
Задача: 23. Merge k Sorted Lists #hard
Условие:
Решение:
Пояснение:
Этот код реализует алгоритм слияния k отсортированных связанных списков.
В этом коде определен тип pqueue, который представляет очередь с приоритетами, основанную на куче. Каждый элемент в очереди представляет узел списка и содержит значение этого узла.
Методы len, less, swap определены для работы с очередью. Методы push и pop добавляют и удаляют элементы из очереди соответственно. Метод peek возвращает элемент с наивысшим приоритетом (с наименьшим значением) в очереди.
Функция mergeklists принимает массив lists содержащий указатели на начало каждого отсортированного связанного списка. Алгоритм начинает слияние, добавляя все не пустые списки в приоритетную очередь. Затем в цикле извлекается узел с наименьшим значением из очереди и добавляется к результату слияния. Если узел имеет следующий элемент, он добавляется обратно в очередь. Этот процесс продолжается, пока очередь не станет пустой.
В конце функция возвращает указатель на первый элемент нового отсортированного связанного списка.
Использование стратегии слияния списков с помощью приоритетной очереди позволяет эффективно объединять множество уже отсортированных списков в один отсортированный список.
Условие:
Вам дан массив из k списков связанных списков, каждый связанный список отсортирован в порядке возрастания.
Объедините все связанные списки в один отсортированный связанный список и верните его.
Решение:
import "container/heap"
type PQueue []*ListNode
func (pq PQueue) Len() int {
return len(pq)
}
func (pq PQueue) Less(i, j int) bool {
return pq[i].Val < pq[j].Val
}
func (pq PQueue) Swap(i, j int) {
pq[i], pq[j] = pq[j], pq[i]
}
func (pq *PQueue) Push(x interface{}) {
item := x.(*ListNode)
*pq = append(*pq, item)
}
func (pq *PQueue) Pop() interface{} {
old := *pq
n := len(old)
item := old[n-1]
old[n-1] = nil
*pq = old[0 : n-1]
return item
}
func (pq *PQueue) Peek(x interface{}) *ListNode {
return (*pq)[len(*pq)-1]
}
func mergeKLists(lists []*ListNode) *ListNode {
top := &ListNode{
Val: -1,
}
merged := top
pq := PQueue{}
for _, l := range lists {
if l != nil {
pq = append(pq, l)
}
}
heap.Init(&pq)
for len(pq) > 0 {
merged.Next = heap.Pop(&pq).(*ListNode)
merged = merged.Next
if merged.Next != nil {
heap.Push(&pq, merged.Next)
}
}
return top.Next
}
Пояснение:
Этот код реализует алгоритм слияния k отсортированных связанных списков.
В этом коде определен тип pqueue, который представляет очередь с приоритетами, основанную на куче. Каждый элемент в очереди представляет узел списка и содержит значение этого узла.
Методы len, less, swap определены для работы с очередью. Методы push и pop добавляют и удаляют элементы из очереди соответственно. Метод peek возвращает элемент с наивысшим приоритетом (с наименьшим значением) в очереди.
Функция mergeklists принимает массив lists содержащий указатели на начало каждого отсортированного связанного списка. Алгоритм начинает слияние, добавляя все не пустые списки в приоритетную очередь. Затем в цикле извлекается узел с наименьшим значением из очереди и добавляется к результату слияния. Если узел имеет следующий элемент, он добавляется обратно в очередь. Этот процесс продолжается, пока очередь не станет пустой.
В конце функция возвращает указатель на первый элемент нового отсортированного связанного списка.
Использование стратегии слияния списков с помощью приоритетной очереди позволяет эффективно объединять множество уже отсортированных списков в один отсортированный список.
👍2❤1
Задача: 24. Swap Nodes in Pairs
#medium
Условие:
Решение:
Пояснение:
Конечно! Давайте разберем этот код подробнее:
Этот код представляет собой функцию `swapPairs`, которая меняет местами каждую пару соседних элементов в связанном списке.
1. Создается новый узел `newHead`, который инициализируется как исходный головной узел списка.
2. Устанавливается указатель `prev` на `newHead`, который будет использоваться для обновления связей между узлами списка.
3. Устанавливаются указатели `i` и `j` на начальный и следующий после него узлы соответственно.
4. Происходит проверка, если начальный узел `i` равен `nil` (конец списка), то возвращается исходный головной узел.
5. В цикле происходит обмен значениями между узлами:
- `prev.Next` указывает на `j` (следующий после `i`)
- `i.Next` указывает на `j.Next` (следующий после `j`)
- `j.Next` указывает на `i`
- Если `i.Next` равен `nil`, то прерывается цикл
- Обновляются указатели `prev`, `i`, `j` на следующие узлы
6. После завершения цикла возвращается головной узел списка, указываемый `newHead.Next`, который стал новым первым элементом после обмена.
Таким образом, функция `swapPairs` меняет местами каждую пару соседних узлов в связанном списке, используя указатели для изменения связей между узлами.
#medium
Условие:
Учитывая связанный список, поменяйте местами каждые два соседних узла и верните его голову. Вы должны решить проблему, не изменяя значения в узлах списка (т. е. изменять можно только сами узлы).
Решение:
func swapPairs(head *ListNode) *ListNode {
newHead := &ListNode{
Next: head,
}
prev := newHead
i := head
if i == nil {
return head
}
j := head.Next
for i != nil && j != nil {
prev.Next = j
i.Next = j.Next
j.Next = i
if i.Next == nil {
break
}
prev, i, j = i, i.Next, i.Next.Next
}
return newHead.Next
}Пояснение:
Конечно! Давайте разберем этот код подробнее:
Этот код представляет собой функцию `swapPairs`, которая меняет местами каждую пару соседних элементов в связанном списке.
1. Создается новый узел `newHead`, который инициализируется как исходный головной узел списка.
2. Устанавливается указатель `prev` на `newHead`, который будет использоваться для обновления связей между узлами списка.
3. Устанавливаются указатели `i` и `j` на начальный и следующий после него узлы соответственно.
4. Происходит проверка, если начальный узел `i` равен `nil` (конец списка), то возвращается исходный головной узел.
5. В цикле происходит обмен значениями между узлами:
- `prev.Next` указывает на `j` (следующий после `i`)
- `i.Next` указывает на `j.Next` (следующий после `j`)
- `j.Next` указывает на `i`
- Если `i.Next` равен `nil`, то прерывается цикл
- Обновляются указатели `prev`, `i`, `j` на следующие узлы
6. После завершения цикла возвращается головной узел списка, указываемый `newHead.Next`, который стал новым первым элементом после обмена.
Таким образом, функция `swapPairs` меняет местами каждую пару соседних узлов в связанном списке, используя указатели для изменения связей между узлами.
👍2❤1🤔1
Задача: 25. Reverse Nodes in k-Group #hard
Условие:
Решение:
Пояснение:
Функция `reverseKGroup`:
1. Создается новый узел `top`, который инициализируется как исходный головной узел списка.
2. Устанавливается указатель `track` на `top`, который используется для отслеживания текущего положения в списке.
3. В цикле выполняется следующие действия для каждой группы из k элементов:
- Вызывается функция `reverse`, которая возвращает последний узел (`last`) и узел, следующий за группой (`after`).
- Если возвращенный `last` равен `nil`, значит достигнут конец списка и происходит возврат нового головного узла `top.Next`.
- В противном случае, устанавливаются связи между узлами в группе.
- Обновляется указатель `track` на последний узел текущей группы, и продолжается обход списка.
4. По завершении обхода списка возвращается новый головной узел `top.Next`.
Функция `reverse`:
1. Функция рекурсивно меняет порядок следования узлов в группе размером `k`.
2. Если остался один элемент в группе (remaining == 1), то возвращается последний узел и узел, следующий за ним.
3. Если узел `n` является последним в списке, то возвращаются `nil` значения.
4. Иначе, функция вызывается рекурсивно с узлом следующим за `n` и уменьшением оставшегося количества элементов.
5. После рекурсивного вызова меняется порядок следования узлов в группе.
6. Возвращаются узлы `last` (последний элемент в группе) и `after` (узел, следующий за группой).
Эти две функции совместно образуют реализацию обращения каждой группы из `k` элементов в списке, используя рекурсию и обновление связей между узлами.
https://leetcode.com/problems/reverse-nodes-in-k-group
Условие:
Учитывая заголовок связанного списка, поменяйте местами узлы списка k за раз и верните измененный список.
k — целое положительное число, меньшее или равное длине связанного списка. Если количество узлов не кратно k, то пропущенные узлы в конечном итоге должны остаться такими, какие они есть.
Вы не можете изменять значения в узлах списка, можно изменять только сами узлы
Решение:
func reverseKGroup(head *ListNode, k int) *ListNode {
top := &ListNode{
Next: head,
}
track := top
for track.Next != nil {
last, after := reverse(track.Next, k)
if last == nil {
return top.Next
}
track.Next.Next = after
track.Next, track = last, track.Next
}
return top.Next
}
func reverse(n *ListNode, remaining int) (last, after *ListNode) {
if remaining == 1 {
return n, n.Next
}
if n.Next == nil {
return nil, nil
}
last, after = reverse(n.Next, remaining-1)
if last == nil {
return nil, nil
}
n.Next.Next = n
return
}Пояснение:
Функция `reverseKGroup`:
1. Создается новый узел `top`, который инициализируется как исходный головной узел списка.
2. Устанавливается указатель `track` на `top`, который используется для отслеживания текущего положения в списке.
3. В цикле выполняется следующие действия для каждой группы из k элементов:
- Вызывается функция `reverse`, которая возвращает последний узел (`last`) и узел, следующий за группой (`after`).
- Если возвращенный `last` равен `nil`, значит достигнут конец списка и происходит возврат нового головного узла `top.Next`.
- В противном случае, устанавливаются связи между узлами в группе.
- Обновляется указатель `track` на последний узел текущей группы, и продолжается обход списка.
4. По завершении обхода списка возвращается новый головной узел `top.Next`.
Функция `reverse`:
1. Функция рекурсивно меняет порядок следования узлов в группе размером `k`.
2. Если остался один элемент в группе (remaining == 1), то возвращается последний узел и узел, следующий за ним.
3. Если узел `n` является последним в списке, то возвращаются `nil` значения.
4. Иначе, функция вызывается рекурсивно с узлом следующим за `n` и уменьшением оставшегося количества элементов.
5. После рекурсивного вызова меняется порядок следования узлов в группе.
6. Возвращаются узлы `last` (последний элемент в группе) и `after` (узел, следующий за группой).
Эти две функции совместно образуют реализацию обращения каждой группы из `k` элементов в списке, используя рекурсию и обновление связей между узлами.
https://leetcode.com/problems/reverse-nodes-in-k-group
👍1🤔1
Задача: 26. Remove Duplicates from Sorted Array #easy
Условие:
Решение:
Пояснение:
Функция `removeDuplicates` принимает на вход срез целых чисел `nums` и выполняет удаление дубликатов из него. Она возвращает количество уникальных элементов и обновляет исходный срез, удаляя дубликаты.
1. Сначала проверяется длина среза `nums`. Если он меньше или равен 1, то функция мгновенно возвращает длину среза (т.е. в таком случае нет дубликатов).
2. Инициализируются два указателя `i` и `j`, где `i` указывает на начало уникальной части массива, а `j` на следующий за `i` элемент.
3. Запускается цикл, который проходит по элементам массива, начиная с элемента под индексом `1`.
4. На каждой итерации проверяется, равны ли элементы под индексами `i` и `j`.
- Если элементы равны, инкрементируется `j`, чтобы пропустить дубликат.
- В противном случае элемент под индексом `j` копируется на позицию `i+1`, увеличивается `i` и `j` на 1.
5. Процесс продолжается до тех пор, пока `j` не достигнет конца массива.
6. Функция возвращает `i+1`, что соответствует количеству уникальных элементов в массиве.
Таким образом, данная функция эффективно удаляет дубликаты из среза, меняя элементы на месте и возвращая количество уникальных элементов.
Условие:
Учитывая целочисленный массив чисел, отсортированный в неубывающем порядке, удалите дубликаты на месте так, чтобы каждый уникальный элемент появлялся только один раз. Относительный порядок элементов должен оставаться неизменным. Затем верните количество уникальных элементов в числах.
Считайте, что количество уникальных элементов чисел равно k. Чтобы вас приняли, вам нужно сделать следующее:
Измените массив nums так, чтобы первые k элементов nums содержали уникальные элементы в том порядке, в котором они присутствовали в nums изначально. Остальные элементы nums не важны, как и размер nums.
Вернуть К.
Решение:
func removeDuplicates(nums []int) int {
if len(nums) <= 1 {
return len(nums)
}
i, j := 0, 1
for j < len(nums) {
if nums[i] == nums[j] {
j++
} else {
nums[i+1] = nums[j]
i++
j++
}
}
return i+1
}Пояснение:
Функция `removeDuplicates` принимает на вход срез целых чисел `nums` и выполняет удаление дубликатов из него. Она возвращает количество уникальных элементов и обновляет исходный срез, удаляя дубликаты.
1. Сначала проверяется длина среза `nums`. Если он меньше или равен 1, то функция мгновенно возвращает длину среза (т.е. в таком случае нет дубликатов).
2. Инициализируются два указателя `i` и `j`, где `i` указывает на начало уникальной части массива, а `j` на следующий за `i` элемент.
3. Запускается цикл, который проходит по элементам массива, начиная с элемента под индексом `1`.
4. На каждой итерации проверяется, равны ли элементы под индексами `i` и `j`.
- Если элементы равны, инкрементируется `j`, чтобы пропустить дубликат.
- В противном случае элемент под индексом `j` копируется на позицию `i+1`, увеличивается `i` и `j` на 1.
5. Процесс продолжается до тех пор, пока `j` не достигнет конца массива.
6. Функция возвращает `i+1`, что соответствует количеству уникальных элементов в массиве.
Таким образом, данная функция эффективно удаляет дубликаты из среза, меняя элементы на месте и возвращая количество уникальных элементов.
👍2🤔1
Задача: 27. Remove Element #easy
Условие:
Решение:
Пояснение:
Функция `removeElement` принимает на вход срез целых чисел `a` и значение `val`, которое нужно удалить из среза. Функция возвращает количество элементов в срезе после удаления указанного значения.
1. Длина среза `a` сохраняется в переменной `n`.
2. Инициализируется переменная `j`, которая будет использоваться для обновления индексов в срезе.
3. В цикле `for` проходятся все элементы среза от `0` до `n-1` индекса.
4. На каждой итерации проверяется, равен ли элемент `a[i]` значению `val`.
- Если элемент не равен заданному значению `val`, то он копируется на позицию `a[j]` и значение переменной `j` увеличивается на `1`.
- Это позволяет обновить срез таким образом, чтобы значения, отличные от `val`, были скопированы в начало среза.
5. После завершения цикла возвращается значение `j`, которое является количеством элементов в срезе после удаления всех элементов со значением `val`.
Таким образом, данная функция эффективно удаляет все встречающиеся значения `val` из среза, сдвигая оставшиеся элементы в начало и возвращая количество оставшихся элементов.
Условие:
Учитывая целочисленный массив nums и целочисленное значение, удалите все вхождения val в nums на месте. Порядок элементов может быть изменен. Затем верните количество элементов в виде чисел, которые не равны val.
Учитывайте количество элементов в nums, которые не равны val be k. Чтобы вас приняли, вам необходимо сделать следующее:
Измените массив nums так, чтобы первые k элементов nums содержали элементы, не равные val. Остальные элементы nums не важны, как и размер nums.
Вернуть К.
Решение:
func removeElement(a []int, val int) int {
n := len(a)
j := 0
for i := 0; i<n; i++ {
if a[i] != val {
a[j] = a[i]
j++
}
}
return j
}Пояснение:
Функция `removeElement` принимает на вход срез целых чисел `a` и значение `val`, которое нужно удалить из среза. Функция возвращает количество элементов в срезе после удаления указанного значения.
1. Длина среза `a` сохраняется в переменной `n`.
2. Инициализируется переменная `j`, которая будет использоваться для обновления индексов в срезе.
3. В цикле `for` проходятся все элементы среза от `0` до `n-1` индекса.
4. На каждой итерации проверяется, равен ли элемент `a[i]` значению `val`.
- Если элемент не равен заданному значению `val`, то он копируется на позицию `a[j]` и значение переменной `j` увеличивается на `1`.
- Это позволяет обновить срез таким образом, чтобы значения, отличные от `val`, были скопированы в начало среза.
5. После завершения цикла возвращается значение `j`, которое является количеством элементов в срезе после удаления всех элементов со значением `val`.
Таким образом, данная функция эффективно удаляет все встречающиеся значения `val` из среза, сдвигая оставшиеся элементы в начало и возвращая количество оставшихся элементов.
🤔1
Задача: 28. Find the Index of the First Occurrence in a String #easy
Условие:
Решение:
Пояснение:
Функция `strStr` принимает две строки `haystack` и `needle` и ищет первое вхождение подстроки `needle` в строку `haystack`. Если подстрока не найдена, функция возвращает -1, иначе возвращает индекс, с которого начинается найденная подстрока.
1. Получаем длину строки `needle` и сохраняем ее в переменную `n`.
2. Проверяем, если длина `needle` равна нулю, то сразу возвращаем индекс 0, так как пустая подстрока считается встроенной в любую строку.
3. В цикле `for` перебираем индексы от 0 до `len(haystack)-n+1`, чтобы не выходить за пределы строки `haystack` в попытке сравнения подстроки.
4. На каждой итерации сравниваем подстроку `haystack[i:i+n]` с подстрокой `needle`.
- Если они равны, возвращаем индекс `i`, который указывает на начало вхождения подстроки.
5. Если цикл завершается и ни одно вхождение не было найдено, функция возвращает -1.
Таким образом, данная функция выполняет поиск первого вхождения подстроки `needle` в строку `haystack`, путем сравнения подстрок на каждой позиции.
Условие:
Учитывая две строки, игла и стог сена, верните индекс первого вхождения иглы в стоге сена или -1, если игла не является частью стога сена
Решение:
func strStr(haystack string, needle string) int {
n := len(needle)
if n==0 {
return 0
}
for i:=0; i<len(haystack)-n+1; i++ {
if haystack[i:i+n] == needle {
return i
}
}
return -1
}Пояснение:
Функция `strStr` принимает две строки `haystack` и `needle` и ищет первое вхождение подстроки `needle` в строку `haystack`. Если подстрока не найдена, функция возвращает -1, иначе возвращает индекс, с которого начинается найденная подстрока.
1. Получаем длину строки `needle` и сохраняем ее в переменную `n`.
2. Проверяем, если длина `needle` равна нулю, то сразу возвращаем индекс 0, так как пустая подстрока считается встроенной в любую строку.
3. В цикле `for` перебираем индексы от 0 до `len(haystack)-n+1`, чтобы не выходить за пределы строки `haystack` в попытке сравнения подстроки.
4. На каждой итерации сравниваем подстроку `haystack[i:i+n]` с подстрокой `needle`.
- Если они равны, возвращаем индекс `i`, который указывает на начало вхождения подстроки.
5. Если цикл завершается и ни одно вхождение не было найдено, функция возвращает -1.
Таким образом, данная функция выполняет поиск первого вхождения подстроки `needle` в строку `haystack`, путем сравнения подстрок на каждой позиции.
🤔1
Задача: 29. Divide Two Integers #medium
Условие:
Решение:
Пояснение:
Функция `divide` выполняет деление двух целых чисел `dividend` на `divisor`. Если результат деления выходит за пределы 32-битного целого числа, возвращает максимально возможное целое число (INT_MAX или INT_MIN).
1. Инициализируется переменная `c` для хранения результата деления.
2. `dividend` и `divisor` обрабатываются функцией `SplitSignAndNum`, которая возвращает знак (1 или -1) и абсолютное значение числа.
3. В цикле вычитаем из `r` (абсолютное значение делимого) `d` (абсолютное значение делителя) и увеличиваем счетчик `c`, пока `r >= d`.
4. Результат деления сохраняется в переменной `result`.
5. Если исходные числа были отрицательными, результат деления корректируется со знаком.
6. Проверяется переполнение результата по условиям INT_MIN и INT_MAX.
7. Возвращается результат.
Функция `SplitSignAndNum` просто возвращает знак числа и его абсолютное значение. Если число меньше 0, знак будет -1, иначе 1.
Этот код эмулирует деление целых чисел без использования встроенного оператора деления, обрабатывает знаки чисел и контролирует переполнение результата.
Условие:
Учитывая два целых числа: делимое и делитель, разделите два целых числа, не используя операторы умножения, деления и модификатора.
Целочисленное деление должно сокращаться до нуля, что означает потерю дробной части. Например, 8,345 будет сокращено до 8, а -2,7335 будет сокращено до -2.
Возвращает частное после деления делимого на делитель.
Примечание. Предположим, мы имеем дело со средой, которая может хранить целые числа только в пределах 32-битного целого диапазона со знаком: [−2^31, 2^31 − 1]. В этой задаче, если частное строго больше 2^31 - 1, верните 2^31 - 1, а если частное строго меньше -2^31, верните -2^31.
Решение:
func divide(dividend int, divisor int) int {
c := 0
dividendS, r := SplitSignAndNum(dividend)
divisorS, d := SplitSignAndNum(divisor)
for r >= d {
r = r - d
c++
}
result := c
if dividendS < 0 || divisorS < 0 {
if !(dividendS < 0 && divisorS < 0) {
result = -c
}
}
if result < -2147483648 {
return -2147483648
} else if result > 2147483647 {
return 2147483647
}
return result
}
func SplitSignAndNum(i int) (int,int) {
if i < 0 {
return -1, -i
}
return 1, i
}Пояснение:
Функция `divide` выполняет деление двух целых чисел `dividend` на `divisor`. Если результат деления выходит за пределы 32-битного целого числа, возвращает максимально возможное целое число (INT_MAX или INT_MIN).
1. Инициализируется переменная `c` для хранения результата деления.
2. `dividend` и `divisor` обрабатываются функцией `SplitSignAndNum`, которая возвращает знак (1 или -1) и абсолютное значение числа.
3. В цикле вычитаем из `r` (абсолютное значение делимого) `d` (абсолютное значение делителя) и увеличиваем счетчик `c`, пока `r >= d`.
4. Результат деления сохраняется в переменной `result`.
5. Если исходные числа были отрицательными, результат деления корректируется со знаком.
6. Проверяется переполнение результата по условиям INT_MIN и INT_MAX.
7. Возвращается результат.
Функция `SplitSignAndNum` просто возвращает знак числа и его абсолютное значение. Если число меньше 0, знак будет -1, иначе 1.
Этот код эмулирует деление целых чисел без использования встроенного оператора деления, обрабатывает знаки чисел и контролирует переполнение результата.
🤔1
Задача: 30. Substring with Concatenation of All Words #hard
Условие:
Решение:
Пояснение:
Функция `findSubstring` выполняет поиск всех начальных индексов в строке `s`, с которых начинается подстрока, образованная конкатенацией всех слов из среза `words`. Функция использует функцию `startsWithConcatenatedSubstring` для проверки соответствия подстроки условиям.
1. Сначала все слова в срезе `words` сортируются в лексикографическом порядке.
2. Создается пустой срез `result` для хранения индексов начала подстрок.
3. В цикле `for`, проходящем по индексам строки `s`, проверяется, начинается ли подстрока с индексом `i` с конкатенации слов из `words` (используется функция `startsWithConcatenatedSubstring`). Если условие выполняется, индекс `i` добавляется в срез `result`.
4. Возвращается срез `result` с индексами начала подстрок.
Функция `startsWithConcatenatedSubstring` проверяет, начинается ли переданная строка `s` с конкатенации слов из среза `words`:
1. Создается временный срез `parts`, куда добавляются подстроки длиной `wl` (длина одного слова) из строки `s`.
2. Подстроки также сортируются в лексикографическом порядке.
3. Проверяется соответствие каждой подстроки с элементом из среза `words`. Если хоть одна подстрока не соответствует, возвращается `false`.
4. Если все проверки успешны, возвращается `true`, указывая на то, что строка `s` начинается с конкатенации слов из `words`.
Таким образом, данная функция позволяет находить начальные индексы в строке, с которых начинаются конкатенации слов из заданного среза слов.
https://leetcode.com/problems/substring-with-concatenation-of-all-words
Условие:
Вам дана строка s и массив строк-слов. Все строки слов имеют одинаковую длину.
Объединенная строка — это строка, которая в точности содержит все строки любой перестановки объединенных слов.
Например, если слова = ["ab", "cd", "ef"], то "abcdef", "abefcd", "cdabef", "cdefab", "efabcd" и "efcdab" являются объединенными строками. «acdbef» не является объединенной строкой, поскольку не является объединением какой-либо перестановки слов.
Возвращает массив начальных индексов всех объединенных подстрок в s. Вы можете вернуть ответ в любом порядке
Решение:
import "sort"
func findSubstring(s string, words []string) []int {
sort.Strings(words)
var result []int
for i := range s {
if startsWithConcatenatedSubstring(s[i:], words) {
result = append(result, i)
}
}
return result
}
func startsWithConcatenatedSubstring(s string, words []string) bool {
var parts[] string
wl := len(words[0])
for i := range words {
startPos := wl*i
endPos := wl*(i+1)
if endPos > len(s) {
return false
}
p := s[startPos:endPos]
parts = append(parts, p)
}
sort.Strings(parts)
for i, p := range parts {
if p != words[i] {
return false
}
}
return true
}
Пояснение:
Функция `findSubstring` выполняет поиск всех начальных индексов в строке `s`, с которых начинается подстрока, образованная конкатенацией всех слов из среза `words`. Функция использует функцию `startsWithConcatenatedSubstring` для проверки соответствия подстроки условиям.
1. Сначала все слова в срезе `words` сортируются в лексикографическом порядке.
2. Создается пустой срез `result` для хранения индексов начала подстрок.
3. В цикле `for`, проходящем по индексам строки `s`, проверяется, начинается ли подстрока с индексом `i` с конкатенации слов из `words` (используется функция `startsWithConcatenatedSubstring`). Если условие выполняется, индекс `i` добавляется в срез `result`.
4. Возвращается срез `result` с индексами начала подстрок.
Функция `startsWithConcatenatedSubstring` проверяет, начинается ли переданная строка `s` с конкатенации слов из среза `words`:
1. Создается временный срез `parts`, куда добавляются подстроки длиной `wl` (длина одного слова) из строки `s`.
2. Подстроки также сортируются в лексикографическом порядке.
3. Проверяется соответствие каждой подстроки с элементом из среза `words`. Если хоть одна подстрока не соответствует, возвращается `false`.
4. Если все проверки успешны, возвращается `true`, указывая на то, что строка `s` начинается с конкатенации слов из `words`.
Таким образом, данная функция позволяет находить начальные индексы в строке, с которых начинаются конкатенации слов из заданного среза слов.
https://leetcode.com/problems/substring-with-concatenation-of-all-words
🤔1
{kind=link}
#medium
Задача: 31. Next Permutation
Перестановка массива целых чисел — это упорядочивание его элементов в последовательность или линейный порядок.
Например, для arr = [1,2,3] следующие являются всеми перестановками arr: [1,2,3], [1,3,2], [2, 1, 3], [2, 3, 1], [3,1,2], [3,2,1].
Следующая перестановка массива целых чисел — это следующая лексикографически большая перестановка его чисел. Более формально, если все перестановки массива отсортированы в одном контейнере по лексикографическому порядку, то следующая перестановка этого массива — это перестановка, следующая за ней в отсортированном контейнере. Если такое упорядочивание невозможно, массив должен быть переупорядочен в наименьший возможный порядок (то есть отсортирован по возрастанию).
Например, следующая перестановка arr = [1,2,3] — это [1,3,2].
Аналогично, следующая перестановка arr = [2,3,1] — это [3,1,2].
В то время как следующая перестановка arr = [3,2,1] — это [1,2,3], потому что [3,2,1] не имеет лексикографически большего переупорядочивания.
Для данного массива целых чисел nums найдите следующую перестановку nums.
Замена должна быть выполнена на месте и использовать только постоянную дополнительную память.
Пример:
👨💻 Алгоритм:
1️⃣ Мы меняем местами числа a[i−1] и a[j]. Теперь у нас есть правильное число на индексе i−1. Однако текущая перестановка ещё не является той перестановкой, которую мы ищем. Нам нужна наименьшая перестановка, которая может быть сформирована с использованием чисел только справа от a[i−1]. Следовательно, нам нужно расположить эти числа в порядке возрастания, чтобы получить их наименьшую перестановку.
2️⃣ Однако, вспомните, что, сканируя числа справа налево, мы просто уменьшали индекс, пока не нашли пару a[i] и a[i−1], где a[i] > a[i−1]. Таким образом, все числа справа от a[i−1] уже были отсортированы в порядке убывания. Более того, обмен местами a[i−1] и a[j] не изменил этот порядок.
3️⃣ Поэтому нам просто нужно перевернуть числа, следующие за a[i−1], чтобы получить следующую наименьшую лексикографическую перестановку.
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 31. Next Permutation
Перестановка массива целых чисел — это упорядочивание его элементов в последовательность или линейный порядок.
Например, для arr = [1,2,3] следующие являются всеми перестановками arr: [1,2,3], [1,3,2], [2, 1, 3], [2, 3, 1], [3,1,2], [3,2,1].
Следующая перестановка массива целых чисел — это следующая лексикографически большая перестановка его чисел. Более формально, если все перестановки массива отсортированы в одном контейнере по лексикографическому порядку, то следующая перестановка этого массива — это перестановка, следующая за ней в отсортированном контейнере. Если такое упорядочивание невозможно, массив должен быть переупорядочен в наименьший возможный порядок (то есть отсортирован по возрастанию).
Например, следующая перестановка arr = [1,2,3] — это [1,3,2].
Аналогично, следующая перестановка arr = [2,3,1] — это [3,1,2].
В то время как следующая перестановка arr = [3,2,1] — это [1,2,3], потому что [3,2,1] не имеет лексикографически большего переупорядочивания.
Для данного массива целых чисел nums найдите следующую перестановку nums.
Замена должна быть выполнена на месте и использовать только постоянную дополнительную память.
Пример:
Input: nums = [1,2,3]
Output: [1,3,2]
func nextPermutation(nums []int) {
i := len(nums) - 2
for i >= 0 && nums[i+1] <= nums[i] {
i--
}
if i >= 0 {
j := len(nums) - 1
for nums[j] <= nums[i] {
j--
}
swap(nums, i, j)
}
reverse(nums, i+1)
}
func reverse(nums []int, start int) {
i, j := start, len(nums)-1
for i < j {
swap(nums, i, j)
i++
j--
}
}
func swap(nums []int, i int, j int) {
temp := nums[i]
nums[i] = nums[j]
nums[j] = temp
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#hard
Задача: 32. Longest Valid Parentheses
Дана строка, содержащая только символы '(' и ')'. Верните длину самой длинной подстроки с корректными (правильно сформированными) скобками.
Пример:
👨💻 Алгоритм:
1️⃣ В этом подходе мы рассматриваем каждую возможную непустую подстроку чётной длины из заданной строки и проверяем, является ли она корректной строкой скобок. Для проверки корректности мы используем метод стека.
2️⃣ Каждый раз, когда мы встречаем символ ‘(’, мы кладём его в стек. Для каждого встреченного символа ‘)’ мы извлекаем из стека символ ‘(’. Если символ ‘(’ недоступен в стеке для извлечения в любой момент или если в стеке остались элементы после обработки всей подстроки, подстрока скобок является некорректной.
3️⃣ Таким образом, мы повторяем процесс для каждой возможной подстроки и продолжаем сохранять длину самой длинной найденной корректной строки.
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 32. Longest Valid Parentheses
Дана строка, содержащая только символы '(' и ')'. Верните длину самой длинной подстроки с корректными (правильно сформированными) скобками.
Пример:
Input: s = "(()"
Output: 2
func isValid(s string) bool {
stack := []rune{}
for _, char := range s {
if char == '(' {
stack = append(stack, char)
} else if len(stack) > 0 && stack[len(stack)-1] == '(' {
stack = stack[:len(stack)-1]
} else {
return false
}
}
return len(stack) == 0
}
func longestValidParentheses(s string) int {
maxlen := 0
for i := 0; i < len(s); i++ {
for j := i + 2; j <= len(s); j += 2 {
if isValid(s[i:j]) {
if maxlen < j-i {
maxlen = j - i
}
}
}
}
return maxlen
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 33. Search in Rotated Sorted Array
Есть массив целых чисел nums, отсортированный в порядке возрастания (с уникальными значениями).
Перед передачей в вашу функцию массив nums может быть повёрнут в неизвестном индексе поворота k (1 <= k < nums.length), так что результирующий массив будет иметь вид [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]] (с индексацией с нуля). Например, [0,1,2,4,5,6,7] может быть повёрнут в индексе поворота 3 и стать [4,5,6,7,0,1,2].
Для данного массива nums после возможного поворота и целого числа target, верните индекс target, если он есть в массиве, или -1, если его нет в массиве.
Вы должны написать алгоритм с временной сложностью O(log n).
Пример:
👨💻 Алгоритм:
1️⃣ Выполните двоичный поиск для определения индекса поворота, инициализируя границы области поиска значениями left = 0 и right = n - 1. Пока left < right:
Пусть mid = left + (right - left) // 2.
Если nums[mid] > nums[n - 1], это предполагает, что точка поворота находится справа от mid, следовательно, мы устанавливаем left = mid + 1. В противном случае, поворот может находиться на позиции mid или левее от mid, в этом случае мы должны установить right = mid.
2️⃣ По завершении двоичного поиска мы имеем индекс поворота, обозначенный как pivot = left.
nums состоит из двух отсортированных подмассивов, nums[0 ~ left - 1] и nums[left ~ n - 1].
3️⃣ Выполните двоичный поиск по подмассиву nums[0 ~ left - 1] для поиска target. Если target находится в этом подмассиве, верните его индекс.
В противном случае выполните двоичный поиск по подмассиву nums[left ~ n - 1] для поиска target. Если target находится в этом подмассиве, верните его индекс. В противном случае верните -1.
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 33. Search in Rotated Sorted Array
Есть массив целых чисел nums, отсортированный в порядке возрастания (с уникальными значениями).
Перед передачей в вашу функцию массив nums может быть повёрнут в неизвестном индексе поворота k (1 <= k < nums.length), так что результирующий массив будет иметь вид [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]] (с индексацией с нуля). Например, [0,1,2,4,5,6,7] может быть повёрнут в индексе поворота 3 и стать [4,5,6,7,0,1,2].
Для данного массива nums после возможного поворота и целого числа target, верните индекс target, если он есть в массиве, или -1, если его нет в массиве.
Вы должны написать алгоритм с временной сложностью O(log n).
Пример:
Input: nums = [4,5,6,7,0,1,2], target = 0
Output: 4
Пусть mid = left + (right - left) // 2.
Если nums[mid] > nums[n - 1], это предполагает, что точка поворота находится справа от mid, следовательно, мы устанавливаем left = mid + 1. В противном случае, поворот может находиться на позиции mid или левее от mid, в этом случае мы должны установить right = mid.
nums состоит из двух отсортированных подмассивов, nums[0 ~ left - 1] и nums[left ~ n - 1].
В противном случае выполните двоичный поиск по подмассиву nums[left ~ n - 1] для поиска target. Если target находится в этом подмассиве, верните его индекс. В противном случае верните -1.
func search(nums []int, target int) int {
n := len(nums)
left, right := 0, n-1
for left <= right {
mid := (left + right) / 2
if nums[mid] > nums[n-1] {
left = mid + 1
} else {
right = mid - 1
}
}
binarySearch := func(left_boundary int, right_boundary int, target int) int {
left, right := left_boundary, right_boundary
for left <= right {
mid := (left + right) / 2
if nums[mid] == target {
return mid
} else if nums[mid] > target {
right = mid - 1
} else {
left = mid + 1
}
}
return -1
}
if answer := binarySearch(0, left-1, target); answer != -1 {
return answer
}
return binarySearch(left, n-1, target)
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#medium
Задача: 34. Find First and Last Position of Element in Sorted Array
Дан массив целых чисел nums, отсортированный в неубывающем порядке, найдите начальную и конечную позицию заданного целевого значения.
Если целевое значение не найдено в массиве, верните [-1, -1].
Вы должны написать алгоритм со временной сложностью O(log n).
Пример:
👨💻 Алгоритм:
1️⃣ Определите функцию под названием findBound, которая принимает три аргумента: массив, целевое значение для поиска и булевое значение isFirst, указывающее, ищем ли мы первое или последнее вхождение цели.
Мы используем 2 переменные для отслеживания подмассива, который мы сканируем. Назовем их begin и end. Изначально begin устанавливается в 0, а end — в последний индекс массива.
2️⃣ Мы итерируем, пока begin не станет больше, чем end.
На каждом шаге мы вычисляем средний элемент mid = (begin + end) / 2. Мы используем значение среднего элемента, чтобы решить, какую половину массива нам нужно искать.
Если nums[mid] == target:
Если isFirst true — это означает, что мы пытаемся найти первое вхождение элемента. Если mid == begin или nums[mid - 1] != target, тогда мы возвращаем mid как первое вхождение цели. В противном случае мы обновляем end = mid - 1.
Если isFirst false — это означает, что мы пытаемся найти последнее вхождение элемента. Если mid == end или nums[mid + 1] != target, тогда мы возвращаем mid как последнее вхождение цели. В противном случае мы обновляем begin = mid + 1.
3️⃣ Если nums[mid] > target — мы обновляем end = mid - 1, так как мы должны отбросить правую сторону массива, поскольку средний элемент больше цели.
Если nums[mid] < target — мы обновляем begin = mid + 1, так как мы должны отбросить левую сторону массива, поскольку средний элемент меньше цели.
В конце нашей функции мы возвращаем значение -1, что указывает на то, что цель не найдена в массиве.
В основной функции searchRange мы сначала вызываем findBound с isFirst, установленным в true. Если это значение равно -1, мы можем просто вернуть [-1, -1]. В противном случае мы вызываем findBound с isFirst, установленным в false, чтобы получить последнее вхождение, а затем возвращаем результат.
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 34. Find First and Last Position of Element in Sorted Array
Дан массив целых чисел nums, отсортированный в неубывающем порядке, найдите начальную и конечную позицию заданного целевого значения.
Если целевое значение не найдено в массиве, верните [-1, -1].
Вы должны написать алгоритм со временной сложностью O(log n).
Пример:
Input: nums = [5,7,7,8,8,10], target = 8
Output: [3,4]
Мы используем 2 переменные для отслеживания подмассива, который мы сканируем. Назовем их begin и end. Изначально begin устанавливается в 0, а end — в последний индекс массива.
На каждом шаге мы вычисляем средний элемент mid = (begin + end) / 2. Мы используем значение среднего элемента, чтобы решить, какую половину массива нам нужно искать.
Если nums[mid] == target:
Если isFirst true — это означает, что мы пытаемся найти первое вхождение элемента. Если mid == begin или nums[mid - 1] != target, тогда мы возвращаем mid как первое вхождение цели. В противном случае мы обновляем end = mid - 1.
Если isFirst false — это означает, что мы пытаемся найти последнее вхождение элемента. Если mid == end или nums[mid + 1] != target, тогда мы возвращаем mid как последнее вхождение цели. В противном случае мы обновляем begin = mid + 1.
Если nums[mid] < target — мы обновляем begin = mid + 1, так как мы должны отбросить левую сторону массива, поскольку средний элемент меньше цели.
В конце нашей функции мы возвращаем значение -1, что указывает на то, что цель не найдена в массиве.
В основной функции searchRange мы сначала вызываем findBound с isFirst, установленным в true. Если это значение равно -1, мы можем просто вернуть [-1, -1]. В противном случае мы вызываем findBound с isFirst, установленным в false, чтобы получить последнее вхождение, а затем возвращаем результат.
func searchRange(nums []int, target int) []int {
firstOccurrence := findBound(nums, target, true)
if firstOccurrence == -1 {
return []int{-1, -1}
}
lastOccurrence := findBound(nums, target, false)
return []int{firstOccurrence, lastOccurrence}
}
func findBound(nums []int, target int, isFirst bool) int {
N := len(nums)
begin, end := 0, N-1
for begin <= end {
mid := (begin + end) / 2
if nums[mid] == target {
if isFirst {
if mid == begin || nums[mid-1] != target {
return mid
}
end = mid - 1
} else {
if mid == end || nums[mid+1] != target {
return mid
}
begin = mid + 1
}
} else if nums[mid] > target {
end = mid - 1
} else {
begin = mid + 1
}
}
return -1
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
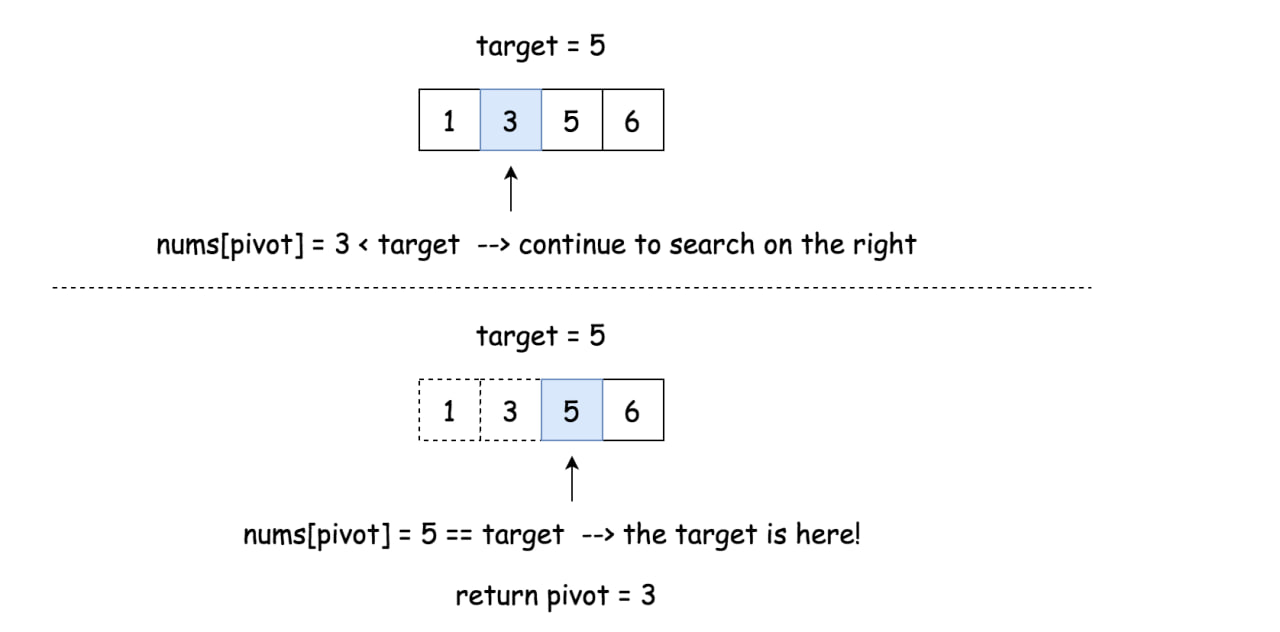{kind=link}
#easy
Задача: 35. Search Insert Position
Дан отсортированный массив уникальных целых чисел и целевое значение. Верните индекс, если цель найдена. Если нет, верните индекс, где она должна быть вставлена в соответствии с порядком.
Вы должны написать алгоритм со временной сложностью O(log n).
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте указатели left и right: left = 0, right = n - 1.
2️⃣ Пока left <= right:
Сравните средний элемент массива nums[pivot] с целевым значением target.
Если средний элемент является целевым, то есть target == nums[pivot]: верните pivot.
Если цель не найдена:
Если target < nums[pivot], продолжайте поиск в левом подмассиве. right = pivot - 1.
Иначе продолжайте поиск в правом подмассиве. left = pivot + 1.
3️⃣ Верните left.
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 35. Search Insert Position
Дан отсортированный массив уникальных целых чисел и целевое значение. Верните индекс, если цель найдена. Если нет, верните индекс, где она должна быть вставлена в соответствии с порядком.
Вы должны написать алгоритм со временной сложностью O(log n).
Пример:
Input: nums = [1,3,5,6], target = 5
Output: 2
Сравните средний элемент массива nums[pivot] с целевым значением target.
Если средний элемент является целевым, то есть target == nums[pivot]: верните pivot.
Если цель не найдена:
Если target < nums[pivot], продолжайте поиск в левом подмассиве. right = pivot - 1.
Иначе продолжайте поиск в правом подмассиве. left = pivot + 1.
func searchInsert(nums []int, target int) int {
var pivot, left, right int = 0, 0, len(nums) - 1
for left <= right {
pivot = left + (right-left)/2
if nums[pivot] == target {
return pivot
} else if target < nums[pivot] {
right = pivot - 1
} else {
left = pivot + 1
}
}
return left
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍2🤔1
{kind=link}
#medium
Задача: 36. Valid Sudoku
Определите, является ли доска Судоку размером 9 на 9 валидной. Необходимо проверить только заполненные ячейки согласно следующим правилам:
Каждая строка должна содержать цифры от 1 до 9 без повторений.
Каждый столбец должен содержать цифры от 1 до 9 без повторений.
Каждая из девяти подзон размером 3 на 3 в сетке должна содержать цифры от 1 до 9 без повторений.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте список из 9 хеш-множеств, где хеш-множество с индексом r будет использоваться для хранения ранее увиденных чисел в строке r судоку. Аналогично инициализируйте списки из 9 хеш-множеств для отслеживания столбцов и блоков.
2️⃣ Итерируйтесь по каждой позиции (r, c) в судоку. На каждой итерации, если на текущей позиции есть число:
Проверьте, существует ли это число в хеш-множестве для текущей строки, столбца или блока. Если да, верните false, потому что это второе появление числа в текущей строке, столбце или блоке.
3️⃣ В противном случае обновите множество, отвечающее за отслеживание ранее увиденных чисел в текущей строке, столбце и блоке. Индекс текущего блока рассчитывается как (r / 3) * 3 + (c / 3), где / означает деление нацело.
Если дубликаты не были найдены после посещения каждой позиции на доске судоку, то судоку валидно, поэтому верните true.
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 36. Valid Sudoku
Определите, является ли доска Судоку размером 9 на 9 валидной. Необходимо проверить только заполненные ячейки согласно следующим правилам:
Каждая строка должна содержать цифры от 1 до 9 без повторений.
Каждый столбец должен содержать цифры от 1 до 9 без повторений.
Каждая из девяти подзон размером 3 на 3 в сетке должна содержать цифры от 1 до 9 без повторений.
Пример:
Input: board =
[["5","3",".",".","7",".",".",".","."]
,["6",".",".","1","9","5",".",".","."]
,[".","9","8",".",".",".",".","6","."]
,["8",".",".",".","6",".",".",".","3"]
,["4",".",".","8",".","3",".",".","1"]
,["7",".",".",".","2",".",".",".","6"]
,[".","6",".",".",".",".","2","8","."]
,[".",".",".","4","1","9",".",".","5"]
,[".",".",".",".","8",".",".","7","9"]]
Output: true
Проверьте, существует ли это число в хеш-множестве для текущей строки, столбца или блока. Если да, верните false, потому что это второе появление числа в текущей строке, столбце или блоке.
Если дубликаты не были найдены после посещения каждой позиции на доске судоку, то судоку валидно, поэтому верните true.
func isValidSudoku(board [][]byte) bool {
N := 9
rows := make([]map[byte]bool, N)
cols := make([]map[byte]bool, N)
boxes := make([]map[byte]bool, N)
for i := 0; i < N; i++ {
rows[i] = make(map[byte]bool)
cols[i] = make(map[byte]bool)
boxes[i] = make(map[byte]bool)
}
for r := 0; r < N; r++ {
for c := 0; c < N; c++ {
val := board[r][c]
if val == '.' {
continue
}
if rows[r][val] {
return false
}
rows[r][val] = true
if cols[c][val] {
return false
}
cols[c][val] = true
idx := (r/3)*3 + c/3
if boxes[idx][val] {
return false
}
boxes[idx][val] = true
}
}
return true
}Please open Telegram to view this post
VIEW IN TELEGRAM
🔥1🤔1
{kind=link}
#hard
Задача: 37. Sudoku Solver
Напишите программу для решения головоломки Судоку, заполнив пустые ячейки.
Решение Судоку должно удовлетворять всем следующим правилам:
Каждая из цифр от 1 до 9 должна встречаться ровно один раз в каждой строке.
Каждая из цифр от 1 до 9 должна встречаться ровно один раз в каждом столбце.
Каждая из цифр от 1 до 9 должна встречаться ровно один раз в каждом из 9 подблоков 3x3 сетки.
Символ '.' обозначает пустые ячейки.
Пример:
👨💻 Алгоритм:
1️⃣ Теперь все готово для написания функции обратного поиска backtrack(row = 0, col = 0). Начните с верхней левой ячейки row = 0, col = 0. Продолжайте, пока не дойдете до первой свободной ячейки.
2️⃣ Итерируйте по числам от 1 до 9 и попробуйте поставить каждое число d в ячейку (row, col).
Если число d еще не в текущей строке, столбце и блоке:
Поместите d в ячейку (row, col).
Запишите, что d теперь присутствует в текущей строке, столбце и блоке.
3️⃣ Если вы на последней ячейке row == 8, col == 8:
Это означает, что судоку решено.
В противном случае продолжайте размещать дальнейшие числа.
Откат, если решение еще не найдено: удалите последнее число из ячейки (row, col).
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 37. Sudoku Solver
Напишите программу для решения головоломки Судоку, заполнив пустые ячейки.
Решение Судоку должно удовлетворять всем следующим правилам:
Каждая из цифр от 1 до 9 должна встречаться ровно один раз в каждой строке.
Каждая из цифр от 1 до 9 должна встречаться ровно один раз в каждом столбце.
Каждая из цифр от 1 до 9 должна встречаться ровно один раз в каждом из 9 подблоков 3x3 сетки.
Символ '.' обозначает пустые ячейки.
Пример:
Input: board =
[["5","3",".",".","7",".",".",".","."],
["6",".",".","1","9","5",".",".","."],
[".","9","8",".",".",".",".","6","."],
["8",".",".",".","6",".",".",".","3"],
["4",".",".","8",".","3",".",".","1"],
["7",".",".",".","2",".",".",".","6"],
[".","6",".",".",".",".","2","8","."],
[".",".",".","4","1","9",".",".","5"],
[".",".",".",".","8",".",".","7","9"]]
Output:
[["5","3","4","6","7","8","9","1","2"],["6","7","2","1","9","5","3","4","8"],["1","9","8","3","4","2","5","6","7"],["8","5","9","7","6","1","4","2","3"],["4","2","6","8","5","3","7","9","1"],["7","1","3","9","2","4","8","5","6"],["9","6","1","5","3","7","2","8","4"],["2","8","7","4","1","9","6","3","5"],["3","4","5","2","8","6","1","7","9"]]
Если число d еще не в текущей строке, столбце и блоке:
Поместите d в ячейку (row, col).
Запишите, что d теперь присутствует в текущей строке, столбце и блоке.
Это означает, что судоку решено.
В противном случае продолжайте размещать дальнейшие числа.
Откат, если решение еще не найдено: удалите последнее число из ячейки (row, col).
type Solution struct {
n, N int
rows, columns, boxes [][]int
board [][]byte
}
func Constructor() Solution {
n, N := 3, 9
rows, columns, boxes := make([][]int, N), make([][]int, N), make([][]int, N)
for i := 0; i < N; i++ {
rows[i], columns[i], boxes[i] = make([]int, N+1), make([]int, N+1), make([]int, N+1)
}
return Solution{n: n, N: N, rows: rows, columns: columns, boxes: boxes}
}
func (s *Solution) couldPlace(d, row, col int) bool {
idx := (row / s.n) * s.n + col / s.n
return s.rows[row][d]+s.columns[col][d]+s.boxes[idx][d] == 0
}
func (s *Solution) placeOrRemove(d, row, col int, place bool) {
idx := (row / s.n) * s.n + col / s.n
delta := 1
if !place {
delta = -1
s.board[row][col] = '.'
} else {
s.board[row][col] = byte(d) + '0'
}
s.rows[row][d] += delta
s.columns[col][d] += delta
s.boxes[idx][d] += delta
}
func (s *Solution) backTrack(row, col int) bool {
if col == s.N {
col, row = 0, row+1
}
if row == s.N {
return true
}
if s.board[row][col] != '.' {
return s.backTrack(row, col+1)
}
for d := 1; d <= 9; d++ {
if s.couldPlace(d, row, col) {
s.placeOrRemove(d, row, col, true)
if s.backTrack(row, col+1) {
return true
}
s.placeOrRemove(d, row, col, false)
}
}
return false
}
func solveSudoku(board [][]byte) {
s := Constructor()
s.board = board
for r := 0; r < s.N; r++ {
for c := 0; c < s.N; c++ {
if board[r][c] != '.' {
d := int(board[r][c] - '0')
s.placeOrRemove(d, r, c, true)
}
}
}
s.backTrack(0, 0)
}Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
Пояснение:
Этот код написан для решения задачи Судоку путем заполнения доски с помощью рекурсивного алгоритма обратного отслеживания (backtracking).
1. В начале создаются 2D массивы `rows`, `cols`, `subs` для отслеживания, какие числа уже присутствуют в строках, столбцах и блоках.
2. Происходит проход по всем элементам доски `board`. Если ячейка не пустая, то соответствующие индексы в массивах `rows`, `cols`, `subs` устанавливаются в `true` для этого числа.
3. Далее определяется внутренняя рекурсивная функция `backtracking`, которая принимает координаты `x` и `y` текущей ячейки.
4. Если `x` (индекс строки) больше 8 (соответствует 9 строке), это означает, что все строки были заполнены, и решение Судоку найдено, возвращается `true`.
5. Затем вычисляются координаты следующей ячейки с учетом порядка заполнения доски (слева направо, сверху вниз).
6. Есть случай, когда текущая ячейка пустая. Тогда производится перебор чисел от 1 до 9:
- Для каждого числа проверяется, является ли оно подходящим для заполнения (не нарушается ли правило игры).
- Если число подходит, оно заполняется, отмечается в массивах `rows`, `cols`, `subs`, и запускается рекурсивный вызов для следующей ячейки.
- Если рекурсивный вызов вернул `true`, значит решение найдено и возвращается `true`.
- Если не удалось найти подходящее число, то текущая ячейка становится пустой, и процесс продолжается с новым числом.
7. Если текущая ячейка уже заполнена, просто выполняется рекурсивный вызов для следующей ячейки.
8. После прохождения всех ячеек доски и выполнения рекурсивных вызовов, если решение не было найдено, возвращается `false`. Если же решение найдено, доска будет заполнена правильно.
Этот код эффективно решает задачу Судоку, используя метод обратного отслеживания для проверки подходящих чисел и постепенного заполнения доски.
Этот код написан для решения задачи Судоку путем заполнения доски с помощью рекурсивного алгоритма обратного отслеживания (backtracking).
1. В начале создаются 2D массивы `rows`, `cols`, `subs` для отслеживания, какие числа уже присутствуют в строках, столбцах и блоках.
2. Происходит проход по всем элементам доски `board`. Если ячейка не пустая, то соответствующие индексы в массивах `rows`, `cols`, `subs` устанавливаются в `true` для этого числа.
3. Далее определяется внутренняя рекурсивная функция `backtracking`, которая принимает координаты `x` и `y` текущей ячейки.
4. Если `x` (индекс строки) больше 8 (соответствует 9 строке), это означает, что все строки были заполнены, и решение Судоку найдено, возвращается `true`.
5. Затем вычисляются координаты следующей ячейки с учетом порядка заполнения доски (слева направо, сверху вниз).
6. Есть случай, когда текущая ячейка пустая. Тогда производится перебор чисел от 1 до 9:
- Для каждого числа проверяется, является ли оно подходящим для заполнения (не нарушается ли правило игры).
- Если число подходит, оно заполняется, отмечается в массивах `rows`, `cols`, `subs`, и запускается рекурсивный вызов для следующей ячейки.
- Если рекурсивный вызов вернул `true`, значит решение найдено и возвращается `true`.
- Если не удалось найти подходящее число, то текущая ячейка становится пустой, и процесс продолжается с новым числом.
7. Если текущая ячейка уже заполнена, просто выполняется рекурсивный вызов для следующей ячейки.
8. После прохождения всех ячеек доски и выполнения рекурсивных вызовов, если решение не было найдено, возвращается `false`. Если же решение найдено, доска будет заполнена правильно.
Этот код эффективно решает задачу Судоку, используя метод обратного отслеживания для проверки подходящих чисел и постепенного заполнения доски.
#medium
Задача: 38. Count and Say
Последовательность "считай и скажи" — это последовательность строк цифр, определяемая с помощью рекурсивной формулы:
countAndSay(1) = "1"
countAndSay(n) — это кодирование длин серий из countAndSay(n - 1).
Кодирование длин серий (RLE) — это метод сжатия строк, который работает путём замены последовательных идентичных символов (повторяющихся 2 или более раз) на конкатенацию символа и числа, обозначающего количество символов (длину серии). Например, чтобы сжать строку "3322251", мы заменяем "33" на "23", "222" на "32", "5" на "15" и "1" на "11". Таким образом, сжатая строка становится "23321511".
Для заданного положительного целого числа n верните n-й элемент последовательности "считай и скажи".
Пример:
👨💻 Алгоритм:
1️⃣ Мы хотим использовать шаблон, который соответствует строкам из одинаковых символов, таких как "4", "7777", "2222222".
Если у вас есть опыт работы с регулярными выражениями, вы можете обнаружить, что шаблон (.)\1* работает.
2️⃣ Мы можем разбить это регулярное выражение на три части:
(.): оно определяет группу, содержащую один символ, который может быть чем угодно.
3️⃣ *: этот квалификатор, следующий за ссылкой на группу \1, указывает, что мы хотели бы видеть повторение группы ноль или более раз.
Таким образом, шаблон соответствует строкам, которые состоят из некоторого символа, а затем ноль или более повторений этого символа после его первого появления. Это то, что нам нужно.
Мы находим все совпадения с регулярным выражением, а затем конкатенируем результаты.
😎 Решение:
🪙 349 вопроса вопроса на Golang разработчика
🔒 База собесов | 🔒 База тестовых
Задача: 38. Count and Say
Последовательность "считай и скажи" — это последовательность строк цифр, определяемая с помощью рекурсивной формулы:
countAndSay(1) = "1"
countAndSay(n) — это кодирование длин серий из countAndSay(n - 1).
Кодирование длин серий (RLE) — это метод сжатия строк, который работает путём замены последовательных идентичных символов (повторяющихся 2 или более раз) на конкатенацию символа и числа, обозначающего количество символов (длину серии). Например, чтобы сжать строку "3322251", мы заменяем "33" на "23", "222" на "32", "5" на "15" и "1" на "11". Таким образом, сжатая строка становится "23321511".
Для заданного положительного целого числа n верните n-й элемент последовательности "считай и скажи".
Пример:
Input: n = 4
Output: "1211"
Explanation:
countAndSay(1) = "1"
countAndSay(2) = RLE of "1" = "11"
countAndSay(3) = RLE of "11" = "21"
countAndSay(4) = RLE of "21" = "1211"
Если у вас есть опыт работы с регулярными выражениями, вы можете обнаружить, что шаблон (.)\1* работает.
(.): оно определяет группу, содержащую один символ, который может быть чем угодно.
Таким образом, шаблон соответствует строкам, которые состоят из некоторого символа, а затем ноль или более повторений этого символа после его первого появления. Это то, что нам нужно.
Мы находим все совпадения с регулярным выражением, а затем конкатенируем результаты.
func countAndSay(n int) string {
s := "1"
for i := 2; i <= n; i++ {
t := ""
count := 1
for j := 1; j < len(s); j++ {
if s[j] == s[j-1] {
count++
} else {
t += strconv.Itoa(count) + string(s[j-1])
count = 1
}
}
t += strconv.Itoa(count) + string(s[len(s)-1])
s = t
}
return s
}Please open Telegram to view this post
VIEW IN TELEGRAM
❤1🤔1
{kind=link}
#medium
Задача: 39. Combination Sum
Дан массив уникальных целых чисел candidates и целевое целое число target. Верните список всех уникальных комбинаций из candidates, где выбранные числа в сумме дают target. Комбинации можно возвращать в любом порядке.
Одно и то же число может быть выбрано из массива candidates неограниченное количество раз. Две комбинации считаются уникальными, если частота хотя бы одного из выбранных чисел отличается.
Тестовые случаи сгенерированы таким образом, что количество уникальных комбинаций, дающих в сумме target, меньше 150 комбинаций для данного ввода.
Пример:
👨💻 Алгоритм:
1️⃣ Как видно, вышеописанный алгоритм обратного отслеживания разворачивается как обход дерева в глубину (DFS - Depth-First Search), который часто реализуется с помощью рекурсии.
Здесь мы определяем рекурсивную функцию backtrack(remain, comb, start) (на Python), которая заполняет комбинации, начиная с текущей комбинации (comb), оставшейся суммы для выполнения (remain) и текущего курсора (start) в списке кандидатов.
Следует отметить, что сигнатура рекурсивной функции немного отличается в Java, но идея остается той же.
2️⃣ Для первого базового случая рекурсивной функции, если remain == 0, то есть мы достигаем желаемой целевой суммы, поэтому мы можем добавить текущую комбинацию в итоговый список.
Как другой базовый случай, если remain < 0, то есть мы превышаем целевое значение, мы прекращаем исследование на этом этапе.
3️⃣ Помимо вышеупомянутых двух базовых случаев, мы затем продолжаем исследовать подсписок кандидатов, начиная с [start ... n].
Для каждого из кандидатов мы вызываем рекурсивную функцию саму с обновленными параметрами.
Конкретно, мы добавляем текущего кандидата в комбинацию.
С добавленным кандидатом у нас теперь меньше суммы для выполнения, то есть remain - candidate.
Для следующего исследования мы все еще начинаем с текущего курсора start.
В конце каждого исследования мы делаем откат, удаляя кандидата из комбинации.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 39. Combination Sum
Дан массив уникальных целых чисел candidates и целевое целое число target. Верните список всех уникальных комбинаций из candidates, где выбранные числа в сумме дают target. Комбинации можно возвращать в любом порядке.
Одно и то же число может быть выбрано из массива candidates неограниченное количество раз. Две комбинации считаются уникальными, если частота хотя бы одного из выбранных чисел отличается.
Тестовые случаи сгенерированы таким образом, что количество уникальных комбинаций, дающих в сумме target, меньше 150 комбинаций для данного ввода.
Пример:
Input: candidates = [2,3,5], target = 8
Output: [[2,2,2,2],[2,3,3],[3,5]]
Здесь мы определяем рекурсивную функцию backtrack(remain, comb, start) (на Python), которая заполняет комбинации, начиная с текущей комбинации (comb), оставшейся суммы для выполнения (remain) и текущего курсора (start) в списке кандидатов.
Следует отметить, что сигнатура рекурсивной функции немного отличается в Java, но идея остается той же.
Как другой базовый случай, если remain < 0, то есть мы превышаем целевое значение, мы прекращаем исследование на этом этапе.
Для каждого из кандидатов мы вызываем рекурсивную функцию саму с обновленными параметрами.
Конкретно, мы добавляем текущего кандидата в комбинацию.
С добавленным кандидатом у нас теперь меньше суммы для выполнения, то есть remain - candidate.
Для следующего исследования мы все еще начинаем с текущего курсора start.
В конце каждого исследования мы делаем откат, удаляя кандидата из комбинации.
func combinationSum(candidates []int, target int) [][]int {
var results [][]int
var comb []int
backtrack(target, comb, 0, candidates, &results)
return results
}
func backtrack(
remain int,
comb []int,
start int,
candidates []int,
results *[][]int,
) {
if remain == 0 {
newComb := make([]int, len(comb))
copy(newComb, comb)
*results = append(*results, newComb)
return
} else if remain < 0 {
return
}
for i := start; i < len(candidates); i++ {
comb = append(comb, candidates[i])
backtrack(remain-candidates[i], comb, i, candidates, results)
comb = comb[:len(comb)-1]
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
❤2🔥1🤔1
{kind=link}
#medium
Задача: 40. Combination Sum II
Дана коллекция кандидатов (candidates) и целевое число (target). Найдите все уникальные комбинации в candidates, где числа кандидатов в сумме дают target.
Каждое число в candidates может быть использовано только один раз в комбинации.
Примечание: Набор решений не должен содержать повторяющихся комбинаций.
Пример:
👨💻 Алгоритм:
1️⃣ Во-первых, мы создаём таблицу счётчиков из предоставленного списка чисел. Затем мы используем эту таблицу счётчиков в процессе обратного поиска, который мы определяем как функцию
2️⃣ При каждом вызове функции обратного поиска мы сначала проверяем, достигли ли мы целевой суммы (то есть
3️⃣ Если осталась сумма для заполнения, мы затем перебираем текущую таблицу счётчиков, чтобы выбрать следующего кандидата. После выбора кандидата мы продолжаем исследование, вызывая функцию
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 40. Combination Sum II
Дана коллекция кандидатов (candidates) и целевое число (target). Найдите все уникальные комбинации в candidates, где числа кандидатов в сумме дают target.
Каждое число в candidates может быть использовано только один раз в комбинации.
Примечание: Набор решений не должен содержать повторяющихся комбинаций.
Пример:
Input: candidates = [10,1,2,7,6,1,5], target = 8
Output:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
backtrack(comb, remain, curr, candidate_groups, results). Для сохранения состояния на каждом этапе обратного поиска мы используем несколько параметров в функции:comb: комбинация, которую мы построили на данный момент.remain: оставшаяся сумма, которую нам нужно заполнить, чтобы достичь целевой суммы.curr: курсор, который указывает на текущую группу чисел, используемую из таблицы счётчиков.counter: текущая таблица счётчиков.results: окончательные комбинации, которые достигают целевой суммы.sum(comb) = target), и нужно ли прекратить исследование, потому что сумма текущей комбинации превышает желаемую целевую сумму.backtrack() с обновлёнными состояниями. Более важно, что в конце каждого исследования нам нужно вернуть состояние, которое мы обновили ранее, чтобы начать с чистого листа для следующего исследования. Именно из-за этой операции обратного поиска алгоритм получил своё название.func combinationSum2(candidates []int, target int) [][]int {
results := [][]int{}
comb := []int{}
counter := map[int]int{}
for _, candidate := range candidates {
counter[candidate]++
}
counterKeys := make([]int, 0, len(counter))
for k := range counter {
counterKeys = append(counterKeys, k)
}
sort.Ints(counterKeys)
var backtrack func(int, int)
backtrack = func(start int, remain int) {
if remain == 0 {
c := make([]int, len(comb))
copy(c, comb)
results = append(results, c)
return
}
if remain < 0 {
return
}
for i := start; i < len(counterKeys); i++ {
candidate := counterKeys[i]
if counter[candidate] > 0 {
comb = append(comb, candidate)
counter[candidate]--
backtrack(i, remain-candidate)
comb = comb[:len(comb)-1]
counter[candidate]++
}
}
}
backtrack(0, target)
return results
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍2🔥1🤔1
#hard
Задача: 41. First Missing Positive
Дан неотсортированный массив целых чисел nums. Верните наименьшее положительное целое число, которого нет в массиве nums.
Необходимо реализовать алгоритм, который работает за время O(n) и использует O(1) дополнительной памяти.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализировать переменную n длиной массива nums. Создать массив seen размером n + 1. Отметить элементы в массиве nums как просмотренные в массиве seen.
Для каждого числа num в массиве nums, если num больше 0 и меньше или равно n, установить seen[num] в значение true.
2️⃣ Найти наименьшее недостающее положительное число:
Проитерировать от 1 до n, и если seen[i] не равно true, вернуть i как наименьшее недостающее положительное число.
3️⃣ Если массив seen содержит все элементы от 1 до n, вернуть n + 1 как наименьшее недостающее положительное число.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 41. First Missing Positive
Дан неотсортированный массив целых чисел nums. Верните наименьшее положительное целое число, которого нет в массиве nums.
Необходимо реализовать алгоритм, который работает за время O(n) и использует O(1) дополнительной памяти.
Пример:
Input: nums = [3,4,-1,1]
Output: 2
Explanation: 1 is in the array but 2 is missing.
Для каждого числа num в массиве nums, если num больше 0 и меньше или равно n, установить seen[num] в значение true.
Проитерировать от 1 до n, и если seen[i] не равно true, вернуть i как наименьшее недостающее положительное число.
func firstMissingPositive(nums []int) int {
n := len(nums)
seen := make([]bool, n+1)
for _, num := range nums {
if num > 0 && num <= n {
seen[num] = true
}
}
for i := 1; i <= n; i++ {
if !seen[i] {
return i
}
}
return n + 1
}Please open Telegram to view this post
VIEW IN TELEGRAM
🔥1🤔1