
Прямо сейчас идёт T0 Discussion with Victor Sanh
Общаются на тему Т0, который мы разбирали пару недель назад, с одним из главных авторов.
Общаются на тему Т0, который мы разбирали пару недель назад, с одним из главных авторов.
YouTube
T0 Discussion with Victor Sanh
Forwarded from DNative — блог Ткачука про SMM
— Почти все рекламинуемые каналы созданы 21-22 октября, либо конец октября
— Все на «очень широкие и популярные темы»
— Все а-ля паблики, без авторов
— Все выглядят одинаково и созданы под копирку
Возможно это какая-то новая будущая огромная медиа-сеть пабликов, на которую выделили большой рекламный бюджет.
Ожидание от рекламы в TG: большие бренды, адекватные рекламные кампании, креатив
Реальность рекламы в TG: паблики гонят себе трафик с топовых каналов за копейки.
Павел, браво! Запуск прошёл прекрасно.
Простое сравнение.
Когда Instagram запускал первые рекламные кампании, Кевин Систром (основатель Instagram) ЛИЧНО отсматривал рекламные объявления, давал по ним правки и не пропускал то, что по его мнению не отражало ценности Instagram.
— Все на «очень широкие и популярные темы»
— Все а-ля паблики, без авторов
— Все выглядят одинаково и созданы под копирку
Возможно это какая-то новая будущая огромная медиа-сеть пабликов, на которую выделили большой рекламный бюджет.
Ожидание от рекламы в TG: большие бренды, адекватные рекламные кампании, креатив
Реальность рекламы в TG: паблики гонят себе трафик с топовых каналов за копейки.
Павел, браво! Запуск прошёл прекрасно.
Простое сравнение.
Когда Instagram запускал первые рекламные кампании, Кевин Систром (основатель Instagram) ЛИЧНО отсматривал рекламные объявления, давал по ним правки и не пропускал то, что по его мнению не отражало ценности Instagram.
MLSpace
github.com/abhishekkrthakur/mlspace
Интересный заход на работу с окружениями от Abhishek Thakur, специфичный для ML. Устанавливает за вас Nvidia driver, CUDA и CUDNN нужных версий, ставит дефолтные вещи типа torch и jupyter. Под капотом этой штуки докер, но интерфейс больше похож на conda.
На данный момент это наверное даже не альфа версия, а просто идея. Я пока что не рекомендую использовать MLSpace, но советую обратить внимание. Сейчас документация частично отсутствует, единственный backend это torch с GPU, код выглядит очень сыро, работает только под Ubuntu.
Мне нравится идея, очень уж много часов своей жизни я убил на установку/переустановку Nvidia-штук.
github.com/abhishekkrthakur/mlspace
Интересный заход на работу с окружениями от Abhishek Thakur, специфичный для ML. Устанавливает за вас Nvidia driver, CUDA и CUDNN нужных версий, ставит дефолтные вещи типа torch и jupyter. Под капотом этой штуки докер, но интерфейс больше похож на conda.
На данный момент это наверное даже не альфа версия, а просто идея. Я пока что не рекомендую использовать MLSpace, но советую обратить внимание. Сейчас документация частично отсутствует, единственный backend это torch с GPU, код выглядит очень сыро, работает только под Ubuntu.
Мне нравится идея, очень уж много часов своей жизни я убил на установку/переустановку Nvidia-штук.
GitHub
GitHub - abhishekkrthakur/mlspace: MLSpace: Hassle-free machine learning & deep learning development
MLSpace: Hassle-free machine learning & deep learning development - GitHub - abhishekkrthakur/mlspace: MLSpace: Hassle-free machine learning & deep learning development
Large Language Models Can Be Strong Differentially Private Learners
Li et al. [Stanford]
arxiv.org/abs/2110.05679
Есть такая вещь как differential privacy. Это математическое понятие приватности, которое очень грубо можно описать как "убирание или добавление одного примера в датасет не изменяет финальную модель". То есть, например, по модели, вы не можете понять, использовались ли для её обучения данные определённого человека.
Большинство моделей с которыми мы работаем сейчас не являются дифференциально приватными, вплоть до того, что иногда можно заставить модель выдавать куски тренировочного сета дословно. Но тематика приватности становится всё более горячей и всё больше людей работают над ней. Например, существует алгоритм опримизации Differentially Private SGD (DP-SGD). Идея состоит в том, чтобы ограничить влияние каждого примера из датасета через ограничение максимальго градиента, который мы можем куммулятвно получить от них за время обучения. Плюсом к этому ещё в градиенты добавляется определённое количество шума.
Проблема с DP-SGD в том, что для больших моделей обычно он работает сильно хуже обычного SGD. Для решения этой проблемы используют кучу хаков. И вот теперь мы наконец доходим до идеи этой статьи: оказывается если вы правильно подобрали гиперпараметры DP-SGD, то большие модели не только тренируются хорошо, но и позволяют получать более высокое качество (при том же уровне приватности), чем модели поменьше. Экспериментировали с GLUE, E2E и DART.
Вообще в DL на удивление часто видишь, как хорошие гиперпараметры со старыми методами работают на уровне или даже лучше, чем новые более сложные методы.
Li et al. [Stanford]
arxiv.org/abs/2110.05679
Есть такая вещь как differential privacy. Это математическое понятие приватности, которое очень грубо можно описать как "убирание или добавление одного примера в датасет не изменяет финальную модель". То есть, например, по модели, вы не можете понять, использовались ли для её обучения данные определённого человека.
Большинство моделей с которыми мы работаем сейчас не являются дифференциально приватными, вплоть до того, что иногда можно заставить модель выдавать куски тренировочного сета дословно. Но тематика приватности становится всё более горячей и всё больше людей работают над ней. Например, существует алгоритм опримизации Differentially Private SGD (DP-SGD). Идея состоит в том, чтобы ограничить влияние каждого примера из датасета через ограничение максимальго градиента, который мы можем куммулятвно получить от них за время обучения. Плюсом к этому ещё в градиенты добавляется определённое количество шума.
Проблема с DP-SGD в том, что для больших моделей обычно он работает сильно хуже обычного SGD. Для решения этой проблемы используют кучу хаков. И вот теперь мы наконец доходим до идеи этой статьи: оказывается если вы правильно подобрали гиперпараметры DP-SGD, то большие модели не только тренируются хорошо, но и позволяют получать более высокое качество (при том же уровне приватности), чем модели поменьше. Экспериментировали с GLUE, E2E и DART.
Вообще в DL на удивление часто видишь, как хорошие гиперпараметры со старыми методами работают на уровне или даже лучше, чем новые более сложные методы.
{kind=link}
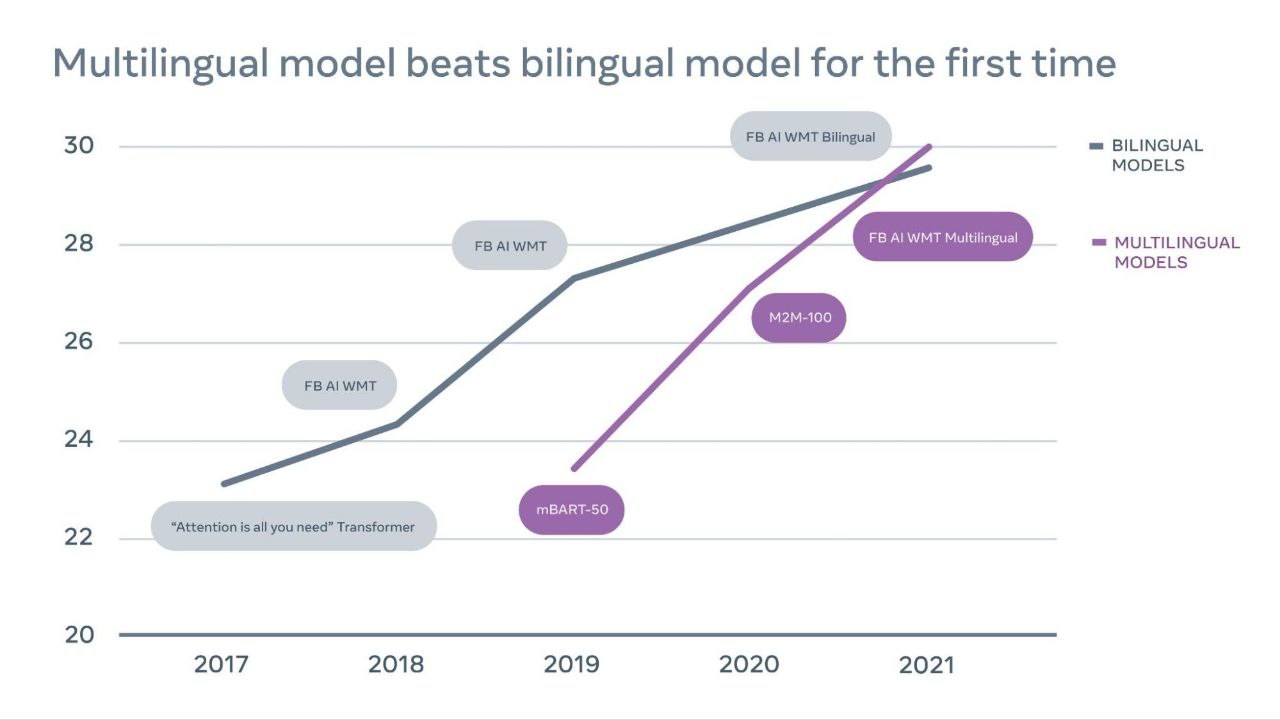
Мультиязычная модель машинного перевода от FAIR превзошла двуязычные модели на соревновании WMT-21.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
{kind=link}
Иногда видишь статью и в голове примерно такие мысли "Все кому не лень пробовали это 5 лет назад, почему сейчас заработало? Может быть у них какой-то умный лосс? Нет. Они просто воткнули туда трансформер и оно заработало? Да."
DL странный, DL рисёч ещё более странный
DL странный, DL рисёч ещё более странный
Forwarded from AI для Всех
Masked Autoencoders Are Scalable Vision Learners
Ещё одна идея, которая казалось бы была на поверхности, and yet… Берём картиночный автоэнкодер, делим картинку на патчи, прячем их в случайном порядке, и просим декодер восстановить изображение (в режиме self-supervised).
Авторы (Facebook/Meta AI), обнаружили, что скрытие большой части входного изображения, например, 75%, дает нетривиальную и осмысленную задачу для self-supervised обучения. Оказалось, что в такой формулировке, автоэнкодер обучается в ~3 раза быстрее (чем если бы мы учили на изображениях без масок).
Более того, оказалось, что если к такому обученному автоэнкодеру прикрутить голову на классификацию (например), то она будет показывать SOTA результаты. Так же, авторы показывают, что при масштабировании датасета, результаты только улучшаются.
📎 Статья
#selfSupervised #autoencoders #images
Ещё одна идея, которая казалось бы была на поверхности, and yet… Берём картиночный автоэнкодер, делим картинку на патчи, прячем их в случайном порядке, и просим декодер восстановить изображение (в режиме self-supervised).
Авторы (Facebook/Meta AI), обнаружили, что скрытие большой части входного изображения, например, 75%, дает нетривиальную и осмысленную задачу для self-supervised обучения. Оказалось, что в такой формулировке, автоэнкодер обучается в ~3 раза быстрее (чем если бы мы учили на изображениях без масок).
Более того, оказалось, что если к такому обученному автоэнкодеру прикрутить голову на классификацию (например), то она будет показывать SOTA результаты. Так же, авторы показывают, что при масштабировании датасета, результаты только улучшаются.
📎 Статья
#selfSupervised #autoencoders #images
A Survey of Document Understanding Models
pragmatic.ml/a-survey-of-document-understanding-models
Сегодня как-то случайно наткнулся на Pragmatic.ml и вспомнил насколько мне нравится этот блог своей... прагрматичностью 🥁. Так вот последний блогпост обозревает свежие модельки для анализа целых документов. У меня довольно много знакомых, которые заниаются подобными задачами, тема кажется очень интересной и прикладной.
Блогпост сам по себе уже сжат, поэтому рекомендую прочитать его полностю, но основные интересные для меня моменты такие:
1. Много кто не выкладывает веса моделей. Это немного грустно, но ожидаемо, тк очень прикладной домен, плюс тут происходит комбинация моделек, как минимум с OCR, что усложняет шеринг кода.
1. Всё ещё много архитектурной работы, но видно много упрощения. Кажется волна "просто бери большой трансформер и учи его как языковую модель" почти дошла до этой области. Думаю в следующем году будет совсем жесть, когда есть A100 с 80Гб памяти.
1. ROI для визуальных фич 🤮, столько вьетнамских флешбеков с этого. Но часть моделек переходит к более простым фичам
pragmatic.ml/a-survey-of-document-understanding-models
Сегодня как-то случайно наткнулся на Pragmatic.ml и вспомнил насколько мне нравится этот блог своей... прагрматичностью 🥁. Так вот последний блогпост обозревает свежие модельки для анализа целых документов. У меня довольно много знакомых, которые заниаются подобными задачами, тема кажется очень интересной и прикладной.
Блогпост сам по себе уже сжат, поэтому рекомендую прочитать его полностю, но основные интересные для меня моменты такие:
1. Много кто не выкладывает веса моделей. Это немного грустно, но ожидаемо, тк очень прикладной домен, плюс тут происходит комбинация моделек, как минимум с OCR, что усложняет шеринг кода.
1. Всё ещё много архитектурной работы, но видно много упрощения. Кажется волна "просто бери большой трансформер и учи его как языковую модель" почти дошла до этой области. Думаю в следующем году будет совсем жесть, когда есть A100 с 80Гб памяти.
1. ROI для визуальных фич 🤮, столько вьетнамских флешбеков с этого. Но часть моделек переходит к более простым фичам
machine learning musings
Suvery: Document Understanding Models
The past three years have seen significant interest in applying language models to the task of visual document understanding – integrating spatial, textual, and visual signals to make sense of PDFs and scanned documents.
👍1
⚡️OpenAI’s API Now Available with No Waitlist
Наконец-то OpenAI открыли публичный доступ к GPT-3. За время закрытого теста к нему добавили небольшие улучшения, такие как Instruct series models, которые лучше реагируют на промты. Кроме этого добавили в документацию safety best practices, которые рассказывают как сделать такую систему, которую нельзя будет атаковать очевидными способами.
Цена пока что кажется неплохой, по крайней мере ниже чем я ожидал. Самая большая модель стоит 6 центов за тысячу токенов. После регистрации вам дают $18, чего хватит для генерации 300 тысяч токенов.
Заходите на openai.com/api, регистрируйтесь и играйтесь с GPT-3 (Codex пока только по инвайтам). Пишите что получается в чат, будет интересно узнать какие у людей в среднем впечатления.
Наконец-то OpenAI открыли публичный доступ к GPT-3. За время закрытого теста к нему добавили небольшие улучшения, такие как Instruct series models, которые лучше реагируют на промты. Кроме этого добавили в документацию safety best practices, которые рассказывают как сделать такую систему, которую нельзя будет атаковать очевидными способами.
Цена пока что кажется неплохой, по крайней мере ниже чем я ожидал. Самая большая модель стоит 6 центов за тысячу токенов. После регистрации вам дают $18, чего хватит для генерации 300 тысяч токенов.
Заходите на openai.com/api, регистрируйтесь и играйтесь с GPT-3 (Codex пока только по инвайтам). Пишите что получается в чат, будет интересно узнать какие у людей в среднем впечатления.
Openai
API Platform
Our API platform offers our latest models and guides for safety best practices.
Forwarded from Derp Learning
Тут товарищ Nikita Kiselov потестил Apple М1 в tensorflow.
tl;dr:
M1 Pro в два раза быстрее Tesla K80 (colab free), и в два раза медленнее Tesla P100 (colab pro)
M1 Max где-то быстрее P100, где-то на ее уровне.
Лонгрид тут
tl;dr:
M1 Pro в два раза быстрее Tesla K80 (colab free), и в два раза медленнее Tesla P100 (colab pro)
M1 Max где-то быстрее P100, где-то на ее уровне.
Лонгрид тут
Hidden Technical Debt in Machine Learning Systems
Sculley et al., [Google], 2015
Несмотря на возраст, статья точно описывает кучу проблем в современных системах. В отличие от обычного софта, когда технический долг весь сидит в коде или документации, в ML есть много альтернативных способов накосячить. Вот некоторые примеры, которые авторы разбирают в статье на основе своего опыта в Google:
1. Старые гиперпараметры, которые непонятно откуда взялись, и не меняются уже N лет, несмотря на то, что и данные и модель уже сильно другие
1. Частный случай предыдущего пункта — трешхолды, которые были потюнены лишь один раз во время первичного деплоя. Это может быть особенно опасно, если ваша система принимает важные для бизнеса или безопасности окружающих решения.
1. Feedback loops — данные для тренировки модели, которые вы коллектите с задеплоеной системы, зависят от модели. Про это нужно помнить и адресовать заранее.
1. Высокоуровневые абстракции над моделями, которые заставляют писать кучу glue code (бывает так что > 90% всего вашего кода это glue code)
1. Рipeline jungles, когда никто не понимает data flow и коммуникация между кусками системы превращается в макароны
1. Предыдущие два пункта зачастую появляются из-за того, что код модели написан рисечерами и его абстракции не подходят для реального мира. Чаще всего лучший способ этого избежать — переписать код модели с нуля.
1. Ещё одно следствие — куча экспериментального кода внутри задеплоеного кода
1. Под конец касаются интересной вещи, которую называют cultural debt. Хорошие ML команды состоят из смеси исследователей и инжереров, которые активно взаимодействуют друг с другом, готовы выкидывать старые куски кода для упрощения системы, обращать столько же внимания на стабильность и мониторинг системы, сколько и на accuracy. Если в команде нету такой культуры, она может быть склонна быстро аккумулировать и преувеличивать существующий техдолг.
Советую почитать оригинальную статью. В ней очень много полезной информации, которую не сжать в пост в телеге.
Sculley et al., [Google], 2015
Несмотря на возраст, статья точно описывает кучу проблем в современных системах. В отличие от обычного софта, когда технический долг весь сидит в коде или документации, в ML есть много альтернативных способов накосячить. Вот некоторые примеры, которые авторы разбирают в статье на основе своего опыта в Google:
1. Старые гиперпараметры, которые непонятно откуда взялись, и не меняются уже N лет, несмотря на то, что и данные и модель уже сильно другие
1. Частный случай предыдущего пункта — трешхолды, которые были потюнены лишь один раз во время первичного деплоя. Это может быть особенно опасно, если ваша система принимает важные для бизнеса или безопасности окружающих решения.
1. Feedback loops — данные для тренировки модели, которые вы коллектите с задеплоеной системы, зависят от модели. Про это нужно помнить и адресовать заранее.
1. Высокоуровневые абстракции над моделями, которые заставляют писать кучу glue code (бывает так что > 90% всего вашего кода это glue code)
1. Рipeline jungles, когда никто не понимает data flow и коммуникация между кусками системы превращается в макароны
1. Предыдущие два пункта зачастую появляются из-за того, что код модели написан рисечерами и его абстракции не подходят для реального мира. Чаще всего лучший способ этого избежать — переписать код модели с нуля.
1. Ещё одно следствие — куча экспериментального кода внутри задеплоеного кода
1. Под конец касаются интересной вещи, которую называют cultural debt. Хорошие ML команды состоят из смеси исследователей и инжереров, которые активно взаимодействуют друг с другом, готовы выкидывать старые куски кода для упрощения системы, обращать столько же внимания на стабильность и мониторинг системы, сколько и на accuracy. Если в команде нету такой культуры, она может быть склонна быстро аккумулировать и преувеличивать существующий техдолг.
Советую почитать оригинальную статью. В ней очень много полезной информации, которую не сжать в пост в телеге.
{kind=link}
👍1
What is Automatic Differentiation?
youtube.com/watch?v=wG_nF1awSSY
Наверное самая хитрая и непонятная тема для тех, кто только погружается в DL — это бэкпроп. Для меня в своё время совершенно знаковой была задачка написания бэкпропа для BatchNorm на нумпае (кстати рекомендую). Но если вместо жёсткого погружения в код вы хотите посмотреть хороший видос по автоматическому дифференцированию, который лежит в основе бэкпропа, я очень рекомендую вот этот видос. В нём рассказывают об отличии численного дифференцирования от аналитического от автоматического. В том числе рассказывают про разницу между forward-mode и backward-mode дифференцированием. А также как их можно комбинировать для эффективного рассчёта hessian-vector product, который вам например нужен в MAML. В общем рекомендую к просмотру.
youtube.com/watch?v=wG_nF1awSSY
Наверное самая хитрая и непонятная тема для тех, кто только погружается в DL — это бэкпроп. Для меня в своё время совершенно знаковой была задачка написания бэкпропа для BatchNorm на нумпае (кстати рекомендую). Но если вместо жёсткого погружения в код вы хотите посмотреть хороший видос по автоматическому дифференцированию, который лежит в основе бэкпропа, я очень рекомендую вот этот видос. В нём рассказывают об отличии численного дифференцирования от аналитического от автоматического. В том числе рассказывают про разницу между forward-mode и backward-mode дифференцированием. А также как их можно комбинировать для эффективного рассчёта hessian-vector product, который вам например нужен в MAML. В общем рекомендую к просмотру.
YouTube
What is Automatic Differentiation?
This short tutorial covers the basics of automatic differentiation, a set of techniques that allow us to efficiently compute derivatives of functions implemented as programs. It is based in part on Baydin et al., 2018: Automatic Differentiation in Machine…
Forwarded from AbstractDL
This media is not supported in your browser
VIEW IN TELEGRAM
GradInit: перебор гиперпараметров оптимизатора и warmup больше не нужны (by Google)
В гугл предложили супер крутой универсальный architecture-agnostic метод инициализации весов моделей.
Идея очень простая: добавить множители перед каждым блоком параметров и запустить по ним несколько итераций оптимизации лосса. Дальше эти множители фиксируем и учим модель как обычно. Такая инициализация не зависит от глубины и типа архитектуры (работает и на резнетах и на трансформерах) и почти полностью решает проблему взрывающихся\затухающих градиентов.
В итоге отпадает необходимость в переборе гиперпараметров оптимизатора, а трансформер вообще получилось обучить без warmup’a, что считалось практически невозможным. Как бонус, такая инициализация даёт небольшой буст на многих бенчмарках (и картиночных и текстовых).
Статья, GitHub
В гугл предложили супер крутой универсальный architecture-agnostic метод инициализации весов моделей.
Идея очень простая: добавить множители перед каждым блоком параметров и запустить по ним несколько итераций оптимизации лосса. Дальше эти множители фиксируем и учим модель как обычно. Такая инициализация не зависит от глубины и типа архитектуры (работает и на резнетах и на трансформерах) и почти полностью решает проблему взрывающихся\затухающих градиентов.
В итоге отпадает необходимость в переборе гиперпараметров оптимизатора, а трансформер вообще получилось обучить без warmup’a, что считалось практически невозможным. Как бонус, такая инициализация даёт небольшой буст на многих бенчмарках (и картиночных и текстовых).
Статья, GitHub
Заметил такой параграф в статье и подумал что он может сильно удивить людей вне NLP / DL (и даже некоторых людей оттуда). С одной стороны он показыает насколько сильно требования на compute выросли за последние пару лет, а с другой — сколько бы экспериментов у тебя не было, #reviewer2 всё равно скажет что их недостаточно и вообще lack of baselines.
Кстати это параграф из статьи The Untapped Potential of Ranking in Natural Language Processing, которая предлагает использовать попарное ранжирование вместо классификации, что позволяет заметно улучшить метрики на датасетах по сентимент-анализу.
Кстати это параграф из статьи The Untapped Potential of Ranking in Natural Language Processing, которая предлагает использовать попарное ранжирование вместо классификации, что позволяет заметно улучшить метрики на датасетах по сентимент-анализу.
👍1
DeepMind натренировал языковую модель почти в два раза больше GPT-3. Естественно сразу получили кучу SOTA, но кажется что это не очень интересно. Вместе с этим выпустили три статьи: 1) технический репорт по тренировке больших моделей, 2) retreival-enhanced transformer (RETRO) и 3) статью о рисках связанных с большими языковыми моделями
В блогпосте рассказывают о том, что размер модели не очень помогает в задачах связанных с логическим выводом (reasoning) и common sence. Второе звучит странно (читать: интересно), тк интуитивно кажется что языковые модели помогают нам решать задачи более хорошо именно из-за выученного common sense.
Надо будет прочитать статьи и посмотреть, что ещё есть интересного в них. На этой неделе вообще много всего происходит, тк NeurIPS. Прямо сейчас идёт воркшоп BigScience, рекомендую подключаться (но нужно быть зарегистрированным).
За новость про DeepMind спасибо @addmeto
В блогпосте рассказывают о том, что размер модели не очень помогает в задачах связанных с логическим выводом (reasoning) и common sence. Второе звучит странно (читать: интересно), тк интуитивно кажется что языковые модели помогают нам решать задачи более хорошо именно из-за выученного common sense.
Надо будет прочитать статьи и посмотреть, что ещё есть интересного в них. На этой неделе вообще много всего происходит, тк NeurIPS. Прямо сейчас идёт воркшоп BigScience, рекомендую подключаться (но нужно быть зарегистрированным).
За новость про DeepMind спасибо @addmeto