#medium
Задача: 537. Complex Number Multiplication
Комплексное число можно представить в виде строки в формате "real+imaginaryi", где:
real — это действительная часть и является целым числом в диапазоне [-100, 100].
imaginary — это мнимая часть и является целым числом в диапазоне [-100, 100].
i^2 == -1.
Даны два комплексных числа num1 и num2 в виде строк, верните строку комплексного числа, представляющую их произведение.
Пример:
👨💻 Алгоритм:
1⃣ Извлечение реальной и мнимой частей:
Разделите строки a и b на реальные и мнимые части, используя символы '+' и 'i'.
2⃣ Вычисление произведения:
Переведите извлечённые части в целые числа.
Используйте формулу для умножения комплексных чисел: (a+ib)×(x+iy)=ax−by+i(bx+ay).
3⃣ Формирование строки результата:
Создайте строку в требуемом формате с реальной и мнимой частями произведения и верните её.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 537. Complex Number Multiplication
Комплексное число можно представить в виде строки в формате "real+imaginaryi", где:
real — это действительная часть и является целым числом в диапазоне [-100, 100].
imaginary — это мнимая часть и является целым числом в диапазоне [-100, 100].
i^2 == -1.
Даны два комплексных числа num1 и num2 в виде строк, верните строку комплексного числа, представляющую их произведение.
Пример:
Input: num1 = "1+1i", num2 = "1+1i"
Output: "0+2i"
Explanation: (1 + i) * (1 + i) = 1 + i2 + 2 * i = 2i, and you need convert it to the form of 0+2i.
Разделите строки a и b на реальные и мнимые части, используя символы '+' и 'i'.
Переведите извлечённые части в целые числа.
Используйте формулу для умножения комплексных чисел: (a+ib)×(x+iy)=ax−by+i(bx+ay).
Создайте строку в требуемом формате с реальной и мнимой частями произведения и верните её.
import (
"fmt"
"strconv"
"strings"
)
func complexNumberMultiply(a string, b string) string {
x := strings.Split(a, "+")
y := strings.Split(b, "+")
a_real, _ := strconv.Atoi(x[0])
a_img, _ := strconv.Atoi(x[1][:len(x[1])-1])
b_real, _ := strconv.Atoi(y[0])
b_img, _ := strconv.Atoi(y[1][:len(y[1])-1])
realPart := a_real * b_real - a_img * b_img
imaginaryPart := a_real * b_img + a_img * b_real
return fmt.Sprintf("%d+%di", realPart, imaginaryPart)
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#medium
Задача: 583. Delete Operation for Two Strings
Даны две строки word1 и word2, вернуть минимальное количество шагов, необходимых для того, чтобы сделать word1 и word2 одинаковыми.
На одном шаге можно удалить ровно один символ в любой строке.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация массива:
Создайте одномерный массив dp для хранения минимального количества удалений, необходимых для уравнивания строк word1 и word2.
2⃣ Заполнение массива:
Используйте временный массив temp для обновления значений dp, представляющих текущую строку. Обновите temp с использованием значений dp предыдущей строки.
3⃣ Обновление и результат:
Скопируйте временный массив temp обратно в dp после обработки каждой строки. В конце верните значение из dp, представляющее минимальное количество удалений.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 583. Delete Operation for Two Strings
Даны две строки word1 и word2, вернуть минимальное количество шагов, необходимых для того, чтобы сделать word1 и word2 одинаковыми.
На одном шаге можно удалить ровно один символ в любой строке.
Пример:
Input: word1 = "sea", word2 = "eat"
Output: 2
Explanation: You need one step to make "sea" to "ea" and another step to make "eat" to "ea".
Создайте одномерный массив dp для хранения минимального количества удалений, необходимых для уравнивания строк word1 и word2.
Используйте временный массив temp для обновления значений dp, представляющих текущую строку. Обновите temp с использованием значений dp предыдущей строки.
Скопируйте временный массив temp обратно в dp после обработки каждой строки. В конце верните значение из dp, представляющее минимальное количество удалений.
func minDistance(word1 string, word2 string) int {
m, n := len(word1), len(word2)
dp := make([]int, n+1)
for i := 0; i <= m; i++ {
temp := make([]int, n+1)
for j := 0; j <= n; j++ {
if i == 0 || j == 0 {
temp[j] = i + j
} else if word1[i-1] == word2[j-1] {
temp[j] = dp[j-1]
} else {
temp[j] = 1 + min(dp[j], temp[j-1])
}
}
dp = temp
}
return dp[n]
}
func min(a, b int) int {
if a < b {
return a
}
return b
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1🤔1
{kind=link}
#hard
Задача: 587. Erect the Fence
Вам дан массив trees, где trees[i] = [xi, yi] представляет местоположение дерева в саду.
Оградите весь сад с использованием минимальной длины веревки, так как это дорого. Сад хорошо огорожен только в том случае, если все деревья окружены.
Верните координаты деревьев, которые находятся точно на периметре ограды. Вы можете вернуть ответ в любом порядке.
Пример:
👨💻 Алгоритм:
1⃣ Сортировка точек и построение нижней оболочки:
Отсортируйте точки по их x-координатам, а в случае совпадения x-координат, по y-координатам.
Постройте нижнюю оболочку, добавляя точки к оболочке и удаляя последние точки, если они не образуют против часовой стрелки поворот.
2⃣ Построение верхней оболочки:
Пройдитесь по точкам в обратном порядке, чтобы построить верхнюю оболочку.
Добавляйте точки к оболочке и удаляйте последние точки, если они не образуют против часовой стрелки поворот.
3⃣ Удаление дублирующих элементов и возврат результата:
Используйте HashSet, чтобы удалить дублирующиеся точки из стека.
Преобразуйте результат в массив и верните его.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 587. Erect the Fence
Вам дан массив trees, где trees[i] = [xi, yi] представляет местоположение дерева в саду.
Оградите весь сад с использованием минимальной длины веревки, так как это дорого. Сад хорошо огорожен только в том случае, если все деревья окружены.
Верните координаты деревьев, которые находятся точно на периметре ограды. Вы можете вернуть ответ в любом порядке.
Пример:
Input: trees = [[1,1],[2,2],[2,0],[2,4],[3,3],[4,2]]
Output: [[1,1],[2,0],[4,2],[3,3],[2,4]]
Explanation: All the trees will be on the perimeter of the fence except the tree at [2, 2], which will be inside the fence.
Отсортируйте точки по их x-координатам, а в случае совпадения x-координат, по y-координатам.
Постройте нижнюю оболочку, добавляя точки к оболочке и удаляя последние точки, если они не образуют против часовой стрелки поворот.
Пройдитесь по точкам в обратном порядке, чтобы построить верхнюю оболочку.
Добавляйте точки к оболочке и удаляйте последние точки, если они не образуют против часовой стрелки поворот.
Используйте HashSet, чтобы удалить дублирующиеся точки из стека.
Преобразуйте результат в массив и верните его.
import "sort"
func orientation(p, q, r []int) int {
return (q[1]-p[1])*(r[0]-q[0]) - (q[0]-p[0])*(r[1]-q[1])
}
func outerTrees(points [][]int) [][]int {
sort.Slice(points, func(i, j int) bool {
if points[i][0] == points[j][0] {
return points[i][1] < points[j][1]
}
return points[i][0] < points[j][0]
})
hull := [][]int{}
for _, point := range points {
for len(hull) >= 2 && orientation(hull[len(hull)-2], hull[len(hull)-1], point) > 0 {
hull = hull[:len(hull)-1]
}
hull = append(hull, point)
}
hull = hull[:len(hull)-1]
for i := len(points) - 1; i >= 0; i-- {
for len(hull) >= 2 && orientation(hull[len(hull)-2], hull[len(hull)-1], points[i]) > 0 {
hull = hull[:len(hull)-1]
}
hull = append(hull, points[i])
}
uniqueHull := make(map[[2]int]bool)
for _, h := range hull {
uniqueHull[[2]int{h[0], h[1]}] = true
}
res := [][]int{}
for k := range uniqueHull {
res = append(res, []int{k[0], k[1]})
}
return res
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1🤔1
{kind=link}
#medium
Задача: 304. Range Sum Query 2D - Immutable
Дана двумерная матрица matrix. Обработайте несколько запросов следующего типа:
Вычислите сумму элементов матрицы внутри прямоугольника, определенного его верхним левым углом (row1, col1) и нижним правым углом (row2, col2).
Реализуйте класс NumMatrix:
- NumMatrix(int[][] matrix) Инициализирует объект целочисленной матрицей matrix.- int sumRegion(int row1, int col1, int row2, int col2) Возвращает сумму элементов матрицы внутри прямоугольника, определенного его верхним левым углом (row1, col1) и нижним правым углом (row2, col2).
Необходимо разработать алгоритм, где метод sumRegion работает за O(1) по времени.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация:
Создайте двумерный массив sums размером (m + 1) x (n + 1), где m и n — размеры исходной матрицы matrix. Заполните этот массив нулями.
2⃣ Предварительное вычисление сумм:
Заполните массив sums, где каждый элемент sums[i][j] будет содержать сумму всех элементов матрицы от начала до позиции (i-1, j-1) включительно.
3⃣ Вычисление диапазонной суммы:
Для каждого запроса суммы элементов внутри прямоугольника, определенного его углами (row1, col1) и (row2, col2), используйте предварительно вычисленный массив sums для получения результата за O(1) времени.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 304. Range Sum Query 2D - Immutable
Дана двумерная матрица matrix. Обработайте несколько запросов следующего типа:
Вычислите сумму элементов матрицы внутри прямоугольника, определенного его верхним левым углом (row1, col1) и нижним правым углом (row2, col2).
Реализуйте класс NumMatrix:
- NumMatrix(int[][] matrix) Инициализирует объект целочисленной матрицей matrix.- int sumRegion(int row1, int col1, int row2, int col2) Возвращает сумму элементов матрицы внутри прямоугольника, определенного его верхним левым углом (row1, col1) и нижним правым углом (row2, col2).
Необходимо разработать алгоритм, где метод sumRegion работает за O(1) по времени.
Пример:
Input
["NumMatrix", "sumRegion", "sumRegion", "sumRegion"]
[[[[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]], [2, 1, 4, 3], [1, 1, 2, 2], [1, 2, 2, 4]]
Создайте двумерный массив sums размером (m + 1) x (n + 1), где m и n — размеры исходной матрицы matrix. Заполните этот массив нулями.
Заполните массив sums, где каждый элемент sums[i][j] будет содержать сумму всех элементов матрицы от начала до позиции (i-1, j-1) включительно.
Для каждого запроса суммы элементов внутри прямоугольника, определенного его углами (row1, col1) и (row2, col2), используйте предварительно вычисленный массив sums для получения результата за O(1) времени.
package main
type NumMatrix struct {
dp [][]int
}
func Constructor(matrix [][]int) NumMatrix {
if len(matrix) == 0 || len(matrix[0]) == 0 {
return NumMatrix{}
}
m, n := len(matrix), len(matrix[0])
dp := make([][]int, m+1)
for i := range dp {
dp[i] = make([]int, n+1)
}
for r := 0; r < m; r++ {
for c := 0; c < n; c++ {
dp[r+1][c+1] = dp[r+1][c] + dp[r][c+1] + matrix[r][c] - dp[r][c]
}
}
return NumMatrix{dp}
}
func (this *NumMatrix) SumRegion(row1, col1, row2, col2 int) int {
return this.dp[row2+1][col2+1] - this.dp[row1][col2+1] - this.dp[row2+1][col1] + this.dp[row1][col1]
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#hard
Задача: 588. Design In-Memory File System
Спроектируйте структуру данных, которая симулирует файловую систему в памяти.
Реализуйте класс FileSystem:
FileSystem() Инициализирует объект системы.
List<String> ls(String path)
Если path является путем к файлу, возвращает список, содержащий только имя этого файла.
Если path является путем к директории, возвращает список имен файлов и директорий в этой директории.
Ответ должен быть в лексикографическом порядке.
void mkdir(String path) Создает новую директорию согласно заданному пути. Заданная директория не существует. Если промежуточные директории в пути не существуют, вы также должны создать их.
void addContentToFile(String filePath, String content)
Если filePath не существует, создает файл, содержащий заданный контент.
Если filePath уже существует, добавляет заданный контент к исходному содержимому.
String readContentFromFile(String filePath) Возвращает содержимое файла по пути filePath.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация файловой системы:
Создайте класс FileSystem, который будет содержать вложенный класс File. Класс File будет представлять либо файл, либо директорию, содержать флаг isfile, словарь files и строку content.
2⃣ Обработка команд:
Реализуйте метод ls, который возвращает список файлов и директорий в указанном пути, либо имя файла, если указанный путь является файлом.
Реализуйте метод mkdir, который создаёт директории по указанному пути. Если промежуточные директории не существуют, создайте их.
Реализуйте метод addContentToFile, который добавляет содержимое в файл по указанному пути. Если файл не существует, создайте его.
Реализуйте метод readContentFromFile, который возвращает содержимое файла по указанному пути.
3⃣ Обработка путей и работа с файлами/директориями:
Используйте метод split для разделения пути на составляющие и навигации по дереву директорий и файлов.
Для каждой команды выполняйте соответствующие операции по созданию, чтению или записи содержимого файлов и директорий.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 588. Design In-Memory File System
Спроектируйте структуру данных, которая симулирует файловую систему в памяти.
Реализуйте класс FileSystem:
FileSystem() Инициализирует объект системы.
List<String> ls(String path)
Если path является путем к файлу, возвращает список, содержащий только имя этого файла.
Если path является путем к директории, возвращает список имен файлов и директорий в этой директории.
Ответ должен быть в лексикографическом порядке.
void mkdir(String path) Создает новую директорию согласно заданному пути. Заданная директория не существует. Если промежуточные директории в пути не существуют, вы также должны создать их.
void addContentToFile(String filePath, String content)
Если filePath не существует, создает файл, содержащий заданный контент.
Если filePath уже существует, добавляет заданный контент к исходному содержимому.
String readContentFromFile(String filePath) Возвращает содержимое файла по пути filePath.
Пример:
Input
["FileSystem", "ls", "mkdir", "addContentToFile", "ls", "readContentFromFile"]
[[], ["/"], ["/a/b/c"], ["/a/b/c/d", "hello"], ["/"], ["/a/b/c/d"]]
Output
[null, [], null, null, ["a"], "hello"]
Explanation
FileSystem fileSystem = new FileSystem();
fileSystem.ls("/"); // return []
fileSystem.mkdir("/a/b/c");
fileSystem.addContentToFile("/a/b/c/d", "hello");
fileSystem.ls("/"); // return ["a"]
fileSystem.readContentFromFile("/a/b/c/d"); // return "hello"
Создайте класс FileSystem, который будет содержать вложенный класс File. Класс File будет представлять либо файл, либо директорию, содержать флаг isfile, словарь files и строку content.
Реализуйте метод ls, который возвращает список файлов и директорий в указанном пути, либо имя файла, если указанный путь является файлом.
Реализуйте метод mkdir, который создаёт директории по указанному пути. Если промежуточные директории не существуют, создайте их.
Реализуйте метод addContentToFile, который добавляет содержимое в файл по указанному пути. Если файл не существует, создайте его.
Реализуйте метод readContentFromFile, который возвращает содержимое файла по указанному пути.
Используйте метод split для разделения пути на составляющие и навигации по дереву директорий и файлов.
Для каждой команды выполняйте соответствующие операции по созданию, чтению или записи содержимого файлов и директорий.
package main
import (
"sort"
"strings"
)
type File struct {
isFile bool
files map[string]*File
content string
}
type FileSystem struct {
root *File
}
func Constructor() FileSystem {
return FileSystem{root: &File{files: make(map[string]*File)}}
}
func (this *FileSystem) navigate(path string) *File {
t := this.root
if path != "/" {
dirs := strings.Split(path, "/")
for _, dir := range dirs {
if dir != "" {
if _, ok := t.files[dir]; !ok {
t.files[dir] = &File{files: make(map[string]*File)}
}
t = t.files[dir]
}
}
}
return t
}
func (this *FileSystem) Ls(path string) []string {
t := this.navigate(path)
if t.isFile {
return []string{path[strings.LastIndex(path, "/")+1:]}
}
var res []string
for name := range t.files {
res = append(res, name)
}
sort.Strings(res)
return res
}
func (this *FileSystem) Mkdir(path string) {
this.navigate(path)
}
func (this *FileSystem) AddContentToFile(filePath string, content string) {
t := this.navigate(filePath)
t.isFile = true
t.content += content
}
func (this *FileSystem) ReadContentFromFile(filePath string) string {
return this.navigate(filePath).content
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 542. 01 Matrix
Дана бинарная матрица размера m x n, верните расстояние до ближайшего нуля для каждой ячейки.
Расстояние между двумя соседними ячейками равно 1.
Пример:
👨💻 Алгоритм:
1⃣ Создайте копию матрицы mat, назовем её matrix. Используйте структуру данных seen для пометки уже посещенных узлов и очередь для выполнения BFS. Поместите все узлы с 0 в очередь и отметьте их в seen.
2⃣ Выполните BFS:
Пока очередь не пуста, извлекайте текущие row, col, steps из очереди.
Итеративно пройдите по четырем направлениям. Для каждой nextRow, nextCol проверьте, находятся ли они в пределах границ и не были ли они уже посещены в seen.
3⃣ Если так, установите matrix[nextRow][nextCol] = steps + 1 и поместите nextRow, nextCol, steps + 1 в очередь. Также отметьте nextRow, nextCol в seen. Верните matrix.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 542. 01 Matrix
Дана бинарная матрица размера m x n, верните расстояние до ближайшего нуля для каждой ячейки.
Расстояние между двумя соседними ячейками равно 1.
Пример:
Input: mat = [[0,0,0],[0,1,0],[0,0,0]]
Output: [[0,0,0],[0,1,0],[0,0,0]]
Пока очередь не пуста, извлекайте текущие row, col, steps из очереди.
Итеративно пройдите по четырем направлениям. Для каждой nextRow, nextCol проверьте, находятся ли они в пределах границ и не были ли они уже посещены в seen.
package main
import (
"container/list"
)
type Solution struct {
m, n int
directions [4][2]int
}
func Constructor() Solution {
return Solution{
directions: [4][2]int{
{0, 1},
{1, 0},
{0, -1},
{-1, 0},
},
}
}
func (s *Solution) updateMatrix(mat [][]int) [][]int {
s.m = len(mat)
s.n = len(mat[0])
matrix := make([][]int, s.m)
seen := make([][]bool, s.m)
queue := list.New()
for i := 0; i < s.m; i++ {
matrix[i] = make([]int, s.n)
seen[i] = make([]bool, s.n)
for j := 0; j < s.n; j++ {
matrix[i][j] = mat[i][j]
if matrix[i][j] == 0 {
queue.PushBack([3]int{i, j, 0})
seen[i][j] = true
}
}
}
for queue.Len() > 0 {
curr := queue.Remove(queue.Front()).([3]int)
row, col, steps := curr[0], curr[1], curr[2]
for _, direction := range s.directions {
nextRow, nextCol := row+direction[0], col+direction[1]
if s.isValid(nextRow, nextCol) && !seen[nextRow][nextCol] {
seen[nextRow][nextCol] = true
queue.PushBack([3]int{nextRow, nextCol, steps + 1})
matrix[nextRow][nextCol] = steps + 1
}
}
}
return matrix
}
func (s *Solution) isValid(row, col int) bool {
return 0 <= row && row < s.m && 0 <= col && col < s.n
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#hard
Задача: 305. Number of Islands II
Дан пустой двумерный бинарный массив
Вы можете выполнить операцию "добавить землю", которая превращает воду в указанной позиции в сушу. Вам дан массив
Верните массив целых чисел
Остров окружен водой и образуется путем соединения соседних земель по горизонтали или вертикали. Вы можете считать, что все четыре края сетки окружены водой.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация:
Создайте массивы x[] = { -1, 1, 0, 0 } и y[] = { 0, 0, -1, 1 }, которые будут использоваться для нахождения соседей ячейки.
Создайте экземпляр UnionFind, например, dsu(m * n). Инициализируйте всех родителей значением -1. Используйте объединение по рангу, инициализируйте все ранги значением 0. Наконец, инициализируйте count = 0.
Создайте список целых чисел answer, где answer[i] будет хранить количество островов, образованных после превращения ячейки positions[i] в сушу.
2⃣ Обработка позиций:
Итерация по массиву positions. Для каждой позиции в positions:
Выполните линейное отображение, чтобы преобразовать двумерную позицию ячейки в landPosition = position[0] * n + position[1].
Используйте операцию addLand(landPosition), чтобы добавить landPosition как узел в граф. Эта функция также увеличит count.
Итерация по каждому соседу позиции. Соседа можно определить с помощью neighborX = position[0] + x[i] и neighborY = position[1] + y[i], где neighborX — координата X, а neighborY — координата Y соседней ячейки. Выполните линейное отображение соседней ячейки с помощью neighborPosition = neighborX * n + neighborY. Теперь, если на neighborPosition есть суша, т.е. isLand(neighborPosition) возвращает true, выполните объединение neighborPosition и landPosition. В объединении уменьшите count на 1.
3⃣ Определение количества островов:
Выполните операцию numberOfIslands, которая возвращает количество островов, образованных после превращения позиции в сушу. Добавьте это значение в answer.
Верните answer.
😎 Решение
Ставь 👍 и забирай 📚 Базу знаний
Задача: 305. Number of Islands II
Дан пустой двумерный бинарный массив
grid размером m x n. Этот массив представляет собой карту, где 0 означает воду, а 1 — сушу. Изначально все ячейки массива — водные (т.е. все ячейки содержат 0).Вы можете выполнить операцию "добавить землю", которая превращает воду в указанной позиции в сушу. Вам дан массив
positions, где positions[i] = [ri, ci] — позиция (ri, ci), в которой следует выполнить i-ю операцию.Верните массив целых чисел
answer, где answer[i] — количество островов после превращения ячейки (ri, ci) в сушу.Остров окружен водой и образуется путем соединения соседних земель по горизонтали или вертикали. Вы можете считать, что все четыре края сетки окружены водой.
Пример:
Input: m = 1, n = 1, positions = [[0,0]]
Output: [1]
Создайте массивы x[] = { -1, 1, 0, 0 } и y[] = { 0, 0, -1, 1 }, которые будут использоваться для нахождения соседей ячейки.
Создайте экземпляр UnionFind, например, dsu(m * n). Инициализируйте всех родителей значением -1. Используйте объединение по рангу, инициализируйте все ранги значением 0. Наконец, инициализируйте count = 0.
Создайте список целых чисел answer, где answer[i] будет хранить количество островов, образованных после превращения ячейки positions[i] в сушу.
Итерация по массиву positions. Для каждой позиции в positions:
Выполните линейное отображение, чтобы преобразовать двумерную позицию ячейки в landPosition = position[0] * n + position[1].
Используйте операцию addLand(landPosition), чтобы добавить landPosition как узел в граф. Эта функция также увеличит count.
Итерация по каждому соседу позиции. Соседа можно определить с помощью neighborX = position[0] + x[i] и neighborY = position[1] + y[i], где neighborX — координата X, а neighborY — координата Y соседней ячейки. Выполните линейное отображение соседней ячейки с помощью neighborPosition = neighborX * n + neighborY. Теперь, если на neighborPosition есть суша, т.е. isLand(neighborPosition) возвращает true, выполните объединение neighborPosition и landPosition. В объединении уменьшите count на 1.
Выполните операцию numberOfIslands, которая возвращает количество островов, образованных после превращения позиции в сушу. Добавьте это значение в answer.
Верните answer.
type UnionFind struct {
parent []int
rank []int
count int
}
func NewUnionFind(size int) *UnionFind {
uf := &UnionFind{parent: make([]int, size), rank: make([]int, size)}
for i := range uf.parent { uf.parent[i] = -1 }
return uf
}
func (uf *UnionFind) AddLand(x int) { if uf.parent[x] < 0 { uf.parent[x] = x; uf.count++ } }
func (uf *UnionFind) IsLand(x int) bool { return uf.parent[x] >= 0 }
func (uf *UnionFind) Find(x int) int { if uf.parent[x] != x { uf.parent[x] = uf.Find(uf.parent[x]) }; return uf.parent[x] }
func (uf *UnionFind) UnionSet(x, y int) { xset, yset := uf.Find(x), uf.Find(y)
if xset != yset { if uf.rank[xset] < uf.rank[yset] { uf.parent[xset] = yset } else { uf.parent[yset] = xset
if uf.rank[xset] == uf.rank[yset] { uf.rank[xset]++ } }; uf.count-- } }
func numIslands2(m int, n int, positions [][]int) []int {
dsu, dirs, answer := NewUnionFind(m * n), [][2]int{{-1, 0}, {1, 0}, {0, -1}, {0, 1}}, []int{}
for _, pos := range positions { land := pos[0]*n + pos[1]; dsu.AddLand(land)
for _, d := range dirs { nx, ny, neighbor := pos[0]+d[0], pos[1]+d[1], (pos[0]+d[0])*n+(pos[1]+d[1])
if nx >= 0 && nx < m && ny >= 0 && ny < n && dsu.IsLand(neighbor) { dsu.UnionSet(land, neighbor) } }
answer = append(answer, dsu.count) }
return answer
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 1530. Number of Good Leaf Nodes Pairs
Вам дан корень бинарного дерева и целое число distance. Пара двух различных листовых узлов бинарного дерева называется хорошей, если длина кратчайшего пути между ними меньше или равна distance.
Верните количество хороших пар листовых узлов в дереве.
Пример:
👨💻 Алгоритм:
1⃣ Инициализируйте список смежности для преобразования дерева в граф и множество для хранения листовых узлов. Используйте вспомогательный метод traverseTree для обхода дерева, чтобы построить граф и найти листовые узлы. В параметрах поддерживайте текущий узел, а также родительский узел. Если текущий узел является листом, добавьте его в множество. В списке смежности добавьте текущий узел в список соседей родительского узла и наоборот. Рекурсивно вызовите traverseTree для левого и правого дочернего узла текущего узла.
2⃣ Инициализируйте переменную ans для подсчета количества хороших пар листовых узлов. Итеративно переберите каждый листовой узел в множестве. Запустите BFS для текущего листового узла. BFS можно прервать досрочно, как только будут обнаружены все узлы, находящиеся на расстоянии от текущего листового узла. Увеличьте ans для каждого листового узла, найденного в каждом запуске BFS.
3⃣ Верните ans / 2. Мы считаем каждую пару дважды, поэтому нужно разделить на 2, чтобы получить фактическое количество.
😎 Решение🐍
Ставь 👍 и забирай 📚 Базу знаний
Задача: 1530. Number of Good Leaf Nodes Pairs
Вам дан корень бинарного дерева и целое число distance. Пара двух различных листовых узлов бинарного дерева называется хорошей, если длина кратчайшего пути между ними меньше или равна distance.
Верните количество хороших пар листовых узлов в дереве.
Пример:
Input: root = [1,2,3,null,4], distance = 3
Output: 1
Explanation: The leaf nodes of the tree are 3 and 4 and the length of the shortest path between them is 3. This is the only good pair.
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
func countPairs(root *TreeNode, distance int) int {
graph := make(map[*TreeNode][]*TreeNode)
leafNodes := make(map[*TreeNode]bool)
traverseTree(root, nil, graph, leafNodes)
ans := 0
for leaf := range leafNodes {
bfsQueue := []*TreeNode{leaf}
seen := make(map[*TreeNode]bool)
seen[leaf] = true
for i := 0; i <= distance; i++ {
size := len(bfsQueue)
for j := 0; j < size; j++ {
currNode := bfsQueue[0]
bfsQueue = bfsQueue[1:]
if leafNodes[currNode] && currNode != leaf {
ans++
}
for _, neighbor := range graph[currNode] {
if !seen[neighbor] {
bfsQueue = append(bfsQueue, neighbor)
seen[neighbor] = true
}
}
}
}
}
return ans / 2
}
func traverseTree(currNode, prevNode *TreeNode, graph map[*TreeNode][]*TreeNode, leafNodes map[*TreeNode]bool) {
if currNode == nil {
return
}
if currNode.Left == nil && currNode.Right == nil {
leafNodes[currNode] = true
}
if prevNode != nil {
graph[prevNode] = append(graph[prevNode], currNode)
graph[currNode] = append(graph[currNode], prevNode)
}
traverseTree(currNode.Left, currNode, graph, leafNodes)
traverseTree(currNode.Right, currNode, graph, leafNodes)
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#medium
Задача: 397. Integer Replacement
К положительному целому числу n можно применить одну из следующих операций: если n четное, замените n на n / 2. если n нечетное, замените n на n + 1 или n - 1. верните минимальное количество операций, необходимых для того, чтобы n стало 1.
Пример:
👨💻 Алгоритм:
1⃣ Начните с данного числа n и выполните одну из следующих операций:
Если n четное, замените n на n / 2.
Если n нечетное, замените n на n + 1 или n - 1.
2⃣ Используйте метод динамического программирования или жадный метод, чтобы найти минимальное количество операций, необходимых для достижения n = 1. Определите, какая операция (n + 1 или n - 1) является более эффективной для минимизации количества шагов.
3⃣ Продолжайте выполнять выбранные операции, пока n не станет равным 1. Считайте количество выполненных операций и верните это значение как результат.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 397. Integer Replacement
К положительному целому числу n можно применить одну из следующих операций: если n четное, замените n на n / 2. если n нечетное, замените n на n + 1 или n - 1. верните минимальное количество операций, необходимых для того, чтобы n стало 1.
Пример:
Input: n = 8
Output: 3
Explanation: 8 -> 4 -> 2 -> 1
Если n четное, замените n на n / 2.
Если n нечетное, замените n на n + 1 или n - 1.
func integerReplacement(n int) int {
memo := make(map[int]int)
return helper(n, memo)
}
func helper(n int, memo map[int]int) int {
if n == 1 {
return 0
}
if val, exists := memo[n]; exists {
return val
}
if n % 2 == 0 {
memo[n] = 1 + helper(n/2, memo)
} else {
memo[n] = 1 + min(helper(n+1, memo), helper(n-1, memo))
}
return memo[n]
}
func min(a, b int) int {
if a < b {
return a
}
return b
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#medium
Задача: 398. Random Pick Index
Из целочисленного массива nums с возможными дубликатами случайным образом выведите индекс заданного целевого числа. Можно предположить, что заданное целевое число должно существовать в массиве. Реализация класса Solution: Solution(int[] nums) Инициализирует объект с массивом nums. int pick(int target) Выбирает случайный индекс i из nums, где nums[i] == target. Если существует несколько допустимых i, то каждый индекс должен иметь равную вероятность возврата.
Пример:
👨💻 Алгоритм:
1⃣ Инициализируйте объект с массивом nums. Сохраните этот массив для дальнейшего использования.
2⃣ Реализуйте метод pick(target), который выбирает случайный индекс i из массива nums, где nums[i] равен target. Если таких индексов несколько, каждый из них должен иметь равную вероятность быть выбранным.
3⃣ Для реализации метода pick используйте алгоритм reservoir sampling для выбора случайного индекса.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 398. Random Pick Index
Из целочисленного массива nums с возможными дубликатами случайным образом выведите индекс заданного целевого числа. Можно предположить, что заданное целевое число должно существовать в массиве. Реализация класса Solution: Solution(int[] nums) Инициализирует объект с массивом nums. int pick(int target) Выбирает случайный индекс i из nums, где nums[i] == target. Если существует несколько допустимых i, то каждый индекс должен иметь равную вероятность возврата.
Пример:
Input
["Solution", "pick", "pick", "pick"]
[[[1, 2, 3, 3, 3]], [3], [1], [3]]
Output
[null, 4, 0, 2]
import (
"math/rand"
"time"
)
type Solution struct {
nums []int
}
func Constructor(nums []int) Solution {
rand.Seed(time.Now().UnixNano())
return Solution{nums: nums}
}
func (this *Solution) Pick(target int) int {
count := 0
result := -1
for i, num := range this.nums {
if num == target {
count++
if rand.Intn(count) == count-1 {
result = i
}
}
}
return result
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 399. Evaluate Division
Вам дан массив пар переменных equations и массив вещественных чисел values, где equations[i] = [Ai, Bi] и values[i] представляют уравнение Ai / Bi = values[i]. Каждая Ai или Bi - это строка, представляющая одну переменную. Вам также даны некоторые запросы, где queries[j] = [Cj, Dj] представляет j-й запрос, в котором вы должны найти ответ для Cj / Dj = ?. Верните ответы на все запросы. Если ни один ответ не может быть определен, верните -1.0. Замечание: входные данные всегда действительны. Можно предположить, что вычисление запросов не приведет к делению на ноль и что противоречия нет. Примечание: Переменные, которые не встречаются в списке уравнений, являются неопределенными, поэтому для них ответ не может быть определен.
Пример:
👨💻 Алгоритм:
1⃣ Создание графа:
Представьте каждую переменную как узел в графе.
Используйте уравнения для создания ребер между узлами, где каждое ребро имеет вес, равный значению уравнения (Ai / Bi = values[i]).
Создайте также обратные ребра с обратным весом (Bi / Ai = 1 / values[i]).
2⃣ Поиск пути:
Для каждого запроса используйте поиск в глубину (DFS) или поиск в ширину (BFS) для поиска пути от Cj до Dj.
Если путь найден, вычислите произведение весов вдоль пути, чтобы найти значение Cj / Dj.
Если путь не найден, верните -1.0.
3⃣ Обработка запросов:
Пройдитесь по всем запросам и используйте граф для вычисления результатов каждого запроса.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 399. Evaluate Division
Вам дан массив пар переменных equations и массив вещественных чисел values, где equations[i] = [Ai, Bi] и values[i] представляют уравнение Ai / Bi = values[i]. Каждая Ai или Bi - это строка, представляющая одну переменную. Вам также даны некоторые запросы, где queries[j] = [Cj, Dj] представляет j-й запрос, в котором вы должны найти ответ для Cj / Dj = ?. Верните ответы на все запросы. Если ни один ответ не может быть определен, верните -1.0. Замечание: входные данные всегда действительны. Можно предположить, что вычисление запросов не приведет к делению на ноль и что противоречия нет. Примечание: Переменные, которые не встречаются в списке уравнений, являются неопределенными, поэтому для них ответ не может быть определен.
Пример:
Input: equations = [["a","b"],["b","c"]], values = [2.0,3.0], queries = [["a","c"],["b","a"],["a","e"],["a","a"],["x","x"]]
Output: [6.00000,0.50000,-1.00000,1.00000,-1.00000]
Представьте каждую переменную как узел в графе.
Используйте уравнения для создания ребер между узлами, где каждое ребро имеет вес, равный значению уравнения (Ai / Bi = values[i]).
Создайте также обратные ребра с обратным весом (Bi / Ai = 1 / values[i]).
Для каждого запроса используйте поиск в глубину (DFS) или поиск в ширину (BFS) для поиска пути от Cj до Dj.
Если путь найден, вычислите произведение весов вдоль пути, чтобы найти значение Cj / Dj.
Если путь не найден, верните -1.0.
Пройдитесь по всем запросам и используйте граф для вычисления результатов каждого запроса.
package main
import "container/list"
func calcEquation(equations [][]string, values []float64, queries [][]string) []float64 {
graph := make(map[string]map[string]float64)
for i, equation := range equations {
A, B := equation[0], equation[1]
value := values[i]
if _, ok := graph[A]; !ok {
graph[A] = make(map[string]float64)
}
if _, ok := graph[B]; !ok {
graph[B] = make(map[string]float64)
}
graph[A][B] = value
graph[B][A] = 1.0 / value
}
bfs := func(start, end string) float64 {
if _, ok := graph[start]; !ok {
return -1.0
}
if _, ok := graph[end]; !ok {
return -1.0
}
q := list.New()
q.PushBack([2]interface{}{start, 1.0})
visited := make(map[string]bool)
for q.Len() > 0 {
e := q.Front()
q.Remove(e)
cur := e.Value.([2]interface{})
current, curProduct := cur[0].(string), cur[1].(float64)
if current == end {
return curProduct
}
visited[current] = true
for neighbor, value := range graph[current] {
if !visited[neighbor] {
q.PushBack([2]interface{}{neighbor, curProduct * value})
}
}
}
return -1.0
}
results := make([]float64, len(queries))
for i, query := range queries {
C, D := query[0], query[1]
results[i] = bfs(C, D)
}
return results
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#medium
Задача: 400. Nth Digit
Дано целое число n, вернуть n-ю цифру бесконечной последовательности чисел [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ...].
Пример:
👨💻 Алгоритм:
1⃣ Определение диапазона:
Начните с определения количества цифр в числах текущего диапазона (1-9, 10-99, 100-999 и т.д.).
Уменьшайте значение n, вычитая количество цифр в текущем диапазоне, пока не найдете диапазон, в который попадает n-я цифра.
2⃣ Нахождение конкретного числа:
Когда определите диапазон, найдите точное число, содержащее n-ю цифру.
Определите индекс цифры в этом числе.
3⃣ Возвращение n-й цифры:
Извлеките и верните n-ю цифру из найденного числа.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 400. Nth Digit
Дано целое число n, вернуть n-ю цифру бесконечной последовательности чисел [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ...].
Пример:
Input: n = 3
Output: 3
Начните с определения количества цифр в числах текущего диапазона (1-9, 10-99, 100-999 и т.д.).
Уменьшайте значение n, вычитая количество цифр в текущем диапазоне, пока не найдете диапазон, в который попадает n-я цифра.
Когда определите диапазон, найдите точное число, содержащее n-ю цифру.
Определите индекс цифры в этом числе.
Извлеките и верните n-ю цифру из найденного числа.
func findNthDigit(n int) int {
length, count, start := 1, 9, 1
for n > length * count {
n -= length * count
length++
count *= 10
start *= 10
}
start += (n - 1) / length
s := strconv.Itoa(start)
return int(s[(n - 1) % length] - '0')
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1🤔1
{kind=link}
#medium
Задача: 402. Remove K Digits
Если задана строка num, представляющая неотрицательное целое число num, и целое число k, верните наименьшее возможное целое число после удаления k цифр из num.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация:
Создайте стек для хранения цифр, которые будут образовывать минимальное число.
2⃣ Обработка каждой цифры:
Перебирайте каждую цифру в строке num.
Если текущая цифра меньше верхней цифры в стеке и у вас есть еще возможность удалить цифры (k > 0), удалите верхнюю цифру из стека.
Добавьте текущую цифру в стек.
Удаление оставшихся цифр:
Если после прохождения всей строки k еще больше нуля, удалите оставшиеся цифры из конца стека
3⃣ Формирование результата:
Постройте итоговое число из цифр в стеке и удалите ведущие нули.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 402. Remove K Digits
Если задана строка num, представляющая неотрицательное целое число num, и целое число k, верните наименьшее возможное целое число после удаления k цифр из num.
Пример:
Input: num = "1432219", k = 3
Output: "1219"
Создайте стек для хранения цифр, которые будут образовывать минимальное число.
Перебирайте каждую цифру в строке num.
Если текущая цифра меньше верхней цифры в стеке и у вас есть еще возможность удалить цифры (k > 0), удалите верхнюю цифру из стека.
Добавьте текущую цифру в стек.
Удаление оставшихся цифр:
Если после прохождения всей строки k еще больше нуля, удалите оставшиеся цифры из конца стека
Постройте итоговое число из цифр в стеке и удалите ведущие нули.
func removeKdigits(num string, k int) string {
stack := []byte{}
for i := 0; i < len(num); i++ {
for k > 0 && len(stack) > 0 && stack[len(stack)-1] > num[i] {
stack = stack[:len(stack)-1]
k--
}
stack = append(stack, num[i])
}
stack = stack[:len(stack)-k]
result := string(stack)
for len(result) > 1 && result[0] == '0' {
result = result[1:]
}
if result == "" {
return "0"
}
return result
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#hard
Задача: 403. Frog Jump
Если задана строка num, представляющая неотрицательное целое число num, и целое число k, верните наименьшее возможное целое число после удаления k цифр из num.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация и структура данных:
Создайте набор для хранения всех камней для быстрого доступа.
Используйте динамическое программирование с помощью словаря для отслеживания достижимых позиций и возможных прыжков.
2⃣ Итерация по камням:
Пройдитесь по каждому камню и для каждого возможного прыжка (k-1, k, k+1) проверьте, если он ведет на существующий камень.
Если такой камень существует, добавьте его в набор возможных прыжков.
3⃣ Проверка достижения последнего камня:
Если можно достичь последний камень с помощью одного из возможных прыжков, верните True.
Если после всех итераций последний камень не достигнут, верните False.Формирование результата:
Постройте итоговое число из цифр в стеке и удалите ведущие нули.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 403. Frog Jump
Если задана строка num, представляющая неотрицательное целое число num, и целое число k, верните наименьшее возможное целое число после удаления k цифр из num.
Пример:
Input: stones = [0,1,3,5,6,8,12,17]
Output: true
Создайте набор для хранения всех камней для быстрого доступа.
Используйте динамическое программирование с помощью словаря для отслеживания достижимых позиций и возможных прыжков.
Пройдитесь по каждому камню и для каждого возможного прыжка (k-1, k, k+1) проверьте, если он ведет на существующий камень.
Если такой камень существует, добавьте его в набор возможных прыжков.
Если можно достичь последний камень с помощью одного из возможных прыжков, верните True.
Если после всех итераций последний камень не достигнут, верните False.Формирование результата:
Постройте итоговое число из цифр в стеке и удалите ведущие нули.
func canCross(stones []int) bool {
dp := make(map[int]map[int]bool)
for _, stone := range stones {
dp[stone] = make(map[int]bool)
}
dp[0][0] = true
for _, stone := range stones {
for jump := range dp[stone] {
for step := jump - 1; step <= jump + 1; step++ {
if step > 0 && dp[stone + step] != nil {
dp[stone + step][step] = true
}
}
}
}
return len(dp[stones[len(stones) - 1]]) > 0
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#easy
Задача: 404. Sum of Left Leaves
Если задан корень бинарного дерева, верните сумму всех левых листьев. Лист - это узел, не имеющий детей. Левый лист - это лист, который является левым ребенком другого узла.
Пример:
👨💻 Алгоритм:
1⃣ Рекурсивный обход дерева:
Обходите дерево с помощью рекурсивной функции, которая принимает текущий узел и флаг, указывающий, является ли узел левым ребенком.
2⃣ Проверка листьев:
Если текущий узел является листом и флаг указывает, что это левый ребенок, добавьте значение узла к сумме.
3⃣ Рекурсивный вызов для детей:
Рекурсивно вызовите функцию для левого и правого детей текущего узла, передавая соответствующий флаг.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 404. Sum of Left Leaves
Если задан корень бинарного дерева, верните сумму всех левых листьев. Лист - это узел, не имеющий детей. Левый лист - это лист, который является левым ребенком другого узла.
Пример:
Input: root = [3,9,20,null,null,15,7]
Output: 24
Обходите дерево с помощью рекурсивной функции, которая принимает текущий узел и флаг, указывающий, является ли узел левым ребенком.
Если текущий узел является листом и флаг указывает, что это левый ребенок, добавьте значение узла к сумме.
Рекурсивно вызовите функцию для левого и правого детей текущего узла, передавая соответствующий флаг.
func sumOfLeftLeaves(root *TreeNode) int {
return dfs(root, false)
}
func dfs(node *TreeNode, isLeft bool) int {
if node == nil {
return 0
}
if node.Left == nil && node.Right == nil {
if isLeft {
return node.Val
}
return 0
}
return dfs(node.Left, true) + dfs(node.Right, false)
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#medium
Задача: 316. Remove Duplicate Letters
Дана строка
Пример:
👨💻 Алгоритм:
1⃣ Инициализация стека
Создайте стек, который будет хранить результат, построенный по мере итерации строки.
2⃣ Итерация по строке
На каждой итерации добавляйте текущий символ в стек, если он еще не был использован. Перед добавлением текущего символа удаляйте как можно больше символов из вершины стека, если это возможно и улучшает лексикографический порядок.
3⃣ Удаление символов
Удаляйте символы с вершины стека при выполнении следующих условий:
Символ на вершине стека больше текущего символа.
Символ может быть удален, так как он встречается позже в строке.
На каждом этапе итерации по строке жадно минимизируйте содержимое стека.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 316. Remove Duplicate Letters
Дана строка
s, удалите повторяющиеся буквы так, чтобы каждая буква появилась один раз и только один раз. Вы должны сделать так, чтобы результат был наименьшим в лексикографическом порядке среди всех возможных результатов.Пример:
Input: s = "bcabc"
Output: "abc"
Создайте стек, который будет хранить результат, построенный по мере итерации строки.
На каждой итерации добавляйте текущий символ в стек, если он еще не был использован. Перед добавлением текущего символа удаляйте как можно больше символов из вершины стека, если это возможно и улучшает лексикографический порядок.
Удаляйте символы с вершины стека при выполнении следующих условий:
Символ на вершине стека больше текущего символа.
Символ может быть удален, так как он встречается позже в строке.
На каждом этапе итерации по строке жадно минимизируйте содержимое стека.
func removeDuplicateLetters(s string) string {
stack := []rune{}
seen := make(map[rune]bool)
lastOccurrence := make(map[rune]int)
for i, c := range s {
lastOccurrence[c] = i
}
for i, c := range s {
if !seen[c] {
for len(stack) > 0 && c < stack[len(stack)-1] && i < lastOccurrence[stack[len(stack)-1]] {
seen[stack[len(stack)-1]] = false
stack = stack[:len(stack)-1]
}
seen[c] = true
stack = append(stack, c)
}
}
return string(stack)
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#hard
Задача: 317. Shortest Distance from All Buildings
Дана сетка m x n, содержащая значения 0, 1 или 2, где:
каждое 0 обозначает пустую землю, по которой можно свободно проходить,
каждое 1 обозначает здание, через которое нельзя пройти,
каждое 2 обозначает препятствие, через которое нельзя пройти.
Вы хотите построить дом на пустой земле, чтобы он достиг всех зданий с минимальным суммарным расстоянием. Можно перемещаться только вверх, вниз, влево и вправо.
Верните минимальное суммарное расстояние для такого дома. Если построить такой дом невозможно согласно указанным правилам, верните -1.
Суммарное расстояние — это сумма расстояний между домами друзей и точкой встречи.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация и запуск BFS
Для каждой пустой ячейки (0) в сетке grid запустите BFS, обходя все соседние ячейки в 4 направлениях, которые не заблокированы и не посещены, отслеживая расстояние от начальной ячейки.
2⃣ Обработка BFS и обновление расстояний
При достижении здания (1) увеличьте счетчик достигнутых домов housesReached и суммарное расстояние distanceSum на текущее расстояние. Если housesReached равно общему количеству зданий, верните суммарное расстояние.
Если BFS не может достигнуть всех домов, установите значение каждой посещенной пустой ячейки в 2, чтобы не запускать новый BFS из этих ячеек, и верните INT_MAX.
3⃣ Обновление и возврат минимального расстояния
Обновите минимальное расстояние (minDistance) после каждого вызова BFS. Если возможно достигнуть все дома из любой пустой ячейки, верните найденное минимальное расстояние. В противном случае, верните -1.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 317. Shortest Distance from All Buildings
Дана сетка m x n, содержащая значения 0, 1 или 2, где:
каждое 0 обозначает пустую землю, по которой можно свободно проходить,
каждое 1 обозначает здание, через которое нельзя пройти,
каждое 2 обозначает препятствие, через которое нельзя пройти.
Вы хотите построить дом на пустой земле, чтобы он достиг всех зданий с минимальным суммарным расстоянием. Можно перемещаться только вверх, вниз, влево и вправо.
Верните минимальное суммарное расстояние для такого дома. Если построить такой дом невозможно согласно указанным правилам, верните -1.
Суммарное расстояние — это сумма расстояний между домами друзей и точкой встречи.
Пример:
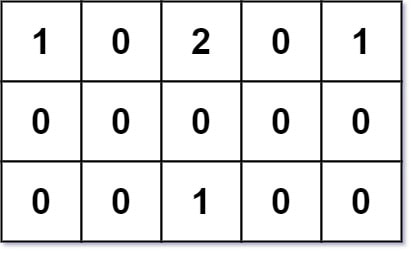
Input: grid = [[1,0,2,0,1],[0,0,0,0,0],[0,0,1,0,0]]
Output: 7
Для каждой пустой ячейки (0) в сетке grid запустите BFS, обходя все соседние ячейки в 4 направлениях, которые не заблокированы и не посещены, отслеживая расстояние от начальной ячейки.
При достижении здания (1) увеличьте счетчик достигнутых домов housesReached и суммарное расстояние distanceSum на текущее расстояние. Если housesReached равно общему количеству зданий, верните суммарное расстояние.
Если BFS не может достигнуть всех домов, установите значение каждой посещенной пустой ячейки в 2, чтобы не запускать новый BFS из этих ячеек, и верните INT_MAX.
Обновите минимальное расстояние (minDistance) после каждого вызова BFS. Если возможно достигнуть все дома из любой пустой ячейки, верните найденное минимальное расстояние. В противном случае, верните -1.
import (
"math"
)
func bfs(grid [][]int, row, col, totalHouses int) int {
dirs := [][2]int{{1, 0}, {-1, 0}, {0, 1}, {0, -1}}
rows, cols := len(grid), len(grid[0])
distanceSum, housesReached, steps := 0, 0, 0
q := [][3]int{{row, col, 0}}
vis := make([][]bool, rows)
for i := range vis {
vis[i] = make([]bool, cols)
}
vis[row][col] = true
for len(q) > 0 && housesReached != totalHouses {
r, c, steps := q[0][0], q[0][1], q[0][2]
q = q[1:]
if grid[r][c] == 1 {
distanceSum += steps
housesReached++
continue
}
for _, dir := range dirs {
nr, nc := r+dir[0], c+dir[1]
if nr >= 0 && nc >= 0 && nr < rows && nc < cols && !vis[nr][nc] && grid[nr][nc] != 2 {
vis[nr][nc] = true
q = append(q, [3]int{nr, nc, steps + 1})
}
}
}
if housesReached != totalHouses {
for r := 0; r < rows; r++ {
for c := 0; c < cols; c++ {
if grid[r][c] == 0 && vis[r][c] {
grid[r][c] = 2
}
}
}
return math.MaxInt32
}
return distanceSum
}
func shortestDistance(grid [][]int) int {
minDistance := math.MaxInt32
rows, cols := len(grid), len(grid[0])
totalHouses := 0
for _, row := range grid {
for _, cell := range row {
if cell == 1 {
totalHouses++
}
}
}
for r := 0; r < rows; r++ {
for c := 0; c < cols; c++ {
if grid[r][c] == 0 {
minDistance = min(minDistance, bfs(grid, r, c, totalHouses))
}
}
}
if minDistance == math.MaxInt32 {
return -1
}
return minDistance
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#medium
Задача: 318. Maximum Product of Word Lengths
Дан массив строк
Пример:
👨💻 Алгоритм:
1⃣ Предварительная обработка масок и длин
Вычислите битовые маски для всех слов и сохраните их в массиве masks. Сохраните длины всех слов в массиве lens.
2⃣ Сравнение слов и проверка общих букв
Сравните каждое слово с каждым последующим словом. Если два слова не имеют общих букв (проверка с использованием масок: (masks[i] & masks[j]) == 0), обновите максимальное произведение maxProd.
3⃣ Возврат результата
Верните максимальное значение произведения maxProd.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 318. Maximum Product of Word Lengths
Дан массив строк
words, верните максимальное значение произведения длины word[i] на длину word[j], где два слова не имеют общих букв. Если таких двух слов не существует, верните 0.Пример:
Input: words = ["abcw","baz","foo","bar","xtfn","abcdef"]
Output: 16
Explanation: The two words can be "abcw", "xtfn".
Вычислите битовые маски для всех слов и сохраните их в массиве masks. Сохраните длины всех слов в массиве lens.
Сравните каждое слово с каждым последующим словом. Если два слова не имеют общих букв (проверка с использованием масок: (masks[i] & masks[j]) == 0), обновите максимальное произведение maxProd.
Верните максимальное значение произведения maxProd.
func maxProduct(words []string) int {
n := len(words)
masks := make([]int, n)
lens := make([]int, n)
for i := 0; i < n; i++ {
bitmask := 0
for _, ch := range words[i] {
bitmask |= 1 << (ch - 'a')
}
masks[i] = bitmask
lens[i] = len(words[i])
}
maxVal := 0
for i := 0; i < n; i++ {
for j := i + 1; j < n; j++ {
if masks[i] & masks[j] == 0 {
maxVal = max(maxVal, lens[i] * lens[j])
}
}
}
return maxVal
}
func max(a, b int) int {
if a > b {
return a
}
return b
}Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 319. Bulb Switcher
Есть n лампочек, которые изначально выключены. Сначала вы включаете все лампочки, затем выключаете каждую вторую лампочку.
На третьем раунде вы переключаете каждую третью лампочку (включаете, если она выключена, или выключаете, если она включена). На i-ом раунде вы переключаете каждую i-ую лампочку. На n-ом раунде вы переключаете только последнюю лампочку.
Верните количество лампочек, которые будут включены после n раундов.
Пример:
👨💻 Алгоритм:
1⃣ Инициализация
Лампочка остается включенной, если она переключалась нечетное количество раз.
Лампочка будет переключаться на каждом делителе её номера.
2⃣ Определение состояния лампочки
Лампочка останется включенной только в том случае, если у нее нечетное количество делителей, что возможно только для квадратных чисел.
3⃣ Подсчет включенных лампочек
Количество лампочек, которые будут включены после n раундов.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 319. Bulb Switcher
Есть n лампочек, которые изначально выключены. Сначала вы включаете все лампочки, затем выключаете каждую вторую лампочку.
На третьем раунде вы переключаете каждую третью лампочку (включаете, если она выключена, или выключаете, если она включена). На i-ом раунде вы переключаете каждую i-ую лампочку. На n-ом раунде вы переключаете только последнюю лампочку.
Верните количество лампочек, которые будут включены после n раундов.
Пример:
Input: n = 3
Output: 1
Explanation: At first, the three bulbs are [off, off, off].
After the first round, the three bulbs are [on, on, on].
After the second round, the three bulbs are [on, off, on].
After the third round, the three bulbs are [on, off, off].
So you should return 1 because there is only one bulb is on.
Explanation: The two words can be "abcw", "xtfn".
Лампочка остается включенной, если она переключалась нечетное количество раз.
Лампочка будет переключаться на каждом делителе её номера.
Лампочка останется включенной только в том случае, если у нее нечетное количество делителей, что возможно только для квадратных чисел.
Количество лампочек, которые будут включены после n раундов.
import "math"
func bulbSwitch(n int) int {
return int(math.Sqrt(float64(n)))
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#easy
Задача: 543. Diameter of Binary Tree
Учитывая корень бинарного дерева, вернуть длину диаметра дерева.
Диаметр бинарного дерева — это длина самого длинного пути между любыми двумя узлами в дереве. Этот путь может проходить или не проходить через корень.
Длина пути между двумя узлами представлена числом ребер между ними.
Пример:
👨💻 Алгоритм:
1⃣ Инициализируйте целочисленную переменную diameter для отслеживания самого длинного пути, найденного с помощью DFS.
2⃣ Реализуйте рекурсивную функцию longestPath, которая принимает TreeNode в качестве входных данных и рекурсивно исследует дерево: Если узел равен None, вернуть 0. Рекурсивно исследовать левые и правые дочерние узлы, возвращая длины путей leftPath и rightPath. Если сумма leftPath и rightPath больше текущего diameter, обновить diameter. Вернуть большее из leftPath и rightPath плюс 1.
3⃣ Вызвать longestPath с root.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 543. Diameter of Binary Tree
Учитывая корень бинарного дерева, вернуть длину диаметра дерева.
Диаметр бинарного дерева — это длина самого длинного пути между любыми двумя узлами в дереве. Этот путь может проходить или не проходить через корень.
Длина пути между двумя узлами представлена числом ребер между ними.
Пример:
Input: root = [1,2]
Output: 1
package main
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
type Solution struct {
diameter int
}
func (s *Solution) diameterOfBinaryTree(root *TreeNode) int {
s.diameter = 0
s.longestPath(root)
return s.diameter
}
func (s *Solution) longestPath(node *TreeNode) int {
if node == nil {
return 0
}
leftPath := s.longestPath(node.Left)
rightPath := s.longestPath(node.Right)
s.diameter = max(s.diameter, leftPath + rightPath)
return max(leftPath, rightPath) + 1
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
#medium
Задача: 320. Generalized Abbreviation
Обобщенная аббревиатура слова может быть построена путем замены любых неперекрывающихся и несмежных подстрок на их соответствующие длины.
Например, "abcde" можно сократить следующим образом:
"a3e" ("bcd" заменено на "3")
"1bcd1" ("a" и "e" заменены на "1")
"5" ("abcde" заменено на "5")
"abcde" (без замены подстрок)
Однако следующие аббревиатуры недействительны:
"23" ("ab" заменено на "2" и "cde" заменено на "3") недействительно, так как выбранные подстроки смежные.
"22de" ("ab" заменено на "2" и "bc" заменено на "2") недействительно, так как выбранные подстроки перекрываются.
Дано слово word, верните список всех возможных обобщенных аббревиатур слова. Верните ответ в любом порядке.
Пример:
👨💻 Алгоритм:
1⃣ Создание битовых масок
Каждая аббревиатура имеет одно к одному соответствие с n-битным двоичным числом x, где n - длина слова. Используйте эти числа в качестве чертежей для построения соответствующих аббревиатур.
2⃣ Генерация аббревиатур
Для числа x просканируйте его бит за битом, чтобы определить, какие символы следует сохранить, а какие - сократить. Если бит равен 1, сохраните соответствующий символ, если 0 - замените его на счетчик.
3⃣ Перебор всех комбинаций
Для каждого числа от 0 до 2^n - 1 используйте его битовое представление для создания соответствующей аббревиатуры. Сканируйте число x побитово, извлекая его последний бит с помощью b = x & 1 и сдвигая x вправо на один бит x >>= 1.
😎 Решение:
Ставь 👍 и забирай 📚 Базу знаний
Задача: 320. Generalized Abbreviation
Обобщенная аббревиатура слова может быть построена путем замены любых неперекрывающихся и несмежных подстрок на их соответствующие длины.
Например, "abcde" можно сократить следующим образом:
"a3e" ("bcd" заменено на "3")
"1bcd1" ("a" и "e" заменены на "1")
"5" ("abcde" заменено на "5")
"abcde" (без замены подстрок)
Однако следующие аббревиатуры недействительны:
"23" ("ab" заменено на "2" и "cde" заменено на "3") недействительно, так как выбранные подстроки смежные.
"22de" ("ab" заменено на "2" и "bc" заменено на "2") недействительно, так как выбранные подстроки перекрываются.
Дано слово word, верните список всех возможных обобщенных аббревиатур слова. Верните ответ в любом порядке.
Пример:
Input: word = "a"
Output: ["1","a"]
Каждая аббревиатура имеет одно к одному соответствие с n-битным двоичным числом x, где n - длина слова. Используйте эти числа в качестве чертежей для построения соответствующих аббревиатур.
Для числа x просканируйте его бит за битом, чтобы определить, какие символы следует сохранить, а какие - сократить. Если бит равен 1, сохраните соответствующий символ, если 0 - замените его на счетчик.
Для каждого числа от 0 до 2^n - 1 используйте его битовое представление для создания соответствующей аббревиатуры. Сканируйте число x побитово, извлекая его последний бит с помощью b = x & 1 и сдвигая x вправо на один бит x >>= 1.
package main
import (
"fmt"
"strconv"
)
func generateAbbreviations(word string) []string {
n := len(word)
var result []string
for x := 0; x < (1 << n); x++ {
result = append(result, abbr(word, x))
}
return result
}
func abbr(word string, x int) string {
var builder []byte
k := 0
for i := 0; i < len(word); i, x = i+1, x>>1 {
if x&1 == 0 {
if k != 0 {
builder = append(builder, strconv.Itoa(k)...)
k = 0
}
builder = append(builder, word[i])
} else {
k++
}
}
if k != 0 {
builder = append(builder, strconv.Itoa(k)...)
}
return string(builder)
}
func main() {
word := "word"
fmt.Println(generateAbbreviations(word))
}
Ставь 👍 и забирай 📚 Базу знаний
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1