
How many arguments
Создайте функцию args_count, которая возвращает количество предоставленных аргументов
Пример:
👉 @frontendInterview
Создайте функцию args_count, которая возвращает количество предоставленных аргументов
Пример:
args_count(1, 2, 3) -> 3
args_count(1, 2, 3, 10) -> 4
👉 @frontendInterview
👎3🤔1
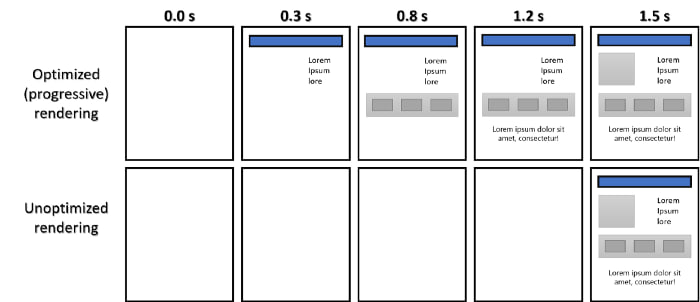
Что такое прогрессивный рендеринг (progressive rendering)?
Чтобы понять что такое progressive rendering, нужно понимать отличие client-side rendering от server-side rendering.
При client-side rendering (CSR) контент отрисовывается на стороне клиента (в браузере). Такой подход используется в React, когда браузеру отсылается практически пустой HTML-документ, а потом запускается скрипт, который генерирует HTML в указанном скрипту теге. Как правило это <div id="root">. Пользователь будет видеть пустую страницу, пока JS-файл полностью не загрузится.
При server-side rendering (SSR) HTML-разметка генерируется на сервере, отсылается браузеру и после этого отрисовывается на клиенте. Пользователь увидит контент сразу же, но не сможет взаимодействовать со страницей, пока не загрузится JS-файл.
При использовании прогрессивного рендеринга, кусочки HTML генерируется на сервере и отсылаются браузеру в порядке их приоритетности. То есть, элементы с самым высоким приоритетом (например <header>, фон, главная интерактивная часть страницы) генерируются на сервере, отсылаются браузеру и отрисовываются в первую очередь. Это позволяет пользователю увидеть самый важный контент как можно скорее, не дожидаясь полной загрузки всего контента. То есть, progressive rendering что-то среднее между client-side rendering и server-side rendering.
Техники реализации прогрессивного рендеринга:
Ленивая загрузка (Lazy Loading). Загрузка контента по мере необходимости. Например, если страница достаточно большая, не нужно загружать изображения вне вьюпорта. Загрузка изображения стартует за некоторое время до того как она появится во вьюпорте. Эту же технику можно использовать для загрузки контента изначально скрытых элементов. Например, можно загрузить контент закрытого меню когда пользователь наводит курсор на кнопку открытия.
Приоритизация контента. Например, не загружать изначально все CSS-стили. Добавлять в <head> загрузку только тех стилей, которые нужны для текущей видимой области HTML-документа. Остальные стили можно добавить в <body>.
👉 @frontendInterview
Чтобы понять что такое progressive rendering, нужно понимать отличие client-side rendering от server-side rendering.
При client-side rendering (CSR) контент отрисовывается на стороне клиента (в браузере). Такой подход используется в React, когда браузеру отсылается практически пустой HTML-документ, а потом запускается скрипт, который генерирует HTML в указанном скрипту теге. Как правило это <div id="root">. Пользователь будет видеть пустую страницу, пока JS-файл полностью не загрузится.
При server-side rendering (SSR) HTML-разметка генерируется на сервере, отсылается браузеру и после этого отрисовывается на клиенте. Пользователь увидит контент сразу же, но не сможет взаимодействовать со страницей, пока не загрузится JS-файл.
При использовании прогрессивного рендеринга, кусочки HTML генерируется на сервере и отсылаются браузеру в порядке их приоритетности. То есть, элементы с самым высоким приоритетом (например <header>, фон, главная интерактивная часть страницы) генерируются на сервере, отсылаются браузеру и отрисовываются в первую очередь. Это позволяет пользователю увидеть самый важный контент как можно скорее, не дожидаясь полной загрузки всего контента. То есть, progressive rendering что-то среднее между client-side rendering и server-side rendering.
Техники реализации прогрессивного рендеринга:
Ленивая загрузка (Lazy Loading). Загрузка контента по мере необходимости. Например, если страница достаточно большая, не нужно загружать изображения вне вьюпорта. Загрузка изображения стартует за некоторое время до того как она появится во вьюпорте. Эту же технику можно использовать для загрузки контента изначально скрытых элементов. Например, можно загрузить контент закрытого меню когда пользователь наводит курсор на кнопку открытия.
Приоритизация контента. Например, не загружать изначально все CSS-стили. Добавлять в <head> загрузку только тех стилей, которые нужны для текущей видимой области HTML-документа. Остальные стили можно добавить в <body>.
👉 @frontendInterview
{kind=link}
👍5❤2
Настройка сайта для поисковиков и скринридеров
Современный сайт — это не только интерфейс пользователя. Чтобы сайт «взлетел» нужно многое добавить после реализации макета в вёрстке. Наряду с быстродействием, оптимизацией загрузки контента и кода, важно уделить внимание настройке сайта под поисковые системы и социальные сети, отработать вариант использования сайта с помощью скринридеров и другое.
Для этого необходимо разобраться с тем, как различные сервисы, службы, приложения «читают» сайт, как подготовить его для них и как сделать это правильно.
👉 @frontendInterview
Современный сайт — это не только интерфейс пользователя. Чтобы сайт «взлетел» нужно многое добавить после реализации макета в вёрстке. Наряду с быстродействием, оптимизацией загрузки контента и кода, важно уделить внимание настройке сайта под поисковые системы и социальные сети, отработать вариант использования сайта с помощью скринридеров и другое.
Для этого необходимо разобраться с тем, как различные сервисы, службы, приложения «читают» сайт, как подготовить его для них и как сделать это правильно.
👉 @frontendInterview
👍1
Пособие по промпт-инжинирингу для программистов
Разработчики всё чаще полагаются на ИИ-помощников, чтобы ускорить повседневную работу с кодом. Эти инструменты умеют автозаполнять функции, предлагать исправления ошибок и даже генерировать целые модули или MVP. Тем не менее, как многие из нас убедились, качество вывода ИИ во многом зависит от качества предоставленного запроса. Плохо сформулированный промпт может привести к нерелевантным или общим ответам, в то время как хорошо составленный — дать продуманные, точные и даже креативные решения для кода.
В статье Эдди Османи, ведущий инженер Google, выделяет ключевые шаблоны запросов, повторяемые фреймворки и запоминающиеся примеры, которые нашли отклик у разработчиков.
Автор приводит параллельные сравнения хороших и плохих промптов, фактические ответы ИИ, а также комментарии: чтобы понять, почему один запрос успешен, а другой терпит неудачу.
👉 @frontendInterview
Разработчики всё чаще полагаются на ИИ-помощников, чтобы ускорить повседневную работу с кодом. Эти инструменты умеют автозаполнять функции, предлагать исправления ошибок и даже генерировать целые модули или MVP. Тем не менее, как многие из нас убедились, качество вывода ИИ во многом зависит от качества предоставленного запроса. Плохо сформулированный промпт может привести к нерелевантным или общим ответам, в то время как хорошо составленный — дать продуманные, точные и даже креативные решения для кода.
В статье Эдди Османи, ведущий инженер Google, выделяет ключевые шаблоны запросов, повторяемые фреймворки и запоминающиеся примеры, которые нашли отклик у разработчиков.
Автор приводит параллельные сравнения хороших и плохих промптов, фактические ответы ИИ, а также комментарии: чтобы понять, почему один запрос успешен, а другой терпит неудачу.
👉 @frontendInterview
👎2👍1
Какое состояние НЕ является одним из состояний промиса?
Anonymous Quiz
19%
Pending
24%
Fulfilled
6%
Rejected
51%
Resolved
❤3
Что такое вендорные префиксы?
Это приставки перед свойствами, селекторами, функциями или другими сущностями в CSS, позволяющие браузерам внедрять экспериментальные фичи до того, как они полностью стандартизированы и готовы для использования. Когда префикс отбрасывается — это знак, что всё готово.
Основные браузеры используют следующие префиксы:
-webkit- — Safari, Chrome, Opera 15+ и другие браузеры на основе движка WebKit или Blink.
-moz- — Firefox и браузеры на движке Gecko.
-o- — Opera 12 и раньше, на движке Presto.
-ms- — Internet Explorer и старый Microsoft Edge 12–18.
👉 @frontendInterview
Это приставки перед свойствами, селекторами, функциями или другими сущностями в CSS, позволяющие браузерам внедрять экспериментальные фичи до того, как они полностью стандартизированы и готовы для использования. Когда префикс отбрасывается — это знак, что всё готово.
Основные браузеры используют следующие префиксы:
-webkit- — Safari, Chrome, Opera 15+ и другие браузеры на основе движка WebKit или Blink.
-moz- — Firefox и браузеры на движке Gecko.
-o- — Opera 12 и раньше, на движке Presto.
-ms- — Internet Explorer и старый Microsoft Edge 12–18.
👉 @frontendInterview
👍4
Web Application Security
Несмотря на то, что доступно много ресурсов с информацией по обеспечению безопасности сети и ИТ, подробные знания о безопасности современных веб-приложений не были структурированы - до выхода данной книги. Это практическое руководство содержит описывает разнообразные концепции информационной безопасности, которые разработчики программного обеспечения могут легко освоить и применить.
👉 @frontendInterview
Несмотря на то, что доступно много ресурсов с информацией по обеспечению безопасности сети и ИТ, подробные знания о безопасности современных веб-приложений не были структурированы - до выхода данной книги. Это практическое руководство содержит описывает разнообразные концепции информационной безопасности, которые разработчики программного обеспечения могут легко освоить и применить.
👉 @frontendInterview
Create Phone Number
Создайте функцию, которая принимает массив из 10 целых чисел (от 0 до 9) и возвращает строку этих чисел в виде номера телефона
Пример:
👉 @frontendInterview
Создайте функцию, которая принимает массив из 10 целых чисел (от 0 до 9) и возвращает строку этих чисел в виде номера телефона
Пример:
createPhoneNumber([1, 2, 3, 4, 5, 6, 7, 8, 9, 0]) // => returns "(123) 456-7890"
👉 @frontendInterview
Как происходит аутентификация?
Это процесс проверки подлинности пользователя, который пытается получить доступ к системе или ресурсу. Веб-приложения и сервисы обычно используют несколько методов аутентификации для обеспечения безопасности и защиты данных.
Методы
Аутентификация по паролю
Пользователь вводит имя пользователя и пароль, которые проверяются на сервере. Веб-сайты с формой входа, требующей логин и пароль. После успешного входа пользователь получает токен (например, JWT), который используется для дальнейших запросов. API, использующие токены для проверки подлинности запросов.
OAuth
Протокол авторизации, позволяющий сторонним приложениям получать ограниченный доступ к ресурсам пользователя без передачи пароля. Вход через Google, Facebook или другие социальные сети.
Двухфакторная аутентификация (2FA)
Требует два различных типа проверки (например, пароль и одноразовый код). Вход с использованием пароля и SMS-кода.
Биометрическая аутентификация
Использует биометрические данные (например, отпечатки пальцев или распознавание лиц) для проверки подлинности. Вход через Touch ID или Face ID на мобильных устройствах.
Сервер на Node.js с использованием Express и JWT
Установка зависимостей
Создание сервера
👉 @frontendInterview
Это процесс проверки подлинности пользователя, который пытается получить доступ к системе или ресурсу. Веб-приложения и сервисы обычно используют несколько методов аутентификации для обеспечения безопасности и защиты данных.
Методы
Аутентификация по паролю
Пользователь вводит имя пользователя и пароль, которые проверяются на сервере. Веб-сайты с формой входа, требующей логин и пароль. После успешного входа пользователь получает токен (например, JWT), который используется для дальнейших запросов. API, использующие токены для проверки подлинности запросов.
OAuth
Протокол авторизации, позволяющий сторонним приложениям получать ограниченный доступ к ресурсам пользователя без передачи пароля. Вход через Google, Facebook или другие социальные сети.
Двухфакторная аутентификация (2FA)
Требует два различных типа проверки (например, пароль и одноразовый код). Вход с использованием пароля и SMS-кода.
Биометрическая аутентификация
Использует биометрические данные (например, отпечатки пальцев или распознавание лиц) для проверки подлинности. Вход через Touch ID или Face ID на мобильных устройствах.
Сервер на Node.js с использованием Express и JWT
Установка зависимостей
npm install express jsonwebtoken bcryptjs body-parser
Создание сервера
const express = require('express');
const jwt = require('jsonwebtoken');
const bcrypt = require('bcryptjs');
const bodyParser = require('body-parser');
const app = express();
const PORT = 3000;
const SECRET_KEY = 'your_secret_key';
let users = []; // Для простоты используем массив в памяти
app.use(bodyParser.json());
// Регистрация пользователя
app.post('/register', async (req, res) => {
const { username, password } = req.body;
const hashedPassword = await bcrypt.hash(password, 8);
users.push({ username, password: hashedPassword });
res.status(201).send('User registered');
});
// Вход пользователя
app.post('/login', async (req, res) => {
const { username, password } = req.body;
const user = users.find(u => u.username === username);
if (!user) {
return res.status(404).send('User not found');
}
const isPasswordValid = await bcrypt.compare(password, user.password);
if (!isPasswordValid) {
return res.status(401).send('Invalid password');
}
const token = jwt.sign({ username: user.username }, SECRET_KEY, { expiresIn: '1h' });
res.json({ token });
});
// Защищенный маршрут
app.get('/protected', (req, res) => {
const token = req.headers['authorization'];
if (!token) {
return res.status(401).send('Access denied');
}
try {
const decoded = jwt.verify(token, SECRET_KEY);
res.json({ message: 'Protected content', user: decoded });
} catch (err) {
res.status(401).send('Invalid token');
}
});
app.listen(PORT, () => {
console.log(`Server is running on https://localhost:${PORT}`);
});👉 @frontendInterview
👍4❤2
Чек-лист по SEO оптимизации для фронтенд разработчика
Оптимизация сайта для SEO по большой части подразумевает то, что мы должны разработать сайт таким образом, чтоб роботы/пауки поискового движка могли легко понимать наш сайт.
Нам как фронтенд разработчикам для этого надо позаботиться о следующих вещах:
- Семантичная и структурированная верстка. На данный момент поисковики обращают внимание на семантику HTML, и если все на div-ах или таблицах, то сайт навряд ли попадет на первые строчки поискового запроса. Семантичная верстка наполняет смыслом теги, и структуры, которые мы создаем в HTML, и это облегчает роботам понимать где и что находится на странице нашего сайта.
- Правильно использовать и структурировать заголовки на страницах. У каждой страницы должен быть один и единственный тег <h1>, который считается основным заголовком и говорит о чем страница, далее должна соблюдаться вложенность заголовков, то есть h2, у вложенного в него элемента заголовок h3 и т.д.
- Никогда не забывать alt атрибут у тега <img>, таким образом мы объясняем роботам, что это за картинка.
- Указать язык страницы, используя атрибут lang на теге <html>.
- Правильно указывать название страницы, то есть тег <title>, он должен быть уникален для каждой страницы и быть длиною до 55 символов, помимо этого значение тега должно отличаться от значения от тега <h1>.
- Использовать мета-тег description: тут пишется описание страницы, на каждую страницу оно должно быть уникальным и длиною до 150 символов.
- Подключить favicon и иконки для Apple Web Meta, Windows Tiles и прочие иконки
- Настроить и добавить OG-теги, то есть Open Graph теги: og:type, og:title, og:site_name, og:description, og:image, og:url, og:error для социальных сетей.
- Удалить комментарии в HTML, это в целом считается хорошей практикой, заливать сайт на продакшн без комментариев в коде/разметке.
- Подключать стили и скрипты и сторонние библиотеки и прочие не блокируя отрисовку сайта, можно использовать асинхронную загрузку сайта <script async src="...">.
- Обязательно иметь страницу ошибки 404.
Оптимизировать производительность сайта, производительность и доступность сайта очень важна для поисковых движков, для этого надо:
- Использовать как можно меньше узлов HTML, т.е. отказаться от лишних оберток в врестке.
- Оптимизировать картинки, кропать их до нужных размеров отображения и сжимать, лучше всего использовать формат webp, и fallback на jpg картники в браузерах, где не поддерживается формат webp. Помимо этого, если на странице много картинок, то лучше использовать ленивую загрузку картинок (lazy loading).
- Оптимизировать JS, удалить мертвый код, не использовать большие библиотеки, если из всей библиотеки вам нужен всего один или несколько методов. Писать код так, чтоб не было утечек памяти.
- Сжимать все файлы HTML, CSS, JS.
Если вы работаете над SSR(Server Side Rendered) приложениями, то не забыть про такие вещи как:
- robots.txt - это конфиг файл, при помощи которого мы можем указать, какие директории, страницы могут индексировать роботы/пауки.
- sitemap.xml - это файл, который хранит в себе все пути к страницам, он нужен для того, чтоб роботам/паукам было проще найти те или иные страницы у вас на сайте.
- Также, если вы пишите SSR или SPA приложение, то лучше хорошо подумать о том, как вы формируете навигацию(роутинг) в приложений. Навигация должна быть лаконичной, все вложенности должны быть сохранены, и соответствовать семантическим URL . К примеру, если у вас есть пользователь, и в личном кабинете пользователя есть страница "Мои оплаты", то стоит формировать навигацию, к примеру: https://example.com/profile/courses Где, https://example.com/ - хост, profile/ - роут до личного кабинета, courses/ - вложенная страница "Мои курсы"
Лучше с самого начала разработки думать о SEO оптимизации, как ни как, оно очень зависит от качества разработки, верстки и соблюдением мелочей, о которых легко забыть при разработке.
👉 @frontendInterview
Оптимизация сайта для SEO по большой части подразумевает то, что мы должны разработать сайт таким образом, чтоб роботы/пауки поискового движка могли легко понимать наш сайт.
Нам как фронтенд разработчикам для этого надо позаботиться о следующих вещах:
- Семантичная и структурированная верстка. На данный момент поисковики обращают внимание на семантику HTML, и если все на div-ах или таблицах, то сайт навряд ли попадет на первые строчки поискового запроса. Семантичная верстка наполняет смыслом теги, и структуры, которые мы создаем в HTML, и это облегчает роботам понимать где и что находится на странице нашего сайта.
- Правильно использовать и структурировать заголовки на страницах. У каждой страницы должен быть один и единственный тег <h1>, который считается основным заголовком и говорит о чем страница, далее должна соблюдаться вложенность заголовков, то есть h2, у вложенного в него элемента заголовок h3 и т.д.
- Никогда не забывать alt атрибут у тега <img>, таким образом мы объясняем роботам, что это за картинка.
- Указать язык страницы, используя атрибут lang на теге <html>.
- Правильно указывать название страницы, то есть тег <title>, он должен быть уникален для каждой страницы и быть длиною до 55 символов, помимо этого значение тега должно отличаться от значения от тега <h1>.
- Использовать мета-тег description: тут пишется описание страницы, на каждую страницу оно должно быть уникальным и длиною до 150 символов.
- Подключить favicon и иконки для Apple Web Meta, Windows Tiles и прочие иконки
- Настроить и добавить OG-теги, то есть Open Graph теги: og:type, og:title, og:site_name, og:description, og:image, og:url, og:error для социальных сетей.
- Удалить комментарии в HTML, это в целом считается хорошей практикой, заливать сайт на продакшн без комментариев в коде/разметке.
- Подключать стили и скрипты и сторонние библиотеки и прочие не блокируя отрисовку сайта, можно использовать асинхронную загрузку сайта <script async src="...">.
- Обязательно иметь страницу ошибки 404.
Оптимизировать производительность сайта, производительность и доступность сайта очень важна для поисковых движков, для этого надо:
- Использовать как можно меньше узлов HTML, т.е. отказаться от лишних оберток в врестке.
- Оптимизировать картинки, кропать их до нужных размеров отображения и сжимать, лучше всего использовать формат webp, и fallback на jpg картники в браузерах, где не поддерживается формат webp. Помимо этого, если на странице много картинок, то лучше использовать ленивую загрузку картинок (lazy loading).
- Оптимизировать JS, удалить мертвый код, не использовать большие библиотеки, если из всей библиотеки вам нужен всего один или несколько методов. Писать код так, чтоб не было утечек памяти.
- Сжимать все файлы HTML, CSS, JS.
Если вы работаете над SSR(Server Side Rendered) приложениями, то не забыть про такие вещи как:
- robots.txt - это конфиг файл, при помощи которого мы можем указать, какие директории, страницы могут индексировать роботы/пауки.
- sitemap.xml - это файл, который хранит в себе все пути к страницам, он нужен для того, чтоб роботам/паукам было проще найти те или иные страницы у вас на сайте.
- Также, если вы пишите SSR или SPA приложение, то лучше хорошо подумать о том, как вы формируете навигацию(роутинг) в приложений. Навигация должна быть лаконичной, все вложенности должны быть сохранены, и соответствовать семантическим URL . К примеру, если у вас есть пользователь, и в личном кабинете пользователя есть страница "Мои оплаты", то стоит формировать навигацию, к примеру: https://example.com/profile/courses Где, https://example.com/ - хост, profile/ - роут до личного кабинета, courses/ - вложенная страница "Мои курсы"
Лучше с самого начала разработки думать о SEO оптимизации, как ни как, оно очень зависит от качества разработки, верстки и соблюдением мелочей, о которых легко забыть при разработке.
👉 @frontendInterview
{kind=link}
👍4❤1
Сердце Фреймворка: Философия и Практика Dependency Injection в Angular
Эта статья не очередной пересказ официальной документации. Это глубокое погружение в архитектуру и философию Dependency Injection в Angular. Наша цель демистифицировать «магию» и превратить ее в предсказуемый, управляемый и мощный инженерный инструмент в вашем арсенале.
👉 @frontendInterview
Эта статья не очередной пересказ официальной документации. Это глубокое погружение в архитектуру и философию Dependency Injection в Angular. Наша цель демистифицировать «магию» и превратить ее в предсказуемый, управляемый и мощный инженерный инструмент в вашем арсенале.
👉 @frontendInterview
👍1
This media is not supported in your browser
VIEW IN TELEGRAM
Тимлид должен джуна похвалить и попросить больше ничего такого на работу не таскать
👉 @frontendInterview
👉 @frontendInterview
🔥8❤1
Почему нельзя отправлять в get запросах чувствительную информацию?
URL видны в истории браузера
GET-запросы отправляют данные через URL, который сохраняется в истории браузера. Это означает, что любой, кто имеет доступ к истории браузера, может увидеть эти данные.
Логи сервера
Многие веб-серверы и прокси-серверы автоматически записывают URL всех запросов в свои логи. Чувствительная информация в URL будет сохранена в этих логах и может быть доступна администраторам серверов или в случае компрометации системы.
Кэширование
Браузеры, прокси-серверы и промежуточные серверы могут кэшировать URL-адреса GET-запросов. Это означает, что чувствительная информация может быть сохранена в кэшах и доступна при последующих обращениях.
Ограничения длины URL
Большинство браузеров и серверов имеют ограничения на длину URL (обычно около 2000 символов). Если данные слишком длинные, они могут быть обрезаны, что приведет к потере информации или ошибкам при обработке запроса.
Видимость в реферере
Когда пользователь переходит по ссылке с одной страницы на другую, URL-адрес исходной страницы часто передается как заголовок Referer в HTTP-запросе. Это означает, что чувствительная информация в URL может быть передана сторонним сайтам.
HTTP-заголовки и GET-запросы
Данные в GET-запросах передаются через URL, в то время как данные в POST-запросах передаются в теле запроса. URL более подвержены утечке, так как они часто видны в различных местах (например, в журналах серверов, истории браузера и т.д.).
Использование POST-запросов в качестве альтернативы
Для отправки чувствительной информации лучше использовать POST-запросы, так как данные передаются в теле запроса и не сохраняются в URL.
👉 @frontendInterview
URL видны в истории браузера
GET-запросы отправляют данные через URL, который сохраняется в истории браузера. Это означает, что любой, кто имеет доступ к истории браузера, может увидеть эти данные.
Логи сервера
Многие веб-серверы и прокси-серверы автоматически записывают URL всех запросов в свои логи. Чувствительная информация в URL будет сохранена в этих логах и может быть доступна администраторам серверов или в случае компрометации системы.
Кэширование
Браузеры, прокси-серверы и промежуточные серверы могут кэшировать URL-адреса GET-запросов. Это означает, что чувствительная информация может быть сохранена в кэшах и доступна при последующих обращениях.
Ограничения длины URL
Большинство браузеров и серверов имеют ограничения на длину URL (обычно около 2000 символов). Если данные слишком длинные, они могут быть обрезаны, что приведет к потере информации или ошибкам при обработке запроса.
Видимость в реферере
Когда пользователь переходит по ссылке с одной страницы на другую, URL-адрес исходной страницы часто передается как заголовок Referer в HTTP-запросе. Это означает, что чувствительная информация в URL может быть передана сторонним сайтам.
HTTP-заголовки и GET-запросы
Данные в GET-запросах передаются через URL, в то время как данные в POST-запросах передаются в теле запроса. URL более подвержены утечке, так как они часто видны в различных местах (например, в журналах серверов, истории браузера и т.д.).
Использование POST-запросов в качестве альтернативы
Для отправки чувствительной информации лучше использовать POST-запросы, так как данные передаются в теле запроса и не сохраняются в URL.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Secure Form</title>
</head>
<body>
<form action="/submit" method="post">
<label for="username">Username:</label>
<input type="text" id="username" name="username">
<label for="password">Password:</label>
<input type="password" id="password" name="password">
<button type="submit">Submit</button>
</form>
</body>
</html>
👉 @frontendInterview
❤3👍2
Грокаем функциональное мышление
Кодовые базы разрастаются, становясь всё сложнее и запутаннее, что не может не пугать разработчиков. Как обнаружить код, изменяющий состояние вашей системы? Как сделать код таким, чтобы он не увеличивал сложность и запутанность кодовой базы?
Большую часть «действий», изменяющих состояние, можно превратить в «вычисления», чтобы ваш код стал проще и логичнее.
Вы научитесь бороться со сложными ошибками синхронизации, которые неизбежно проникают в асинхронный и многопоточный код, узнаете, как компонуемые абстракции предотвращают дублирование кода, и откроете для себя новые уровни его выразительности.
Книга предназначена для разработчиков среднего и высокого уровня, создающих сложный код. Примеры, иллюстрации, вопросы для самопроверки и практические задания помогут надежно закрепить новые знания.
👉 @frontendInterview
Кодовые базы разрастаются, становясь всё сложнее и запутаннее, что не может не пугать разработчиков. Как обнаружить код, изменяющий состояние вашей системы? Как сделать код таким, чтобы он не увеличивал сложность и запутанность кодовой базы?
Большую часть «действий», изменяющих состояние, можно превратить в «вычисления», чтобы ваш код стал проще и логичнее.
Вы научитесь бороться со сложными ошибками синхронизации, которые неизбежно проникают в асинхронный и многопоточный код, узнаете, как компонуемые абстракции предотвращают дублирование кода, и откроете для себя новые уровни его выразительности.
Книга предназначена для разработчиков среднего и высокого уровня, создающих сложный код. Примеры, иллюстрации, вопросы для самопроверки и практические задания помогут надежно закрепить новые знания.
👉 @frontendInterview