
Новый релиз 🤗, теперь с лонгформером
https://github.com/huggingface/transformers/releases/tag/v2.11.0
https://github.com/huggingface/transformers/releases/tag/v2.11.0
GitHub
Release Longformer · huggingface/transformers
Longformer
Longformer (@ibeltagy)
Longformer for QA (@patil-suraj + @patrickvonplaten)
Longformer fast tokenizer (@patil-suraj)
Longformer for sequence classification (@patil-suraj)
Longformer for...
Longformer (@ibeltagy)
Longformer for QA (@patil-suraj + @patrickvonplaten)
Longformer fast tokenizer (@patil-suraj)
Longformer for sequence classification (@patil-suraj)
Longformer for...
Cascaded Text Generation with Markov Transformers
Deng and Ruch [Harvard and Cornell]
arxiv.org/abs/2006.01112
Интересная статья про альтернативу Beam Search для генерации текста. Cascaded decoding можно видеть как что-то обобщающее неавторегрессионные и авторегрессионные модели. Генерация происходит в несколько шагов: в начале вы считаете скоры слов как для неавторегресионной модели (предсказываете весь перевод целеком) и отбрасываете совсем маловероятные слова. После чего для оставшихся слов вы считаете скоры для двуграм (авторегресионно внутри каждой двуграммы) и отбрасываете самые маловероятные, потом для 3-gram итд, пока не успокоитесь.
Для того, чтобы эффективно считать скоры для n-gram авторы также предлогают Markov Transformer. По сути вы просто запрещаете биграммам смотреть друг на друга. Думаю, что это можно написатть следующим образом
Результаты: сравнимо с beam search по качеству (если добавить pseudolabelling с поомщью регрессионной модели), но в 3 раза быстрее.
зарелижен код
Deng and Ruch [Harvard and Cornell]
arxiv.org/abs/2006.01112
Интересная статья про альтернативу Beam Search для генерации текста. Cascaded decoding можно видеть как что-то обобщающее неавторегрессионные и авторегрессионные модели. Генерация происходит в несколько шагов: в начале вы считаете скоры слов как для неавторегресионной модели (предсказываете весь перевод целеком) и отбрасываете совсем маловероятные слова. После чего для оставшихся слов вы считаете скоры для двуграм (авторегресионно внутри каждой двуграммы) и отбрасываете самые маловероятные, потом для 3-gram итд, пока не успокоитесь.
Для того, чтобы эффективно считать скоры для n-gram авторы также предлогают Markov Transformer. По сути вы просто запрещаете биграммам смотреть друг на друга. Думаю, что это можно написатть следующим образом
rearrange(input, "bs (n_gram n) hid -> (bs n_gram) n hid", n_gram=4) без модификаций в архитектуре.Результаты: сравнимо с beam search по качеству (если добавить pseudolabelling с поомщью регрессионной модели), но в 3 раза быстрее.
зарелижен код
GitHub
GitHub - harvardnlp/cascaded-generation: Cascaded Text Generation with Markov Transformers
Cascaded Text Generation with Markov Transformers. Contribute to harvardnlp/cascaded-generation development by creating an account on GitHub.
А теперь хочется добавить критики и высказать свою боль по поводу зарелиженного кода.
Всё больше статей используют фреймворки не как фреймворки, а как часть кода. То есть, когда вы видете
В таком формате может быть нормально проверять свои гипотезы и разрабатывать ранние версии моделей. Но релизить такой код - это как-то невежливо и некрасиво по отношению к комьюнити. Потратье пару дней после сабмита статьи на то, чтобы причесать ваш код и сделать его минимальным. Тот же fairseq можно не модифицировать, а расширять - просто дописывать свои классы в своих файлах, а потом подключать к ванильному fairseq с помощью параметра
Если вы изобрели новую модель, которая делает что-то лучше остальных - позвольте другим использовать её простым и понятным образом. Это увеличит ваш impact, а impact - это ведь одна из главных причин, почему мы вообще занимаемся исследованями.
Помните, что вы пишете код один раз, а читаете его - десятки, а может быть и сотни раз. И не только вы.
Всё больше статей используют фреймворки не как фреймворки, а как часть кода. То есть, когда вы видете
import fairseq это не тот fairseq, который можно получить по pip install, это папка fairseq в конкретно этом проекте, где изменены 3 файла. Какие именно? Смотри по коммитам. А fairseq весьма большой, так что удачи. И это становится ещё хуже - иногда так добавлен не один фреймфорк, а несколько. В результате зарелиженный код может быть и добавляет статье воспроизводимости, но reusability остаётся нулевой.В таком формате может быть нормально проверять свои гипотезы и разрабатывать ранние версии моделей. Но релизить такой код - это как-то невежливо и некрасиво по отношению к комьюнити. Потратье пару дней после сабмита статьи на то, чтобы причесать ваш код и сделать его минимальным. Тот же fairseq можно не модифицировать, а расширять - просто дописывать свои классы в своих файлах, а потом подключать к ванильному fairseq с помощью параметра
--user-dir. В результате размер вашего репозитория уменьшается в сотни раз, позволяя проще модифицировать и переиспользовать ваш код.Если вы изобрели новую модель, которая делает что-то лучше остальных - позвольте другим использовать её простым и понятным образом. Это увеличит ваш impact, а impact - это ведь одна из главных причин, почему мы вообще занимаемся исследованями.
Помните, что вы пишете код один раз, а читаете его - десятки, а может быть и сотни раз. И не только вы.
И ссылочка на тред Thomas Wolf по этой же теме.
https://twitter.com/Thom_Wolf/status/1216990543533821952
https://twitter.com/Thom_Wolf/status/1216990543533821952
Twitter
Thomas Wolf
I often meet research scientists interested in open-sourcing their code/research and asking for advice. Here is a thread for you. First: why should you open-source models along with your paper? Because science is a virtuous circle of knowledge sharing not…
When Can Self-Attention Be Replaced by Feed Forward Layers?
Zhang et al. [University of Edinburgh]
arxiv.org/abs/2005.13895
Авторы тестировались на задачке speech-to-text, так что результат не факт, что обобщается на тексты, но по их наблюденям, можно просто выкинуть attention из последних 1-2 слоёв и не только прибавить в скорости, но и получить небольшой буст в метриках. В качестве бейзлайна сравнились с уменьшение количества слоёв.
Моей первой мыслью было попробовать запустить машинный перевод и посмотреть, как оно зайдёт. Но если внимательнее посмотреть на результаты статьи, они не такие убедительные. Ошибка падает с 9 до 8.9 на одном датасете и 3.5 до 3.4 на другом. Плюс, недавно я узнал, что BERT (по крайней мере 🤗) при обучении (MLM) использует не просто Linear для предсказания слов, a Linear->activation->LayerNorm->Linear. Так что в некотором смысле результаты этой статьи уже известны.
Zhang et al. [University of Edinburgh]
arxiv.org/abs/2005.13895
Авторы тестировались на задачке speech-to-text, так что результат не факт, что обобщается на тексты, но по их наблюденям, можно просто выкинуть attention из последних 1-2 слоёв и не только прибавить в скорости, но и получить небольшой буст в метриках. В качестве бейзлайна сравнились с уменьшение количества слоёв.
Моей первой мыслью было попробовать запустить машинный перевод и посмотреть, как оно зайдёт. Но если внимательнее посмотреть на результаты статьи, они не такие убедительные. Ошибка падает с 9 до 8.9 на одном датасете и 3.5 до 3.4 на другом. Плюс, недавно я узнал, что BERT (по крайней мере 🤗) при обучении (MLM) использует не просто Linear для предсказания слов, a Linear->activation->LayerNorm->Linear. Так что в некотором смысле результаты этой статьи уже известны.
Моделька, которая переводит ваш код с одного языка программирования на другой (C++ <=> Java <=> Python). Без параллельной разметки для обучения. Использовали те же самые алгоритмы, которые применяются для unsupervised перевода в человеческих языках и они неплохо работают.
Забавно как сделали тестсет - набрали примеры алгоритмов на geeksforgeeks, там есть примеры имплементаций на разных языках.
подробнее в треде
twitter.com/GuillaumeLample/status/1269982022413570048
Забавно как сделали тестсет - набрали примеры алгоритмов на geeksforgeeks, там есть примеры имплементаций на разных языках.
подробнее в треде
twitter.com/GuillaumeLample/status/1269982022413570048
Twitter
Guillaume Lample
Unsupervised Translation of Programming Languages. Feed a model with Python, C++, and Java source code from GitHub, and it automatically learns to translate between the 3 languages in a fully unsupervised way. https://t.co/FpUL886KS7 with @MaLachaux @b_roziere…
Forwarded from Ridvan
Сдую пыль со старого поста про неумение в гит в ДС.
Пожалуй лучшее что видел на этот счет это видео Глеба Михайлова https://www.youtube.com/watch?v=0cGIiA0AjNw&t=1s
Совершенно годный контент, на мой взгляд, да еще и на русском
Пожалуй лучшее что видел на этот счет это видео Глеба Михайлова https://www.youtube.com/watch?v=0cGIiA0AjNw&t=1s
Совершенно годный контент, на мой взгляд, да еще и на русском
YouTube
GIT для Дата Саентиста
Мой курс по SQL: https://glebmikhaylov.com/sql
------------------------------------------------------
Посмотри видос и впиши git в свою жизнь. И в резюме).
ПОДДЕРЖАТЬ СОЗДАНИЕ ВИДОСОВ: https://www.glebmikhaylov.com/donate
0:07 Зачем учить git?
1:13 Интуитивное…
------------------------------------------------------
Посмотри видос и впиши git в свою жизнь. И в резюме).
ПОДДЕРЖАТЬ СОЗДАНИЕ ВИДОСОВ: https://www.glebmikhaylov.com/donate
0:07 Зачем учить git?
1:13 Интуитивное…
Forwarded from Data Science by ODS.ai 🦜
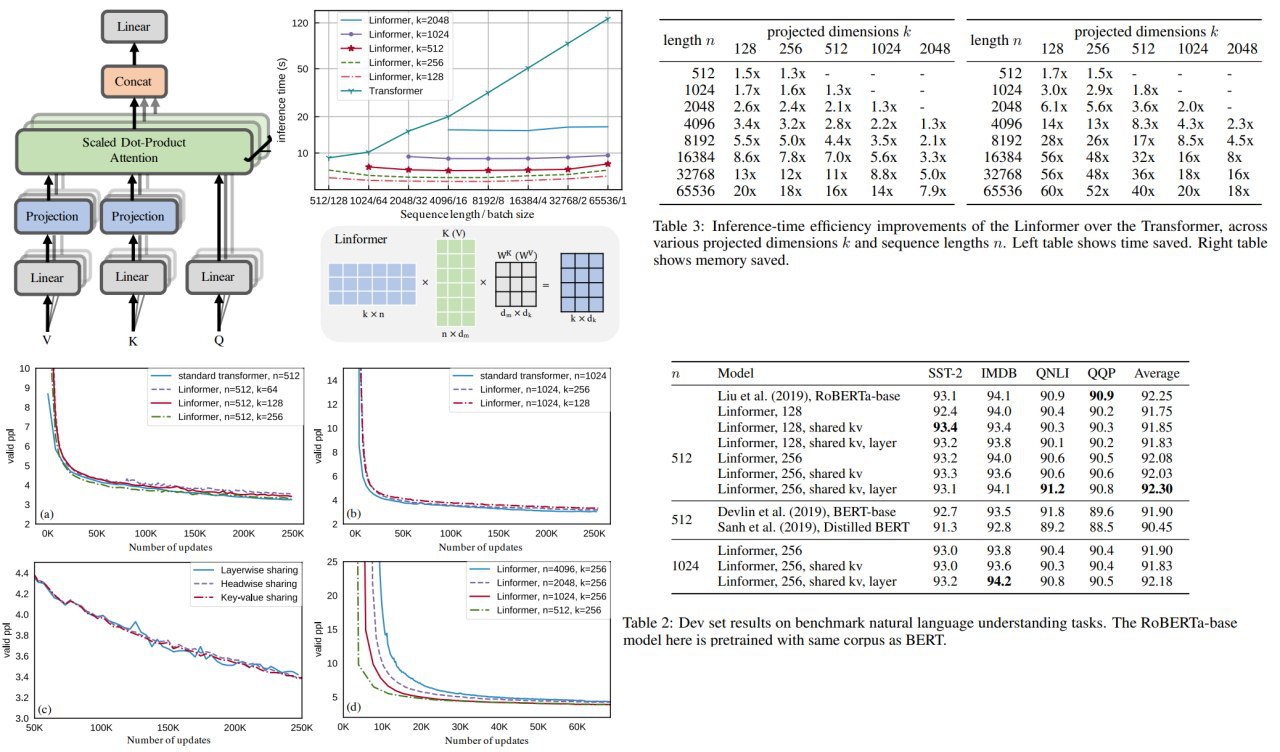
Linformer: Self-Attention with Linear Complexity
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
For experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
O(N^2) to O(N) in both time and space.Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
n and stride kFor experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
{kind=link}
Forwarded from Tatiana Shavrina
Вышел Russian SuperGLUE!
Лидерборд : https://russiansuperglue.com
Код: https://github.com/RussianNLP/RussianSuperGLUE
Чтобы правильно оценивать русскоязычные языковые модели, такие как популярные сейчас BERT, RoBERTa, XLNet и т.д., нужно иметь какие-то объективные метрики. Подходов, как это делать, не так много, а для русского языка их не было. Представлен Russian SuperGLUE - бенчмарк для задачи общего понимания языка (General Language Understanding) и дальнейшего развития моделей на русском.
Набор новых задач для оценки моделей:
1. LiDiRus (Linguistic Diagnostic for Russian) или просто общая диагностика — её мы полностью адаптировали с английского варианта.
2. DaNetQA — набор вопросов на здравый смысл и знание, с да-нет ответом.
3. RCB (Russian Commitment Bank) — классификация наличия причинно-следственных связей между текстом и гипотезой из него.
4. PARus (Plausible Alternatives for Russian) — целеполагание, выбор из альтернативных вариантов на основе здравого смысла.
5. MuSeRC (Multi-Sentence Reading Comprehension) — машинное чтение. Задания содержат текст и вопрос к нему, но такой, на который можно ответить, сделав вывод из текста.
6. RuCoS (Russian reading comprehension with Commonsense) — тоже задача на машинное чтение. Модели даётся новостной текст, а также его краткое содержание с пропуском — пропуск нужно восстановить, выбрав из вариантов.
7. TERRa (Textual Entailment Recognition for Russian) — классификация причинно-следственных связей между предложениями (собрали с нуля по новостям и худлиту).
8. RUSSE (Russian Semantic Evaluation) — задача распознавания смысла слова в контексте (word sense disambiguation). Взят из RUSSE
9. RWSD (Russian Winograd Schema Dataset) — задания на логику, с добавленными неоднозначностями («Если бы у Ивана был осёл, он бы его бил»). Создан по аналогии с Winograd Schema.
Разработчики и энтузиасты приглашаются представить свои модели на лидерборде!
Пост на habr https://habr.com/ru/company/sberbank/blog/506058/