Baselines include GCN and GraphSAGE, but we can probably expect Kaggle grandmasters to come up with creative gradient boosting and decision trees techniques as well 😉 So XGBoost or GNNs? The challenge is open until Nov 17th.
A few weeks ago we found out that Meta disbanded the protein team working on ESM, ESMFold, and a handful of other projects. Now we know that the ESM team formed EvolutionaryScale and raised about $40M of funding promising new versions of ESM every year. Great news for thousands of protein projects using ESM models!
Weekend reading:
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Exploring "dark matter" protein folds using deep learning feat. Andreas Loukas, Michael Bronstein, and Bruno Correia
Google launched a proper graph learning Kaggle competition ”Fast or Slow?” with a $50k prize pool. The challenge is based off a recently released TpuGraphs dataset — given a computational graph (as a DAG), predict its runtime given a certain input configuration (on node- or graph-level) and get the fastest config. Practically, it can be framed as a regression or ranking problem. TpuGraphs is pretty large: 7k nodes / 31M configuration pairs for the layout collection, and 40 nodes / 13M pairs for the tile collection. Baselines include GCN and GraphSAGE, but we can probably expect Kaggle grandmasters to come up with creative gradient boosting and decision trees techniques as well 😉 So XGBoost or GNNs? The challenge is open until Nov 17th.
A few weeks ago we found out that Meta disbanded the protein team working on ESM, ESMFold, and a handful of other projects. Now we know that the ESM team formed EvolutionaryScale and raised about $40M of funding promising new versions of ESM every year. Great news for thousands of protein projects using ESM models!
Weekend reading:
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Exploring "dark matter" protein folds using deep learning feat. Andreas Loukas, Michael Bronstein, and Bruno Correia
Kaggle
Google - Fast or Slow? Predict AI Model Runtime
Predict how fast an AI model runs
Graph ML News (Sep 9th)
The upcoming ICLR deadline and LOG reviewing period seem to keep the community busy and reduce the amount of news content this week. We’ll compensate for that the day ICLR submissions are on OpenReview 😉
The local LoG meetup in Trento will take place on November 27th-30th (together with the main conference held online and fully remotely). There is a handful of local meetups already (if I remember correctly, other locations include UK, Germany, Canada, and a few in the US). Actually, it might be a good time for the LOG organizers to publish the confirmed ones.
The GAIN workshop on explainability and applicability of GNNs took place this week (Sept 6-8th), waiting for the recordings!
Weekend reading:
RetroBridge: Modeling Retrosynthesis with Markov Bridges by Ilia Igashov, Arne Schneuing, Marwin Segler, Michael Bronstein, Bruno Correia — a new generative framework for template-free retrosynthesis with some math traces of discrete diffusion
Where Did the Gap Go? Reassessing the Long-Range Graph Benchmark by Jan Tönshoff, Martin Ritzert, Eran Rosenbluth, Martin Grohe — turns out some hyperparameters tinkering can boost baseline performance on LRGB!
Using Multiple Vector Channels Improves E(n)-Equivariant Graph Neural Networks by Levy, Kaba, et al - a simple and inexpensive multi-channel trick to boost EGNNs
A few theory papers:
Representing Edge Flows on Graphs via Sparse Cell Complexes by Josef Hoppe, Michael T. Schaub
Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond by Shao et al.
The upcoming ICLR deadline and LOG reviewing period seem to keep the community busy and reduce the amount of news content this week. We’ll compensate for that the day ICLR submissions are on OpenReview 😉
The local LoG meetup in Trento will take place on November 27th-30th (together with the main conference held online and fully remotely). There is a handful of local meetups already (if I remember correctly, other locations include UK, Germany, Canada, and a few in the US). Actually, it might be a good time for the LOG organizers to publish the confirmed ones.
The GAIN workshop on explainability and applicability of GNNs took place this week (Sept 6-8th), waiting for the recordings!
Weekend reading:
RetroBridge: Modeling Retrosynthesis with Markov Bridges by Ilia Igashov, Arne Schneuing, Marwin Segler, Michael Bronstein, Bruno Correia — a new generative framework for template-free retrosynthesis with some math traces of discrete diffusion
Where Did the Gap Go? Reassessing the Long-Range Graph Benchmark by Jan Tönshoff, Martin Ritzert, Eran Rosenbluth, Martin Grohe — turns out some hyperparameters tinkering can boost baseline performance on LRGB!
Using Multiple Vector Channels Improves E(n)-Equivariant Graph Neural Networks by Levy, Kaba, et al - a simple and inexpensive multi-channel trick to boost EGNNs
A few theory papers:
Representing Edge Flows on Graphs via Sparse Cell Complexes by Josef Hoppe, Michael T. Schaub
Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond by Shao et al.
Graph ML News (Sep 16th) - Breakthrough Prize, OpenCatalyst cases, Illustrated Cats, EvoDiff
🏆 The Breakthrough Prize winners aka “Oscars of Science” were announced earlier this week (Ig Nobel Prizes were announced as well but that’s a story for another fun time) and they do have a nice connection to Geometric DL! The Math prize went to Simon Brendle (Columbia) for “transformative contributions to differential geometry, including sharp geometric inequalities, many results on Ricci flow and mean curvature flow and the Lawson conjecture on minimal tori in the 3-sphere.”
Ricci flows played a key role in understanding theoretical capabilities of GNNs in the seminal paper by Topping et al that received ICLR 2022 Outstanding Award and spun off more research of differential geometry and GNNs. Perfect time to jump on the Ricci flowwagon (pun intended). Do check other winners, their research is very cool as well.
🧪 The OpenCatalyst team published two case studies how the OCP demo helped in the scientific research of catalyst discovery: for the nitrogen reduction reaction (NRR) and for hydrogen fuel cells. OpenCatalyst turns into smth like AlphaFold but for materials science and chemistry.
😼 Finally, check out the Category Theory Illustrated book by Boris Marinov - this perhaps the most visual resource to understand the basics of Category Theory. As of now, 6 chapters are ready — on Sets, Categories, Monoids, Order, Logic, and Functors. Don’t forget about Cats4AI to learn more about Category Theory applied to ML and GNNs.
🧬 MSR AI4Science released EvoDiff - a massive work on the discrete diffusion generative model for conditional generation of protein sequences. EvoDiff was designed for sequences and MSAs and ships in two sizes — 38M and 640M params so it would fit on a variety of GPUs.
Some weekend reading:
Protein generation with evolutionary diffusion: sequence is all you need - introducing EvoDiff
Graph Neural Networks Use Graphs When They Shouldn't by Bechler-Speicher et al. - one more evidence for graph rewiring
Is Solving Graph Neural Tangent Kernel Equivalent to Training Graph Neural Network? by Qin et al - for all you hardcore theory lovers on the channel
🏆 The Breakthrough Prize winners aka “Oscars of Science” were announced earlier this week (Ig Nobel Prizes were announced as well but that’s a story for another fun time) and they do have a nice connection to Geometric DL! The Math prize went to Simon Brendle (Columbia) for “transformative contributions to differential geometry, including sharp geometric inequalities, many results on Ricci flow and mean curvature flow and the Lawson conjecture on minimal tori in the 3-sphere.”
Ricci flows played a key role in understanding theoretical capabilities of GNNs in the seminal paper by Topping et al that received ICLR 2022 Outstanding Award and spun off more research of differential geometry and GNNs. Perfect time to jump on the Ricci flowwagon (pun intended). Do check other winners, their research is very cool as well.
🧪 The OpenCatalyst team published two case studies how the OCP demo helped in the scientific research of catalyst discovery: for the nitrogen reduction reaction (NRR) and for hydrogen fuel cells. OpenCatalyst turns into smth like AlphaFold but for materials science and chemistry.
😼 Finally, check out the Category Theory Illustrated book by Boris Marinov - this perhaps the most visual resource to understand the basics of Category Theory. As of now, 6 chapters are ready — on Sets, Categories, Monoids, Order, Logic, and Functors. Don’t forget about Cats4AI to learn more about Category Theory applied to ML and GNNs.
🧬 MSR AI4Science released EvoDiff - a massive work on the discrete diffusion generative model for conditional generation of protein sequences. EvoDiff was designed for sequences and MSAs and ships in two sizes — 38M and 640M params so it would fit on a variety of GPUs.
Some weekend reading:
Protein generation with evolutionary diffusion: sequence is all you need - introducing EvoDiff
Graph Neural Networks Use Graphs When They Shouldn't by Bechler-Speicher et al. - one more evidence for graph rewiring
Is Solving Graph Neural Tangent Kernel Equivalent to Training Graph Neural Network? by Qin et al - for all you hardcore theory lovers on the channel
GraphML News (Sep 23rd) - Stanford Graph Learning Workshop, AlphaMisuse, PEFT for ESM
NeurIPS decisions for both tracks are out - congrats to those who made it in and encouragements to those who did not, hopefully the next iteration would get better! Our team got 2 papers accepted including A*Net - a scalable knowledge graph reasoning method that can be used, eg, for improving factual correctness of language models (demo is on github). Next weeks we can expect more accepted papers to be publicly available, so we’ll keep you updated. Don’t forget about the NeurIPS graph workshops many of which extended their deadlines to early October!
Stanford Graph Learning Workshop was officially announced and will take place physically on Oct 24th. This time the organizers published a call for contributed talks from the academic and industry tracks. I will try to be there, ping me if you want to chat.
Google DeepMind announced AlphaMisuse, a model for categorizing “missense” genetic mutations based on AlphaFold. AlphaMisuse predicted labels for ~60M possible missense mutations whereas humans covered at most ~700K. Unfortunately, the authors say the model weights won’t be released so let’s hope for re-implementations in open source ecosystems.
If you have been living under the rock, parameter-efficient fine-tuning (PEFT) techniques took the world of LLMs by the storm and it’s pretty much everywhere now. Amelie Schreiber wrote a great blogpost on applying LoRA to the ESM-2 family of protein LMs so even the beefiest of ESMs (still pretty small compared to Llama’s though) can be now fine-tuned on commodity GPUs. To learn more about PEFT, check out this fresh survey by Vladislav Lialin et al.
Some freshly accepted NeurIPS papers for the weekend reading:
Implicit Transfer Operator Learning: Multiple Time-Resolution Surrogates for Molecular Dynamics
SE(3) Equivariant Augmented Coupling Flows
When Do Graph Neural Networks Help with Node Classification: Investigating the Homophily Principle on Node Distinguishability
Fine-grained Expressivity of Graph Neural Networks
Next week ICLR’24 submissions become available, so oh boy we’ll have the weekend reading 👀
NeurIPS decisions for both tracks are out - congrats to those who made it in and encouragements to those who did not, hopefully the next iteration would get better! Our team got 2 papers accepted including A*Net - a scalable knowledge graph reasoning method that can be used, eg, for improving factual correctness of language models (demo is on github). Next weeks we can expect more accepted papers to be publicly available, so we’ll keep you updated. Don’t forget about the NeurIPS graph workshops many of which extended their deadlines to early October!
Stanford Graph Learning Workshop was officially announced and will take place physically on Oct 24th. This time the organizers published a call for contributed talks from the academic and industry tracks. I will try to be there, ping me if you want to chat.
Google DeepMind announced AlphaMisuse, a model for categorizing “missense” genetic mutations based on AlphaFold. AlphaMisuse predicted labels for ~60M possible missense mutations whereas humans covered at most ~700K. Unfortunately, the authors say the model weights won’t be released so let’s hope for re-implementations in open source ecosystems.
If you have been living under the rock, parameter-efficient fine-tuning (PEFT) techniques took the world of LLMs by the storm and it’s pretty much everywhere now. Amelie Schreiber wrote a great blogpost on applying LoRA to the ESM-2 family of protein LMs so even the beefiest of ESMs (still pretty small compared to Llama’s though) can be now fine-tuned on commodity GPUs. To learn more about PEFT, check out this fresh survey by Vladislav Lialin et al.
Some freshly accepted NeurIPS papers for the weekend reading:
Implicit Transfer Operator Learning: Multiple Time-Resolution Surrogates for Molecular Dynamics
SE(3) Equivariant Augmented Coupling Flows
When Do Graph Neural Networks Help with Node Classification: Investigating the Homophily Principle on Node Distinguishability
Fine-grained Expressivity of Graph Neural Networks
Next week ICLR’24 submissions become available, so oh boy we’ll have the weekend reading 👀
GraphML News (Oct 3rd)
Well, no big news from the past weekend since ICLR’24 submissions are still not available after the main deadline 🙁 At least we can read the abstracts of all accepted NeurIPS’23 papers here. A brief search indicates that the amount of papers with “diffusion” (192) is as large as “graph” papers (202).
Meanwhile, VantAI launches a monthly lecture series on Generative AI in Drug Discovery hosted by Michael Bronstein and Bruno Correia. The inaugural meeting will be held this Friday, October 6, at 11 am ET / 5 pm CET. Free to join using the links provided.
A few fresh software releases: PyDGN got updated to 1.5, and industry-grade GraphStorm released v0.2 featuring better support for distributed training on GPUs.
Paper reading:
Unified Embedding: Battle-Tested Feature Representations for Web-Scale ML Systems (NeurIPS’23) by Google on featurization strategies for ML in search, ads, and recsys.
Limits, approximation and size transferability for GNNs on sparse graphs via graphops (NeurIPS’23) by Thien Le and Stefanie Jegelka on size generalization in GNNs.
Sheaf Hypergraph Networks (NeurIPS’23) by Iulia Duta et al (math alert 🤯)
On the Power of the Weisfeiler-Leman Test for Graph Motif Parameters by Matthias Lanzinger and Pablo Barceló
Well, no big news from the past weekend since ICLR’24 submissions are still not available after the main deadline 🙁 At least we can read the abstracts of all accepted NeurIPS’23 papers here. A brief search indicates that the amount of papers with “diffusion” (192) is as large as “graph” papers (202).
Meanwhile, VantAI launches a monthly lecture series on Generative AI in Drug Discovery hosted by Michael Bronstein and Bruno Correia. The inaugural meeting will be held this Friday, October 6, at 11 am ET / 5 pm CET. Free to join using the links provided.
A few fresh software releases: PyDGN got updated to 1.5, and industry-grade GraphStorm released v0.2 featuring better support for distributed training on GPUs.
Paper reading:
Unified Embedding: Battle-Tested Feature Representations for Web-Scale ML Systems (NeurIPS’23) by Google on featurization strategies for ML in search, ads, and recsys.
Limits, approximation and size transferability for GNNs on sparse graphs via graphops (NeurIPS’23) by Thien Le and Stefanie Jegelka on size generalization in GNNs.
Sheaf Hypergraph Networks (NeurIPS’23) by Iulia Duta et al (math alert 🤯)
On the Power of the Weisfeiler-Leman Test for Graph Motif Parameters by Matthias Lanzinger and Pablo Barceló
Graph ML News (Oct 7th) - FoldFlow, Iambic round, Google’s Graph Mining Library
Although ICLR submissions are still not available, October brings some other news!
🌊 Flow Matching is the generative modeling framework of 2023 (and you’ll hear it everywhere in 2024) that is taking the Geometric DL world step by step. While diffusion models can only generate from a Gaussian prior, Flow Matching generative models can take any prior distribution. The seminal paper by Alex Tong et al made huge advancements in the Continuous Normalizing Flows, conditional flow matching, and optimal transport for flow matching (here is the LoGG reading group talk), and we’ll see a good bunch of generative models for molecules and proteins based on this framework. A few days ago, the DreamFold team from Mila led by Joey Bose and Tara Akhound-Sadegh together with Michael Bronstein (and with Alex Tong) released FoldFlow, an SE(3) equivariant flow matching model for protein backbone generation. Perhaps the coolest result is in the attached figure - whereas AlphaFold 2 can only discover one energy state of the protein structure, FoldFlow captures all modes of the distribution which increases diversity of generated samples.
Hope to hear more from folks at DreamFold in future!
🧬 Iambic Therapeutics (former Entos) raised $100M Series B to advance their drug discovery platform. Iambic identified 2 drug candidates (apparently preliminary trials look ok) and is active in the academic environment, ie, the team created OrbNet and recent NeuralPlexer, an equivariant diffusion model for protein-ligand docking.
⛏️ Google open-sourced the Graph Mining library in C++ with scalable and parallel graph clustering algorithms including the recent ParHAC from NeurIPS’22 that processed a 154 billion edges graph in 3 hours. No graph is too large for Google.
🍧 Floris Geerts (University of Antwerp) gave a Richard M. Karp distinguished lecture at the Simons institute on “The Power of Graph Learning” focusing on theoretical aspects of GNNs expressiveness, and explaining the idea of Graph Embedding Language (GEL) that bridges a gap between GNNs and databases. While the GEL paper is in the works, there is a nice slide deck about it.
Weekend reading:
SE(3)-Stochastic Flow Matching for Protein Backbone Generation - FoldFlow
Equivariant flow matching by Leon Klein, Andreas Krämer, Frank Noé - to complete the equivariant flow matching picture
SaProt: Protein Language Modeling with Structure-aware Vocabulary by Su et al - pretty massive gains over ESM-2 in the protein structure awareness, 650M params trained on 64 A100 for 3 months. The code is already available on GitHub
Cooperative Graph Neural Networks by Ben Finkelshtein et al - a new look at the message passing procedure where nodes can “decide” whether to propagate neighbors messages, send own messages, or remain silent.
Although ICLR submissions are still not available, October brings some other news!
🌊 Flow Matching is the generative modeling framework of 2023 (and you’ll hear it everywhere in 2024) that is taking the Geometric DL world step by step. While diffusion models can only generate from a Gaussian prior, Flow Matching generative models can take any prior distribution. The seminal paper by Alex Tong et al made huge advancements in the Continuous Normalizing Flows, conditional flow matching, and optimal transport for flow matching (here is the LoGG reading group talk), and we’ll see a good bunch of generative models for molecules and proteins based on this framework. A few days ago, the DreamFold team from Mila led by Joey Bose and Tara Akhound-Sadegh together with Michael Bronstein (and with Alex Tong) released FoldFlow, an SE(3) equivariant flow matching model for protein backbone generation. Perhaps the coolest result is in the attached figure - whereas AlphaFold 2 can only discover one energy state of the protein structure, FoldFlow captures all modes of the distribution which increases diversity of generated samples.
Hope to hear more from folks at DreamFold in future!
🧬 Iambic Therapeutics (former Entos) raised $100M Series B to advance their drug discovery platform. Iambic identified 2 drug candidates (apparently preliminary trials look ok) and is active in the academic environment, ie, the team created OrbNet and recent NeuralPlexer, an equivariant diffusion model for protein-ligand docking.
⛏️ Google open-sourced the Graph Mining library in C++ with scalable and parallel graph clustering algorithms including the recent ParHAC from NeurIPS’22 that processed a 154 billion edges graph in 3 hours. No graph is too large for Google.
🍧 Floris Geerts (University of Antwerp) gave a Richard M. Karp distinguished lecture at the Simons institute on “The Power of Graph Learning” focusing on theoretical aspects of GNNs expressiveness, and explaining the idea of Graph Embedding Language (GEL) that bridges a gap between GNNs and databases. While the GEL paper is in the works, there is a nice slide deck about it.
Weekend reading:
SE(3)-Stochastic Flow Matching for Protein Backbone Generation - FoldFlow
Equivariant flow matching by Leon Klein, Andreas Krämer, Frank Noé - to complete the equivariant flow matching picture
SaProt: Protein Language Modeling with Structure-aware Vocabulary by Su et al - pretty massive gains over ESM-2 in the protein structure awareness, 650M params trained on 64 A100 for 3 months. The code is already available on GitHub
Cooperative Graph Neural Networks by Ben Finkelshtein et al - a new look at the message passing procedure where nodes can “decide” whether to propagate neighbors messages, send own messages, or remain silent.
{kind=link}
Fresh ICLR’24 Submissions
OpenReview has finally opened all submissions on OpenReview! Here is a fresh batch of papers I found interesting:
Diffusion-based generation:
Plug-And-Play Controllable Graph Generation With Diffusion Models
Sparse Training of Discrete Diffusion Models for Graph Generation
GraphMaker: Can Diffusion Models Generate Large Attributed Graphs?
Graph Generation with Destination-Predicting Diffusion Mixture
DIFUSCO-LNS: Diffusion-Guided Large Neighbourhood Search for Integer Linear Programming
Graph Generation with K2 Trees
Proteins:
EquiPocket: an E(3)-Equivariant Geometric Graph Neural Network for Ligand Binding Site Prediction
DiffDock-Pocket: Diffusion for Pocket-Level Docking with Sidechain Flexibility
DiffSim: Aligning Diffusion Model and Molecular Dynamics Simulation for Accurate Blind Docking
Rigid Protein-Protein Docking via Equivariant Elliptic-Paraboloid Interface Prediction
Crystals and Material Generation:
Space Group Constrained Crystal Generation
Scalable Diffusion for Materials Generation
Hierarchical GFlownet for Crystal Structure Generation
MOFDiff: Coarse-grained Diffusion for Metal-Organic Framework Design
Equivariant nets:
Generalizing Denoising to Non-Equilibrium Structures Improves Equivariant Force Fields
Orbit-Equivariant Graph Neural Networks
E(3) Equivariant Scalar Interaction Network
Rethinking the Benefits of Steerable Features in 3D Equivariant Graph Neural Networks
Clifford Group Equivariant Simplicial Message Passing Networks
Theory, Weisfeiler & Leman go:
G2N2: Weisfeiler and Lehman go grammatical
Attacking Graph Neural Networks with Bit Flips: Weisfeiler and Lehman Go Indifferent
Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness
How Graph Neural Networks Learn: Lessons from Training Dynamics in Function Space
New GNN architectures:
How Powerful are Graph Neural Networks with Random Weights?
Non-backtracking Graph Neural Networks
Neural Priority Queues for Graph Neural Networks (GNNs)
Graph Transformers: too many, too similar 😅
LLMs + Graphs: tons, I'd better stay away 🫠
OpenReview has finally opened all submissions on OpenReview! Here is a fresh batch of papers I found interesting:
Diffusion-based generation:
Plug-And-Play Controllable Graph Generation With Diffusion Models
Sparse Training of Discrete Diffusion Models for Graph Generation
GraphMaker: Can Diffusion Models Generate Large Attributed Graphs?
Graph Generation with Destination-Predicting Diffusion Mixture
DIFUSCO-LNS: Diffusion-Guided Large Neighbourhood Search for Integer Linear Programming
Graph Generation with K2 Trees
Proteins:
EquiPocket: an E(3)-Equivariant Geometric Graph Neural Network for Ligand Binding Site Prediction
DiffDock-Pocket: Diffusion for Pocket-Level Docking with Sidechain Flexibility
DiffSim: Aligning Diffusion Model and Molecular Dynamics Simulation for Accurate Blind Docking
Rigid Protein-Protein Docking via Equivariant Elliptic-Paraboloid Interface Prediction
Crystals and Material Generation:
Space Group Constrained Crystal Generation
Scalable Diffusion for Materials Generation
Hierarchical GFlownet for Crystal Structure Generation
MOFDiff: Coarse-grained Diffusion for Metal-Organic Framework Design
Equivariant nets:
Generalizing Denoising to Non-Equilibrium Structures Improves Equivariant Force Fields
Orbit-Equivariant Graph Neural Networks
E(3) Equivariant Scalar Interaction Network
Rethinking the Benefits of Steerable Features in 3D Equivariant Graph Neural Networks
Clifford Group Equivariant Simplicial Message Passing Networks
Theory, Weisfeiler & Leman go:
G2N2: Weisfeiler and Lehman go grammatical
Attacking Graph Neural Networks with Bit Flips: Weisfeiler and Lehman Go Indifferent
Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness
How Graph Neural Networks Learn: Lessons from Training Dynamics in Function Space
New GNN architectures:
How Powerful are Graph Neural Networks with Random Weights?
Non-backtracking Graph Neural Networks
Neural Priority Queues for Graph Neural Networks (GNNs)
Graph Transformers: too many, too similar 😅
LLMs + Graphs: tons, I'd better stay away 🫠
GraphML News (Oct 14th) - ICLR’24 submissions, more Flow Matching, PyG 2.4
📚 ICLR’24 has finally opened all submissions on OpenReview - we will have the weekend reading! Apart from the papers already available on arxiv and/or rejected from past conferences, one could find new, fresh, and anonymous hidden gems (sometimes even with the implementation in the supplementary). See the first batch of new Graph & Geometric DL papers that haven’t yet appeared on Twitter in the previous post.
🦦 Flow Matching papers continue to conquer the generative world - this week MIT and Microsoft Research released two new works: FlowSite from Hannes Stärk et al on protein-ligand docking and FrameFlow from Jason Yim et al on protein backbone generation. Both models significantly improve over the previous generation of diffusion-based approaches.
⌨️ PyG 2.4 was released this week. The newest version brings the support of
🪐 Polymathic is a new initiative to bring foundation models into the world of complex scientific problems. The announcement release features models for numbers encoding (so LLMs can better work with floats), models for learning physics and dynamical systems, and AstroCLIP for matching galaxy spectra with their images.
Weekend reading:
See the previous post with ICLR’24 submissions
📚 ICLR’24 has finally opened all submissions on OpenReview - we will have the weekend reading! Apart from the papers already available on arxiv and/or rejected from past conferences, one could find new, fresh, and anonymous hidden gems (sometimes even with the implementation in the supplementary). See the first batch of new Graph & Geometric DL papers that haven’t yet appeared on Twitter in the previous post.
🦦 Flow Matching papers continue to conquer the generative world - this week MIT and Microsoft Research released two new works: FlowSite from Hannes Stärk et al on protein-ligand docking and FrameFlow from Jason Yim et al on protein backbone generation. Both models significantly improve over the previous generation of diffusion-based approaches.
⌨️ PyG 2.4 was released this week. The newest version brings the support of
torch.compile() to GNNs - compiled GNNs yield up to 300% speed boosts. Previously, compilation of GNNs wouldn’t be that useful on inductive tasks when the graph or a batch of graphs have different shapes, but PyTorch 2.1 makes dynamic shaping more friendly. JAX aficionados might look at this with a humble smile, but guys, the torch community is catching up.🪐 Polymathic is a new initiative to bring foundation models into the world of complex scientific problems. The announcement release features models for numbers encoding (so LLMs can better work with floats), models for learning physics and dynamical systems, and AstroCLIP for matching galaxy spectra with their images.
Weekend reading:
See the previous post with ICLR’24 submissions
GraphML News (Oct 21st) - Upcoming events, internships, the book on equivariance
Get ready for several upcoming graph learning events! 1️⃣ Stanford Graph Learning workshop will take place on Tuesday, Oct 24th, and its program is now available. I will give a talk introducing our new project (more on that soon) and present a poster - let’s meet if you are there 👋. 2️⃣ On Nov 8th, Molecular ML (MoML) will take place at MIT and its program with talks and posters is now available as well. Seems like the majority of posters at MoML is dedicated to generative models from three families: diffusion, flow matching, and GFlowNets.
A few LoG meetups have been announced as well. 3️⃣ LoG Madrid is planned for Nov 27-29th and accepts submissions until Nov 3rd. The venue is URJC Madrid-Arguelles Campus. 4️⃣ LoG meetup at Mila in Montreal will happen on Dec 1st.
🎓 New internship opportunities were announced from Google Research and from Google DeepMind (those are still two different entities, don’t be confused). The sooner you apply - the better.
📚 Finally, a new 524-page book on Equivariant and Coordinate Independent Convolutional Networks by Maurice Weiler , Patrick Forré , Erik Verlinde , and Max Welling is a monumental work on baking symmetries and equivariances into convnets. If you are fascinated by this topic, have a look at the course on Group Equivariant DL by Erik Bekkers - after a year its importance has only been growing for modern geometric DL models.
Weekend reading: still digesting ICLR submissions
Get ready for several upcoming graph learning events! 1️⃣ Stanford Graph Learning workshop will take place on Tuesday, Oct 24th, and its program is now available. I will give a talk introducing our new project (more on that soon) and present a poster - let’s meet if you are there 👋. 2️⃣ On Nov 8th, Molecular ML (MoML) will take place at MIT and its program with talks and posters is now available as well. Seems like the majority of posters at MoML is dedicated to generative models from three families: diffusion, flow matching, and GFlowNets.
A few LoG meetups have been announced as well. 3️⃣ LoG Madrid is planned for Nov 27-29th and accepts submissions until Nov 3rd. The venue is URJC Madrid-Arguelles Campus. 4️⃣ LoG meetup at Mila in Montreal will happen on Dec 1st.
🎓 New internship opportunities were announced from Google Research and from Google DeepMind (those are still two different entities, don’t be confused). The sooner you apply - the better.
📚 Finally, a new 524-page book on Equivariant and Coordinate Independent Convolutional Networks by Maurice Weiler , Patrick Forré , Erik Verlinde , and Max Welling is a monumental work on baking symmetries and equivariances into convnets. If you are fascinated by this topic, have a look at the course on Group Equivariant DL by Erik Bekkers - after a year its importance has only been growing for modern geometric DL models.
Weekend reading: still digesting ICLR submissions
ULTRA: Towards Foundation Models for Knowledge Graph Reasoning
by Mikhail Galkin, Xinyu Yuan, Hesham Mostafa, Jian Tang, and Zhaocheng Zhu
arxiv: https://arxiv.org/abs/2310.04562
code: https://github.com/DeepGraphLearning/ULTRA
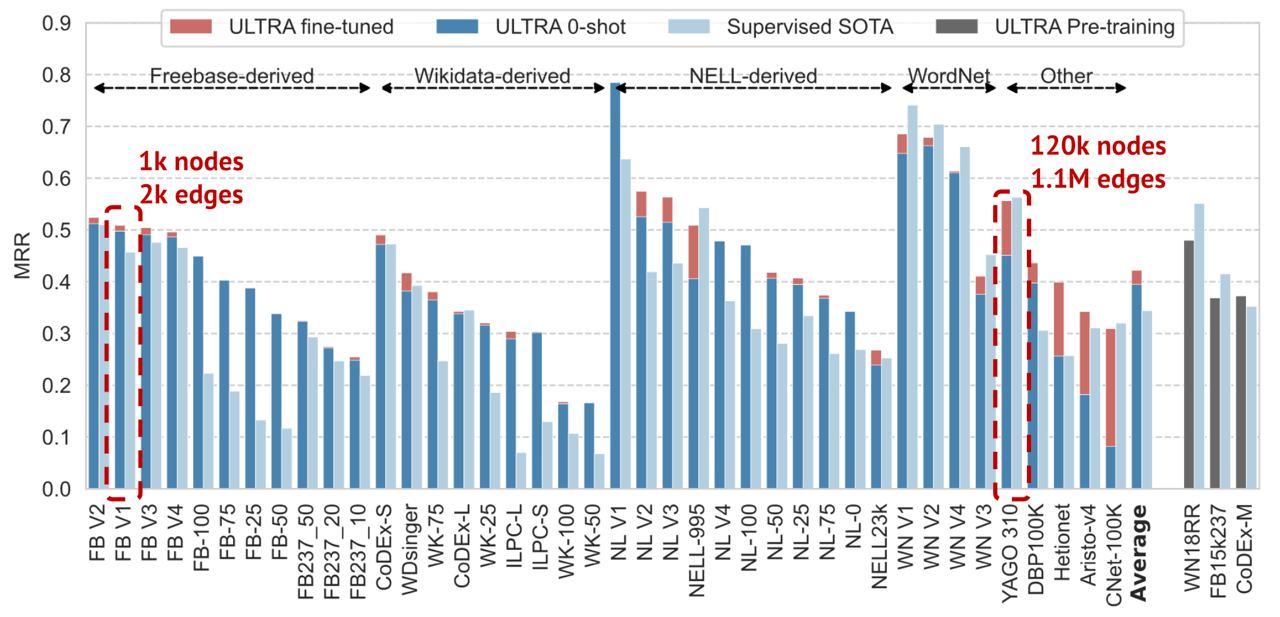
It’s time to announce our latest work - ULTRA - a pre-trained foundation model for knowledge graph reasoning that works on any graph and outperforms supervised SOTA models on 50+ graphs.
For years, ML on knowledge graphs implied training one model per dataset and those were fixed to a particular set of entities and relations, hence not transferable at all. The key problem: different, often non-overlapping sets of entities and relations (eg, Freebase and Wikidata).
Since graph learning is a question of symmetries and invariances, we pose a question: what is the transferable invariance in seemingly different graphs even with different relations? We find the invariance in relation interactions in the graph of relations!
Even though relations are different, their interactions remain the same - and we model 4 such interactions (edge types) in the graph of relations. Learning those means we can have a single trained model working on any multi-relational graph.
Practically, ULTRA consists of 2 GNNs with the labeling trick (Neural Bellman-Ford nets in our case): given a query
We pre-train ULTRA on 3 standard KGs (from Freebase, Wordnet, and Wikidata) and evaluate on 50+ other graphs of various sizes. A single ULTRA outperforms supervised SOTA even in the 0-shot regime never seeing those graphs before. Fine-tuning bumps the performance by additional 10%!
Cool fact: it can be shown that ULTRA is a distributionally double-equivariant (to nodes and relations permutations) model - thanks to Bruno Ribeiro for noticing that! Double equivariance is a theoretical framework for inductive reasoning and (probably) is a necessary condition for designing inductive neural nets (arxiv).
We publish the code in the latest PyG 2.4 and PyTorch 2.1 and also release the pre-trained checkpoints so you can run them on your own graphs right away!
by Mikhail Galkin, Xinyu Yuan, Hesham Mostafa, Jian Tang, and Zhaocheng Zhu
arxiv: https://arxiv.org/abs/2310.04562
code: https://github.com/DeepGraphLearning/ULTRA
It’s time to announce our latest work - ULTRA - a pre-trained foundation model for knowledge graph reasoning that works on any graph and outperforms supervised SOTA models on 50+ graphs.
For years, ML on knowledge graphs implied training one model per dataset and those were fixed to a particular set of entities and relations, hence not transferable at all. The key problem: different, often non-overlapping sets of entities and relations (eg, Freebase and Wikidata).
Since graph learning is a question of symmetries and invariances, we pose a question: what is the transferable invariance in seemingly different graphs even with different relations? We find the invariance in relation interactions in the graph of relations!
Even though relations are different, their interactions remain the same - and we model 4 such interactions (edge types) in the graph of relations. Learning those means we can have a single trained model working on any multi-relational graph.
Practically, ULTRA consists of 2 GNNs with the labeling trick (Neural Bellman-Ford nets in our case): given a query
(h,r,?), one produces relational features conditioned on the query relation and interaction graph, the 2nd one uses those for inductive reasoning on the main graphWe pre-train ULTRA on 3 standard KGs (from Freebase, Wordnet, and Wikidata) and evaluate on 50+ other graphs of various sizes. A single ULTRA outperforms supervised SOTA even in the 0-shot regime never seeing those graphs before. Fine-tuning bumps the performance by additional 10%!
Cool fact: it can be shown that ULTRA is a distributionally double-equivariant (to nodes and relations permutations) model - thanks to Bruno Ribeiro for noticing that! Double equivariance is a theoretical framework for inductive reasoning and (probably) is a necessary condition for designing inductive neural nets (arxiv).
We publish the code in the latest PyG 2.4 and PyTorch 2.1 and also release the pre-trained checkpoints so you can run them on your own graphs right away!
{kind=link}
❤1🔥1
GraphML News (Oct 28th) - Stanford Graph Workshop, NeurIPS workshops
The Stanford Graph Learning workshop happened on Tuesday, 24th and I was privileged to visit it in person and deliver a talk about our recent ULTRA - it was great to meet old friends and many new folks from the graph learning area! The recording will (hopefully) be available soon. Among big announcements was TorchFrame from the authors of PyG - a library for deep learning on tabular data (before Kaggle grandmasters enter the berserker mode 👺 - yes it allows to run xgboost and catboost) that has uniform interfaces for training and inferencing over huge dataframes. PyG but for tabular data!
MoML on Nov 8th at MIT is the next big venue for the geometric learning and drug discovery communities.
NeurIPS workshops decisions are (mostly) out - check out your inboxes if you submitted anything. Some already have the proceedings available on OpenReview: Generative AI and Bio, Deep Generative Models for Health, AI4Science. Have a look there - usually such workshops contain precursors and hints to what will be published by big labs soon.
A new blogpost Topological Generalisation with Advective Diffusion Transformers by Michael Bronstein, Qitian Wu, and Chenxiao Wang introducing ADiT, Advective Diffusion Transformers.
Weekend reading:
Graph Deep Learning for Time Series Forecasting by Andrea Cini et al (IDSIA)
Talk like a Graph: Encoding Graphs for Large Language Models by Bahare Fatemi et al (Google)
Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets by Dominique Beaini et al (Valence, Mila)
Graph Positional and Structural Encoder by Renming Liu, Semih Cantürk et al (Michigan, Mila)
The Stanford Graph Learning workshop happened on Tuesday, 24th and I was privileged to visit it in person and deliver a talk about our recent ULTRA - it was great to meet old friends and many new folks from the graph learning area! The recording will (hopefully) be available soon. Among big announcements was TorchFrame from the authors of PyG - a library for deep learning on tabular data (before Kaggle grandmasters enter the berserker mode 👺 - yes it allows to run xgboost and catboost) that has uniform interfaces for training and inferencing over huge dataframes. PyG but for tabular data!
MoML on Nov 8th at MIT is the next big venue for the geometric learning and drug discovery communities.
NeurIPS workshops decisions are (mostly) out - check out your inboxes if you submitted anything. Some already have the proceedings available on OpenReview: Generative AI and Bio, Deep Generative Models for Health, AI4Science. Have a look there - usually such workshops contain precursors and hints to what will be published by big labs soon.
A new blogpost Topological Generalisation with Advective Diffusion Transformers by Michael Bronstein, Qitian Wu, and Chenxiao Wang introducing ADiT, Advective Diffusion Transformers.
Weekend reading:
Graph Deep Learning for Time Series Forecasting by Andrea Cini et al (IDSIA)
Talk like a Graph: Encoding Graphs for Large Language Models by Bahare Fatemi et al (Google)
Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets by Dominique Beaini et al (Valence, Mila)
Graph Positional and Structural Encoder by Renming Liu, Semih Cantürk et al (Michigan, Mila)
Graph Deep Learning for Time Series Forecasting
by Andrea Cini, Ivan Marisca, Daniele Zambon, Cesare Alippi
arxiv: https://arxiv.org/abs/2310.15978
We are happy to announce the release of our paper on graph deep learning for time series forecasting. This work distills what we learned in the last few years using GNNs for time series analysis.
Key Contributions:
- We introduce a methodological framework that addresses foundational aspects of graph-based neural forecasting often overlooked in existing literature.
- Our approach formalizes the forecasting problem in a graph-based context and offers design principles for building efficient graph-based predictors.
- We discuss how spatiotemporal GNNs can take advantage of pairwise relationships by sharing parameters and conditioning forecasts on graphs spanning the time series collection.
Highlights:
- The paper provides an extensive overview of the field, alongside best practices and recommendations to design and evaluate predictors.
- It delves into ongoing challenges such as latent graph learning, handling missing data, dealing with local effects, inductive learning, and scalability issues.
Additional Resources:
For those interested in practical applications, we have also developed a PyTorch library, TorchSpatiotemporal (https://github.com/TorchSpatiotemporal/tsl), aimed at simplifying the implementation of graph-based time series models. More on our work at https://gmlg.ch.
We hope you find this useful for your research!
by Andrea Cini, Ivan Marisca, Daniele Zambon, Cesare Alippi
arxiv: https://arxiv.org/abs/2310.15978
We are happy to announce the release of our paper on graph deep learning for time series forecasting. This work distills what we learned in the last few years using GNNs for time series analysis.
Key Contributions:
- We introduce a methodological framework that addresses foundational aspects of graph-based neural forecasting often overlooked in existing literature.
- Our approach formalizes the forecasting problem in a graph-based context and offers design principles for building efficient graph-based predictors.
- We discuss how spatiotemporal GNNs can take advantage of pairwise relationships by sharing parameters and conditioning forecasts on graphs spanning the time series collection.
Highlights:
- The paper provides an extensive overview of the field, alongside best practices and recommendations to design and evaluate predictors.
- It delves into ongoing challenges such as latent graph learning, handling missing data, dealing with local effects, inductive learning, and scalability issues.
Additional Resources:
For those interested in practical applications, we have also developed a PyTorch library, TorchSpatiotemporal (https://github.com/TorchSpatiotemporal/tsl), aimed at simplifying the implementation of graph-based time series models. More on our work at https://gmlg.ch.
We hope you find this useful for your research!
GitHub
GitHub - TorchSpatiotemporal/tsl: tsl: a PyTorch library for processing spatiotemporal data.
tsl: a PyTorch library for processing spatiotemporal data. - TorchSpatiotemporal/tsl
GraphML News (Nov 4th) - AlphaFold 2.3 for docking, OpenDAC, KwikBucks
🧬 Google DeepMind and Isomorphic Labs announced AlphaFold 2.3 (with a funny PDF name like Jupyter notebooks) - the newest iteration is crushing the baselines in 3 tasks: docking benchmarks (almost 2x better than DiffDock on PoseBusters), protein-nucleic acid interactions, and antibody-antigen prediction. Most of the paper’s content is devoted to experimental results and some examples. Following the trend of big AI labs, the document is authored by “teams” and has no details on the model architecture — from those 3 paragraphs in the model section, an educated guess might be an equivariant Transformer architecture. I would also add proper citations to the ML docking baselines, eg, DiffDock and TankBind, they deserved it 🙂
💎 Prepare your GemNets and EquiFormers: Open Direct Air Capture (OpenDAC) is a collab between Meta AI and Georgia Tech on discovering new sorbents for capturing CO2 from the air. OpenDAC is a massive dataset that includes 40M DFT calculations from 170K relaxations and will be a part of the OpenCatalyst (OCP) project. OCP delivers a lot of cool stuff this year - apart from OpenDAC they released AdsorbML for the NeurIPS’23 challenge.
💸 Google Research published a blog post on KwikBucks (the person who came up with the name deserves a peer bonus), a clustering method based on the graph representation. Mainly designed for text clustering and document retrieval, the algorithm also works on standard graphs like Cora and Amazon Photos. In case graphs have no features, the authors run Deep Graph Infomax (DGI) to get unsupervised features.
A few shorter updates:
The Workshop on AI-driven discovery for physics and astrophysics (AI4Phys) organized by Center for Data-Driven Discovery and Simons Foundations will take place on January 22-26th at the University of Tokyo. Meanwhile, the proceedings of the NeurIPS AI4Mat Workshop (AI for Accelerated Materials Design) are now available.
LoG is approaching and so are the local meetups! The LoG Meetup at EPFL in Lausanne will be held on Nov 22nd and the meetup at TUM in Munich will be held on Nov30th-Dec 1st.
Weekend reading:
Scaling Riemannian Diffusion Models by Aaron Lou, Minkai Xu, and Stefano Ermon (Stanford)
Equivariant Matrix Function Neural Networks by Ilyes Batatia feat. Gábor Csányi (Cambridge)
A Unified Framework to Enforce, Discover, and Promote Symmetry in Machine Learning by Samuel E. Otto feat. Steven L. Brunton (UW) - a massive work on symmetries and equivariances in neural nets highlighting the effectiveness of Lie derivatives
Effect of Choosing Loss Function when Using T-batching for Representation Learning on Dynamic Networks by Erfan Loghmani and MohammadAmin Fazli (Sharif) - on the losses for temporal graph learning, also introduces the Myket dataset already integrated into PyG
🧬 Google DeepMind and Isomorphic Labs announced AlphaFold 2.3 (with a funny PDF name like Jupyter notebooks) - the newest iteration is crushing the baselines in 3 tasks: docking benchmarks (almost 2x better than DiffDock on PoseBusters), protein-nucleic acid interactions, and antibody-antigen prediction. Most of the paper’s content is devoted to experimental results and some examples. Following the trend of big AI labs, the document is authored by “teams” and has no details on the model architecture — from those 3 paragraphs in the model section, an educated guess might be an equivariant Transformer architecture. I would also add proper citations to the ML docking baselines, eg, DiffDock and TankBind, they deserved it 🙂
💎 Prepare your GemNets and EquiFormers: Open Direct Air Capture (OpenDAC) is a collab between Meta AI and Georgia Tech on discovering new sorbents for capturing CO2 from the air. OpenDAC is a massive dataset that includes 40M DFT calculations from 170K relaxations and will be a part of the OpenCatalyst (OCP) project. OCP delivers a lot of cool stuff this year - apart from OpenDAC they released AdsorbML for the NeurIPS’23 challenge.
💸 Google Research published a blog post on KwikBucks (the person who came up with the name deserves a peer bonus), a clustering method based on the graph representation. Mainly designed for text clustering and document retrieval, the algorithm also works on standard graphs like Cora and Amazon Photos. In case graphs have no features, the authors run Deep Graph Infomax (DGI) to get unsupervised features.
A few shorter updates:
The Workshop on AI-driven discovery for physics and astrophysics (AI4Phys) organized by Center for Data-Driven Discovery and Simons Foundations will take place on January 22-26th at the University of Tokyo. Meanwhile, the proceedings of the NeurIPS AI4Mat Workshop (AI for Accelerated Materials Design) are now available.
LoG is approaching and so are the local meetups! The LoG Meetup at EPFL in Lausanne will be held on Nov 22nd and the meetup at TUM in Munich will be held on Nov30th-Dec 1st.
Weekend reading:
Scaling Riemannian Diffusion Models by Aaron Lou, Minkai Xu, and Stefano Ermon (Stanford)
Equivariant Matrix Function Neural Networks by Ilyes Batatia feat. Gábor Csányi (Cambridge)
A Unified Framework to Enforce, Discover, and Promote Symmetry in Machine Learning by Samuel E. Otto feat. Steven L. Brunton (UW) - a massive work on symmetries and equivariances in neural nets highlighting the effectiveness of Lie derivatives
Effect of Choosing Loss Function when Using T-batching for Representation Learning on Dynamic Networks by Erfan Loghmani and MohammadAmin Fazli (Sharif) - on the losses for temporal graph learning, also introduces the Myket dataset already integrated into PyG
{kind=link}
GraphML News (Nov 11th) - MoML, GFlowNets workshop, NeurIPS workshops and blogs
👺 Brace yourselves, ICLR reviews are out and Reviewer 2 is most dangerous in those wildest conditions.
🧬 The Molecular ML conference at MIT happened a few days ago and brought together folks from geometric DL, computational biology, drug discovery, protein learning, and materials science. We won’t have the recordings, but the list of accepted posters is published and you can find many of them on arxiv already.
🌊 A handful of the MoML posters featured Generative Flow Networks (GFlowNets), and its authors at Mila organized a whole 3-day workshop on the basics of generative modeling and foundations of GFlowNets with many practical examples - all 24 hours of streams are available on YouTube now.
More NeurIPS workshops opened the lists of accepted papers: AI for Accelerated Materials Design, Temporal Graph Learning, Mathematical Reasoning and AI
✍️ And several new blogposts have arrived:
- Equivariant neural networks – *what*, *why* and *how* ? by Maurice Weiler - Part 1 out of the planned five chapters explaining the main ideas in the recent book on Equivariant and Coordinate Independent CNNs.
- ULTRA: Foundation Models for Knowledge Graph Reasoning by our small team featuring the invited guest Bruno Ribeiro (Purdue) where we give more visual explanation on the motivation and mechanisms behind our recent paper on KG reasoning.
Weekend reading:
From Molecules to Materials: Pre-training Large Generalizable Models for Atomic Property Prediction by Nima Shoghi feat. Larry Zitnick (Meta AI and CMU) - pretty much a foundation model for many molecular and materials science tasks - a pre-trained 230M params GemNet-OC, lots of engineering insights on training such complex models on diverse and imbalanced datasets
Examining graph neural networks for crystal structures: Limitations and opportunities for capturing periodicity by Sheng Gong feat. Tian Xie, Rafael Gomez-Bombarelli, Shuiwang Ji - on the eternal quest of designing abstractions for periodic structures where GNNs can still fail
Efficient Subgraph GNNs by Learning Effective Selection Policies by Beatrice Bevilacqua feat. Bruno Ribeiro, Haggai Maron - on improving notoriously hungry subgraph GNNs with Gumbel-Softmax and Straight-through estimation tricks
Locality-Aware Graph-Rewiring in GNNs (NeurIPS’23) by Federico Barbero feat Michael Bronstein and Francesco Di Giovanni - introduces the LASER graph rewiring method that produces a sequence of rewired graph snapshots with new edges selected based on the connectivity and locality constraints. Fast and effective!
👺 Brace yourselves, ICLR reviews are out and Reviewer 2 is most dangerous in those wildest conditions.
🧬 The Molecular ML conference at MIT happened a few days ago and brought together folks from geometric DL, computational biology, drug discovery, protein learning, and materials science. We won’t have the recordings, but the list of accepted posters is published and you can find many of them on arxiv already.
🌊 A handful of the MoML posters featured Generative Flow Networks (GFlowNets), and its authors at Mila organized a whole 3-day workshop on the basics of generative modeling and foundations of GFlowNets with many practical examples - all 24 hours of streams are available on YouTube now.
More NeurIPS workshops opened the lists of accepted papers: AI for Accelerated Materials Design, Temporal Graph Learning, Mathematical Reasoning and AI
✍️ And several new blogposts have arrived:
- Equivariant neural networks – *what*, *why* and *how* ? by Maurice Weiler - Part 1 out of the planned five chapters explaining the main ideas in the recent book on Equivariant and Coordinate Independent CNNs.
- ULTRA: Foundation Models for Knowledge Graph Reasoning by our small team featuring the invited guest Bruno Ribeiro (Purdue) where we give more visual explanation on the motivation and mechanisms behind our recent paper on KG reasoning.
Weekend reading:
From Molecules to Materials: Pre-training Large Generalizable Models for Atomic Property Prediction by Nima Shoghi feat. Larry Zitnick (Meta AI and CMU) - pretty much a foundation model for many molecular and materials science tasks - a pre-trained 230M params GemNet-OC, lots of engineering insights on training such complex models on diverse and imbalanced datasets
Examining graph neural networks for crystal structures: Limitations and opportunities for capturing periodicity by Sheng Gong feat. Tian Xie, Rafael Gomez-Bombarelli, Shuiwang Ji - on the eternal quest of designing abstractions for periodic structures where GNNs can still fail
Efficient Subgraph GNNs by Learning Effective Selection Policies by Beatrice Bevilacqua feat. Bruno Ribeiro, Haggai Maron - on improving notoriously hungry subgraph GNNs with Gumbel-Softmax and Straight-through estimation tricks
Locality-Aware Graph-Rewiring in GNNs (NeurIPS’23) by Federico Barbero feat Michael Bronstein and Francesco Di Giovanni - introduces the LASER graph rewiring method that produces a sequence of rewired graph snapshots with new edges selected based on the connectivity and locality constraints. Fast and effective!
GraphML News (Nov 18th) - GraphCast and Chroma release, Neural Circulation Models
While one half of the world digests the drama around OpenAI and comes up with conspiracy theories and another half is working on ICLR rebuttals and CVPR deadlines, let’s look at the GraphML news!
☔ Two models we first spotted and mentioned in 2023 The State of Affairs post were officially released as Science and Nature publications: GraphCast from Google DeepMind for weather prediction and Chroma for protein design from Generate Biomedicines. Both GraphCast and Chroma are open-sourced on Github (GraphCast repo, Chroma repo), huge kudos for the authors for doing that 👏
🏟️ Both Chroma and RFDiffusion will be the keynotes at the MLSB workshop at NeurIPS, and Gabriele Corso already suggests to prepare some 🍿 to see the final showdown of the two heavy-weight generative champions (with EvoDiff in the interlude).
Google Research and DeepMind went an extra mile and uploaded a new paper on Neural General Circulation Models that already outperforms GraphCast on several tasks. The core component of NeuralGCM is a differentiable ODE solver, but otherwise it’s the encode-process-decode architecture with MLPs.
Xiaoxin He compiled a list of graph papers to be presented at NeurIPS’23 - a handy tool to get ready for the poster sessions!
Weekend reading:
A new age in protein design empowered by deep learning by Hamed Khakzad et al feat Michael Bronstein and Bruno Correia - a survey on (geometric) DL models for protein design including hot generative models.
Exposition on over-squashing problem on GNNs: Current Methods, Benchmarks and Challenges by Dai Shi et al - a comprehensive survey on oversquashing and how to deal with it
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search by Abbas Mehrabian, Ankit Anand, Hyunjik Kim, et al (feat Petar Veličković) - an excellent read on approaching one of the classical graph theory problems with RL
While one half of the world digests the drama around OpenAI and comes up with conspiracy theories and another half is working on ICLR rebuttals and CVPR deadlines, let’s look at the GraphML news!
☔ Two models we first spotted and mentioned in 2023 The State of Affairs post were officially released as Science and Nature publications: GraphCast from Google DeepMind for weather prediction and Chroma for protein design from Generate Biomedicines. Both GraphCast and Chroma are open-sourced on Github (GraphCast repo, Chroma repo), huge kudos for the authors for doing that 👏
🏟️ Both Chroma and RFDiffusion will be the keynotes at the MLSB workshop at NeurIPS, and Gabriele Corso already suggests to prepare some 🍿 to see the final showdown of the two heavy-weight generative champions (with EvoDiff in the interlude).
Google Research and DeepMind went an extra mile and uploaded a new paper on Neural General Circulation Models that already outperforms GraphCast on several tasks. The core component of NeuralGCM is a differentiable ODE solver, but otherwise it’s the encode-process-decode architecture with MLPs.
Xiaoxin He compiled a list of graph papers to be presented at NeurIPS’23 - a handy tool to get ready for the poster sessions!
Weekend reading:
A new age in protein design empowered by deep learning by Hamed Khakzad et al feat Michael Bronstein and Bruno Correia - a survey on (geometric) DL models for protein design including hot generative models.
Exposition on over-squashing problem on GNNs: Current Methods, Benchmarks and Challenges by Dai Shi et al - a comprehensive survey on oversquashing and how to deal with it
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search by Abbas Mehrabian, Ankit Anand, Hyunjik Kim, et al (feat Petar Veličković) - an excellent read on approaching one of the classical graph theory problems with RL
GraphML News (Nov 25th) - LOG’23 starts next week, EEML’24,
The OpenAI drama has been successfully resolved and now the ML world is wandering about Q* that (allegedly) showed some amazing improvements towards AGI. Henceforth, Q-learning and classic A* search algorithm are among the hottest trends this week 🤣 (where I could insert a shameless plug and point that audience to the neural A*Net paper we’ll be presenting at NeurIPS’23). Besides that:
LoG 2023, the graph’iest ML conference, starts next Monday, November 27th — registration is free and participation is fully-remote. It would have been nicer to have a list of accepted papers and tutorials a bit before the very starting day of the conference 🙂 (perhaps the organizers are also busy with ICLR rebuttals and NeurIPS workshops).
The Eastern European ML Summer School (EEML) has just announced its 2024 installment (15-20 July, Novi Sad, Serbia) featuring a stellar lineup of speakers and organizers including Kyunghyun Cho, Doina Precup, Michael Bronstein, Alfredo Canziani, Petar Veličković, and many more prominent researchers (especially from DeepMind). So we would expect quite a few lectures and tutorials on graph learning!
Weekend reading:
Generalized Biomolecular Modeling and Design with RoseTTAFold All-Atom from the Baker Lab - all-atom versions of RosettaFold (RFAA) for structure prediction and RFdiffusionAA for protein-ligand binding generative model.
Geometric Algebra Transformer (GATr 🐊) by Johann Brehmer feat. Taco Cohen. GATr = Clifford Algebras + Transformers, built-in E(3) equivariance. Some applications include n-body dynamics, wall-shear-stress estimation of human arteries, and robotic planning. The code was recently published as well.
A Survey of Graph Meets Large Language Model: Progress and Future Directions by Yuhan Li et al. The subfield exists for a few months but there is already a survey about it.
The OpenAI drama has been successfully resolved and now the ML world is wandering about Q* that (allegedly) showed some amazing improvements towards AGI. Henceforth, Q-learning and classic A* search algorithm are among the hottest trends this week 🤣 (where I could insert a shameless plug and point that audience to the neural A*Net paper we’ll be presenting at NeurIPS’23). Besides that:
LoG 2023, the graph’iest ML conference, starts next Monday, November 27th — registration is free and participation is fully-remote. It would have been nicer to have a list of accepted papers and tutorials a bit before the very starting day of the conference 🙂 (perhaps the organizers are also busy with ICLR rebuttals and NeurIPS workshops).
The Eastern European ML Summer School (EEML) has just announced its 2024 installment (15-20 July, Novi Sad, Serbia) featuring a stellar lineup of speakers and organizers including Kyunghyun Cho, Doina Precup, Michael Bronstein, Alfredo Canziani, Petar Veličković, and many more prominent researchers (especially from DeepMind). So we would expect quite a few lectures and tutorials on graph learning!
Weekend reading:
Generalized Biomolecular Modeling and Design with RoseTTAFold All-Atom from the Baker Lab - all-atom versions of RosettaFold (RFAA) for structure prediction and RFdiffusionAA for protein-ligand binding generative model.
Geometric Algebra Transformer (GATr 🐊) by Johann Brehmer feat. Taco Cohen. GATr = Clifford Algebras + Transformers, built-in E(3) equivariance. Some applications include n-body dynamics, wall-shear-stress estimation of human arteries, and robotic planning. The code was recently published as well.
A Survey of Graph Meets Large Language Model: Progress and Future Directions by Yuhan Li et al. The subfield exists for a few months but there is already a survey about it.
The Learning on Graphs Conference 2023 will be taking place virtually for free from 27th -- 30th November.
LoG is an annual research conference started to provide a dedicated venue for areas broadly related to machine learning on graphs and geometric data, with a special focus on review quality (top reviewers are given monetary awards).
Website: https://logconference.org/
Slack: https://join.slack.com/t/logconference/shared_invite/zt-27nv8ba1y-pXspnAzgLOMdDzfKgpOafg
This year's program has an excited lineup of keynote speakers, oral presentations, and tutorials, as well as poster sessions and social hours. All the details on how to attend are available on the LoG website.
Tune in to hear about the latest trends in Graph Neural Network theory, applications of Geometric Deep Learning, and more!
LoG is an annual research conference started to provide a dedicated venue for areas broadly related to machine learning on graphs and geometric data, with a special focus on review quality (top reviewers are given monetary awards).
Website: https://logconference.org/
Slack: https://join.slack.com/t/logconference/shared_invite/zt-27nv8ba1y-pXspnAzgLOMdDzfKgpOafg
This year's program has an excited lineup of keynote speakers, oral presentations, and tutorials, as well as poster sessions and social hours. All the details on how to attend are available on the LoG website.
Tune in to hear about the latest trends in Graph Neural Network theory, applications of Geometric Deep Learning, and more!
GraphML News (Dec 2nd) - RelBench, GNoME, and 3 roasts of the week
The LoG’23 conference took place this week (along with numerous local meetups!) and all the steam recordings are already available on the YouTube channel including tutorials and keynotes by Jure Leskovec, Andreas Loukas, Stefanie Jegelka, and Kyle Cranmer — check them out over the weekend!
➡️ One of the huge LoG announcements is RelBench — a new benchmark for Relational Deep Learning introduced by Jure Leskovec and the PyG / TorchFrame team behind it. RelBench poses temporal classification and regression tasks over large tables that can be represented as multi-partite graphs (each row from each table is a unique node). Jure also hinted that temporal hypergraphs can be even more efficient. The first 🔥 roast of the week 🔥 goes to Jure for noticing all those modern graph databases being orders of magnitude slower for such tasks. Time to sell GDBMS stocks? 📉
⚛️ The second big announcement is GNoME from Google DeepMind - a GNN-based system that discovered 2.2M new crystal structures including about 380k stable structures. GNoME traces were already there in the Materials Project database since spring, and now we see a full release upon the publication in Nature. Practically, GNoME consists of two GNNs - a simple MPNN as a composition model and NequIP as a structural model for interatomic potentials. GNoME demonstrates impressive scaling capabilities and features sophisticated pipelines involving DFT calculations and active learning loops. The code and data are published on GitHub and we can enjoy the JAX implementation of NequIP - time to jump on the tensor product train 🚂 if you haven’t yet.
The GNoMe project spawned another accepted Nature paper on the experimental side of creating those materials in the automated lab, and it spawned quite some active community discussion. The second 🔥 roast of the week 🔥 goes to Robert Palgrave from UCL for highlighting many issues of that paper that might have been swept under the rug and compromised the methodology.
Weekend reading:
Relational Deep Learning: Graph Representation Learning on Relational Databases by Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, and Kumo + Stanford team. The RelBench paper
Scaling deep learning for materials discovery by Amil Merchant, Simon Batzner, et al. The GNoME paper.
Generating Molecular Conformer Fields by Wang et al and Apple - turns out a simple diffusion model without fancy equivariances can beat GeoDiff and Torsional Diffusion in conformer generation. Definitely deserves the third 🔥 roast of the week 🔥
The LoG’23 conference took place this week (along with numerous local meetups!) and all the steam recordings are already available on the YouTube channel including tutorials and keynotes by Jure Leskovec, Andreas Loukas, Stefanie Jegelka, and Kyle Cranmer — check them out over the weekend!
➡️ One of the huge LoG announcements is RelBench — a new benchmark for Relational Deep Learning introduced by Jure Leskovec and the PyG / TorchFrame team behind it. RelBench poses temporal classification and regression tasks over large tables that can be represented as multi-partite graphs (each row from each table is a unique node). Jure also hinted that temporal hypergraphs can be even more efficient. The first 🔥 roast of the week 🔥 goes to Jure for noticing all those modern graph databases being orders of magnitude slower for such tasks. Time to sell GDBMS stocks? 📉
⚛️ The second big announcement is GNoME from Google DeepMind - a GNN-based system that discovered 2.2M new crystal structures including about 380k stable structures. GNoME traces were already there in the Materials Project database since spring, and now we see a full release upon the publication in Nature. Practically, GNoME consists of two GNNs - a simple MPNN as a composition model and NequIP as a structural model for interatomic potentials. GNoME demonstrates impressive scaling capabilities and features sophisticated pipelines involving DFT calculations and active learning loops. The code and data are published on GitHub and we can enjoy the JAX implementation of NequIP - time to jump on the tensor product train 🚂 if you haven’t yet.
The GNoMe project spawned another accepted Nature paper on the experimental side of creating those materials in the automated lab, and it spawned quite some active community discussion. The second 🔥 roast of the week 🔥 goes to Robert Palgrave from UCL for highlighting many issues of that paper that might have been swept under the rug and compromised the methodology.
Weekend reading:
Relational Deep Learning: Graph Representation Learning on Relational Databases by Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, and Kumo + Stanford team. The RelBench paper
Scaling deep learning for materials discovery by Amil Merchant, Simon Batzner, et al. The GNoME paper.
Generating Molecular Conformer Fields by Wang et al and Apple - turns out a simple diffusion model without fancy equivariances can beat GeoDiff and Torsional Diffusion in conformer generation. Definitely deserves the third 🔥 roast of the week 🔥
Guest post by Maryan Ramezani:
Joint Inference of Diffusion and Structure in Partially Observed Social Networks Using Coupled Matrix Factorization
By Maryam Ramezani, Aryan Ahadinia, Amirmohammad Ziaei Bideh, and Hamid R Rabiee.
Published in ACM Transactions on Knowledge Discovery from Data (TKDD).
📢 Thrilled to unveil our latest research on #SocialNetworks! My paper dives into the challenges of missing data in large-scale networks from a novel point of view: partial observation of both the temporal cascades and the underlying structure. Introducing 'DiffStru,' a probabilistic generative model, we jointly uncover hidden diffusion activities and network structures through coupled matrix factorization. Excitingly, our approach not only fills gaps in data but also aids in network classification problems by learning coupled representations of temporal cascades and users. 🚀 Tested on synthetic and real datasets, the results are promising – detecting hidden behaviors and predicting links by unveiling latent features. 📊🔍
Our method uses the following input.
☝️ A partial observations of the underlying network as a graph: Nodes are representing users and directed links are corresponding to the following relations between users. All nodes are present but some links are omitted.
✌️ A partial sequential observation of user participations in information diffusion process, namely cascades: Users participate in cascades, e.g. retweeting a topic, in a social media. Our observation is a set of cascades with users participated in some of them in a specified timestamp.
The output of our method is as follows.
1️⃣ Predictions of omitted links in the underlying network.
2️⃣ Predictions of users' participations in cascades, including their timestamps.
3️⃣ A coupled representation of users and cascades which can be used for further analysis, e.g. community detection.
Joint Inference of Diffusion and Structure in Partially Observed Social Networks Using Coupled Matrix Factorization
By Maryam Ramezani, Aryan Ahadinia, Amirmohammad Ziaei Bideh, and Hamid R Rabiee.
Published in ACM Transactions on Knowledge Discovery from Data (TKDD).
🌐 ACM Digital Library: https://dl.acm.org/doi/abs/10.1145/3599237🌐 GitHub: https://github.com/maryram/DiffStru📢 Thrilled to unveil our latest research on #SocialNetworks! My paper dives into the challenges of missing data in large-scale networks from a novel point of view: partial observation of both the temporal cascades and the underlying structure. Introducing 'DiffStru,' a probabilistic generative model, we jointly uncover hidden diffusion activities and network structures through coupled matrix factorization. Excitingly, our approach not only fills gaps in data but also aids in network classification problems by learning coupled representations of temporal cascades and users. 🚀 Tested on synthetic and real datasets, the results are promising – detecting hidden behaviors and predicting links by unveiling latent features. 📊🔍
Our method uses the following input.
☝️ A partial observations of the underlying network as a graph: Nodes are representing users and directed links are corresponding to the following relations between users. All nodes are present but some links are omitted.
✌️ A partial sequential observation of user participations in information diffusion process, namely cascades: Users participate in cascades, e.g. retweeting a topic, in a social media. Our observation is a set of cascades with users participated in some of them in a specified timestamp.
The output of our method is as follows.
1️⃣ Predictions of omitted links in the underlying network.
2️⃣ Predictions of users' participations in cascades, including their timestamps.
3️⃣ A coupled representation of users and cascades which can be used for further analysis, e.g. community detection.
ACM Transactions on Knowledge Discovery from Data
Joint Inference of Diffusion and Structure in Partially Observed Social Networks Using Coupled Matrix Factorization | ACM Transactions…
Access to complete data in large-scale networks is often infeasible. Therefore, the
problem of missing data is a crucial and unavoidable issue in the analysis and modeling
of real-world social networks. However, most of the research on different aspects
...
problem of missing data is a crucial and unavoidable issue in the analysis and modeling
of real-world social networks. However, most of the research on different aspects
...
👍1