
Когда не нужно заменять HashMap на ArrayMap
Думаю, все в курсе — если попробовать использовать HashMap, студия предложит заменить тип на ArrayMap
Почему (короткий ответ) — ArrayMap оптимизирован под Android
Почему (правильный ответ) —
HashMap для каждой пары ключ-значение создаёт объект Map.Entry, который хранит ключ, значение, хэш ключа, ссылку на следующий объект
Такая сложность нужна, так как HashMap хранит данные в массиве массивов (см. "связанные посты" в комментариях)
Но даже пустой объект весит n-байт, а тут столько побочной информации
Поэтому ArrayMap реализует другой подход: он содержит два массива - один mArray для keys и objects, второй mHashes для хэша ключей
Процесс добавления новой пары:
1. в mArray кладется ключ
2. на следующую позицию в mArray кладется объект
3. вычисляется hash от ключа и кладется в mHashes
Вывод: в HashMap поиск по ключу быстрее, но ArrayMap съедает в разы меньше памяти
....
А зачем тогда SparseArray?
Бывали ли у вас ситуации, когда правильный выбор структуры давал заметный прирост к производительности или андроид-разработчику в реальности такие знания не пригождаются?
Думаю, все в курсе — если попробовать использовать HashMap, студия предложит заменить тип на ArrayMap
Почему (короткий ответ) — ArrayMap оптимизирован под Android
Почему (правильный ответ) —
HashMap для каждой пары ключ-значение создаёт объект Map.Entry, который хранит ключ, значение, хэш ключа, ссылку на следующий объект
Такая сложность нужна, так как HashMap хранит данные в массиве массивов (см. "связанные посты" в комментариях)
Но даже пустой объект весит n-байт, а тут столько побочной информации
Поэтому ArrayMap реализует другой подход: он содержит два массива - один mArray для keys и objects, второй mHashes для хэша ключей
Процесс добавления новой пары:
1. в mArray кладется ключ
2. на следующую позицию в mArray кладется объект
3. вычисляется hash от ключа и кладется в mHashes
Вывод: в HashMap поиск по ключу быстрее, но ArrayMap съедает в разы меньше памяти
....
А зачем тогда SparseArray?
Бывали ли у вас ситуации, когда правильный выбор структуры давал заметный прирост к производительности или андроид-разработчику в реальности такие знания не пригождаются?
{kind=link}
👍2👎1
с наступившим, работяги!
желаю отдохнуть от работы, учебы, самообразования и всего, от чего хочется отдохнуть, чтобы взяться за все это с новыми силами и получить новые успехи
желаю отдохнуть от работы, учебы, самообразования и всего, от чего хочется отдохнуть, чтобы взяться за все это с новыми силами и получить новые успехи
{kind=link}
❤1
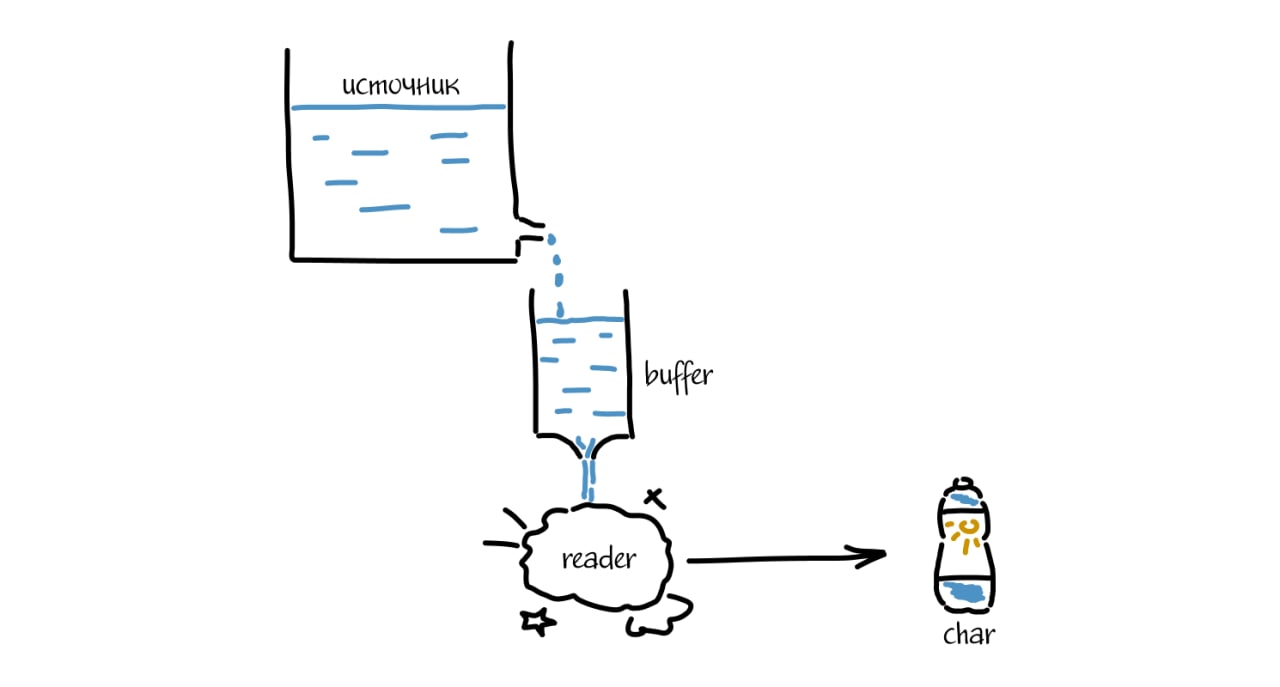
Концепция InputStream - Reader - Buffered
С понятием InputStream мобильный разработчик сталкивается, когда нужно прочитать локальный файл или загрузить его по ссылке
Общая логика считывания больших объемов данных (или данных неизвестного размера) следующая:
• InputStream (все его реализации) — класс, позволяющий обозначить источник данных (файл, ссылка, массив байтов...) и начать считывать его байт за байтом
• Reader (все его реализации) — класс, преобразующий байты, считываемые при помощи InputStream, в символы по заданной таблице кодирования (например, Unicode)
• Buffered (все его реализации) — класс, позволяющий ускорить процесс чтения за счет буферизации источника данных
Зачем буфер: если мы читаем файл с жесткого диска, то каждая операция запроса и переноса байтов с самого диска в оперативку занимает много времени. Потому нашей программе лучше за одно обращение считать n-байтов, а не один. Это справедливо для сетевых запросов
Комбинация реализаций позволяет считать данные в нужном формате и с оптимальными настройками буферизации
Та же самая история справедлива и для отдачи байтов: OutputStream - Writer - Buffered
....
загадка: по какой таблице кодирования Reader/Writer сопоставит байты и символы? откуда он ее возьмет - зашита в Java, определена в Android, задается JVM...?
С понятием InputStream мобильный разработчик сталкивается, когда нужно прочитать локальный файл или загрузить его по ссылке
Общая логика считывания больших объемов данных (или данных неизвестного размера) следующая:
• InputStream (все его реализации) — класс, позволяющий обозначить источник данных (файл, ссылка, массив байтов...) и начать считывать его байт за байтом
• Reader (все его реализации) — класс, преобразующий байты, считываемые при помощи InputStream, в символы по заданной таблице кодирования (например, Unicode)
• Buffered (все его реализации) — класс, позволяющий ускорить процесс чтения за счет буферизации источника данных
Зачем буфер: если мы читаем файл с жесткого диска, то каждая операция запроса и переноса байтов с самого диска в оперативку занимает много времени. Потому нашей программе лучше за одно обращение считать n-байтов, а не один. Это справедливо для сетевых запросов
Комбинация реализаций позволяет считать данные в нужном формате и с оптимальными настройками буферизации
Та же самая история справедлива и для отдачи байтов: OutputStream - Writer - Buffered
....
загадка: по какой таблице кодирования Reader/Writer сопоставит байты и символы? откуда он ее возьмет - зашита в Java, определена в Android, задается JVM...?
{kind=link}
🔥5👍3❤1
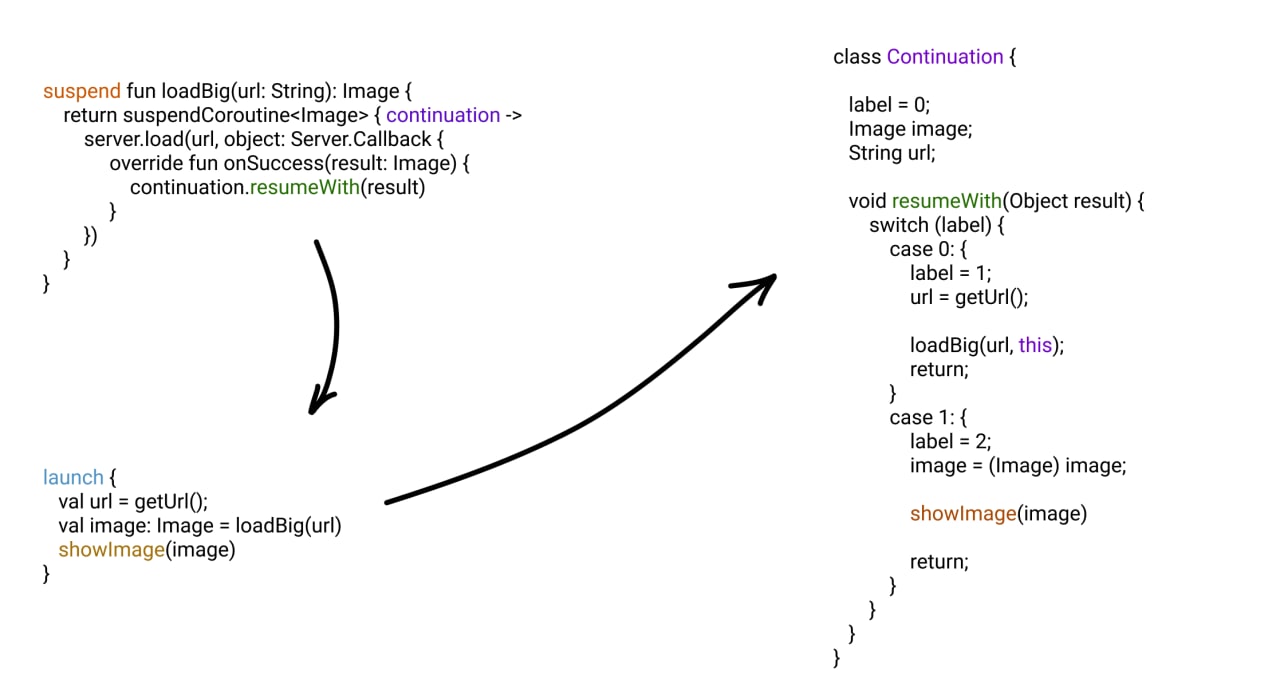
Kotlin Coroutine. Suspend — зачем и как?
suspend — ключевое слово, которое говорит компилятору о том, что в функцию нужно добавить (и передать при вызове) аргумент типа Continuation
Continuation — интерфейс, который содержит одну функцию resumeWith(result: Result<T>). то есть обычный колбэк
когда suspend-функция выполнила работу, она должна вызвать continuation.resumeWith(result)
если она этого не сделает, то корутина, вызвавшая эту suspend-функцию, просто зависнет
после вызова колбэка, корутина, запустившая suspend-функцию, получит результат (если функция обещала что-то вернуть) и продолжит работу
примечание: разработчику самому нужно вызывать continuation.resumeWith(result) только когда он использует suspendCoroutine { ... }. в остальных корутин-билдерах оно вызывается самостоятельно под капотом
Выводы:
• suspend само по себе не делает функцию асинхронной, только добавляет параметр при компиляции
если вы на функцию поставите клеймо suspend, но долгие операции, выполняемые в ней, не вынесите в отдельный поток, то асинхронность не случится
• suspend-функцию можно вызвать только из корутины (или другой suspend-функции)
потому что Continuation — это объект, который создается в корутине и передается suspend-функциям внутри нее
suspend — ключевое слово, которое говорит компилятору о том, что в функцию нужно добавить (и передать при вызове) аргумент типа Continuation
Continuation — интерфейс, который содержит одну функцию resumeWith(result: Result<T>). то есть обычный колбэк
когда suspend-функция выполнила работу, она должна вызвать continuation.resumeWith(result)
если она этого не сделает, то корутина, вызвавшая эту suspend-функцию, просто зависнет
после вызова колбэка, корутина, запустившая suspend-функцию, получит результат (если функция обещала что-то вернуть) и продолжит работу
примечание: разработчику самому нужно вызывать continuation.resumeWith(result) только когда он использует suspendCoroutine { ... }. в остальных корутин-билдерах оно вызывается самостоятельно под капотом
Выводы:
• suspend само по себе не делает функцию асинхронной, только добавляет параметр при компиляции
если вы на функцию поставите клеймо suspend, но долгие операции, выполняемые в ней, не вынесите в отдельный поток, то асинхронность не случится
• suspend-функцию можно вызвать только из корутины (или другой suspend-функции)
потому что Continuation — это объект, который создается в корутине и передается suspend-функциям внутри нее
{kind=link}
🔥16👍7
sealed interface vs sealed class vs enum
enum:
• в первую очередь - это перечисление. поэтому у него есть методы для перебора значений
• у каждой константы перечисления есть только параметры, описанные в конструкторе родительского enum
• у каждого константы перечисления есть только функции, объявленные как abstract или определенные в родительском enum
• каждое константы перечисления - object, то есть имеет один экземпляр
• реализует serializable (удобно сохранять\отправлять как строку) и comporable (непонятно зачем)
sealed:
• в первую очередь - обычный класс
• каждый из наследников может иметь свой конструктор, свои функции
• наследниками могут быть как object, так и class
следовательно, наследники-классы могут существовать в нескольких экземплярах
• в отличие от обычных open-классов, все наследники sealed класса должны быть определены до компиляции
то есть sealed что-то среднее между open и final-классами
sealed class или sealed interface:
• class - если хочешь создать переменную в конструкторе\внутри класса
• interface - если переменные не нужны\достаточно констант в companion object
....
в каких конкретно кейсах вы используете sealed, а в каких enum?
enum:
• в первую очередь - это перечисление. поэтому у него есть методы для перебора значений
• у каждой константы перечисления есть только параметры, описанные в конструкторе родительского enum
• у каждого константы перечисления есть только функции, объявленные как abstract или определенные в родительском enum
• каждое константы перечисления - object, то есть имеет один экземпляр
• реализует serializable (удобно сохранять\отправлять как строку) и comporable (непонятно зачем)
sealed:
• в первую очередь - обычный класс
• каждый из наследников может иметь свой конструктор, свои функции
• наследниками могут быть как object, так и class
следовательно, наследники-классы могут существовать в нескольких экземплярах
• в отличие от обычных open-классов, все наследники sealed класса должны быть определены до компиляции
то есть sealed что-то среднее между open и final-классами
sealed class или sealed interface:
• class - если хочешь создать переменную в конструкторе\внутри класса
• interface - если переменные не нужны\достаточно констант в companion object
....
в каких конкретно кейсах вы используете sealed, а в каких enum?
{kind=link}
👍8😁4🔥3🤩1
новая карта канала
в давности обещал усовершенствовать карту канала. момент настал:
• можно увидеть список всех вышедших постов на одном экране
• с помощью поиска по заголовку и телу отыщатся посты на интересующие вас темы
• киллерфича — кнопка "открыть рандомный пост". использовать, когда хочется получить новые знания, но не знаешь, с чего начать
android-dpd.ru
....
в комментариях можно предлагать недостающие фичи, высмеивать баги и голосовать, нужен ли полноценный многостраничник
в давности обещал усовершенствовать карту канала. момент настал:
• можно увидеть список всех вышедших постов на одном экране
• с помощью поиска по заголовку и телу отыщатся посты на интересующие вас темы
• киллерфича — кнопка "открыть рандомный пост". использовать, когда хочется получить новые знания, но не знаешь, с чего начать
android-dpd.ru
....
в комментариях можно предлагать недостающие фичи, высмеивать баги и голосовать, нужен ли полноценный многостраничник
{kind=link}
🔥11🎉5👍4
Dolgo.polo Dev | Денис Долгополов pinned «новая карта канала в давности обещал усовершенствовать карту канала. момент настал: • можно увидеть список всех вышедших постов на одном экране • с помощью поиска по заголовку и телу отыщатся посты на интересующие вас темы • киллерфича — кнопка "открыть…»
Kotlin Coroutine — корутины за 100 слов
Основные принципы:
• Приостанавливаемые — могут в определенных точках запомнить свое состояние, замереть, дать потоку выполнить часть другой функции, а после продолжить выполнение с той же точки
• Асинхронные — за счет приостанавливаемости функции разбиваются на блоки. Поток может выполнять блоки от разных функций вперемешку
• Прекращаемые — можем прекратить выполнение функции с помощью job.cancel()
Функция замечает, что ее отменили, когда проверяет флаг Job.isActive
Основные понятия:
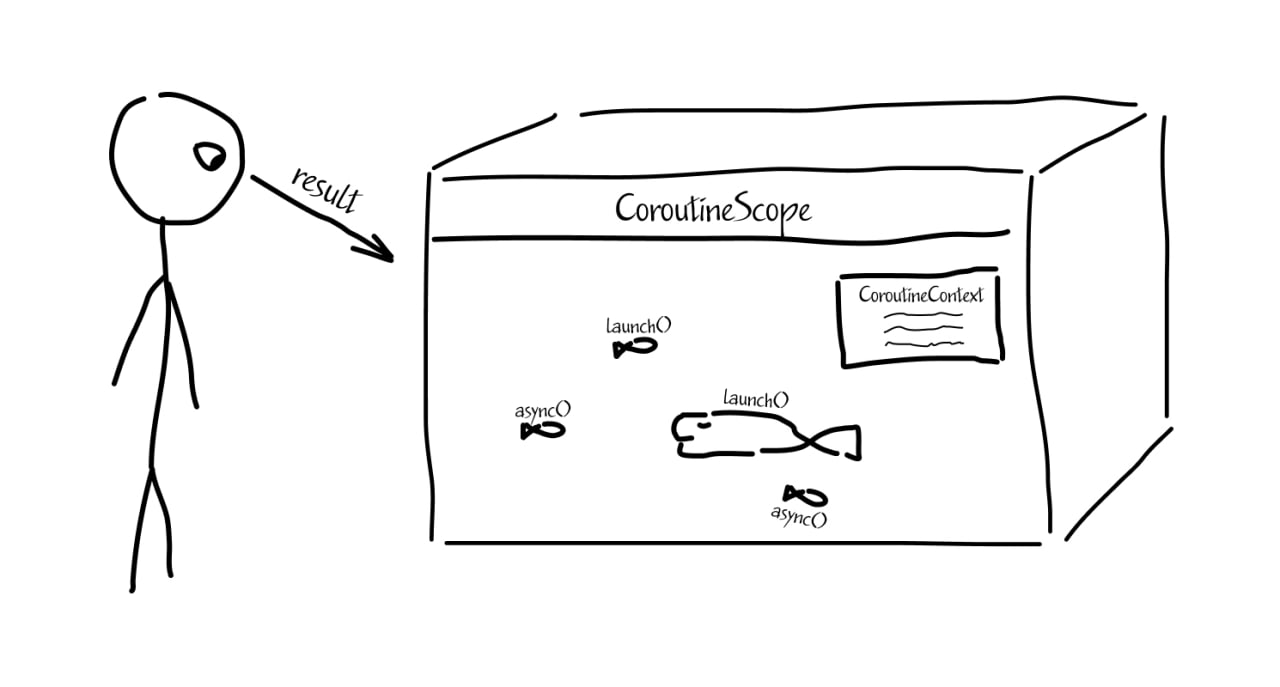
• CoroutineScope — контейнер для корутин
дает возможность сгруппировать корутины, задать параметры CoroutineContext и отменить сразу все дочерние корутины
корутины могут быть запущены только внутри CoroutineScope
• CoroutineContext — характеристики для CoroutineScope
Например, Dispatcher.Main - это наследник CoroutineContext - задает пул потоков, в котором будут выполняться функции
• suspend — указывает, что функция может содержать асинхронный код
• Job — объект, описывающий состояние корутины
Напримери, содержит флаг isActive
• Deffered<T> — расширяет Job. Позволяет вернуть значение из корутины
Основные билдеры — функции, создающие и сразу запускающие корутину:
• launch — возвращает Job
• async — возвращает Deffered<T>
• suspendCoroutine(cont: Continuation<T>) — возвращает T, который нужно вернуть через колбек cont.resume(obj: T)
Основные принципы:
• Приостанавливаемые — могут в определенных точках запомнить свое состояние, замереть, дать потоку выполнить часть другой функции, а после продолжить выполнение с той же точки
• Асинхронные — за счет приостанавливаемости функции разбиваются на блоки. Поток может выполнять блоки от разных функций вперемешку
• Прекращаемые — можем прекратить выполнение функции с помощью job.cancel()
Функция замечает, что ее отменили, когда проверяет флаг Job.isActive
Основные понятия:
• CoroutineScope — контейнер для корутин
дает возможность сгруппировать корутины, задать параметры CoroutineContext и отменить сразу все дочерние корутины
корутины могут быть запущены только внутри CoroutineScope
• CoroutineContext — характеристики для CoroutineScope
Например, Dispatcher.Main - это наследник CoroutineContext - задает пул потоков, в котором будут выполняться функции
• suspend — указывает, что функция может содержать асинхронный код
• Job — объект, описывающий состояние корутины
Напримери, содержит флаг isActive
• Deffered<T> — расширяет Job. Позволяет вернуть значение из корутины
Основные билдеры — функции, создающие и сразу запускающие корутину:
• launch — возвращает Job
• async — возвращает Deffered<T>
• suspendCoroutine(cont: Continuation<T>) — возвращает T, который нужно вернуть через колбек cont.resume(obj: T)
{kind=link}
👍25❤3
ладно, возвращаемся
для начала не будет забавной пикчи, будет предположения о последствиях нового закона об IT
плюсы:
• освобождение от налогов — у компаний останется значительно больше дохода на развитие
• отсрочка от армии — приличной части айтишников действительно будет полезнее провести год, занимаясь профильным делом
• льготная ипотека сотрудникам — кредиты под хорошую ставку всегда хорошо
минусы:
• освобождение от налогов
тут нужно учитывать, что у государства не так много видов дохода. один из них — налоги
если их начинают собирать меньше, то в бюджете становится меньше денег на добрые дела (развитие инфраструктуры, безопасности, поддержки нуждающихся)
значит, нужно либо больше печатать, либо больше собирать с других, либо урезать расходы
• отсрочка от армии
вероятнее всего, в законе будет прописано, что отсрочку получат только те, кто отработал энное количество времени на организацию
значит, у компаний будет козырь на снижение зарплат молодым специалистам: "не хочешь работать за полцены? мы тебя списываем с должности жизненно важного айтишника и твоя отсрочка сгорает"
не то чтобы это совсем нечестно, просто к этому нужно быть готовым
• льготная ипотека сотрудникам
риски аналогичны предыдущему пункту
перебежать из компании в компанию (или шантажировать начальство офером в другую компанию) станет куда сложнее, если твоя ипотека превращается в анти-льготную при переходе в другую компанию
опять же, это абсолютно честно, но бесконечный рост айтишных зарплат замедлит
для начала не будет забавной пикчи, будет предположения о последствиях нового закона об IT
плюсы:
• освобождение от налогов — у компаний останется значительно больше дохода на развитие
• отсрочка от армии — приличной части айтишников действительно будет полезнее провести год, занимаясь профильным делом
• льготная ипотека сотрудникам — кредиты под хорошую ставку всегда хорошо
минусы:
• освобождение от налогов
тут нужно учитывать, что у государства не так много видов дохода. один из них — налоги
если их начинают собирать меньше, то в бюджете становится меньше денег на добрые дела (развитие инфраструктуры, безопасности, поддержки нуждающихся)
значит, нужно либо больше печатать, либо больше собирать с других, либо урезать расходы
• отсрочка от армии
вероятнее всего, в законе будет прописано, что отсрочку получат только те, кто отработал энное количество времени на организацию
значит, у компаний будет козырь на снижение зарплат молодым специалистам: "не хочешь работать за полцены? мы тебя списываем с должности жизненно важного айтишника и твоя отсрочка сгорает"
не то чтобы это совсем нечестно, просто к этому нужно быть готовым
• льготная ипотека сотрудникам
риски аналогичны предыдущему пункту
перебежать из компании в компанию (или шантажировать начальство офером в другую компанию) станет куда сложнее, если твоя ипотека превращается в анти-льготную при переходе в другую компанию
опять же, это абсолютно честно, но бесконечный рост айтишных зарплат замедлит
👍2
Типы permissions для получения локации
Для работы с местоположением, нужно явно запросить одно из разрешений:
• ACCESS COARSE LOCATION
когда приложение находится в статусе foreground (открыта активити или запущен сервис с уведмолением) и нужно получить примерную локацию (точность порядка +-3 км)
• ACCESS FINE LOCATION
статус foreground и нужно получить точную локацию (порядка +-10-50м)
• ACCESS BACKGROUND LOCATION
можно получать локацию, когда приложение не имеет статуса foreground
такое нужно приложениям для семейного контроля, отслеживанию друзей или IoT-пультам
особенности:
• можно запросить только COARSE, но нельзя запросить только FINE
если вам нужно разрешение ACCESS FINE LOCATION, запрашивайте сразу оба, а пользователь выберет - дать точную локацию, приближенную или отказать
• если пользователь уже выдал COARSE, можно запросить апгрейд до FINE
для этого снова выполните запрос на оба разрешения
• запрашивать ACCESS BACKGROUND LOCATION можно после получения одного из foreground-разрешений
при этом, если получено только COARSE, то только эта точность и будет доступна в background
....
описанные механики разнятся от версии к версии андроида
приведенная логика справедлива для Android 12, в более старых некоторые требования мягче
Для работы с местоположением, нужно явно запросить одно из разрешений:
• ACCESS COARSE LOCATION
когда приложение находится в статусе foreground (открыта активити или запущен сервис с уведмолением) и нужно получить примерную локацию (точность порядка +-3 км)
• ACCESS FINE LOCATION
статус foreground и нужно получить точную локацию (порядка +-10-50м)
• ACCESS BACKGROUND LOCATION
можно получать локацию, когда приложение не имеет статуса foreground
такое нужно приложениям для семейного контроля, отслеживанию друзей или IoT-пультам
особенности:
• можно запросить только COARSE, но нельзя запросить только FINE
если вам нужно разрешение ACCESS FINE LOCATION, запрашивайте сразу оба, а пользователь выберет - дать точную локацию, приближенную или отказать
• если пользователь уже выдал COARSE, можно запросить апгрейд до FINE
для этого снова выполните запрос на оба разрешения
• запрашивать ACCESS BACKGROUND LOCATION можно после получения одного из foreground-разрешений
при этом, если получено только COARSE, то только эта точность и будет доступна в background
....
описанные механики разнятся от версии к версии андроида
приведенная логика справедлива для Android 12, в более старых некоторые требования мягче
{kind=link}
👍11🔥2
Философия LayoutParams
xml-вьюшки стремительно отмирают в пользу Compose. уважим их несколькими постами и заодно разберемся, почему у людей возникло желание от них избавиться
свойства LayoutParams:
• базовый класс — ViewGroup.LayoutParams
он содержит только два свойства - height, weight
• View получают LayoutParams от ближайшего родительского ViewGroup
если родитель вьюшки - RelativeLayout, то View.mLayoutParams = RelativeLayout.LayoutParams
если у вьюшки нет родителя (она еще не attached), то View.mLayoutParams = null
• ViewGroup.LayoutParams расширяется наследниками
например, есть такая иерархия: RelativeLayout.LayoutParams extends ViewGroup.MarginLayoutParams extends ViewGroup.LayoutParams
• если вызвать View.setLayoutParams(...), то View передаст новые параметры родителю, тот перерисует себя, а после перерисуется сама View
....
какие отрицательные побочки мы получаем от наследовательной архитектуры LayoutParams? в чем ее минусы (из-за которых набирает популярность compose)?
xml-вьюшки стремительно отмирают в пользу Compose. уважим их несколькими постами и заодно разберемся, почему у людей возникло желание от них избавиться
свойства LayoutParams:
• базовый класс — ViewGroup.LayoutParams
он содержит только два свойства - height, weight
• View получают LayoutParams от ближайшего родительского ViewGroup
если родитель вьюшки - RelativeLayout, то View.mLayoutParams = RelativeLayout.LayoutParams
если у вьюшки нет родителя (она еще не attached), то View.mLayoutParams = null
• ViewGroup.LayoutParams расширяется наследниками
например, есть такая иерархия: RelativeLayout.LayoutParams extends ViewGroup.MarginLayoutParams extends ViewGroup.LayoutParams
• если вызвать View.setLayoutParams(...), то View передаст новые параметры родителю, тот перерисует себя, а после перерисуется сама View
....
какие отрицательные побочки мы получаем от наследовательной архитектуры LayoutParams? в чем ее минусы (из-за которых набирает популярность compose)?
{kind=link}
👍6
Xml — зачем префиксы android, tools, app
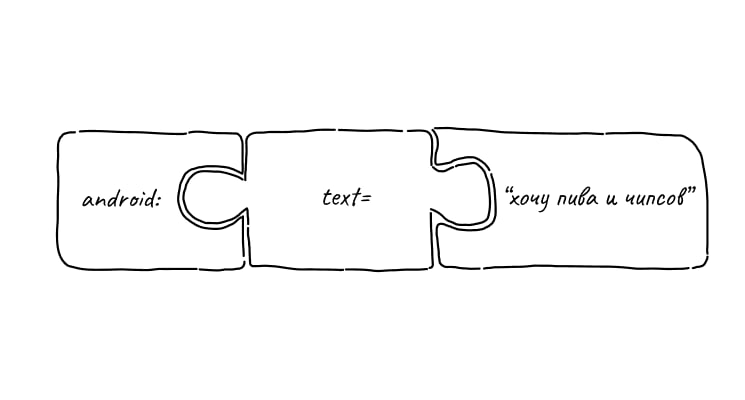
Описывая вьюшки в xml-файлах, мы чаще всего пишем android:paramName="value"
В этом случае android — это префикс
Префикс принято объявлять в самом старшем элементе xml-файла — используется следующая конструкция:
xmlns:prefixName="URI"
Зачем?
чтобы можно было легко подменять способ применения параметра, не изменяя его имени
например, параметр text для TextView
• если написать, android:text="value", то после запуска приложения мы увидим в TextView текст "value"
• если написать tools:text="value", то в редакторе студии мы увидим в TextView текст "value", а при запуске приложения - нет
один и тот же параметр обработался по-разному
Существуют следующие префиксы:
• android — параметры, которые повлияют на работу приложения
• tools — параметры, которые учитываются Lint и визуальным редактором студии, но вырезаются при компиляции
• app — создание собственных параметров (или использования кастомных параметров из библиотек)
....
почему ссылка из объявления префикса не открывается?
например, xmlns:app="https://schemas.android.com/apk/res-auto"
Описывая вьюшки в xml-файлах, мы чаще всего пишем android:paramName="value"
В этом случае android — это префикс
Префикс принято объявлять в самом старшем элементе xml-файла — используется следующая конструкция:
xmlns:prefixName="URI"
Зачем?
чтобы можно было легко подменять способ применения параметра, не изменяя его имени
например, параметр text для TextView
• если написать, android:text="value", то после запуска приложения мы увидим в TextView текст "value"
• если написать tools:text="value", то в редакторе студии мы увидим в TextView текст "value", а при запуске приложения - нет
один и тот же параметр обработался по-разному
Существуют следующие префиксы:
• android — параметры, которые повлияют на работу приложения
• tools — параметры, которые учитываются Lint и визуальным редактором студии, но вырезаются при компиляции
• app — создание собственных параметров (или использования кастомных параметров из библиотек)
....
почему ссылка из объявления префикса не открывается?
например, xmlns:app="https://schemas.android.com/apk/res-auto"
{kind=link}
👍17🤩1
Философия LayoutInflator
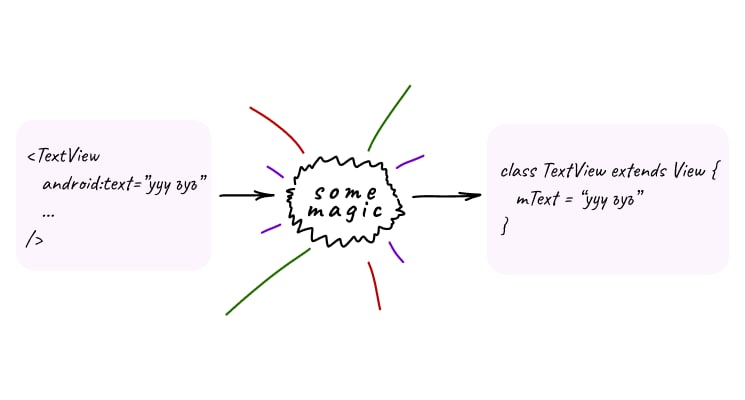
LayoutInflator — класс, умеющий создавать из xml-разметки объект View
По умолчанию он использует стандартный парсер XmlPullParser, но можно передать свой (зачем - придумать сложно)
Способности:
• inflate(...) — парсит xml-файл в View-объект
если передать ссылку на родителя-ViewGroup, то LayoutInflator автоматически прикрепит View к родителю и вернет ссылку не на View, а на этого родителя
при передачи родителя View получает родительский LayoutParams. если родителя нет — View.mLayoutParams = null
• createView(...)
может создать нужную View без xml-файла
замечание:
findViewById(...) — не парсит xml, а осуществляет поиск по уже созданным View
LayoutInflator — класс, умеющий создавать из xml-разметки объект View
По умолчанию он использует стандартный парсер XmlPullParser, но можно передать свой (зачем - придумать сложно)
Способности:
• inflate(...) — парсит xml-файл в View-объект
если передать ссылку на родителя-ViewGroup, то LayoutInflator автоматически прикрепит View к родителю и вернет ссылку не на View, а на этого родителя
при передачи родителя View получает родительский LayoutParams. если родителя нет — View.mLayoutParams = null
• createView(...)
может создать нужную View без xml-файла
замечание:
findViewById(...) — не парсит xml, а осуществляет поиск по уже созданным View
{kind=link}
👍27🔥1🎉1
Kotlin Operator
Еще одна возможность котлина, которой можно придумать применение в своем проекте
чтобы коллеги потом ходили и спрашивали, чего ты там такой умный понапридумывал
Как работает:
1. помечаем функцию словом operator
2. даем ей одно из заложенных в языке названий
например, unaryPlus() связана с оператором "+"
3. пишем реализацию этой функции — все, что душе угодно
Например (напишем через extensions-функцию — гулять так гулять):
operator fun User.unaryPlus() : User {
this. name = this. name + " vot eto ya molodec"
return this
}
используем:
user. name = "Ivan"
print( (+user).name) )
получаем:
Ivan vot eto ya molodec
также доступны функции:
• unaryMinus() == "-"
• not() = "!"
• plus() == a "+" b
• rangeTo() == a".."b
и другие
....
где в реальном проекте этому можно найти хорошее применение?
Еще одна возможность котлина, которой можно придумать применение в своем проекте
чтобы коллеги потом ходили и спрашивали, чего ты там такой умный понапридумывал
Как работает:
1. помечаем функцию словом operator
2. даем ей одно из заложенных в языке названий
например, unaryPlus() связана с оператором "+"
3. пишем реализацию этой функции — все, что душе угодно
Например (напишем через extensions-функцию — гулять так гулять):
operator fun User.unaryPlus() : User {
this. name = this. name + " vot eto ya molodec"
return this
}
используем:
user. name = "Ivan"
print( (+user).name) )
получаем:
Ivan vot eto ya molodec
также доступны функции:
• unaryMinus() == "-"
• not() = "!"
• plus() == a "+" b
• rangeTo() == a".."b
и другие
....
где в реальном проекте этому можно найти хорошее применение?
{kind=link}
👍9🔥7😁3🎉1
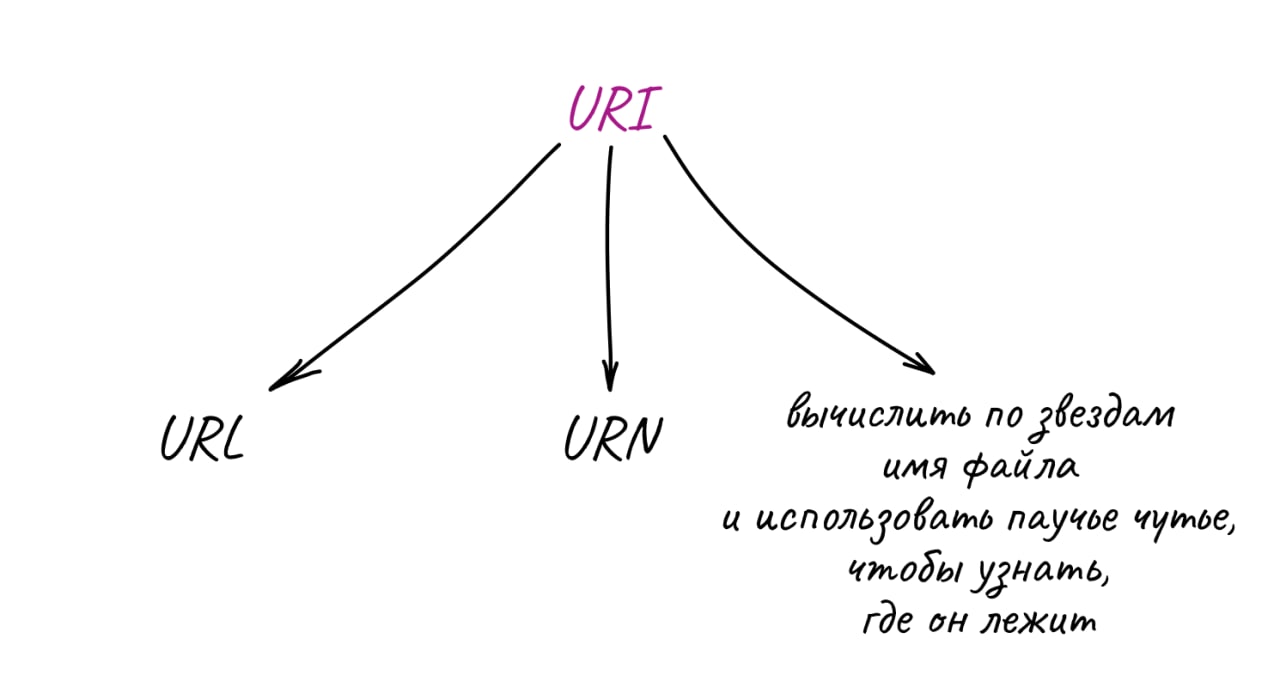
URL vs URI
При работе с файлами или интернетом можно заметить, что иногда нужно указывать URL, а иногда — URI. а почему?
URI — это более общее понятие, включающее в себя URL и URN
UR* - Uniform Resource
• I - Identifier
• L - Location
• N - Name
значит:
• URI может являться и путем до файла, и именем файла
• URL — указывает расположение файла (причем обычно в сети Интернет, кхе)
• URN — имя файла (без пути до него)
URL/URI имеют схожую структуру:
scheme://authoritypath?query# fragment
• scheme — протокол (например, http: или mailto: или tel:)
• authority — логин или хост
• path — путь до файла, разделенный косыми чертами
• query — слова-фильтры
• fragment — произвольный параметр
URI могут быть абсолютные или относительные (вести куда-то, относительно папки, в которой будут открыты)
....
чем отличаются две scheme, встречающиеся при работе с файлами в андроиде — content и file?
При работе с файлами или интернетом можно заметить, что иногда нужно указывать URL, а иногда — URI. а почему?
URI — это более общее понятие, включающее в себя URL и URN
UR* - Uniform Resource
• I - Identifier
• L - Location
• N - Name
значит:
• URI может являться и путем до файла, и именем файла
• URL — указывает расположение файла (причем обычно в сети Интернет, кхе)
• URN — имя файла (без пути до него)
URL/URI имеют схожую структуру:
scheme://authoritypath?query# fragment
• scheme — протокол (например, http: или mailto: или tel:)
• authority — логин или хост
• path — путь до файла, разделенный косыми чертами
• query — слова-фильтры
• fragment — произвольный параметр
URI могут быть абсолютные или относительные (вести куда-то, относительно папки, в которой будут открыты)
....
чем отличаются две scheme, встречающиеся при работе с файлами в андроиде — content и file?
{kind=link}
❤10🔥10👍9
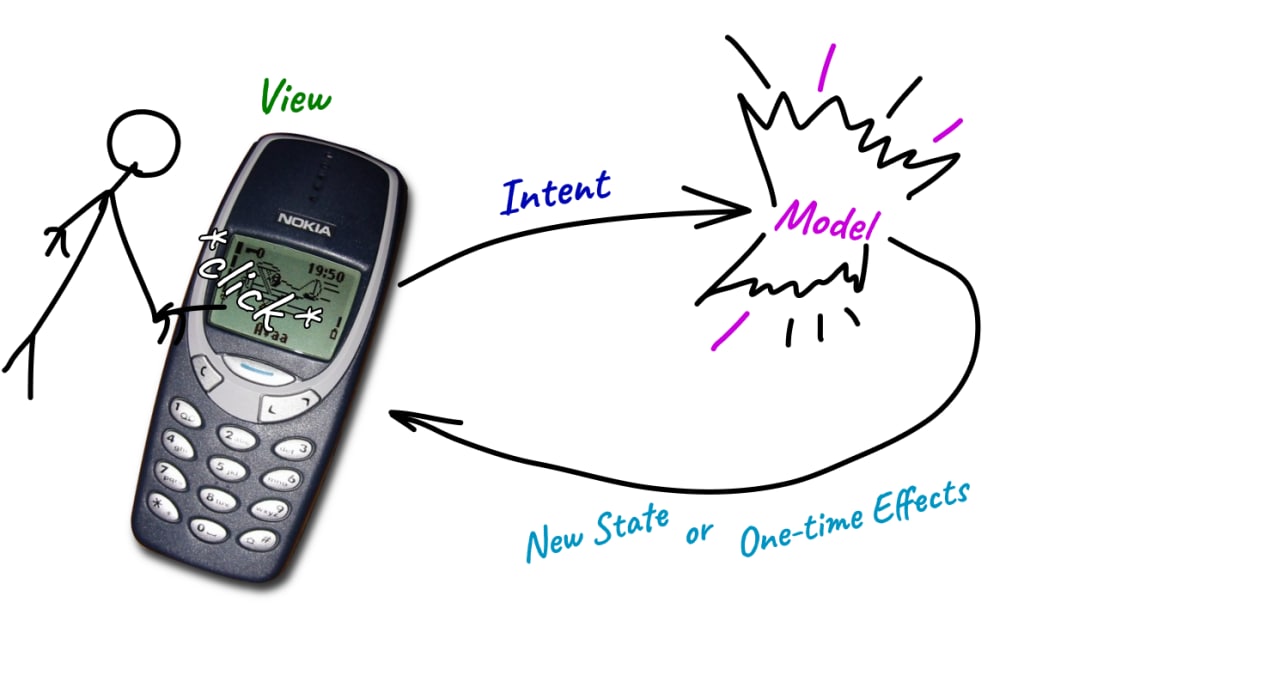
MVI — архитектура за 100 слов
Этот подход набирает все большую популярность, вытесняя MVVM
Яркий признак MVI — наличие State
State — неизменяемое состояние (объект, который называет состояние и передает все связанные с ним данные)
Например, ErrorState(val errorMessage: String)
Слои:
• Model — источник State для View
• View — принимает State и отображает
• Intent — события
Не буду вдаваться в философию, приведу пример:
когда пользователь открывает экран, Model создает State.Defult
загружает в этот State всю информацию, которую нужно отобразить, и отдает View
через некоторые время пользователь нажимает кнопку
View сообщает об новом Intent в Model
Model формирует новый State и отдает View
В целом — это все. Но мир не идеален, поэтому:
Intent можно разделить на 2 группы:
• Действия юзера
• События от бекенда (например, пришло новое сообщение)
State можно поделить на 2 группы:
• Стабильные — должны отображаться даже после переворота экрана
• Эффекты — должны отобразиться один раз (например, Toast\Snackbar)
Плюсы MVI:
• наглядность — прямой "поток" данных и событий, без макарон
• модульность — тестируемость
• заранее прописываешь стейты, так что не забываешь учесть разные состояния (обычно State.Default, State.Failed, State.Loading, State.Success)
Минусы MVI:
• часто приходится делать тяжелый моральный выбор - если на экране появляются новые вьюшка, то нужно создавать новый State или модифицировать старый?
Этот подход набирает все большую популярность, вытесняя MVVM
Яркий признак MVI — наличие State
State — неизменяемое состояние (объект, который называет состояние и передает все связанные с ним данные)
Например, ErrorState(val errorMessage: String)
Слои:
• Model — источник State для View
• View — принимает State и отображает
• Intent — события
Не буду вдаваться в философию, приведу пример:
когда пользователь открывает экран, Model создает State.Defult
загружает в этот State всю информацию, которую нужно отобразить, и отдает View
через некоторые время пользователь нажимает кнопку
View сообщает об новом Intent в Model
Model формирует новый State и отдает View
В целом — это все. Но мир не идеален, поэтому:
Intent можно разделить на 2 группы:
• Действия юзера
• События от бекенда (например, пришло новое сообщение)
State можно поделить на 2 группы:
• Стабильные — должны отображаться даже после переворота экрана
• Эффекты — должны отобразиться один раз (например, Toast\Snackbar)
Плюсы MVI:
• наглядность — прямой "поток" данных и событий, без макарон
• модульность — тестируемость
• заранее прописываешь стейты, так что не забываешь учесть разные состояния (обычно State.Default, State.Failed, State.Loading, State.Success)
Минусы MVI:
• часто приходится делать тяжелый моральный выбор - если на экране появляются новые вьюшка, то нужно создавать новый State или модифицировать старый?
{kind=link}
👍28🔥8❤2
Прошло несколько месяцев — мы праздновали первую сотню человек в нашей тусовочке — теперь масштабы серьезнее
Теперь мы поднимаем кружки кофе и пива за первую 1000 человек — торжественное ура
.....
Желаю всем классного ворк-лайф баланса, чтобы разработка приносила интересные события в жизнь и новые технологии перестали появляться каждую неделю)
А мне желаю наконец-то найти классных рекламодателей — это будет следующий большой рывок в развитии этой тусовки
🍻🤝🍻
.....
в ближайших планах:
• продолжаю равно то же самое, пытаюсь удержаться от ввода новых рубрик. еще не время)
• появится форма обратной связи, через которую можно будет влиять на темы следующих постов
Теперь мы поднимаем кружки кофе и пива за первую 1000 человек — торжественное ура
.....
Желаю всем классного ворк-лайф баланса, чтобы разработка приносила интересные события в жизнь и новые технологии перестали появляться каждую неделю)
А мне желаю наконец-то найти классных рекламодателей — это будет следующий большой рывок в развитии этой тусовки
🍻🤝🍻
.....
в ближайших планах:
• продолжаю равно то же самое, пытаюсь удержаться от ввода новых рубрик. еще не время)
• появится форма обратной связи, через которую можно будет влиять на темы следующих постов
👍15🎉7🔥5❤1🤩1🤮1
Порядок инициализации полей, конструкторов и блоков
Рассмотрим самый сложный пример — представим, что у нас есть наследование, статика, конструкторы и поля (+ companion object, + init)
Порядок инициализации в Java и Kotlin немного различны, хотя и схожи по общей идее
Java:
Статические и нестатические поля и блоки инициализируются в порядке объявления (чем выше строчка, тем первее она будет инициализирована)
1. Статические поля и блоки родителя
2. Статические поля и блоки ребенка
3. Нестатические поля и блоки родителя
4. Конструктор родителя
5. Нестатические поля и блоки ребенка
6. Конструктор ребенка
Kotlin
В котлине нет статики, нельзя написать код блока вне функции, но появляются companion object и init-функция
1. Поля внутри companion object родителя
2. Поля внутри companion object ребенка
3. Поля и блок init родителя (в порядке объявления)
4. Конструктор родителя
5. Поля и блок init ребенка (в порядке объявления)
6. Конструктор ребенка
....
когда приходится использовать статические или нестатические блоки кода в боевых проектах?
в какой момент инициализируется статическое поле, если к нему обратиться, не создавая объект класса? как это повлияет на порядок инициализации в момент создания объекта класса?
Рассмотрим самый сложный пример — представим, что у нас есть наследование, статика, конструкторы и поля (+ companion object, + init)
Порядок инициализации в Java и Kotlin немного различны, хотя и схожи по общей идее
Java:
Статические и нестатические поля и блоки инициализируются в порядке объявления (чем выше строчка, тем первее она будет инициализирована)
1. Статические поля и блоки родителя
2. Статические поля и блоки ребенка
3. Нестатические поля и блоки родителя
4. Конструктор родителя
5. Нестатические поля и блоки ребенка
6. Конструктор ребенка
Kotlin
В котлине нет статики, нельзя написать код блока вне функции, но появляются companion object и init-функция
1. Поля внутри companion object родителя
2. Поля внутри companion object ребенка
3. Поля и блок init родителя (в порядке объявления)
4. Конструктор родителя
5. Поля и блок init ребенка (в порядке объявления)
6. Конструктор ребенка
....
когда приходится использовать статические или нестатические блоки кода в боевых проектах?
в какой момент инициализируется статическое поле, если к нему обратиться, не создавая объект класса? как это повлияет на порядок инициализации в момент создания объекта класса?
{kind=link}
👍29❤3🤩1
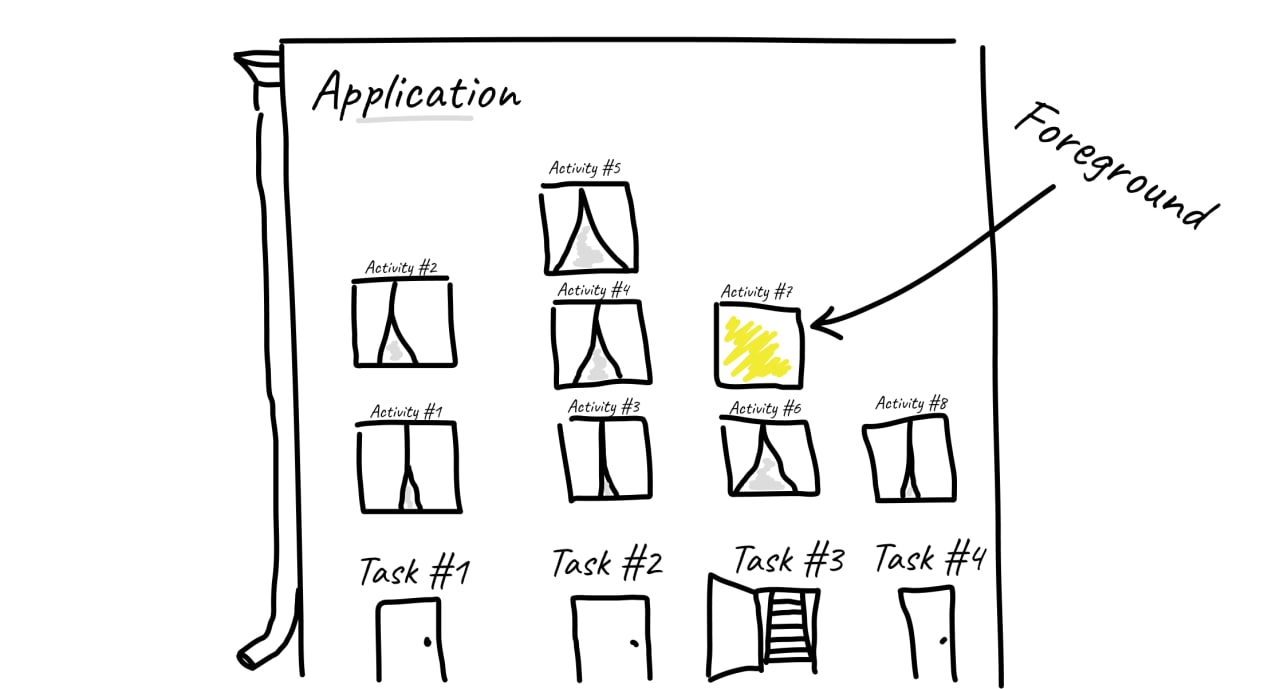
Task или виды Activity launch mode
У каждого приложения может быть несколько стеков из Activity. Под каждый стек создается новая Task
Activity launch mode — описывает сценарий изменения стека при запуске новой Activity
Например, можно открывать каждую Activity в отдельном стеке. Тогда в списке запущенных приложений (Recent screen) вы увидите, что ваше приложение открыто в нескольких окнах, каждое из которых можно закрыть отдельно
Выбрать, что произойдет после запуска новой Activity, можно с помощью тега launchMode у <activity> в Manifest. И при помощи установка флага в Intent. А еще при помощи параметра taskAffinity, allowTaskReparenting, clearTaskOnLaunch, alwaysRetainTaskState, finishOnTaskLaunch....
Все гениальное просто, да?
Но разберем основные варианты, которые покрывают 99,99% случаев:
• standart
создастся новая Activity в текущей таске. даже если ее экземпляры есть в текущей таске или в другой
• singleTop
если в текущей таске Activity находится на вершине, то новый ее инстанс создан не будет. текущий инстанс получит Intent через onNewIntent()
в противном случае создастся новый экземпляр в текущей таске
• singleTask
если уже есть таска, в которой вызываемая Activity находится в корне стека, то откроется экземпляр этой Activity, ей будет передан Intent через onNewIntent(), а все остальные Activity в этой таске будут задестроены
в противном случае создается новая таска с новым Activity
• singleInstance
аналогично singleTask. отличие - в таске, в которой находится Activity с таким флагом, может находиться только эта Activity. Под остальные Activity, запущенные из этой Activity, будут создаваться новые таски
• singleInstancePerTask
аналогично singleTask. отличие - если добавить флаг FLAG ACTIVITY MULTIPLE TASK, запуск новой Activity может вызвать создание новой таски, даже если уже есть таска с инстансом этой Activity в корне стека
• standart + FLAG ACTIVITY CLEAR TOP
если в текущей таске есть запускаемая Activity, то она получит Intent через onNewIntent(), а все Activity, запущенные после нее, будут задестроены
в противном случае будет создан новый экземпляр Activity в текущей таске
....
1. есть Activity, есть Task. а зачем тогда вводится и за что отвечает абстракция Window?
2. все вышеописанное справедливо для приложения с множеством Activity. а возможно ли добиться создания нескольких Task в single activity приложении на Fragments/Compose?
У каждого приложения может быть несколько стеков из Activity. Под каждый стек создается новая Task
Activity launch mode — описывает сценарий изменения стека при запуске новой Activity
Например, можно открывать каждую Activity в отдельном стеке. Тогда в списке запущенных приложений (Recent screen) вы увидите, что ваше приложение открыто в нескольких окнах, каждое из которых можно закрыть отдельно
Выбрать, что произойдет после запуска новой Activity, можно с помощью тега launchMode у <activity> в Manifest. И при помощи установка флага в Intent. А еще при помощи параметра taskAffinity, allowTaskReparenting, clearTaskOnLaunch, alwaysRetainTaskState, finishOnTaskLaunch....
Все гениальное просто, да?
Но разберем основные варианты, которые покрывают 99,99% случаев:
• standart
создастся новая Activity в текущей таске. даже если ее экземпляры есть в текущей таске или в другой
• singleTop
если в текущей таске Activity находится на вершине, то новый ее инстанс создан не будет. текущий инстанс получит Intent через onNewIntent()
в противном случае создастся новый экземпляр в текущей таске
• singleTask
если уже есть таска, в которой вызываемая Activity находится в корне стека, то откроется экземпляр этой Activity, ей будет передан Intent через onNewIntent(), а все остальные Activity в этой таске будут задестроены
в противном случае создается новая таска с новым Activity
• singleInstance
аналогично singleTask. отличие - в таске, в которой находится Activity с таким флагом, может находиться только эта Activity. Под остальные Activity, запущенные из этой Activity, будут создаваться новые таски
• singleInstancePerTask
аналогично singleTask. отличие - если добавить флаг FLAG ACTIVITY MULTIPLE TASK, запуск новой Activity может вызвать создание новой таски, даже если уже есть таска с инстансом этой Activity в корне стека
• standart + FLAG ACTIVITY CLEAR TOP
если в текущей таске есть запускаемая Activity, то она получит Intent через onNewIntent(), а все Activity, запущенные после нее, будут задестроены
в противном случае будет создан новый экземпляр Activity в текущей таске
....
1. есть Activity, есть Task. а зачем тогда вводится и за что отвечает абстракция Window?
2. все вышеописанное справедливо для приложения с множеством Activity. а возможно ли добиться создания нескольких Task в single activity приложении на Fragments/Compose?
{kind=link}
👍14❤2😁1🤩1
Как придумать свои единицы измерения на примере Compose
Вероятно, это начало серии постов о Compose. Начнем с малого
В Compose можно использовать привычные единицы измерения:
• 18.dp
• 18.sp
• 18.em
Но почему не приходится писать Dp(18) или Dp.Builder().get(18)?
Фокус в extensions-функциях, созданных для всех численных примитивов (Int, Float, Double)
Например:
inline val Int.dp: Dp get() = Dp(value = this.toFloat())
(если вы практикуете только Java, вам может стать плохо, это нормально)
Разберем каждую часть строчки:
• inline — слово, заставляющее компилятор на этапе компиляции упростить код за счет замены лямбда-выражения на последовательный код
если слово inline стоит перед переменной (как в текущем примере), то оно относится к функциям get() и set() переменной
• .dp: Dp — создание переменное типа Dp в классе Int (расширили класс Int новой переменной)
• get() — переопределили зарезервированную функцию get() для переменной dp
• this — ссылка на класс Int, то есть в случае 18.dp ссылка на класс Int(18)
• value — название параметра в конструкторе класса Dp (просто для наглядности)
вот так, использовав всего 5 трюков котлина в одной строчке, можно придумать собственную единицу измерения
....
в боевом проекте такую фишку можно применить для управления, например, балансом юзера — 18.rub + 20.dol = 30.eur. еще идеи?
Вероятно, это начало серии постов о Compose. Начнем с малого
В Compose можно использовать привычные единицы измерения:
• 18.dp
• 18.sp
• 18.em
Но почему не приходится писать Dp(18) или Dp.Builder().get(18)?
Фокус в extensions-функциях, созданных для всех численных примитивов (Int, Float, Double)
Например:
inline val Int.dp: Dp get() = Dp(value = this.toFloat())
(если вы практикуете только Java, вам может стать плохо, это нормально)
Разберем каждую часть строчки:
• inline — слово, заставляющее компилятор на этапе компиляции упростить код за счет замены лямбда-выражения на последовательный код
если слово inline стоит перед переменной (как в текущем примере), то оно относится к функциям get() и set() переменной
• .dp: Dp — создание переменное типа Dp в классе Int (расширили класс Int новой переменной)
• get() — переопределили зарезервированную функцию get() для переменной dp
• this — ссылка на класс Int, то есть в случае 18.dp ссылка на класс Int(18)
• value — название параметра в конструкторе класса Dp (просто для наглядности)
вот так, использовав всего 5 трюков котлина в одной строчке, можно придумать собственную единицу измерения
....
в боевом проекте такую фишку можно применить для управления, например, балансом юзера — 18.rub + 20.dol = 30.eur. еще идеи?
{kind=link}
🔥14❤5👍3😁2
Thread Safe — когда пора начать об этом думать
Понятие Thread Safe имеет множество определений, но суть у них одна:
если переменную изменяют несколько потоков, то результат изменения должен быть предсказуемый
(если b = 1, и мы дважды вызываем b++, то ожидаем увидеть b = 3 — это и есть предсказуемость)
Что может пойти не так?
Во-первых, по умолчанию потоки работают с переменной не в общей памяти, а создают свою локальную копию. А после всех манипуляций с объектом внутри потока возвращают объект в общую память
То есть другие потоки смогут увидеть изменения в объекте только после завершения этапа работы первого потока
Во-вторых, один поток может взять переменную и начать изменять ее. Например, была строка var s = "Big", а на выходе должна получится строка s = s + "Hot"
Но пока первый поток не закончил изменение s, второй поток тоже считал s. И решил сделать из нее s = s + "Dog"
Получается, что мы хотели прибавить к "Big" строки "Hot" и "Dog", а получим на выходе не "BigHotDog", а "BigHot" или "BigDog" или "BigDogHot" — результат непредсказуем
Ответ на заголовок поста:
пора начинать разбираться в многопоточности, как только в проекте появляется два и более потоков, работающих с общими переменными
....
с чего стоит начать, если хочешь понять эту вашу многопоточность вдоль и поперек?
Понятие Thread Safe имеет множество определений, но суть у них одна:
если переменную изменяют несколько потоков, то результат изменения должен быть предсказуемый
(если b = 1, и мы дважды вызываем b++, то ожидаем увидеть b = 3 — это и есть предсказуемость)
Что может пойти не так?
Во-первых, по умолчанию потоки работают с переменной не в общей памяти, а создают свою локальную копию. А после всех манипуляций с объектом внутри потока возвращают объект в общую память
То есть другие потоки смогут увидеть изменения в объекте только после завершения этапа работы первого потока
Во-вторых, один поток может взять переменную и начать изменять ее. Например, была строка var s = "Big", а на выходе должна получится строка s = s + "Hot"
Но пока первый поток не закончил изменение s, второй поток тоже считал s. И решил сделать из нее s = s + "Dog"
Получается, что мы хотели прибавить к "Big" строки "Hot" и "Dog", а получим на выходе не "BigHotDog", а "BigHot" или "BigDog" или "BigDogHot" — результат непредсказуем
Ответ на заголовок поста:
пора начинать разбираться в многопоточности, как только в проекте появляется два и более потоков, работающих с общими переменными
....
с чего стоит начать, если хочешь понять эту вашу многопоточность вдоль и поперек?
{kind=link}
👍24❤4