
{kind=link}
#medium
Задача: 71. Simplify Path
Дан абсолютный путь для файловой системы в стиле Unix, который начинается с символа '/'. Преобразуйте этот путь в его упрощенный канонический путь.
В контексте файловой системы Unix-style одинарная точка '.' обозначает текущий каталог, двойная точка '..' означает переход на один уровень каталога вверх, а несколько слэшей, таких как '//', интерпретируются как один слэш. В этой задаче последовательности точек, не охваченные предыдущими правилами (например, '...'), следует рассматривать как допустимые имена для файлов или каталогов.
Упрощенный канонический путь должен соответствовать следующим правилам:
Он должен начинаться с одного слэша '/'.
Каталоги в пути должны быть разделены только одним слэшем '/'.
Он не должен заканчиваться слэшем '/', если только это не корневой каталог.
Он должен исключать любые одинарные или двойные точки, используемые для обозначения текущих или родительских каталогов.
Верните новый путь.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируем стек S, который будет использоваться в нашей реализации. Разделяем входную строку, используя символ '/' в качестве разделителя. Этот шаг очень важен, поскольку входные данные всегда являются допустимым путем, и наша задача — лишь его сократить. Таким образом, все, что находится между двумя символами '/', является либо именем каталога, либо специальным символом, и мы должны соответственно обработать их.
2️⃣ Как только входной путь разделен, мы обрабатываем каждый компонент по отдельности. Если текущий компонент — это точка '.' или пустая строка, мы ничего не делаем и просто продолжаем. Если вспомнить, массив строк, полученный при разделении строки '/a//b', будет [a, , b], где между a и b находится пустая строка, что в контексте общего пути не имеет значения. Если мы сталкиваемся с двойной точкой '..', это означает, что нужно подняться на один уровень выше в текущем пути каталога. Поэтому мы удаляем запись из нашего стека, если он не пуст.
3️⃣ Наконец, если обрабатываемый нами в данный момент компонент не является одним из специальных символов, мы просто добавляем его в наш стек, так как это законное имя каталога. Как только все компоненты обработаны, нам просто нужно соединить все имена каталогов в нашем стеке, используя '/' в качестве разделителя, и мы получим самый короткий путь, который приведет нас в тот же каталог, что и предоставленный на входе.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 71. Simplify Path
Дан абсолютный путь для файловой системы в стиле Unix, который начинается с символа '/'. Преобразуйте этот путь в его упрощенный канонический путь.
В контексте файловой системы Unix-style одинарная точка '.' обозначает текущий каталог, двойная точка '..' означает переход на один уровень каталога вверх, а несколько слэшей, таких как '//', интерпретируются как один слэш. В этой задаче последовательности точек, не охваченные предыдущими правилами (например, '...'), следует рассматривать как допустимые имена для файлов или каталогов.
Упрощенный канонический путь должен соответствовать следующим правилам:
Он должен начинаться с одного слэша '/'.
Каталоги в пути должны быть разделены только одним слэшем '/'.
Он не должен заканчиваться слэшем '/', если только это не корневой каталог.
Он должен исключать любые одинарные или двойные точки, используемые для обозначения текущих или родительских каталогов.
Верните новый путь.
Пример:
Input: path = "/home/"
Output: "/home"
Explanation:
The trailing slash should be removed.
func simplifyPath(path string) string {
portions := strings.Split(path, "/")
stack := []string{}
for _, portion := range portions {
if portion == ".." {
if len(stack) > 0 {
stack = stack[:len(stack)-1]
}
} else if portion != "." && len(portion) > 0 {
stack = append(stack, portion)
}
}
return "/" + strings.Join(stack, "/")
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 72. Edit Distance
Даны два слова word1 и word2. Верните минимальное количество операций, необходимых для преобразования word1 в word2.
Доступны следующие три операции над словом:
Вставить символ.
Удалить символ.
Заменить символ.
Пример:
👨💻 Алгоритм:
1️⃣ Подход динамического программирования с верху вниз реализуется путем добавления кэширования в рекурсивные вызовы функций. Например, в рекурсивном вызове будут следующие параметры: word1 = abc, word2 = ad, word1Index = 2 (с индексацией от нуля) и word2Index = 1 (с индексацией от нуля).
2️⃣ Для кэширования результата данной подзадачи необходимо использовать структуру данных, которая хранит результат для word1, заканчивающегося на индексе word1Index, то есть 2, и word2, заканчивающегося на word2Index, то есть 1. Один из возможных способов реализации - использование двумерного массива, например, memo, где memo[word1Index][word2Index] кэширует результат для word1, заканчивающегося на word1Index, и word2, заканчивающегося на word2Index.
3️⃣ Индексы word1Index и word2Index указывают на текущие символы строк word1 и word2 соответственно. Алгоритм реализуется по следующей схеме: перед вычислением результата подзадачи проверяется, не сохранен ли он уже в memo[word1Index][word2Index]. Если да, то возвращается сохраненный результат. После вычисления результата каждой подзадачи результат сохраняется в memo для будущего использования.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 72. Edit Distance
Даны два слова word1 и word2. Верните минимальное количество операций, необходимых для преобразования word1 в word2.
Доступны следующие три операции над словом:
Вставить символ.
Удалить символ.
Заменить символ.
Пример:
Input: word1 = "horse", word2 = "ros"
Output: 3
Explanation:
horse -> rorse (replace 'h' with 'r')
rorse -> rose (remove 'r')
rose -> ros (remove 'e')
func minDistance(word1 string, word2 string) int {
memo := make([][]int, len(word1)+1)
for i := range memo {
memo[i] = make([]int, len(word2)+1)
for j := range memo[i] {
memo[i][j] = -1
}
}
min := func(a, b, c int) int {
if a < b {
if a < c {
return a
}
return c
}
if b < c {
return b
}
return c
}
var minDistanceRecur func(word1, word2 string, word1Index, word2Index int) int
minDistanceRecur = func(word1, word2 string, word1Index, word2Index int) int {
if word1Index == 0 {
return word2Index
}
if word2Index == 0 {
return word1Index
}
if memo[word1Index][word2Index] != -1 {
return memo[word1Index][word2Index]
}
var minEditDistance int
if word1[word1Index-1] == word2[word2Index-1] {
minEditDistance = minDistanceRecur(
word1,
word2,
word1Index-1,
word2Index-1,
)
} else {
insertOperation := minDistanceRecur(word1, word2, word1Index, word2Index-1)
deleteOperation := minDistanceRecur(word1, word2, word1Index-1, word2Index)
replaceOperation := minDistanceRecur(word1, word2, word1Index-1, word2Index-1)
minEditDistance = min(insertOperation, deleteOperation, replaceOperation) + 1
}
memo[word1Index][word2Index] = minEditDistance
return minEditDistance
}
return minDistanceRecur(word1, word2, len(word1), len(word2))
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 73. Set Matrix Zeroes
Дана матрица размером m×n, состоящая из целых чисел. Если элемент матрицы равен 0, установите в 0 все элементы его строки и столбца.
Необходимо выполнить это действие на месте, не используя дополнительное пространство для другой матрицы.
Пример:
👨💻 Алгоритм:
1️⃣ Мы перебираем матрицу и отмечаем первую ячейку строки i и первую ячейку столбца j, если условие в приведенном выше псевдокоде выполняется, т.е. если cell[i][j] == 0.
2️⃣ Первая ячейка строки и столбца для первой строки и первого столбца совпадают, т.е. cell[0][0]. Поэтому мы используем дополнительную переменную, чтобы узнать, был ли отмечен первый столбец, а cell[0][0] используется для того же для первой строки.
3️⃣ Теперь мы перебираем исходную матрицу, начиная со второй строки и второго столбца, т.е. с matrix[1][1]. Для каждой ячейки мы проверяем, были ли ранее отмечены строка r или столбец c, проверяя соответствующую первую ячейку строки или первую ячейку столбца. Если любая из них была отмечена, мы устанавливаем значение в ячейке на 0. Обратите внимание, что первая строка и первый столбец служат как row_set и column_set, которые мы использовали в первом подходе. Затем мы проверяем, равна ли cell[0][0] нулю, если это так, мы отмечаем первую строку как ноль. И, наконец, если первый столбец был отмечен, мы делаем все записи в нем нулевыми.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 73. Set Matrix Zeroes
Дана матрица размером m×n, состоящая из целых чисел. Если элемент матрицы равен 0, установите в 0 все элементы его строки и столбца.
Необходимо выполнить это действие на месте, не используя дополнительное пространство для другой матрицы.
Пример:
Input: matrix = [[1,1,1],[1,0,1],[1,1,1]]
Output: [[1,0,1],[0,0,0],[1,0,1]]
func setZeroes(matrix [][]int) {
isCol := false
R := len(matrix)
C := len(matrix[0])
for i := 0; i < R; i++ {
if matrix[i][0] == 0 {
isCol = true
}
for j := 1; j < C; j++ {
if matrix[i][j] == 0 {
matrix[0][j] = 0
matrix[i][0] = 0
}
}
}
for i := 1; i < R; i++ {
for j := 1; j < C; j++ {
if matrix[i][0] == 0 || matrix[0][j] == 0 {
matrix[i][j] = 0
}
}
}
if matrix[0][0] == 0 {
for j := 0; j < C; j++ {
matrix[0][j] = 0
}
}
if isCol {
for i := 0; i < R; i++ {
matrix[i][0] = 0
}
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 74. Search a 2D Matrix
Вам дана матрица из целых чисел размером m на n с следующими двумя свойствами:
Каждая строка отсортирована в порядке неубывания.
Первое число каждой строки больше последнего числа предыдущей строки.
Дано целое число target. Верните true, если target присутствует в матрице, и false в противном случае.
Вы должны написать решение с временной сложностью O(log(m * n)).
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте индексы слева и справа: left = 0 и right = m x n - 1.
2️⃣ Пока left <= right:
Выберите индекс посередине виртуального массива в качестве опорного индекса: pivot_idx = (left + right) / 2.
3️⃣ Индекс соответствует row = pivot_idx // n и col = pivot_idx % n в исходной матрице, и, следовательно, можно получить pivot_element. Этот элемент делит виртуальный массив на две части.
Сравните pivot_element и target, чтобы определить, в какой части нужно искать target.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 74. Search a 2D Matrix
Вам дана матрица из целых чисел размером m на n с следующими двумя свойствами:
Каждая строка отсортирована в порядке неубывания.
Первое число каждой строки больше последнего числа предыдущей строки.
Дано целое число target. Верните true, если target присутствует в матрице, и false в противном случае.
Вы должны написать решение с временной сложностью O(log(m * n)).
Пример:
Input: matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
Output: true
Выберите индекс посередине виртуального массива в качестве опорного индекса: pivot_idx = (left + right) / 2.
Сравните pivot_element и target, чтобы определить, в какой части нужно искать target.
func searchMatrix(matrix [][]int, target int) bool {
m := len(matrix)
if m == 0 {
return false
}
n := len(matrix[0])
left, right := 0, m*n-1
var pivotIdx, pivotElement int
for left <= right {
pivotIdx = (left + right) / 2
pivotElement = matrix[pivotIdx/n][pivotIdx%n]
if target == pivotElement {
return true
} else {
if target < pivotElement {
right = pivotIdx - 1
} else {
left = pivotIdx + 1
}
}
}
return false
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍1🤔1
{kind=link}
#medium
Задача: 75. Sort Colors
Дан массив nums, содержащий n объектов, окрашенных в красный, белый или синий цвет. Отсортируйте их на месте так, чтобы объекты одного цвета находились рядом, а цвета располагались в порядке красный, белый и синий.
Мы будем использовать целые числа 0, 1 и 2 для обозначения красного, белого и синего цветов соответственно.
Вы должны решить эту задачу без использования функции сортировки библиотеки.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация крайней правой границы нулей: p0 = 0. Во время выполнения алгоритма nums[idx < p0] = 0.
2️⃣ Инициализация крайней левой границы двоек: p2 = n - 1. Во время выполнения алгоритма nums[idx > p2] = 2.
3️⃣ Инициализация индекса текущего элемента для рассмотрения: curr = 0.
Пока curr <= p2:
Если nums[curr] = 0: поменять местами элементы с индексами curr и p0, и сдвинуть оба указателя вправо.
Если nums[curr] = 2: поменять местами элементы с индексами curr и p2. Сдвинуть указатель p2 влево.
Если nums[curr] = 1: сдвинуть указатель curr вправо.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 75. Sort Colors
Дан массив nums, содержащий n объектов, окрашенных в красный, белый или синий цвет. Отсортируйте их на месте так, чтобы объекты одного цвета находились рядом, а цвета располагались в порядке красный, белый и синий.
Мы будем использовать целые числа 0, 1 и 2 для обозначения красного, белого и синего цветов соответственно.
Вы должны решить эту задачу без использования функции сортировки библиотеки.
Пример:
Input: nums = [2,0,2,1,1,0]
Output: [0,0,1,1,2,2]
Пока curr <= p2:
Если nums[curr] = 0: поменять местами элементы с индексами curr и p0, и сдвинуть оба указателя вправо.
Если nums[curr] = 2: поменять местами элементы с индексами curr и p2. Сдвинуть указатель p2 влево.
Если nums[curr] = 1: сдвинуть указатель curr вправо.
func sortColors(nums []int) {
p0, curr := 0, 0
p2 := len(nums) - 1
for curr <= p2 {
if nums[curr] == 0 {
nums[curr], nums[p0] = nums[p0], nums[curr]
curr++
p0++
} else if nums[curr] == 2 {
nums[curr], nums[p2] = nums[p2], nums[curr]
p2--
} else {
curr++
}
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍1🤔1
{kind=link}
#hard
Задача: 76. Minimum Window Substring
Даны две строки s и t длиной m и n соответственно. Верните наименьшую подстроку строки s так, чтобы каждый символ из строки t (включая дубликаты) входил в эту подстроку. Если такой подстроки не существует, верните пустую строку "".
Тестовые примеры будут сформированы таким образом, что ответ будет уникальным.
Пример:
👨💻 Алгоритм:
1️⃣ Мы начинаем с двух указателей, left и right, которые изначально указывают на первый элемент строки S.
2️⃣ Мы используем указатель right для расширения окна до тех пор, пока не получим желаемое окно, т.е. окно, которое содержит все символы из T.
3️⃣ Как только у нас есть окно со всеми символами, мы можем передвигать указатель left вперёд по одному. Если окно по-прежнему желаемое, мы продолжаем обновлять размер минимального окна. Если окно больше не желаемое, мы повторяем шаг 2 и далее.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 76. Minimum Window Substring
Даны две строки s и t длиной m и n соответственно. Верните наименьшую подстроку строки s так, чтобы каждый символ из строки t (включая дубликаты) входил в эту подстроку. Если такой подстроки не существует, верните пустую строку "".
Тестовые примеры будут сформированы таким образом, что ответ будет уникальным.
Пример:
Input: s = "ADOBECODEBANC", t = "ABC"
Output: "BANC"
Explanation: The minimum window substring "BANC" includes 'A', 'B', and 'C' from string t.
func minWindow(s string, t string) string {
if len(s) == 0 || len(t) == 0 {
return ""
}
dictT := make(map[rune]int)
for _, c := range t {
dictT[c]++
}
required := len(dictT)
l, r := 0, 0
formed := 0
windowCounts := make(map[rune]int)
ans := []int{-1, 0, 0}
for r < len(s) {
c := rune(s[r])
windowCounts[c]++
if _, ok := dictT[c]; ok && windowCounts[c] == dictT[c] {
formed++
}
for l <= r && formed == required {
c = rune(s[l])
if ans[0] == -1 || r-l+1 < ans[0] {
ans[0] = r - l + 1
ans[1] = l
ans[2] = r
}
windowCounts[c]--
if _, ok := dictT[c]; ok && windowCounts[c] < dictT[c] {
formed--
}
l++
}
r++
}
if ans[0] == -1 {
return ""
}
return s[ans[1] : ans[2]+1]
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 77. Combinations
Даны два целых числа n и k. Верните все возможные комбинации из k чисел, выбранных из диапазона [1, n].
Ответ можно вернуть в любом порядке.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализировать массив ответов ans и массив для построения комбинаций curr.
2️⃣ Создать функцию обратного вызова backtrack, которая принимает curr в качестве аргумента, а также целое число firstNum:
Если длина curr равна k, добавить копию curr в ans и вернуться.
Вычислить available, количество чисел, которые мы можем рассмотреть в текущем узле.
Итерировать num от firstNum до firstNum + available включительно.
Для каждого num, добавить его в curr, вызвать backtrack(curr, num + 1), а затем удалить num из curr.
3️⃣ Вызвать backtrack с изначально пустым curr и firstNum = 1.
Вернуть ans.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 77. Combinations
Даны два целых числа n и k. Верните все возможные комбинации из k чисел, выбранных из диапазона [1, n].
Ответ можно вернуть в любом порядке.
Пример:
Input: n = 4, k = 2
Output: [[1,2],[1,3],[1,4],[2,3],[2,4],[3,4]]
Explanation: There are 4 choose 2 = 6 total combinations.
Note that combinations are unordered, i.e., [1,2] and [2,1] are considered to be the same combination.
Если длина curr равна k, добавить копию curr в ans и вернуться.
Вычислить available, количество чисел, которые мы можем рассмотреть в текущем узле.
Итерировать num от firstNum до firstNum + available включительно.
Для каждого num, добавить его в curr, вызвать backtrack(curr, num + 1), а затем удалить num из curr.
Вернуть ans.
func combine(n int, k int) [][]int {
var ans [][]int
var curr []int
var backtrack func(int)
backtrack = func(firstNum int) {
if len(curr) == k {
ans = append(ans, append([]int{}, curr...))
return
}
need := k - len(curr)
remain := n - firstNum + 1
available := remain - need
for num := firstNum; num <= firstNum+available; num++ {
curr = append(curr, num)
backtrack(num + 1)
curr = curr[:len(curr)-1]
}
}
backtrack(1)
return ans
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 78. Subsets
Дан массив целых чисел nums, содержащий уникальные элементы. Верните все возможные подмножества (степенной набор).
Множество решений не должно содержать дублирующихся подмножеств. Результат может быть возвращен в любом порядке.
Пример:
👨💻 Алгоритм:
1️⃣ Определяем функцию обратного отслеживания под названием backtrack(first, curr), которая принимает индекс первого элемента, который нужно добавить, и текущую комбинацию в качестве аргументов.
2️⃣ Если текущая комбинация завершена, мы добавляем её в итоговый вывод.
3️⃣ В противном случае перебираем индексы i от first до длины всей последовательности n, добавляем элемент nums[i] в текущую комбинацию curr, продолжаем добавлять больше чисел в комбинацию: backtrack(i + 1, curr) и возвращаемся, удаляя nums[i] из curr.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 78. Subsets
Дан массив целых чисел nums, содержащий уникальные элементы. Верните все возможные подмножества (степенной набор).
Множество решений не должно содержать дублирующихся подмножеств. Результат может быть возвращен в любом порядке.
Пример:
Input: nums = [1,2,3]
Output: [[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
func subsets(nums []int) [][]int {
n := len(nums)
var output [][]int
var curr []int
var backtrack func(int, int)
backtrack = func(first int, k int) {
if len(curr) == k {
output = append(output, append([]int(nil), curr...))
return
}
for i := first; i < n; i++ {
curr = append(curr, nums[i])
backtrack(i+1, k)
curr = curr[:len(curr)-1]
}
}
for k := 0; k < n+1; k++ {
backtrack(0, k)
}
return output
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 79. Word Search
Дана сетка символов размером m на n, называемая board, и строка word. Верните true, если слово word существует в сетке.
Слово можно составить из букв последовательно смежных ячеек, где смежные ячейки находятся рядом по горизонтали или вертикали. Одна и та же ячейка с буквой не может быть использована более одного раза.
Пример:
👨💻 Алгоритм:
1️⃣ Общий подход к алгоритмам обратной трассировки: В каждом алгоритме обратной трассировки существует определенный шаблон кода. Например, один из таких шаблонов можно найти в нашем разделе "Рекурсия II". Скелет алгоритма представляет собой цикл, который проходит через каждую ячейку в сетке. Для каждой ячейки вызывается функция обратной трассировки (backtrack()), чтобы проверить, можно ли найти решение, начиная с этой ячейки.
2️⃣ Функция обратной трассировки: Эта функция, реализуемая как алгоритм поиска в глубину (DFS), часто представляет собой рекурсивную функцию. Первым делом проверяется, достигнут ли базовый случай рекурсии, когда слово для сопоставления пусто, то есть для каждого префикса слова уже найдено совпадение. Затем проверяется, не является ли текущее состояние недопустимым: либо позиция ячейки выходит за границы доски, либо буква в текущей ячейке не совпадает с первой буквой слова.
3️⃣ Исследование и завершение: Если текущий шаг допустим, начинается исследование с использованием стратегии DFS. Сначала текущая ячейка помечается как посещенная, например, любой неалфавитный символ подойдет. Затем осуществляется итерация через четыре возможных направления: вверх, вправо, вниз и влево. Порядок направлений может быть изменен по предпочтениям пользователя. В конце исследования ячейка возвращается к своему исходному состоянию, и возвращается результат исследования.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 79. Word Search
Дана сетка символов размером m на n, называемая board, и строка word. Верните true, если слово word существует в сетке.
Слово можно составить из букв последовательно смежных ячеек, где смежные ячейки находятся рядом по горизонтали или вертикали. Одна и та же ячейка с буквой не может быть использована более одного раза.
Пример:
Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
Output: true
func exist(board [][]byte, word string) bool {
rows := len(board)
if rows == 0 {
return false
}
cols := len(board[0])
var backtrack func(row int, col int, index int) bool
backtrack = func(row int, col int, index int) bool {
if index == len(word) {
return true
}
if row < 0 || row >= rows || col < 0 || col >= cols ||
board[row][col] != word[index] {
return false
}
ret := false
temp := board[row][col]
board[row][col] = '#'
rowOffsets := []int{0, 1, 0, -1}
colOffsets := []int{1, 0, -1, 0}
for d := 0; d < 4; d++ {
ret = backtrack(row+rowOffsets[d], col+colOffsets[d], index+1)
if ret {
break
}
}
board[row][col] = temp
return ret
}
for row := 0; row < rows; row++ {
for col := 0; col < cols; col++ {
if board[row][col] == word[0] && backtrack(row, col, 0) {
return true
}
}
}
return false
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 80. Remove Duplicates from Sorted Array II
Дан массив целых чисел nums, отсортированный в неубывающем порядке. Удалите из него некоторые дубликаты на месте так, чтобы каждый уникальный элемент встречался не более двух раз. Относительный порядок элементов должен быть сохранён.
Поскольку в некоторых языках программирования невозможно изменить длину массива, результат следует разместить в первой части массива nums. Более формально, если после удаления дубликатов остаётся k элементов, то первые k элементов массива nums должны содержать итоговый результат. Не важно, что остаётся за пределами первых k элементов.
Верните k после размещения итогового результата в первые k слотов массива nums.
Не выделяйте дополнительное пространство для другого массива. Вы должны сделать это, изменяя исходный массив на месте с использованием дополнительной памяти O(1).
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация переменных: Используйте две переменные: i, которая указывает на текущий индекс в массиве, и count, которая отслеживает количество каждого элемента. Начните обработку массива с первого элемента (индекс 1), предполагая, что первый элемент всегда имеет count равный 1.
2️⃣ Обработка элементов массива: Для каждого элемента в массиве:
3️⃣ Если текущий элемент такой же, как предыдущий (nums[i] == nums[i - 1]), увеличьте count.
Если count больше 2, это означает, что текущий элемент встречается более двух раз. В этом случае удалите этот элемент из массива с помощью операции удаления, поддерживаемой вашим языком программирования (например, del, pop, remove), и уменьшите индекс i на 1, чтобы корректно обработать следующий элемент.
Если текущий элемент отличается от предыдущего (nums[i] != nums[i - 1]), это означает начало новой последовательности, поэтому сбросьте count к 1.
Возвращение результата: После обработки всех элементов в массиве, все ненужные дубликаты удалены, и в массиве остаются только допустимые элементы. Верните длину обработанного массива, так как это количество элементов, которые теперь соответствуют условиям задачи.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 80. Remove Duplicates from Sorted Array II
Дан массив целых чисел nums, отсортированный в неубывающем порядке. Удалите из него некоторые дубликаты на месте так, чтобы каждый уникальный элемент встречался не более двух раз. Относительный порядок элементов должен быть сохранён.
Поскольку в некоторых языках программирования невозможно изменить длину массива, результат следует разместить в первой части массива nums. Более формально, если после удаления дубликатов остаётся k элементов, то первые k элементов массива nums должны содержать итоговый результат. Не важно, что остаётся за пределами первых k элементов.
Верните k после размещения итогового результата в первые k слотов массива nums.
Не выделяйте дополнительное пространство для другого массива. Вы должны сделать это, изменяя исходный массив на месте с использованием дополнительной памяти O(1).
Пример:
Input: nums = [1,1,1,2,2,3]
Output: 5, nums = [1,1,2,2,3,_]
Explanation: Your function should return k = 5, with the first five elements of nums being 1, 1, 2, 2 and 3 respectively.
It does not matter what you leave beyond the returned k (hence they are underscores).
Если count больше 2, это означает, что текущий элемент встречается более двух раз. В этом случае удалите этот элемент из массива с помощью операции удаления, поддерживаемой вашим языком программирования (например, del, pop, remove), и уменьшите индекс i на 1, чтобы корректно обработать следующий элемент.
Если текущий элемент отличается от предыдущего (nums[i] != nums[i - 1]), это означает начало новой последовательности, поэтому сбросьте count к 1.
Возвращение результата: После обработки всех элементов в массиве, все ненужные дубликаты удалены, и в массиве остаются только допустимые элементы. Верните длину обработанного массива, так как это количество элементов, которые теперь соответствуют условиям задачи.
func removeDuplicates(nums []int) int {
j := 0
for i := 0; i < len(nums); i++ {
if j < 2 || nums[i] > nums[j-2] {
nums[j] = nums[i]
j++
}
}
return j
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 81. Search in Rotated Sorted Array II
В массиве целых чисел nums, отсортированном в неубывающем порядке (не обязательно содержащем уникальные значения), произведена ротация в неизвестном индексе поворота k (0 <= k < nums.length). В результате массив принимает вид [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]] (нумерация с 0). Например, массив [0,1,2,4,4,4,5,6,6,7] может быть повернут в индексе 5 и превратиться в [4,5,6,6,7,0,1,2,4,4].
Для данного массива nums после ротации и целого числа target необходимо вернуть true, если target присутствует в nums, и false в противном случае.
Необходимо сократить количество операций поиска настолько, насколько это возможно.
Пример:
👨💻 Алгоритм:
1️⃣ Вспомним стандартный бинарный поиск, где мы используем два указателя (start и end), чтобы отслеживать область поиска в массиве arr. Затем мы делим пространство поиска на три части: [start, mid), [mid, mid], (mid, end]. Далее мы продолжаем искать наш целевой элемент в одной из этих зон поиска.
2️⃣ Определяя положение arr[mid] и target в двух частях массива F и S, мы можем сократить область поиска так же, как в стандартном бинарном поиске:
Случай 1: arr[mid] находится в F, target в S: так как S начинается после окончания F, мы знаем, что элемент находится здесь: (mid, end].
Случай 2: arr[mid] находится в S, target в F: аналогично, мы знаем, что элемент находится здесь: [start, mid).
Случай 3: Оба arr[mid] и target находятся в F: поскольку оба они находятся в той же отсортированной части массива, мы можем сравнить arr[mid] и target, чтобы решить, как сократить область поиска.
Случай 4: Оба arr[mid] и target находятся в S: так как оба они в той же отсортированной части массива, мы также можем сравнить их для решения о сокращении области поиска.
3️⃣ Однако, если arr[mid] равен arr[start], то мы знаем, что arr[mid] может принадлежать и F, и S, и поэтому мы не можем определить относительное положение target относительно mid. В этом случае у нас нет другого выбора, кроме как перейти к следующей области поиска итеративно. Таким образом, существуют области поиска, которые позволяют использовать бинарный поиск, и области, где это невозможно.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 81. Search in Rotated Sorted Array II
В массиве целых чисел nums, отсортированном в неубывающем порядке (не обязательно содержащем уникальные значения), произведена ротация в неизвестном индексе поворота k (0 <= k < nums.length). В результате массив принимает вид [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]] (нумерация с 0). Например, массив [0,1,2,4,4,4,5,6,6,7] может быть повернут в индексе 5 и превратиться в [4,5,6,6,7,0,1,2,4,4].
Для данного массива nums после ротации и целого числа target необходимо вернуть true, если target присутствует в nums, и false в противном случае.
Необходимо сократить количество операций поиска настолько, насколько это возможно.
Пример:
Input: nums = [2,5,6,0,0,1,2], target = 0
Output: true
Случай 1: arr[mid] находится в F, target в S: так как S начинается после окончания F, мы знаем, что элемент находится здесь: (mid, end].
Случай 2: arr[mid] находится в S, target в F: аналогично, мы знаем, что элемент находится здесь: [start, mid).
Случай 3: Оба arr[mid] и target находятся в F: поскольку оба они находятся в той же отсортированной части массива, мы можем сравнить arr[mid] и target, чтобы решить, как сократить область поиска.
Случай 4: Оба arr[mid] и target находятся в S: так как оба они в той же отсортированной части массива, мы также можем сравнить их для решения о сокращении области поиска.
func search(nums []int, target int) bool {
n := len(nums)
if n == 0 {
return false
}
end := n - 1
start := 0
for start <= end {
mid := start + (end-start)/2
if nums[mid] == target {
return true
}
if !isBinarySearchHelpful(nums, start, nums[mid]) {
start++
continue
}
pivotArray := existsInFirst(nums, start, nums[mid])
targetArray := existsInFirst(nums, start, target)
if pivotArray != targetArray {
if pivotArray {
start = mid + 1
} else {
end = mid - 1
}
} else {
if nums[mid] < target {
start = mid + 1
} else {
end = mid - 1
}
}
}
return false
}
func isBinarySearchHelpful(nums []int, start int, element int) bool {
return nums[start] != element
}
func existsInFirst(nums []int, start int, element int) bool {
return nums[start] <= element
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 82. Remove Duplicates from Sorted List II
Дана голова отсортированного связного списка. Удалите все узлы, содержащие повторяющиеся числа, оставив только уникальные числа из исходного списка. Верните отсортированный связный список.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация "стража" и предшественника:
Создается фиктивный начальный узел sentinel, который указывает на начало связного списка. Это делается для удобства управления указателем на начало списка, особенно если первые несколько узлов могут быть удалены.
Устанавливаем предшественника pred, который будет последним узлом перед потенциально дублирующимися узлами. Изначально предшественником назначается страж.
2️⃣ Проход по списку с проверкой на дубликаты:
Итерируемся по списку начиная с головы head. На каждом шаге проверяем, есть ли дублирующиеся узлы, сравнивая текущий узел head.val с следующим head.next.val.
Если узлы дублируются, то пропускаем все последующие дубликаты, перемещая указатель head до последнего дублированного узла. После этого предшественник pred соединяется с первым узлом после всех дубликатов pred.next = head.next, тем самым пропуская весь блок дублированных узлов.
3️⃣ Переход к следующему узлу и возврат результата:
Если текущий узел не имел дубликатов, просто переводим предшественника pred на следующий узел.
Двигаем указатель head на следующий узел в списке.
После завершения цикла возвращаем список, начиная с узла, на который указывает sentinel.next, что позволяет исключить все дублирующиеся узлы и вернуть начало нового списка без дубликатов.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 82. Remove Duplicates from Sorted List II
Дана голова отсортированного связного списка. Удалите все узлы, содержащие повторяющиеся числа, оставив только уникальные числа из исходного списка. Верните отсортированный связный список.
Пример:
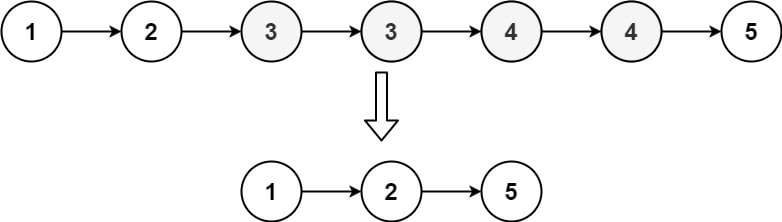
Input: head = [1,2,3,3,4,4,5]
Output: [1,2,5]
Создается фиктивный начальный узел sentinel, который указывает на начало связного списка. Это делается для удобства управления указателем на начало списка, особенно если первые несколько узлов могут быть удалены.
Устанавливаем предшественника pred, который будет последним узлом перед потенциально дублирующимися узлами. Изначально предшественником назначается страж.
Итерируемся по списку начиная с головы head. На каждом шаге проверяем, есть ли дублирующиеся узлы, сравнивая текущий узел head.val с следующим head.next.val.
Если узлы дублируются, то пропускаем все последующие дубликаты, перемещая указатель head до последнего дублированного узла. После этого предшественник pred соединяется с первым узлом после всех дубликатов pred.next = head.next, тем самым пропуская весь блок дублированных узлов.
Если текущий узел не имел дубликатов, просто переводим предшественника pred на следующий узел.
Двигаем указатель head на следующий узел в списке.
После завершения цикла возвращаем список, начиная с узла, на который указывает sentinel.next, что позволяет исключить все дублирующиеся узлы и вернуть начало нового списка без дубликатов.
func deleteDuplicates(head *ListNode) *ListNode {
sentinel := &ListNode{0, head}
pred := sentinel
for head != nil {
if head.Next != nil && head.Val == head.Next.Val {
for head.Next != nil && head.Val == head.Next.Val {
head = head.Next
}
pred.Next = head.Next
} else {
pred = pred.Next
}
head = head.Next
}
return sentinel.Next
}Please open Telegram to view this post
VIEW IN TELEGRAM
❤1🤔1
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#easy
Задача: 83. Remove Duplicates from Sorted List
Дана голова отсортированного связного списка. Удалите все дубликаты таким образом, чтобы каждый элемент появлялся только один раз. Верните также отсортированный связный список.
Пример:
👨💻 Алгоритм:
1️⃣ Это простая задача, которая проверяет вашу способность манипулировать указателями узлов списка. Поскольку входной список отсортирован, мы можем определить, является ли узел дубликатом, сравнив его значение с значением следующего узла в списке.
2️⃣ Если узел является дубликатом, мы изменяем указатель next текущего узла так, чтобы он пропускал следующий узел и напрямую указывал на узел, следующий за следующим.
3️⃣ Это позволяет исключить дубликаты из списка, продвигаясь вперёд по списку и корректируя связи между узлами для сохранения только уникальных элементов.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 83. Remove Duplicates from Sorted List
Дана голова отсортированного связного списка. Удалите все дубликаты таким образом, чтобы каждый элемент появлялся только один раз. Верните также отсортированный связный список.
Пример:
Input: head = [1,1,2]
Output: [1,2]
func deleteDuplicates(head *ListNode) *ListNode {
current := head
for current != nil && current.Next != nil {
if current.Next.Val == current.Val {
current.Next = current.Next.Next
} else {
current = current.Next
}
}
return head
}Please open Telegram to view this post
VIEW IN TELEGRAM
🔥2🤔1
{kind=link}
#hard
Задача: 84. Largest Rectangle in Histogram
Дан массив целых чисел heights, представляющий высоту столбцов гистограммы, где ширина каждого столбца равна 1. Верните площадь наибольшего прямоугольника в гистограмме.
Пример:
👨💻 Алгоритм:
1️⃣ Введение в проблему:
Прежде всего, следует учитывать, что высота прямоугольника, образованного между любыми двумя столбиками, всегда будет ограничена высотой самого низкого столбика, находящегося между ними. Это можно понять, взглянув на рисунок ниже.
2️⃣ Описание метода:
Таким образом, мы можем начать с рассмотрения каждой возможной пары столбиков и нахождения площади прямоугольника, образованного между ними, используя высоту самого низкого столбика между ними в качестве высоты и расстояние между ними в качестве ширины прямоугольника.
3️⃣ Вычисление максимальной площади:
Таким образом, мы можем найти требуемый прямоугольник с максимальной площадью.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 84. Largest Rectangle in Histogram
Дан массив целых чисел heights, представляющий высоту столбцов гистограммы, где ширина каждого столбца равна 1. Верните площадь наибольшего прямоугольника в гистограмме.
Пример:
Input: heights = [2,1,5,6,2,3]
Output: 10
Explanation: The above is a histogram where width of each bar is 1.
The largest rectangle is shown in the red area, which has an area = 10 units.
Прежде всего, следует учитывать, что высота прямоугольника, образованного между любыми двумя столбиками, всегда будет ограничена высотой самого низкого столбика, находящегося между ними. Это можно понять, взглянув на рисунок ниже.
Таким образом, мы можем начать с рассмотрения каждой возможной пары столбиков и нахождения площади прямоугольника, образованного между ними, используя высоту самого низкого столбика между ними в качестве высоты и расстояние между ними в качестве ширины прямоугольника.
Таким образом, мы можем найти требуемый прямоугольник с максимальной площадью.
func largestRectangleArea(heights []int) int {
max_area := 0
inf := int(^uint(0) >> 1)
for i := 0; i < len(heights); i++ {
for j := i; j < len(heights); j++ {
min_height := inf
for k := i; k <= j; k++ {
if heights[k] < min_height {
min_height = heights[k]
}
}
if min_height*(j-i+1) > max_area {
max_area = min_height * (j - i + 1)
}
}
}
return max_area
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍1🤔1
{kind=link}
#hard
Задача: 85. Maximal Rectangle
Дана бинарная матрица размером rows x cols, заполненная 0 и 1. Найдите наибольший прямоугольник, содержащий только 1, и верните его площадь.
Пример:
👨💻 Алгоритм:
1️⃣ Вычисление максимальной ширины прямоугольника для каждой координаты: Для каждой ячейки в каждой строке сохраняем количество последовательных единиц. При прохождении по строке обновляем максимально возможную ширину в этой точке, используя формулу row[i] = row[i - 1] + 1, если row[i] == '1'.
2️⃣ Определение максимальной площади прямоугольника с нижним правым углом в данной точке: При итерации вверх по столбцу максимальная ширина прямоугольника от исходной точки до текущей точки является минимальным значением среди всех максимальных ширин, с которыми мы сталкивались. Используем формулу maxWidth = min(maxWidth, widthHere) и curArea = maxWidth * (currentRow - originalRow + 1), затем обновляем maxArea = max(maxArea, curArea).
3️⃣ Применение алгоритма для каждой точки ввода для глобального максимума: Преобразуя входные данные в набор гистограмм, где каждый столбец является новой гистограммой, мы вычисляем максимальную площадь для каждой гистограммы.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 85. Maximal Rectangle
Дана бинарная матрица размером rows x cols, заполненная 0 и 1. Найдите наибольший прямоугольник, содержащий только 1, и верните его площадь.
Пример:
Input: matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
Output: 6
Explanation: The maximal rectangle is shown in the above picture.
func maximalRectangle(matrix [][]byte) int {
if len(matrix) == 0 {
return 0
}
maxarea := 0
dp := make([][]int, len(matrix))
for i := range dp {
dp[i] = make([]int, len(matrix[0]))
}
for i := 0; i < len(matrix); i++ {
for j := 0; j < len(matrix[0]); j++ {
if matrix[i][j] == '1' {
dp[i][j] = 1
if j != 0 {
dp[i][j] += dp[i][j-1]
}
width := dp[i][j]
for k := i; k >= 0; k-- {
width = min(width, dp[k][j])
maxarea = max(maxarea, width*(i-k+1))
}
}
}
}
return maxarea
}
func min(x, y int) int {
if x < y {
return x
}
return y
}
func max(x, y int) int {
if x > y {
return x
}
return y
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#hard
Задача: 87. Scramble String
Мы можем перемешать строку s, чтобы получить строку t, используя следующий алгоритм:
1. Если длина строки равна 1, остановиться.
2. Если длина строки больше 1, выполнить следующее:
- Разделить строку на две непустые подстроки в случайном индексе, например, если строка это s, разделить её на x и y, где s = x + y.
- Случайным образом решить, поменять ли местами две подстроки или оставить их в том же порядке. То есть после этого шага s может стать s = x + y или s = y + x.
- Применить шаг 1 рекурсивно к каждой из двух подстрок x и y.
Для двух строк s1 и s2 одинаковой длины вернуть true, если s2 является перемешанной строкой s1, в противном случае вернуть false.
Пример:
👨💻 Алгоритм:
1️⃣ - Итерируйте i от 0 до n-1.
- Итерируйте j от 0 до n-1.
- Установите dp[1][i][j] в булево значение s1[i] == s2[j]. (Базовый случай динамического программирования).
2️⃣ - Итерируйте length от 2 до n.
- Итерируйте i от 0 до n + 1 - length.
- Итерируйте j от 0 до n + 1 - length.
3️⃣ - Итерируйте newLength от 1 до length - 1.
- Если dp[newLength][i][j] && dp[length-newLength][i+newLength][j+newLength]) || (dp[newLength][i][j+length-newLength] && dp[length-newLength][i+newLength][j]) верно, установите dp[length][i][j] в true.
- Верните dp[n][0][0].
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 87. Scramble String
Мы можем перемешать строку s, чтобы получить строку t, используя следующий алгоритм:
1. Если длина строки равна 1, остановиться.
2. Если длина строки больше 1, выполнить следующее:
- Разделить строку на две непустые подстроки в случайном индексе, например, если строка это s, разделить её на x и y, где s = x + y.
- Случайным образом решить, поменять ли местами две подстроки или оставить их в том же порядке. То есть после этого шага s может стать s = x + y или s = y + x.
- Применить шаг 1 рекурсивно к каждой из двух подстрок x и y.
Для двух строк s1 и s2 одинаковой длины вернуть true, если s2 является перемешанной строкой s1, в противном случае вернуть false.
Пример:
Input: s1 = "great", s2 = "rgeat"
Output: true
Explanation: One possible scenario applied on s1 is:
"great" --> "gr/eat" // divide at random index.
"gr/eat" --> "gr/eat" // random decision is not to swap the two substrings and keep them in order.
"gr/eat" --> "g/r / e/at" // apply the same algorithm recursively on both substrings. divide at random index each of them.
"g/r / e/at" --> "r/g / e/at" // random decision was to swap the first substring and to keep the second substring in the same order.
"r/g / e/at" --> "r/g / e/ a/t" // again apply the algorithm recursively, divide "at" to "a/t".
"r/g / e/ a/t" --> "r/g / e/ a/t" // random decision is to keep both substrings in the same order.
The algorithm stops now, and the result string is "rgeat" which is s2.
As one possible scenario led s1 to be scrambled to s2, we return true.
- Итерируйте j от 0 до n-1.
- Установите dp[1][i][j] в булево значение s1[i] == s2[j]. (Базовый случай динамического программирования).
- Итерируйте i от 0 до n + 1 - length.
- Итерируйте j от 0 до n + 1 - length.
- Если dp[newLength][i][j] && dp[length-newLength][i+newLength][j+newLength]) || (dp[newLength][i][j+length-newLength] && dp[length-newLength][i+newLength][j]) верно, установите dp[length][i][j] в true.
- Верните dp[n][0][0].
func isScramble(s1 string, s2 string) bool {
n := len(s1)
dp := make([][][]bool, n+1)
for i := range dp {
dp[i] = make([][]bool, n)
for j := range dp[i] {
dp[i][j] = make([]bool, n)
}
}
for i := 0; i < n; i++ {
for j := 0; j < n; j++ {
dp[1][i][j] = s1[i] == s2[j]
}
}
for length := 2; length <= n; length++ {
for i := 0; i < n+1-length; i++ {
for j := 0; j < n+1-length; j++ {
for newLength := 1; newLength < length; newLength++ {
dp1 := dp[newLength][i]
dp2 := dp[length-newLength][i+newLength]
dp[length][i][j] = dp[length][i][j] ||
(dp1[j] && dp2[j+newLength])
dp[length][i][j] = dp[length][i][j] ||
(dp1[j+length-newLength] && dp2[j])
}
}
}
}
return dp[n][0][0]
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#easy
Задача: 88. Merge Sorted Array
Вам даны два массива целых чисел nums1 и nums2, отсортированных в порядке неубывания, а также два целых числа m и n, представляющих количество элементов в nums1 и nums2 соответственно.
Слейте nums1 и nums2 в один массив, отсортированный в порядке неубывания.
Итоговый отсортированный массив не должен возвращаться функцией, а должен храниться внутри массива nums1. Чтобы это обеспечить, длина nums1 составляет m + n, где первые m элементов обозначают элементы, которые должны быть объединены, а последние n элементов установлены в 0 и должны быть проигнорированы. Длина nums2 составляет n.
Пример:
👨💻 Алгоритм:
1️⃣ Самая простая реализация заключалась бы в создании копии значений в nums1, называемой nums1Copy, а затем использовании двух указателей для чтения и одного указателя для записи для чтения значений из nums1Copy и nums2 и записи их в nums1.
2️⃣ Инициализируйте nums1Copy новым массивом, содержащим первые m значений nums1.
Инициализируйте указатель для чтения p1 в начале nums1Copy.
Инициализируйте указатель для чтения p2 в начале nums2.
3️⃣ Инициализируйте указатель для записи p в начале nums1.
Пока p все еще находится внутри nums1:
Если nums1Copy[p1] существует и меньше или равно nums2[p2]:
Запишите nums1Copy[p1] в nums1[p], и увеличьте p1 на 1.
Иначе
Запишите nums2[p2] в nums1[p], и увеличьте p2 на 1.
Увеличьте p на 1.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 88. Merge Sorted Array
Вам даны два массива целых чисел nums1 и nums2, отсортированных в порядке неубывания, а также два целых числа m и n, представляющих количество элементов в nums1 и nums2 соответственно.
Слейте nums1 и nums2 в один массив, отсортированный в порядке неубывания.
Итоговый отсортированный массив не должен возвращаться функцией, а должен храниться внутри массива nums1. Чтобы это обеспечить, длина nums1 составляет m + n, где первые m элементов обозначают элементы, которые должны быть объединены, а последние n элементов установлены в 0 и должны быть проигнорированы. Длина nums2 составляет n.
Пример:
Input: nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
Output: [1,2,2,3,5,6]
Explanation: The arrays we are merging are [1,2,3] and [2,5,6].
The result of the merge is [1,2,2,3,5,6] with the underlined elements coming from nums1.
Инициализируйте указатель для чтения p1 в начале nums1Copy.
Инициализируйте указатель для чтения p2 в начале nums2.
Пока p все еще находится внутри nums1:
Если nums1Copy[p1] существует и меньше или равно nums2[p2]:
Запишите nums1Copy[p1] в nums1[p], и увеличьте p1 на 1.
Иначе
Запишите nums2[p2] в nums1[p], и увеличьте p2 на 1.
Увеличьте p на 1.
func merge(nums1 []int, m int, nums2 []int, n int) {
nums1Copy := append([]int(nil), nums1[:m]...)
p1 := 0
p2 := 0
for p := 0; p < m+n; p++ {
if p2 >= n || (p1 < m && nums1Copy[p1] < nums2[p2]) {
nums1[p] = nums1Copy[p1]
p1++
} else {
nums1[p] = nums2[p2]
p2++
}
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍1🔥1🤔1
{kind=link}
#medium
Задача: 89. Gray Code
Последовательность Грея с n-битами — это последовательность из 2^n целых чисел, где:
1. Каждое число находится в включающем диапазоне от 0 до 2^n - 1,
2. Первое число равно 0,
3. Каждое число встречается в последовательности не более одного раза,
4. Двоичное представление каждой пары соседних чисел отличается ровно на один бит,
5. Двоичное представление первого и последнего чисел отличается ровно на один бит.
Для заданного числа n возвращается любая допустимая последовательность Грея с n-битами.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте список результатов для хранения последовательности решений. Добавьте 0 в список перед вызовом вспомогательного метода, так как все последовательности Грея начинаются с 0.
2️⃣ Инициализируйте множество visited. Это позволяет отслеживать числа, присутствующие в текущей последовательности, чтобы избежать повторения.
Начните с числа 0.
В функции grayCodeHelper() используйте цикл for, чтобы найти каждое возможное число (next), которое может быть сгенерировано путем изменения одного бита последнего числа в списке результатов (current). Делайте это, переключая i-ый бит на каждой итерации. Поскольку максимально возможное количество битов в любом числе последовательности равно n, необходимо переключить n битов.
3️⃣ Если next не присутствует в множестве использованных чисел (isPresent), добавьте его в список результатов и множество isPresent.
Продолжайте поиск с next.
Если grayCodeHelper(next) возвращает true, это означает, что допустимая последовательность найдена. Дальнейший поиск не требуется (ранняя остановка). Это раннее завершение улучшает время выполнения.
Если с next не найдена допустимая последовательность, удаляем его из списка результатов и множества isPresent и продолжаем поиск.
При достижении базового условия, когда длина текущей последовательности равна 2^n, возвращаем true.
Выход из цикла for означает, что с current в качестве последнего числа не найдена допустимая последовательность кода Грея. Поэтому возвращаем false.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 89. Gray Code
Последовательность Грея с n-битами — это последовательность из 2^n целых чисел, где:
1. Каждое число находится в включающем диапазоне от 0 до 2^n - 1,
2. Первое число равно 0,
3. Каждое число встречается в последовательности не более одного раза,
4. Двоичное представление каждой пары соседних чисел отличается ровно на один бит,
5. Двоичное представление первого и последнего чисел отличается ровно на один бит.
Для заданного числа n возвращается любая допустимая последовательность Грея с n-битами.
Пример:
Input: n = 2
Output: [0,1,3,2]
Explanation:
The binary representation of [0,1,3,2] is [00,01,11,10].
- 00 and 01 differ by one bit
- 01 and 11 differ by one bit
- 11 and 10 differ by one bit
- 10 and 00 differ by one bit
[0,2,3,1] is also a valid gray code sequence, whose binary representation is [00,10,11,01].
- 00 and 10 differ by one bit
- 10 and 11 differ by one bit
- 11 and 01 differ by one bit
- 01 and 00 differ by one bit
Начните с числа 0.
В функции grayCodeHelper() используйте цикл for, чтобы найти каждое возможное число (next), которое может быть сгенерировано путем изменения одного бита последнего числа в списке результатов (current). Делайте это, переключая i-ый бит на каждой итерации. Поскольку максимально возможное количество битов в любом числе последовательности равно n, необходимо переключить n битов.
Продолжайте поиск с next.
Если grayCodeHelper(next) возвращает true, это означает, что допустимая последовательность найдена. Дальнейший поиск не требуется (ранняя остановка). Это раннее завершение улучшает время выполнения.
Если с next не найдена допустимая последовательность, удаляем его из списка результатов и множества isPresent и продолжаем поиск.
При достижении базового условия, когда длина текущей последовательности равна 2^n, возвращаем true.
Выход из цикла for означает, что с current в качестве последнего числа не найдена допустимая последовательность кода Грея. Поэтому возвращаем false.
func grayCode(n int) []int {
seen := map[int]bool{0: true}
res := []int{0}
var helper func(n int, seen map[int]bool) bool
helper = func(n int, seen map[int]bool) bool {
if len(res) == 1<<n {
return true
}
curr := res[len(res)-1]
for i := 0; i < n; i++ {
next := curr ^ (1 << i)
if seen[next] == false {
seen[next] = true
res = append(res, next)
if helper(n, seen) {
return true
}
seen[next] = false
res = res[:len(res)-1]
}
}
return false
}
helper(n, seen)
return res
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 90. Subsets II
Дан массив целых чисел nums, который может содержать повторяющиеся элементы. Верните все возможные подмножества (степенной набор).
Результирующий набор не должен содержать дублирующихся подмножеств. Возвращаемый результат может быть в любом порядке.
Пример:
👨💻 Алгоритм:
1️⃣ Отсортируйте массив nums. Сортировка необходима для того, чтобы все сгенерированные подмножества также были отсортированы. Это помогает идентифицировать дубликаты.
2️⃣ Инициализируйте maxNumberOfSubsets максимальным количеством подмножеств, которые можно сгенерировать, т.е., 2 в степени n.
Инициализируйте множество, seen, типа string, для хранения всех сгенерированных подмножеств. Добавление всех отсортированных подмножеств в множество дает нам возможность отловить любые дублирующие подмножества.
3️⃣ Итерируйте от 0 до maxNumberOfSubsets - 1. Установленные биты в двоичном представлении subsetIndex указывают на позицию элементов в массиве nums, которые присутствуют в текущем подмножестве.
Инициализируйте строку hashcode, которая будет хранить список чисел в текущемSubset в виде строки, разделенной запятыми. hashcode необходим для уникальной идентификации каждого подмножества с помощью множества.
Выполните внутренний цикл for от j = 0 до n - 1, чтобы проверить позицию установленных битов в subsetIndex. Если на позиции j установлен бит, добавьте nums[j] в текущее подмножество currentSubset и добавьте nums[j] в строку hashcode.
Добавьте текущее подмножество currentSubset в seen и в список подмножеств, если сгенерированный hashcode еще не в seen.
Верните подмножества.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 90. Subsets II
Дан массив целых чисел nums, который может содержать повторяющиеся элементы. Верните все возможные подмножества (степенной набор).
Результирующий набор не должен содержать дублирующихся подмножеств. Возвращаемый результат может быть в любом порядке.
Пример:
Input: nums = [1,2,2]
Output: [[],[1],[1,2],[1,2,2],[2],[2,2]]
Инициализируйте множество, seen, типа string, для хранения всех сгенерированных подмножеств. Добавление всех отсортированных подмножеств в множество дает нам возможность отловить любые дублирующие подмножества.
Инициализируйте строку hashcode, которая будет хранить список чисел в текущемSubset в виде строки, разделенной запятыми. hashcode необходим для уникальной идентификации каждого подмножества с помощью множества.
Выполните внутренний цикл for от j = 0 до n - 1, чтобы проверить позицию установленных битов в subsetIndex. Если на позиции j установлен бит, добавьте nums[j] в текущее подмножество currentSubset и добавьте nums[j] в строку hashcode.
Добавьте текущее подмножество currentSubset в seen и в список подмножеств, если сгенерированный hashcode еще не в seen.
Верните подмножества.
func subsetsWithDup(nums []int) [][]int {
n := len(nums)
sort.Ints(nums)
subsets := make([][]int, 0)
maxNumberOfSubsets := 1 << n
seen := make(map[string]bool)
for subsetIndex := 0; subsetIndex < maxNumberOfSubsets; subsetIndex++ {
currentSubset := make([]int, 0)
hashcode := ""
for j := 0; j < n; j++ {
mask := 1 << j
isSet := mask & subsetIndex
if isSet != 0 {
currentSubset = append(currentSubset, nums[j])
hashcode += strconv.Itoa(nums[j]) + ","
}
}
if _, ok := seen[hashcode]; !ok {
subsets = append(subsets, currentSubset)
seen[hashcode] = true
}
}
return subsets
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1