
{kind=link}
#easy
Задача: 110. Balanced Binary Tree
Дано бинарное дерево, определите, является ли оно
сбалансированным по высоте.
Пример:
👨💻 Алгоритм:
1️⃣ Сначала мы определяем функцию height, которая для любого узла p в дереве T возвращает:
-1, если p является пустым поддеревом, т.е. null;
1 + max(height(p.left), height(p.right)) в противном случае.
2️⃣ Теперь, когда у нас есть метод для определения высоты дерева, остается только сравнить высоты детей каждого узла. Дерево T с корнем r является сбалансированным тогда и только тогда, когда высоты его двух детей отличаются не более чем на 1 и поддеревья каждого ребенка также сбалансированы.
3️⃣ Следовательно, мы можем сравнить высоты двух дочерних поддеревьев, а затем рекурсивно проверить каждое из них:
Если root == NULL, возвращаем true.
Если abs(height(root.left) - height(root.right)) > 1, возвращаем false.
В противном случае возвращаем isBalanced(root.left) && isBalanced(root.right).
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 110. Balanced Binary Tree
Дано бинарное дерево, определите, является ли оно
сбалансированным по высоте.
Пример:
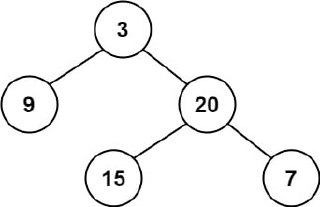
Input: root = [3,9,20,null,null,15,7]
Output: true
-1, если p является пустым поддеревом, т.е. null;
1 + max(height(p.left), height(p.right)) в противном случае.
Если root == NULL, возвращаем true.
Если abs(height(root.left) - height(root.right)) > 1, возвращаем false.
В противном случае возвращаем isBalanced(root.left) && isBalanced(root.right).
public class Solution {
private int Height(TreeNode root) {
if (root == null) {
return -1;
}
return 1 + Math.Max(Height(root.left), Height(root.right));
}
public bool IsBalanced(TreeNode root) {
if (root == null) {
return true;
}
return Math.Abs(Height(root.left) - Height(root.right)) < 2 &&
IsBalanced(root.left) && IsBalanced(root.right);
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#easy
Задача: 111. Minimum Depth of Binary Tree
Дано бинарное дерево, найдите его минимальную глубину.
Минимальная глубина - это количество узлов вдоль самого короткого пути от корневого узла до ближайшего листового узла.
Пример:
👨💻 Алгоритм:
1️⃣ Мы будем использовать метод обхода в глубину (dfs) с корнем в качестве аргумента.
Базовое условие рекурсии: это для узла NULL, в этом случае мы должны вернуть 0.
2️⃣ Если левый ребенок корня является NULL: тогда мы должны вернуть 1 + минимальную глубину для правого ребенка корневого узла, что равно 1 + dfs(root.right).
3️⃣ Если правый ребенок корня является NULL: тогда мы должны вернуть 1 + минимальную глубину для левого ребенка корневого узла, что равно 1 + dfs(root.left). Если оба ребенка не являются NULL, тогда вернуть 1 + min(dfs(root.left), dfs(root.right)).
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 111. Minimum Depth of Binary Tree
Дано бинарное дерево, найдите его минимальную глубину.
Минимальная глубина - это количество узлов вдоль самого короткого пути от корневого узла до ближайшего листового узла.
Пример:
Input: root = [3,9,20,null,null,15,7]
Output: 2
Базовое условие рекурсии: это для узла NULL, в этом случае мы должны вернуть 0.
public class Solution {
private int Dfs(TreeNode root) {
if (root == null) {
return 0;
}
if (root.left == null) {
return 1 + Dfs(root.right);
} else if (root.right == null) {
return 1 + Dfs(root.left);
}
return 1 + Math.Min(Dfs(root.left), Dfs(root.right));
}
public int MinDepth(TreeNode root) {
return Dfs(root);
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#easy
Задача: 112. Path Sum
Дан корень бинарного дерева и целое число targetSum. Верните true, если в дереве существует путь от корня до листа, такой, что сумма всех значений вдоль пути равна targetSum.
Лист — это узел без детей.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация стека: Начать с помещения в стек корневого узла и соответствующей оставшейся суммы, равной sum - root.val.
2️⃣ Обработка узлов: Извлечь текущий узел из стека и вернуть True, если оставшаяся сумма равна 0 и узел является листом.
3️⃣ Добавление дочерних узлов в стек: Если оставшаяся сумма не равна нулю или узел не является листом, добавить в стек дочерние узлы с соответствующими оставшимися суммами.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 112. Path Sum
Дан корень бинарного дерева и целое число targetSum. Верните true, если в дереве существует путь от корня до листа, такой, что сумма всех значений вдоль пути равна targetSum.
Лист — это узел без детей.
Пример:
Input: root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
Output: true
Explanation: The root-to-leaf path with the target sum is shown.
public class Solution {
public bool HasPathSum(TreeNode root, int sum) {
if (root == null)
return false;
Stack<TreeNode> nodeStack = new Stack<TreeNode>();
Stack<int> sumStack = new Stack<int>();
nodeStack.Push(root);
sumStack.Push(sum - root.val);
while (nodeStack.Count > 0) {
TreeNode node = nodeStack.Pop();
int currSum = sumStack.Pop();
if (node.left == null && node.right == null && currSum == 0)
return true;
if (node.left != null) {
nodeStack.Push(node.left);
sumStack.Push(currSum - node.left.val);
}
if (node.right != null) {
nodeStack.Push(node.right);
sumStack.Push(currSum - node.right.val);
}
}
return false;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#Medium
Задача: 113. Path Sum II
Дан корень бинарного дерева и целое число targetSum. Верните все пути от корня до листа, где сумма значений узлов в пути равна targetSum. Каждый путь должен быть возвращён как список значений узлов, а не ссылок на узлы.
Путь от корня до листа — это путь, начинающийся от корня и заканчивающийся на любом листовом узле. Лист — это узел без детей.
Пример:
👨💻 Алгоритм:
1️⃣ Определение функции recurseTree: Функция принимает текущий узел (node), оставшуюся сумму (remainingSum), которая необходима для продолжения поиска вниз по дереву, и список узлов (pathNodes), который содержит все узлы, встреченные до текущего момента на данной ветке.
2️⃣ Проверка условий: На каждом шаге проверяется, равна ли оставшаяся сумма значению текущего узла. Если это так и текущий узел является листом, текущий путь (pathNodes) добавляется в итоговый список путей, который должен быть возвращен.
3️⃣ Обработка всех ветвей: Учитывая, что значения узлов могут быть отрицательными, необходимо исследовать все ветви дерева до самых листьев, независимо от текущей суммы по пути.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 113. Path Sum II
Дан корень бинарного дерева и целое число targetSum. Верните все пути от корня до листа, где сумма значений узлов в пути равна targetSum. Каждый путь должен быть возвращён как список значений узлов, а не ссылок на узлы.
Путь от корня до листа — это путь, начинающийся от корня и заканчивающийся на любом листовом узле. Лист — это узел без детей.
Пример:
Input: root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
Output: [[5,4,11,2],[5,8,4,5]]
Explanation: There are two paths whose sum equals targetSum:
5 + 4 + 11 + 2 = 22
5 + 8 + 4 + 5 = 22
public class Solution {
private void RecurseTree(TreeNode node, int remainingSum,
List<int> pathNodes, IList<IList<int>> pathsList) {
if (node == null) {
return;
}
pathNodes.Add(node.val);
if (remainingSum == node.val && node.left == null && node.right == null) {
pathsList.Add(new List<int>(pathNodes));
} else {
this.RecurseTree(node.left, remainingSum - node.val, pathNodes, pathsList);
this.RecurseTree(node.right, remainingSum - node.val, pathNodes, pathsList);
}
pathNodes.RemoveAt(pathNodes.Count - 1);
}
public IList<IList<int>> PathSum(TreeNode root, int sum) {
List<IList<int>> pathsList = new List<IList<int>>();
List<int> pathNodes = new List<int>();
this.RecurseTree(root, sum, pathNodes, pathsList);
return pathsList;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#Medium
Задача: 114. Flatten Binary Tree to Linked List
"Связный список" должен использовать тот же класс TreeNode, где указатель на правого ребенка указывает на следующий узел в списке, а указатель на левого ребенка всегда равен null.
"Связный список" должен быть в том же порядке, что и обход бинарного дерева в прямом порядке.
Пример:
👨💻 Алгоритм:
1️⃣ Плоское преобразование дерева: Рекурсивно преобразуем левое и правое поддеревья заданного узла, сохраняя соответствующие конечные узлы в leftTail и rightTail.
2️⃣ Установка соединений: Если у текущего узла есть левый ребенок, выполняем следующие соединения:
leftTail.right = node.right
node.right = node.left
node.left = None
3️⃣ Возврат конечного узла: Возвращаем rightTail, если у узла есть правый ребенок, иначе возвращаем leftTail.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 114. Flatten Binary Tree to Linked List
"Связный список" должен использовать тот же класс TreeNode, где указатель на правого ребенка указывает на следующий узел в списке, а указатель на левого ребенка всегда равен null.
"Связный список" должен быть в том же порядке, что и обход бинарного дерева в прямом порядке.
Пример:
Input: root = [1,2,5,3,4,null,6]
Output: [1,null,2,null,3,null,4,null,5,null,6]
leftTail.right = node.right
node.right = node.left
node.left = None
public class Solution {
private TreeNode FlattenTree(TreeNode node) {
if (node == null) {
return null;
}
if (node.left == null && node.right == null) {
return node;
}
TreeNode leftTail = FlattenTree(node.left);
TreeNode rightTail = FlattenTree(node.right);
if (leftTail != null) {
leftTail.right = node.right;
node.right = node.left;
node.left = null;
}
return rightTail == null ? leftTail : rightTail;
}
public void Flatten(TreeNode root) {
FlattenTree(root);
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#hard
Задача: 115. Distinct Subsequences
"Даны две строки s и t. Верните количество различных подпоследовательностей строки s, которые равны строке t.
Тестовые примеры сгенерированы таким образом, что ответ укладывается в 32-битное целое число со знаком."
Пример:
👨💻 Алгоритм:
1️⃣ Определите функцию с названием recurse, которая принимает два целочисленных значения i и j. Первое значение представляет текущий обрабатываемый символ в строке S, а второе - текущий символ в строке T. Инициализируйте словарь под названием memo, который будет кэшировать результаты различных вызовов рекурсии.**
2️⃣ Проверьте базовый случай. Если одна из строк закончилась, возвращается 0 или 1 в зависимости от того, удалось ли обработать всю строку T или нет. Есть ещё один базовый случай, который следует рассмотреть. Если оставшаяся длина строки S меньше, чем у строки T, то совпадение невозможно. Если это обнаруживается, то рекурсия также обрезается и возвращается 0.**
3️⃣ Затем проверяем, существует ли текущая пара индексов в нашем словаре. Если да, то просто возвращаем сохранённое/кэшированное значение. Если нет, то продолжаем обычную обработку. Сравниваем символы s[i] и t[j]. Сохраняем результат вызова recurse(i + 1, j) в переменную. Как упоминалось ранее, результат этой рекурсии необходим, независимо от совпадения символов. Если символы совпадают, добавляем к переменной результат вызова recurse(i + 1, j + 1). Наконец, сохраняем значение этой переменной в словаре с ключом (i, j) и возвращаем это значение в качестве ответа.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 115. Distinct Subsequences
"Даны две строки s и t. Верните количество различных подпоследовательностей строки s, которые равны строке t.
Тестовые примеры сгенерированы таким образом, что ответ укладывается в 32-битное целое число со знаком."
Пример:
Input: s = "rabbbit", t = "rabbit"
Output: 3
Explanation:
As shown below, there are 3 ways you can generate "rabbit" from s.
rabbbit
rabbbit
rabbbit
public class Solution {
private Dictionary<string, int> memo;
public int NumDistinct(string s, string t) {
if (s.Length < t.Length)
return 0;
if (s == t || t == "")
return 1;
memo = new Dictionary<string, int>();
return DistinctHelper(s.Substring(0, s.Length - 1), t) +
((s[s.Length - 1] == t[t.Length - 1])
? DistinctHelper(s.Substring(0, s.Length - 1),
t.Substring(0, t.Length - 1))
: 0);
}
private int DistinctHelper(string s, string t) {
if (memo.ContainsKey(s + "," + t))
return memo[s + "," + t];
if (s.Length < t.Length)
return 0;
if (s == t || t == "")
return 1;
memo[s + "," + t] = DistinctHelper(s.Substring(0, s.Length - 1), t) +
((s[s.Length - 1] == t[t.Length - 1])
? DistinctHelper(s.Substring(0, s.Length - 1),
t.Substring(0, t.Length - 1))
: 0);
return memo[s + "," + t];
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#medium
Задача: 116. Populating Next Right Pointers in Each Node
Вам дано идеальное бинарное дерево, где все листья находятся на одном уровне, и у каждого родителя есть два детей. Бинарное дерево имеет следующее определение:
Заполните каждый указатель
Изначально все указатели
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте очередь Q, которую мы будем использовать во время обхода. Существует несколько способов реализации обхода в ширину, особенно когда речь идет о определении уровня конкретного узла. Можно добавлять в очередь пару (узел, уровень), и каждый раз, когда добавляются дети узла, мы добавляем (node.left, parent_level + 1) и (node.right, parent_level + 1). Этот подход не будет очень эффективен для нашего алгоритма, так как нам нужны все узлы на одном уровне, и для этого потребуется еще одна структура данных.
2️⃣ Более эффективный с точки зрения памяти способ разделения узлов одного уровня заключается в использовании некоторой разграничительной метки между уровнями. Обычно мы вставляем в очередь элемент NULL, который отмечает конец предыдущего уровня и начало следующего. Это отличный подход, но он все равно потребует некоторого количества памяти, пропорционально количеству уровней в дереве.
3️⃣ Подход, который мы будем использовать здесь, будет иметь структуру вложенных циклов, чтобы обойти необходимость указателя NULL. По сути, на каждом шаге мы записываем размер очереди, который всегда соответствует всем узлам на определенном уровне. Как только мы узнаем этот размер, мы обрабатываем только это количество элементов и не более. К моменту, когда мы закончим обработку заданного количества элементов, в очереди будут все узлы следующего уровня. Вот псевдокод для этого:
Мы начинаем с добавления корня дерева в очередь. Поскольку на уровне 0 есть только один узел, нам не нужно устанавливать какие-либо соединения, и мы можем перейти к циклу while.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 116. Populating Next Right Pointers in Each Node
Вам дано идеальное бинарное дерево, где все листья находятся на одном уровне, и у каждого родителя есть два детей. Бинарное дерево имеет следующее определение:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}Заполните каждый указатель
next так, чтобы он указывал на следующий правый узел. Если следующего правого узла нет, указатель next должен быть установлен в NULL.Изначально все указатели
next установлены в NULL.Пример:
Input: root = [1,2,3,4,5,6,7]
Output: [1,#,2,3,#,4,5,6,7,#]
Explanation: Given the above perfect binary tree (Figure A), your function should populate each next pointer to point to its next right node, just like in Figure B. The serialized output is in level order as connected by the next pointers, with '#' signifying the end of each level.
while (!Q.empty())
{
size = Q.size()
for i in range 0..size
{
node = Q.pop()
Q.push(node.left)
Q.push(node.right)
}
}
Мы начинаем с добавления корня дерева в очередь. Поскольку на уровне 0 есть только один узел, нам не нужно устанавливать какие-либо соединения, и мы можем перейти к циклу while.
public class Solution {
public Node Connect(Node root) {
if (root == null) {
return root;
}
Queue<Node> Q = new Queue<Node>();
Q.Enqueue(root);
while (Q.Count > 0) {
int size = Q.Count;
for (int i = 0; i < size; i++) {
Node node = Q.Dequeue();
if (i < size - 1) {
node.next = Q.Peek();
}
if (node.left != null) {
Q.Enqueue(node.left);
}
if (node.right != null) {
Q.Enqueue(node.right);
}
}
}
return root;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#medium
Задача: 117. Populating Next Right Pointers in Each Node II
Вам дано бинарное дерево:
Заполните каждый указатель
Изначально все указатели
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте очередь Q, которая будет использоваться во время обхода. Существует несколько способов реализации обхода в ширину, особенно когда дело доходит до определения уровня конкретного узла. Можно добавить в очередь пару (узел, уровень), и каждый раз, когда мы добавляем детей узла, мы добавляем (node.left, parent_level+1) и (node.right, parent_level+1). Этот подход может оказаться неэффективным для нашего алгоритма, так как нам нужны все узлы на одном уровне, и потребуется дополнительная структура данных.
2️⃣ Более эффективный с точки зрения памяти способ разделения узлов одного уровня - использовать разграничение между уровнями. Обычно мы вставляем в очередь элемент NULL, который обозначает конец предыдущего уровня и начало следующего. Это отличный подход, но он все равно потребует некоторого объема памяти, пропорционального количеству уровней в дереве.
3️⃣ Подход, который мы будем использовать, предполагает структуру вложенных циклов, чтобы обойти необходимость NULL указателя. По сути, на каждом шаге мы фиксируем размер очереди, который всегда соответствует всем узлам на определенном уровне. Как только мы узнаем этот размер, мы обрабатываем только это количество элементов и больше ничего. К тому времени, как мы закончим обработку заданного количества элементов, в очереди окажутся все узлы следующего уровня. Вот псевдокод для этого:
Мы начинаем с добавления корня дерева в очередь. Так как на уровне 0 есть только один узел, нам не нужно устанавливать какие-либо соединения, и мы можем перейти к циклу while.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 117. Populating Next Right Pointers in Each Node II
Вам дано бинарное дерево:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}Заполните каждый указатель
next, чтобы он указывал на следующий правый узел. Если следующего правого узла нет, указатель next должен быть установлен в NULL.Изначально все указатели
next установлены в NULL.Пример:
Input: root = [1,2,3,4,5,null,7]
Output: [1,#,2,3,#,4,5,7,#]
Explanation: Given the above binary tree (Figure A), your function should populate each next pointer to point to its next right node, just like in Figure B. The serialized output is in level order as connected by the next pointers, with '#' signifying the end of each level.
while (!Q.empty())
{
size = Q.size()
for i in range 0..size
{
node = Q.pop()
Q.push(node.left)
Q.push(node.right)
}
}
Мы начинаем с добавления корня дерева в очередь. Так как на уровне 0 есть только один узел, нам не нужно устанавливать какие-либо соединения, и мы можем перейти к циклу while.
public class Solution {
public Node Connect(Node root) {
if (root == null) {
return root;
}
Queue<Node> Q = new Queue<Node>();
Q.Enqueue(root);
while (Q.Count > 0) {
int size = Q.Count;
for (int i = 0; i < size; i++) {
Node node = Q.Dequeue();
if (i < size - 1) {
node.next = Q.Peek();
}
if (node.left != null) {
Q.Enqueue(node.left);
}
if (node.right != null) {
Q.Enqueue(node.right);
}
}
}
return root;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#hard
Задача: 124. Binary Tree Maximum Path Sum
Вам дан массив цен, где prices[i] — это цена данной акции в i-й день.
Найдите максимальную прибыль, которую вы можете получить. Вы можете совершить не более двух транзакций.
Обратите внимание: вы не можете участвовать в нескольких транзакциях одновременно (то есть, вы должны продать акцию, прежде чем снова её купить).
Пример:
👨💻 Алгоритм:
1️⃣ Наивная реализация этой идеи заключалась бы в разделении последовательностей на две части и последующем перечислении каждой из подпоследовательностей, хотя это определенно не самое оптимизированное решение.
Для последовательности длиной N у нас было бы N возможных разделений (включая отсутствие разделения), каждый элемент был бы посещен один раз в каждом разделении. В результате общая временная сложность этой наивной реализации составила бы O(N²).
2️⃣ Мы могли бы сделать лучше, чем наивная реализация O(N²). Что касается алгоритмов разделяй и властвуй,
одна из общих техник, которую мы можем применить для оптимизации временной сложности, называется динамическим программированием (DP), где мы меняем менее повторяющиеся вычисления на некоторое дополнительное пространство.
В алгоритмах динамического программирования обычно мы создаем массив одного или двух измерений для сохранения промежуточных оптимальных результатов. В данной задаче мы бы использовали два массива, один массив сохранял бы результаты последовательности слева направо, а другой массив сохранял бы результаты последовательности справа налево. Для удобства мы могли бы назвать это двунаправленным динамическим программированием.
3️⃣ Сначала мы обозначаем последовательность цен как Prices[i], с индексом начиная от 0 до N-1. Затем мы определяем два массива, а именно left_profits[i] и right_profits[i].
Как следует из названия, каждый элемент в массиве left_profits[i] будет содержать максимальную прибыль, которую можно получить от выполнения одной транзакции в левой подпоследовательности цен от индекса ноль до i, (т.е. Prices[0], Prices[1], ... Prices[i]).
Например, для подпоследовательности [7, 1, 5] соответствующий left_profits[2] будет равен 4, что означает покупку по цене 1 и продажу по цене 5.
И каждый элемент в массиве right_profits[i] будет содержать максимальную прибыль, которую можно получить от выполнения одной транзакции в правой подпоследовательности цен от индекса i до N-1, (т.е. Prices[i], Prices[i+1], ... Prices[N-1]).
Например, для правой подпоследовательности [3, 6, 4] соответствующий right_profits[3] будет равен 3, что означает покупку по цене 3 и продажу по цене 6.
Теперь, если мы разделим последовательность цен вокруг элемента с индексом i на две подпоследовательности, с левыми подпоследовательностями как Prices[0], Prices[1], ... Prices[i] и правой подпоследовательностью как Prices[i+1], ... Prices[N-1],
то общая максимальная прибыль, которую мы получим от этого разделения (обозначенная как max_profits[i]), может быть выражена следующим образом:
max_profits[i] = left_profits[i] + right_profits[i+1]
Задача: 124. Binary Tree Maximum Path Sum
Вам дан массив цен, где prices[i] — это цена данной акции в i-й день.
Найдите максимальную прибыль, которую вы можете получить. Вы можете совершить не более двух транзакций.
Обратите внимание: вы не можете участвовать в нескольких транзакциях одновременно (то есть, вы должны продать акцию, прежде чем снова её купить).
Пример:
Input: prices = [3,3,5,0,0,3,1,4]
Output: 6
Explanation: Buy on day 4 (price = 0) and sell on day 6 (price = 3), profit = 3-0 = 3.
Then buy on day 7 (price = 1) and sell on day 8 (price = 4), profit = 4-1
Для последовательности длиной N у нас было бы N возможных разделений (включая отсутствие разделения), каждый элемент был бы посещен один раз в каждом разделении. В результате общая временная сложность этой наивной реализации составила бы O(N²).
одна из общих техник, которую мы можем применить для оптимизации временной сложности, называется динамическим программированием (DP), где мы меняем менее повторяющиеся вычисления на некоторое дополнительное пространство.
В алгоритмах динамического программирования обычно мы создаем массив одного или двух измерений для сохранения промежуточных оптимальных результатов. В данной задаче мы бы использовали два массива, один массив сохранял бы результаты последовательности слева направо, а другой массив сохранял бы результаты последовательности справа налево. Для удобства мы могли бы назвать это двунаправленным динамическим программированием.
Как следует из названия, каждый элемент в массиве left_profits[i] будет содержать максимальную прибыль, которую можно получить от выполнения одной транзакции в левой подпоследовательности цен от индекса ноль до i, (т.е. Prices[0], Prices[1], ... Prices[i]).
Например, для подпоследовательности [7, 1, 5] соответствующий left_profits[2] будет равен 4, что означает покупку по цене 1 и продажу по цене 5.
И каждый элемент в массиве right_profits[i] будет содержать максимальную прибыль, которую можно получить от выполнения одной транзакции в правой подпоследовательности цен от индекса i до N-1, (т.е. Prices[i], Prices[i+1], ... Prices[N-1]).
Например, для правой подпоследовательности [3, 6, 4] соответствующий right_profits[3] будет равен 3, что означает покупку по цене 3 и продажу по цене 6.
Теперь, если мы разделим последовательность цен вокруг элемента с индексом i на две подпоследовательности, с левыми подпоследовательностями как Prices[0], Prices[1], ... Prices[i] и правой подпоследовательностью как Prices[i+1], ... Prices[N-1],
то общая максимальная прибыль, которую мы получим от этого разделения (обозначенная как max_profits[i]), может быть выражена следующим образом:
max_profits[i] = left_profits[i] + right_profits[i+1]
Please open Telegram to view this post
VIEW IN TELEGRAM
public class Solution {
public int MaxProfit(int[] prices) {
int length = prices.Length;
if (length <= 1)
return 0;
int leftMin = prices[0];
int rightMax = prices[length - 1];
int[] leftProfits = new int[length];
int[] rightProfits = new int[length + 1];
for (var l = 1; l < length; ++l) {
leftProfits[l] = Math.Max(leftProfits[l - 1], prices[l] - leftMin);
leftMin = Math.Min(leftMin, prices[l]);
int r = length - 1 - l;
rightProfits[r] =
Math.Max(rightProfits[r + 1], rightMax - prices[r]);
rightMax = Math.Max(rightMax, prices[r]);
}
var maxProfit = 0;
for (var i = 0; i < length; ++i)
maxProfit =
Math.Max(maxProfit, leftProfits[i] + rightProfits[i + 1]);
return maxProfit;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
#easy
Задача: 125. Valid Palindrome
Фраза является палиндромом, если после преобразования всех заглавных букв в строчные и удаления всех неалфавитно-цифровых символов она читается одинаково как слева направо, так и справа налево. Алфавитно-цифровые символы включают в себя буквы и цифры.
Для данной строки s верните true, если она является палиндромом, и false в противном случае.
Пример:
👨💻 Алгоритм:
1️⃣ Поскольку входная строка содержит символы, которые нам нужно игнорировать при проверке на палиндром, становится трудно определить реальную середину нашего палиндромического ввода.
2️⃣ Вместо того, чтобы двигаться от середины наружу, мы можем двигаться внутрь к середине! Если начать перемещаться внутрь, с обоих концов входной строки, мы можем ожидать увидеть те же символы в том же порядке.
3️⃣ Результирующий алгоритм прост:
1. Установите два указателя, один на каждом конце входной строки.
2. Если ввод является палиндромом, оба указателя должны указывать на эквивалентные символы в любой момент времени.
3. Если это условие не выполняется в какой-либо момент времени, мы прерываемся и возвращаемся раньше.
4. Мы можем просто игнорировать неалфавитно-цифровые символы, продолжая двигаться дальше.
5. Продолжайте перемещение внутрь, пока указатели не встретятся в середине.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 125. Valid Palindrome
Фраза является палиндромом, если после преобразования всех заглавных букв в строчные и удаления всех неалфавитно-цифровых символов она читается одинаково как слева направо, так и справа налево. Алфавитно-цифровые символы включают в себя буквы и цифры.
Для данной строки s верните true, если она является палиндромом, и false в противном случае.
Пример:
Input: s = "A man, a plan, a canal: Panama"
Output: true
Explanation: "amanaplanacanalpanama" is a palindrome.
1. Установите два указателя, один на каждом конце входной строки.
2. Если ввод является палиндромом, оба указателя должны указывать на эквивалентные символы в любой момент времени.
3. Если это условие не выполняется в какой-либо момент времени, мы прерываемся и возвращаемся раньше.
4. Мы можем просто игнорировать неалфавитно-цифровые символы, продолжая двигаться дальше.
5. Продолжайте перемещение внутрь, пока указатели не встретятся в середине.
public class Solution {
public bool IsPalindrome(string s) {
int i = 0;
int j = s.Length - 1;
while (i < j) {
while (i < j && !Char.IsLetterOrDigit(s[i])) {
i++;
}
while (i < j && !Char.IsLetterOrDigit(s[j])) {
j--;
}
if (char.ToLower(s[i]) != char.ToLower(s[j]))
return false;
i++;
j--;
}
return true;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
❤1
#Hard
Задача: 126.Word Ladder II
Последовательность преобразований от слова beginWord до слова endWord с использованием словаря wordList — это последовательность слов beginWord -> s1 -> s2 -> ... -> sk, для которой выполняются следующие условия:
Каждая пара соседних слов отличается ровно одной буквой.
Каждое si для 1 <= i <= k находится в wordList. Отметим, что beginWord не обязательно должно быть в wordList.
sk == endWord.
Для двух слов, beginWord и endWord, и словаря wordList, вернуть все самые короткие последовательности преобразований от beginWord до endWord или пустой список, если такая последовательность не существует. Каждая последовательность должна возвращаться в виде списка слов [beginWord, s1, s2, ..., sk].
Пример:
👨💻 Алгоритм:
1️⃣ Сохранение слов из списка слов (wordList) в хэш-таблицу (unordered set) для эффективного удаления слов в процессе поиска в ширину (BFS).
2️⃣ Выполнение BFS, добавление связей в список смежности (adjList). После завершения уровня удалять посещенные слова из wordList.
3️⃣ Начать с beginWord и отслеживать текущий путь как currPath, просматривать все возможные пути, и когда путь ведет к endWord, сохранять путь в shortestPaths.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 126.Word Ladder II
Последовательность преобразований от слова beginWord до слова endWord с использованием словаря wordList — это последовательность слов beginWord -> s1 -> s2 -> ... -> sk, для которой выполняются следующие условия:
Каждая пара соседних слов отличается ровно одной буквой.
Каждое si для 1 <= i <= k находится в wordList. Отметим, что beginWord не обязательно должно быть в wordList.
sk == endWord.
Для двух слов, beginWord и endWord, и словаря wordList, вернуть все самые короткие последовательности преобразований от beginWord до endWord или пустой список, если такая последовательность не существует. Каждая последовательность должна возвращаться в виде списка слов [beginWord, s1, s2, ..., sk].
Пример:
Input: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
Output: [["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]]
Explanation: There are 2 shortest transformation sequences:
"hit" -> "hot" -> "dot" -> "dog" -> "cog"
"hit" -> "hot" -> "lot" -> "log" -> "cog"
public class Solution {
Dictionary<string, List<string>> adjList = new Dictionary<string, List<string>>();
List<string> currPath = new List<string>();
List<IList<string>> shortestPaths = new List<IList<string>>();
private List<string> FindNeighbors(string word, HashSet<string> wordList) {
List<string> neighbors = new List<string>();
char[] charList = word.ToCharArray();
for (int i = 0; i < word.Length; i++) {
char oldChar = charList[i];
for (char c = 'a'; c <= 'z'; c++) {
if (c != oldChar) {
charList[i] = c;
string newWord = new string(charList);
if (wordList.Contains(newWord)) neighbors.Add(newWord);
}
}
charList[i] = oldChar;
}
return neighbors;
}
private void Backtrack(string source, string destination) {
if (source == destination) {
var tempPath = new List<string>(currPath);
tempPath.Reverse();
shortestPaths.Add(tempPath);
return;
}
if (adjList.ContainsKey(source)) {
foreach (var neighbor in adjList[source]) {
currPath.Add(neighbor);
Backtrack(neighbor, destination);
currPath.RemoveAt(currPath.Count - 1);
}
}
}
private void Bfs(string beginWord, HashSet<string> wordList) {
Queue<string> q = new Queue<string>(new[] { beginWord });
wordList.Remove(beginWord);
while (q.Count > 0) {
for (int i = q.Count; i > 0; i--) {
var currWord = q.Dequeue();
foreach (var neighbor in FindNeighbors(currWord, wordList)) {
if (!adjList.TryGetValue(neighbor, out var list)) {
list = adjList[neighbor] = new List<string>();
q.Enqueue(neighbor);
}
list.Add(currWord);
}
}
}
}
public IList<IList<string>> FindLadders(string beginWord, string endWord, IList<string> wordList) {
Bfs(beginWord, new HashSet<string>(wordList));
currPath.Add(endWord);
Backtrack(endWord, beginWord);
return shortestPaths;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
#Hard
Задача: 127. Word Ladder
Секвенция трансформации от слова beginWord к слову endWord с использованием словаря wordList представляет собой последовательность слов beginWord -> s1 -> s2 -> ... -> sk, при которой:
Каждая пара соседних слов отличается ровно одной буквой.
Каждый элемент si для 1 <= i <= k присутствует в wordList. Отметим, что beginWord не обязан быть в wordList.
sk равно endWord.
Для двух слов, beginWord и endWord, и словаря wordList, верните количество слов в кратчайшей секвенции трансформации от beginWord к endWord, или 0, если такая секвенция не существует.
Пример:
👨💻 Алгоритм:
1️⃣ Препроцессинг списка слов: Осуществите препроцессинг заданного списка слов (wordList), чтобы найти все возможные промежуточные состояния слов. Сохраните эти состояния в словаре, где ключом будет промежуточное слово, а значением — список слов, имеющих то же промежуточное состояние.
2️⃣ Использование очереди для обхода: Поместите в очередь кортеж, содержащий
3️⃣ Поиск кратчайшего пути через BFS (обход в ширину): Пока в очереди есть элементы, получите первый элемент очереди. Для каждого слова определите все промежуточные преобразования и проверьте, не являются ли эти преобразования также преобразованиями других слов из списка. Для каждого найденного слова, которое имеет общее промежуточное состояние с текущим словом, добавьте в очередь пару (слово, уровень + 1), где уровень — это уровень текущего слова. Если вы достигли искомого слова, его уровень покажет длину кратчайшей последовательности преобразования.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 127. Word Ladder
Секвенция трансформации от слова beginWord к слову endWord с использованием словаря wordList представляет собой последовательность слов beginWord -> s1 -> s2 -> ... -> sk, при которой:
Каждая пара соседних слов отличается ровно одной буквой.
Каждый элемент si для 1 <= i <= k присутствует в wordList. Отметим, что beginWord не обязан быть в wordList.
sk равно endWord.
Для двух слов, beginWord и endWord, и словаря wordList, верните количество слов в кратчайшей секвенции трансформации от beginWord к endWord, или 0, если такая секвенция не существует.
Пример:
Input: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
Output: 5
Explanation: One shortest transformation sequence is "hit" -> "hot" -> "dot" -> "dog" -> cog", which is 5 words long.
beginWord и число 1, где 1 обозначает уровень узла. Вам нужно вернуть уровень узла endWord, так как он будет представлять длину кратчайшей последовательности преобразования. Используйте словарь посещений, чтобы избежать циклов.using System;
using System.Collections.Generic;
using System.Linq;
public class Solution {
public int LadderLength(string beginWord, string endWord, IList<string> wordList) {
int L = beginWord.Length;
Dictionary<string, List<string>> allComboDict = new Dictionary<string, List<string>>();
foreach (string word in wordList) {
for (int i = 0; i < L; i++) {
string newWord = word.Substring(0, i) + '*' + word.Substring(i + 1, L - i - 1);
if (!allComboDict.ContainsKey(newWord))
allComboDict[newWord] = new List<string>();
allComboDict[newWord].Add(word);
}
}
Queue<Tuple<string, int>> Q = new Queue<Tuple<string, int>>();
Q.Enqueue(new Tuple<string, int>(beginWord, 1));
Dictionary<string, bool> visited = new Dictionary<string, bool>();
visited[beginWord] = true;
while (Q.Any()) {
var node = Q.Dequeue();
string word = node.Item1;
int level = node.Item2;
for (int i = 0; i < L; i++) {
string newWord = word.Substring(0, i) + '*' + word.Substring(i + 1, L - i - 1);
foreach (string adjacentWord in allComboDict.GetValueOrDefault(newWord, new List<string>())) {
if (adjacentWord.Equals(endWord))
return level + 1;
if (!visited.ContainsKey(adjacentWord)) {
visited[adjacentWord] = true;
Q.Enqueue(new Tuple<string, int>(adjacentWord, level + 1));
}
}
}
}
return 0;
}
}
Please open Telegram to view this post
VIEW IN TELEGRAM
#Medium
Задача: 128. Longest Consecutive Sequence
Дан несортированный массив целых чисел nums. Верните длину самой длинной последовательности последовательных элементов.
Необходимо написать алгоритм, который работает за время O(n).
Пример:
👨💻 Алгоритм:
1️⃣ Проверка базового случая:
Перед началом работы проверяем базовый случай с пустым массивом.
Самая длинная последовательность в пустом массиве, очевидно, равна 0, поэтому мы можем просто вернуть это значение.
2️⃣ Обработка чисел в массиве:
Для всех других случаев мы сортируем массив nums и рассматриваем каждое число, начиная со второго (поскольку нам нужно сравнивать каждое число с предыдущим).
Если текущее число и предыдущее равны, то текущая последовательность не удлиняется и не прерывается, поэтому мы просто переходим к следующему числу.
Если числа не равны, то нужно проверить, удлиняет ли текущее число последовательность (т.е. nums[i] == nums[i-1] + 1). Если удлиняет, то мы увеличиваем наш текущий счёт и продолжаем.
3️⃣ Завершение обработки и возврат результата:
В противном случае последовательность прерывается, и мы записываем нашу текущую последовательность и сбрасываем её до 1 (чтобы включить число, которое прервало последовательность).
Возможно, что последний элемент массива nums является частью самой длинной последовательности, поэтому мы возвращаем максимум из текущей последовательности и самой длинной.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 128. Longest Consecutive Sequence
Дан несортированный массив целых чисел nums. Верните длину самой длинной последовательности последовательных элементов.
Необходимо написать алгоритм, который работает за время O(n).
Пример:
Input: nums = [100,4,200,1,3,2]
Output: 4
Explanation: The longest consecutive elements sequence is [1, 2, 3, 4]. Therefore its length is 4.
Перед началом работы проверяем базовый случай с пустым массивом.
Самая длинная последовательность в пустом массиве, очевидно, равна 0, поэтому мы можем просто вернуть это значение.
Для всех других случаев мы сортируем массив nums и рассматриваем каждое число, начиная со второго (поскольку нам нужно сравнивать каждое число с предыдущим).
Если текущее число и предыдущее равны, то текущая последовательность не удлиняется и не прерывается, поэтому мы просто переходим к следующему числу.
Если числа не равны, то нужно проверить, удлиняет ли текущее число последовательность (т.е. nums[i] == nums[i-1] + 1). Если удлиняет, то мы увеличиваем наш текущий счёт и продолжаем.
В противном случае последовательность прерывается, и мы записываем нашу текущую последовательность и сбрасываем её до 1 (чтобы включить число, которое прервало последовательность).
Возможно, что последний элемент массива nums является частью самой длинной последовательности, поэтому мы возвращаем максимум из текущей последовательности и самой длинной.
public class Solution {
private bool ArrayContains(int[] arr, int num) {
for (int i = 0; i < arr.Length; i++) {
if (arr[i] == num) {
return true;
}
}
return false;
}
public int LongestConsecutive(int[] nums) {
int longestStreak = 0;
for (int i = 0; i < nums.Length; i++) {
int currentNum = nums[i];
int currentStreak = 1;
while (ArrayContains(nums, currentNum + 1)) {
currentNum += 1;
currentStreak += 1;
}
longestStreak = Math.Max(longestStreak, currentStreak);
}
return longestStreak;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#Medium
Задача: 129. Sum Root to Leaf Numbers
Вам дан корень бинарного дерева, содержащего только цифры от 0 до 9.
Каждый путь от корня до листа в дереве представляет собой число.
Например, путь от корня до листа 1 -> 2 -> 3 представляет число 123.
Верните общую сумму всех чисел от корня до листа. Тестовые случаи созданы таким образом, что ответ поместится в 32-битное целое число.
Листовой узел — это узел без детей.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация:
Создайте переменные для хранения суммы чисел (rootToLeaf) и текущего числа (currNumber), а также стек для обхода дерева, начиная с корневого узла.
2️⃣ Обход дерева:
Используйте стек для глубинного обхода дерева (DFS), обновляя currNumber путём умножения на 10 и добавления значения узла. Для каждого листа добавляйте currNumber к rootToLeaf.
3️⃣ Возвращение результата:
По завершении обхода всех узлов возвращайте rootToLeaf, содержащую сумму всех чисел от корня до листьев дерева.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 129. Sum Root to Leaf Numbers
Вам дан корень бинарного дерева, содержащего только цифры от 0 до 9.
Каждый путь от корня до листа в дереве представляет собой число.
Например, путь от корня до листа 1 -> 2 -> 3 представляет число 123.
Верните общую сумму всех чисел от корня до листа. Тестовые случаи созданы таким образом, что ответ поместится в 32-битное целое число.
Листовой узел — это узел без детей.
Пример:
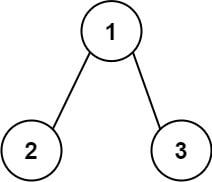
Input: root = [1,2,3]
Output: 25
Explanation:
The root-to-leaf path 1->2 represents the number 12.
The root-to-leaf path 1->3 represents the number 13.
Therefore, sum = 12 + 13 = 25.
Создайте переменные для хранения суммы чисел (rootToLeaf) и текущего числа (currNumber), а также стек для обхода дерева, начиная с корневого узла.
Используйте стек для глубинного обхода дерева (DFS), обновляя currNumber путём умножения на 10 и добавления значения узла. Для каждого листа добавляйте currNumber к rootToLeaf.
По завершении обхода всех узлов возвращайте rootToLeaf, содержащую сумму всех чисел от корня до листьев дерева.
public class Solution {
public int SumNumbers(TreeNode root) {
int rootToLeaf = 0, currNumber = 0;
int steps;
TreeNode predecessor;
while (root != null) {
if (root.left != null) {
predecessor = root.left;
steps = 1;
while (predecessor.right != null && predecessor.right != root) {
predecessor = predecessor.right;
++steps;
}
if (predecessor.right == null) {
currNumber = currNumber * 10 + root.val;
predecessor.right = root;
root = root.left;
} else {
if (predecessor.left == null) {
rootToLeaf += currNumber;
}
for (int i = 0; i < steps; ++i) {
currNumber /= 10;
}
predecessor.right = null;
root = root.right;
}
} else {
currNumber = currNumber * 10 + root.val;
if (root.right == null) {
rootToLeaf += currNumber;
}
root = root.right;
}
}
return rootToLeaf;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
#Medium
Задача: 130. Surrounded Regions
Вам дана матрица размером m на n, которая содержит буквы 'X' и 'O'. Захватите регионы, которые окружены:
Соединение: Ячейка соединена с соседними ячейками по горизонтали или вертикали.
Регион: Для формирования региона соедините каждую ячейку 'O'.
Окружение: Регион окружён ячейками 'X', если можно соединить регион с ячейками 'X', и ни одна из ячеек региона не находится на краю доски.
Окруженный регион захватывается путём замены всех 'O' на 'X' в исходной матрице.
Пример:
👨💻 Алгоритм:
1️⃣ Выбор начальных ячеек и инициация DFS:
Начинаем с выбора всех ячеек, расположенных на границах доски.
Затем, начиная с каждой выбранной ячейки на границе, выполняем обход в глубину (DFS).
2️⃣ Логика и выполнение DFS:
Если ячейка на границе оказывается 'O', это означает, что эта ячейка "жива", вместе с другими ячейками 'O', соединёнными с этой граничной ячейкой. Две ячейки считаются соединёнными, если между ними существует путь, состоящий только из букв 'O'.
Цель нашего обхода DFS будет заключаться в том, чтобы отметить все такие связанные ячейки 'O', которые исходят из границы, каким-либо отличительным символом, например, 'E'.
3️⃣ Классификация и финальная обработка ячеек:
После обхода всех граничных ячеек мы получаем три типа ячеек:
Ячейки с буквой 'X': эти ячейки можно считать стеной.
Ячейки с буквой 'O': эти ячейки не затрагиваются в нашем обходе DFS, то есть они не имеют соединения с границей, следовательно, они захвачены. Эти ячейки следует заменить на букву 'X'.
Ячейки с буквой 'E': это ячейки, отмеченные в ходе нашего обхода DFS, то есть ячейки, имеющие хотя бы одно соединение с границами, следовательно, они не захвачены. В результате мы должны вернуть этим ячейкам их исходную букву 'O'.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 130. Surrounded Regions
Вам дана матрица размером m на n, которая содержит буквы 'X' и 'O'. Захватите регионы, которые окружены:
Соединение: Ячейка соединена с соседними ячейками по горизонтали или вертикали.
Регион: Для формирования региона соедините каждую ячейку 'O'.
Окружение: Регион окружён ячейками 'X', если можно соединить регион с ячейками 'X', и ни одна из ячеек региона не находится на краю доски.
Окруженный регион захватывается путём замены всех 'O' на 'X' в исходной матрице.
Пример:
Input: board = [["X"]]
Output: [["X"]]
Начинаем с выбора всех ячеек, расположенных на границах доски.
Затем, начиная с каждой выбранной ячейки на границе, выполняем обход в глубину (DFS).
Если ячейка на границе оказывается 'O', это означает, что эта ячейка "жива", вместе с другими ячейками 'O', соединёнными с этой граничной ячейкой. Две ячейки считаются соединёнными, если между ними существует путь, состоящий только из букв 'O'.
Цель нашего обхода DFS будет заключаться в том, чтобы отметить все такие связанные ячейки 'O', которые исходят из границы, каким-либо отличительным символом, например, 'E'.
После обхода всех граничных ячеек мы получаем три типа ячеек:
Ячейки с буквой 'X': эти ячейки можно считать стеной.
Ячейки с буквой 'O': эти ячейки не затрагиваются в нашем обходе DFS, то есть они не имеют соединения с границей, следовательно, они захвачены. Эти ячейки следует заменить на букву 'X'.
Ячейки с буквой 'E': это ячейки, отмеченные в ходе нашего обхода DFS, то есть ячейки, имеющие хотя бы одно соединение с границами, следовательно, они не захвачены. В результате мы должны вернуть этим ячейкам их исходную букву 'O'.
public class Solution {
public void Solve(char[][] board) {
if (board == null || board.Length == 0) {
return;
}
this.ROWS = board.Length;
this.COLS = board[0].Length;
List<int[]> borders = new List<int[]>();
for (int r = 0; r < this.ROWS; ++r) {
borders.Add(new int[] { r, 0 });
borders.Add(new int[] { r, this.COLS - 1 });
}
for (int c = 0; c < this.COLS; ++c) {
borders.Add(new int[] { 0, c });
borders.Add(new int[] { this.ROWS - 1, c });
}
foreach (var pair in borders) {
this.DFS(board, pair[0], pair[1]);
}
for (int r = 0; r < this.ROWS; ++r) {
for (int c = 0; c < this.COLS; ++c) {
if (board[r][c] == 'O')
board[r][c] = 'X';
if (board[r][c] == 'E')
board[r][c] = 'O';
}
}
}
int ROWS, COLS;
protected void DFS(char[][] board, int row, int col) {
if (board[row][col] != 'O')
return;
board[row][col] = 'E';
if (col < this.COLS - 1)
DFS(board, row, col + 1);
if (row < this.ROWS - 1)
DFS(board, row + 1, col);
if (col > 0)
DFS(board, row, col - 1);
if (row > 0)
DFS(board, row - 1, col);
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
#Medium
Задача: 131. Palindrome Partitioning
Дана строка s. Разделите строку таким образом, чтобы каждая подстрока разделения была палиндромом. Верните все возможные варианты разделения строки s на палиндромы.
Пример:
👨💻 Алгоритм:
1️⃣ Инициация рекурсивного обхода:
В алгоритме обратного отслеживания (backtracking) мы рекурсивно пробегаем по строке, используя метод поиска в глубину (depth-first search). Для каждого рекурсивного вызова задаётся начальный индекс строки start.
Итеративно генерируем все возможные подстроки, начиная с индекса start. Индекс end увеличивается от start до конца строки.
2️⃣ Проверка на палиндром и продолжение поиска:
Для каждой сгенерированной подстроки проверяем, является ли она палиндромом.
Если подстрока оказывается палиндромом, она становится потенциальным кандидатом. Добавляем подстроку в currentList и выполняем поиск в глубину для оставшейся части строки. Если текущая подстрока заканчивается на индексе end, то end+1 становится начальным индексом для следующего рекурсивного вызова.
3️⃣ Возврат (Backtracking) и сохранение результатов:
Возвращаемся, если начальный индекс start больше или равен длине строки, и добавляем currentList в результат.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 131. Palindrome Partitioning
Дана строка s. Разделите строку таким образом, чтобы каждая подстрока разделения была палиндромом. Верните все возможные варианты разделения строки s на палиндромы.
Пример:
Input: s = "aab"
Output: [["a","a","b"],["aa","b"]]
В алгоритме обратного отслеживания (backtracking) мы рекурсивно пробегаем по строке, используя метод поиска в глубину (depth-first search). Для каждого рекурсивного вызова задаётся начальный индекс строки start.
Итеративно генерируем все возможные подстроки, начиная с индекса start. Индекс end увеличивается от start до конца строки.
Для каждой сгенерированной подстроки проверяем, является ли она палиндромом.
Если подстрока оказывается палиндромом, она становится потенциальным кандидатом. Добавляем подстроку в currentList и выполняем поиск в глубину для оставшейся части строки. Если текущая подстрока заканчивается на индексе end, то end+1 становится начальным индексом для следующего рекурсивного вызова.
Возвращаемся, если начальный индекс start больше или равен длине строки, и добавляем currentList в результат.
public class Solution {
public IList<IList<string>> Partition(string s) {
var ans = new List<IList<string>>();
Dfs(0, new List<string>(), s, ans);
return ans;
}
private void Dfs(int start, List<string> currentList, string s,
List<IList<string>> result) {
if (start >= s.Length)
result.Add(new List<string>(currentList));
else {
for (int end = start; end < s.Length; end++) {
if (IsPalindrome(s, start, end)) {
currentList.Add(s.Substring(start, end - start + 1));
Dfs(end + 1, currentList, s, result);
currentList.RemoveAt(currentList.Count - 1);
}
}
}
}
bool IsPalindrome(string s, int low, int high) {
while (low < high)
if (s[low++] != s[high--])
return false;
return true;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
#Hard
Задача: 132. Palindrome Partitioning II
Дана строка s. Разделите строку так, чтобы каждая подстрока разделения была палиндромом.
Верните минимальное количество разрезов, необходимых для разделения строки s на палиндромы.
Пример:
👨💻 Алгоритм:
1️⃣ Определение задачи и начальные условия:
Алгоритм обратного отслеживания реализуется путём рекурсивного изучения кандидатов-подстрок. Мы определяем рекурсивный метод findMinimumCut, который находит минимальное количество разрезов для подстроки, начинающейся с индекса start и заканчивающейся на индексе end.
Чтобы найти минимальное количество разрезов, мы также должны знать минимальное количество разрезов, которые были найдены ранее для других разделений на палиндромы. Эта информация отслеживается в переменной minimumCut.
Начальное значение minimumCut будет равно максимально возможному количеству разрезов в строке, что равно длине строки минус один (т.е. разрез между каждым символом).
2️⃣ Генерация подстрок и рекурсивный поиск:
Теперь, когда мы знаем начальные и конечные индексы, мы должны сгенерировать все возможные подстроки, начиная с индекса start. Для этого мы будем держать начальный индекс постоянным. currentEndIndex обозначает конец текущей подстроки.
3️⃣ Условие палиндрома и рекурсивное разделение:
Если текущая подстрока является палиндромом, мы сделаем разрез после currentEndIndex и рекурсивно найдем минимальный разрез для оставшейся строки
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 132. Palindrome Partitioning II
Дана строка s. Разделите строку так, чтобы каждая подстрока разделения была палиндромом.
Верните минимальное количество разрезов, необходимых для разделения строки s на палиндромы.
Пример:
Input: s = "aab"
Output: 1
Explanation: The palindrome partitioning ["aa","b"] could be produced using 1 cut.
Алгоритм обратного отслеживания реализуется путём рекурсивного изучения кандидатов-подстрок. Мы определяем рекурсивный метод findMinimumCut, который находит минимальное количество разрезов для подстроки, начинающейся с индекса start и заканчивающейся на индексе end.
Чтобы найти минимальное количество разрезов, мы также должны знать минимальное количество разрезов, которые были найдены ранее для других разделений на палиндромы. Эта информация отслеживается в переменной minimumCut.
Начальное значение minimumCut будет равно максимально возможному количеству разрезов в строке, что равно длине строки минус один (т.е. разрез между каждым символом).
Теперь, когда мы знаем начальные и конечные индексы, мы должны сгенерировать все возможные подстроки, начиная с индекса start. Для этого мы будем держать начальный индекс постоянным. currentEndIndex обозначает конец текущей подстроки.
Если текущая подстрока является палиндромом, мы сделаем разрез после currentEndIndex и рекурсивно найдем минимальный разрез для оставшейся строки
public class Solution {
public int MinCut(string s) {
return findMinimumCut(s, 0, s.Length - 1, s.Length - 1);
}
private int findMinimumCut(string s, int start, int end, int minimumCut) {
if (start == end || isPalindrome(s, start, end)) {
return 0;
}
for (int currentEndIndex = start; currentEndIndex <= end; currentEndIndex++) {
if (isPalindrome(s, start, currentEndIndex)) {
minimumCut = Math.Min(
minimumCut, 1 + findMinimumCut(s, currentEndIndex + 1, end, minimumCut));
}
}
return minimumCut;
}
private bool isPalindrome(string s, int start, int end) {
while (start < end) {
if (s[start++] != s[end--]) {
return false;
}
}
return true;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#medium
Задача: 133. Clone Graph
Дана ссылка на узел в связанном неориентированном графе.
Верните глубокую копию (клон) графа.
Каждый узел в графе содержит значение (целое число) и список (List[Node]) своих соседей.
Пример:
👨💻 Алгоритм:
1️⃣ Используйте хеш-таблицу для хранения ссылок на копии всех уже посещенных и скопированных узлов. Ключом будет узел оригинального графа, а значением — соответствующий клонированный узел клонированного графа. Хеш-таблица посещенных узлов также используется для предотвращения циклов.
2️⃣ Добавьте первый узел в очередь, клонируйте его и добавьте в хеш-таблицу посещенных.
3️⃣ Выполните обход в ширину (BFS): извлеките узел из начала очереди, посетите всех соседей этого узла. Если какой-либо сосед уже был посещен, получите его клон из хеш-таблицы посещенных; если нет, создайте клон и добавьте его в хеш-таблицу. Добавьте клоны соседей в список соседей клонированного узла.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 133. Clone Graph
Дана ссылка на узел в связанном неориентированном графе.
Верните глубокую копию (клон) графа.
Каждый узел в графе содержит значение (целое число) и список (List[Node]) своих соседей.
Пример:
Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Output: [[2,4],[1,3],[2,4],[1,3]]
Explanation: There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
using System.Collections.Generic;
public class Node {
public int val;
public IList<Node> neighbors;
public Node() {
val = 0;
neighbors = new List<Node>();
}
public Node(int _val) {
val = _val;
neighbors = new List<Node>();
}
public Node(int _val, List<Node> _neighbors) {
val = _val;
neighbors = _neighbors;
}
}
public class Solution {
public Node CloneGraph(Node node) {
if (node == null) {
return node;
}
Dictionary<Node, Node> visited = new Dictionary<Node, Node>();
Queue<Node> queue = new Queue<Node>();
queue.Enqueue(node);
visited[node] = new Node(node.val, new List<Node>());
while (queue.Count > 0) {
Node n = queue.Dequeue();
foreach (Node neighbor in n.neighbors) {
if (!visited.ContainsKey(neighbor)) {
visited[neighbor] = new Node(neighbor.val, new List<Node>());
queue.Enqueue(neighbor);
}
visited[n].neighbors.Add(visited[neighbor]);
}
}
return visited[node];
}
}
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
#medium
Задача: 134. Gas Station
Вдоль кругового маршрута расположены n заправочных станций, на каждой из которых находится определённое количество топлива gas[i].
У вас есть автомобиль с неограниченным топливным баком, и для проезда от i-й станции к следующей (i + 1)-й станции требуется cost[i] топлива. Путешествие начинается с пустым баком на одной из заправочных станций.
Учитывая два массива целых чисел gas и cost, верните индекс начальной заправочной станции, если вы можете проехать вокруг цепи один раз по часовой стрелке, в противном случае верните -1. Если решение существует, оно гарантированно будет уникальным.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте переменные curr_gain, total_gain и answer значением 0.
2️⃣ Пройдите по массивам gas и cost. Для каждого индекса i увеличивайте total_gain и curr_gain на gas[i] - cost[i].
Если curr_gain меньше 0, проверьте, может ли станция i + 1 быть начальной станцией: установите answer как i + 1, сбросьте curr_gain до 0 и повторите шаг 2.
3️⃣ По завершении итерации, если total_gain меньше 0, верните -1. В противном случае верните answer.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 134. Gas Station
Вдоль кругового маршрута расположены n заправочных станций, на каждой из которых находится определённое количество топлива gas[i].
У вас есть автомобиль с неограниченным топливным баком, и для проезда от i-й станции к следующей (i + 1)-й станции требуется cost[i] топлива. Путешествие начинается с пустым баком на одной из заправочных станций.
Учитывая два массива целых чисел gas и cost, верните индекс начальной заправочной станции, если вы можете проехать вокруг цепи один раз по часовой стрелке, в противном случае верните -1. Если решение существует, оно гарантированно будет уникальным.
Пример:
Input: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
Output: 3
Explanation:
Start at station 3 (index 3) and fill up with 4 unit of gas. Your tank = 0 + 4 = 4
Travel to station 4. Your tank = 4 - 1 + 5 = 8
Travel to station 0. Your tank = 8 - 2 + 1 = 7
Travel to station 1. Your tank = 7 - 3 + 2 = 6
Travel to station 2. Your tank = 6 - 4 + 3 = 5
Travel to station 3. The cost is 5. Your gas is just enough to travel back to station 3.
Therefore, return 3 as the starting index.
Если curr_gain меньше 0, проверьте, может ли станция i + 1 быть начальной станцией: установите answer как i + 1, сбросьте curr_gain до 0 и повторите шаг 2.
public class Solution {
public int CanCompleteCircuit(int[] gas, int[] cost) {
int currGain = 0, totalGain = 0, answer = 0;
for (int i = 0; i < gas.Length; ++i) {
totalGain += gas[i] - cost[i];
currGain += gas[i] - cost[i];
if (currGain < 0) {
answer = i + 1;
currGain = 0;
}
}
return totalGain >= 0 ? answer : -1;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
#hard
Задача: 135. Candy
В очереди стоят n детей. Каждому ребенку присвоено значение рейтинга, указанное в массиве целых чисел ratings.
Вы раздаете конфеты этим детям с соблюдением следующих требований:
Каждый ребенок должен получить как минимум одну конфету.
Дети с более высоким рейтингом должны получать больше конфет, чем их соседи.
Верните минимальное количество конфет, которое вам нужно иметь, чтобы распределить их среди детей.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация и первичное заполнение массивов:
Создайте два массива: left2right для расчета конфет с учетом только левых соседей и right2left для расчета с учетом только правых соседей. Изначально каждому ученику в обоих массивах присваивается по одной конфете.
2️⃣ Обход и обновление значений в массивах:
Проходите массив ratings слева направо, увеличивая значение в left2right для каждого ученика, чей рейтинг выше рейтинга его левого соседа.
Затем проходите массив справа налево, увеличивая значение в right2left для каждого ученика, чей рейтинг выше рейтинга его правого соседа.
3️⃣ Расчет минимального количества конфет:
Для каждого ученика определите максимальное значение конфет между left2right[i] и right2left[i], чтобы соответствовать требованиям к распределению конфет.
Суммируйте полученные значения для всех учеников, чтобы найти минимальное количество конфет, необходимое для соблюдения всех правил.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 135. Candy
В очереди стоят n детей. Каждому ребенку присвоено значение рейтинга, указанное в массиве целых чисел ratings.
Вы раздаете конфеты этим детям с соблюдением следующих требований:
Каждый ребенок должен получить как минимум одну конфету.
Дети с более высоким рейтингом должны получать больше конфет, чем их соседи.
Верните минимальное количество конфет, которое вам нужно иметь, чтобы распределить их среди детей.
Пример:
Input: ratings = [1,0,2]
Output: 5
Explanation: You can allocate to the first, second and third child with 2, 1, 2 candies respectively.
Создайте два массива: left2right для расчета конфет с учетом только левых соседей и right2left для расчета с учетом только правых соседей. Изначально каждому ученику в обоих массивах присваивается по одной конфете.
Проходите массив ratings слева направо, увеличивая значение в left2right для каждого ученика, чей рейтинг выше рейтинга его левого соседа.
Затем проходите массив справа налево, увеличивая значение в right2left для каждого ученика, чей рейтинг выше рейтинга его правого соседа.
Для каждого ученика определите максимальное значение конфет между left2right[i] и right2left[i], чтобы соответствовать требованиям к распределению конфет.
Суммируйте полученные значения для всех учеников, чтобы найти минимальное количество конфет, необходимое для соблюдения всех правил.
public class Solution {
public int Candy(int[] ratings) {
int sum = 0;
int length = ratings.Length;
int[] left2right = Enumerable.Repeat(1, length).ToArray();
int[] right2left = Enumerable.Repeat(1, length).ToArray();
for (int i = 1; i < length; i++) {
if (ratings[i] > ratings[i - 1]) {
left2right[i] = left2right[i - 1] + 1;
}
}
for (int i = length - 2; i >= 0; i--) {
if (ratings[i] > ratings[i + 1]) {
right2left[i] = right2left[i + 1] + 1;
}
}
for (int i = 0; i < length; i++) {
sum += Math.Max(left2right[i], right2left[i]);
}
return sum;
}
}Please open Telegram to view this post
VIEW IN TELEGRAM
❤1