
И несколько примеров работы модели. Я был скептичен, но T0pp показала себя на удивление хорошо.
UPD: извиняюсь за такое количество уведомлений одновременно, не ожидал что все скриншоты пошлются как разные сообщения
UPD: извиняюсь за такое количество уведомлений одновременно, не ожидал что все скриншоты пошлются как разные сообщения
Тут подъехала довольно неприятная, но ожидаемая новость — Телеграм начинает показывать рекламу в каналах с более чем 1000 человек. Авторы каналов не могут выключить показ этой рекламы или повлиять на её содержание какими-то понятными образами. Говорят что реклама будет ориентироваться на тематику каналов, но посмотрим насколько хорошей будет имплементация.
Мне очень не нравится что в этом канале будет появляться контент, который я не контролирую. Отличить эти посты от моих можно будет по маленькой плашке "sponsored" в правом нижнем углу.
Мне очень не нравится что в этом канале будет появляться контент, который я не контролирую. Отличить эти посты от моих можно будет по маленькой плашке "sponsored" в правом нижнем углу.
Meduza
Павел Дуров заявил о запуске официальной рекламы в Telegram
Скоро в телеграм-каналах появятся рекламные сообщения, которые будет размещать администрация мессенджера. Об этом рассказал создатель Telegram Павел Дуров.
DeepLearning.ai выпустили новый курс в Natural Language Processing Specialization, рассказывающий про трансформеры (да, каким-то обраозм трансформеров там до сих пор не было).
Я проглядел его по диагонали и курс выглядит довольно неплохо. Есть домашки по машинному переводу, суммаризации, QA и чатботам. На последней неделе даже проходят reformer (длинный трансформер работающий через LSH-attention). Если кто-то решит пройти, буду рад если поделитесь своими впечатленями в чате.
UPD: Галя, отмена! В чате обратили внимание, что в отзывах говорят что курс поверностный и в нём недостаточно матана, чтобы понять как работают трансформеры.
Я проглядел его по диагонали и курс выглядит довольно неплохо. Есть домашки по машинному переводу, суммаризации, QA и чатботам. На последней неделе даже проходят reformer (длинный трансформер работающий через LSH-attention). Если кто-то решит пройти, буду рад если поделитесь своими впечатленями в чате.
UPD: Галя, отмена! В чате обратили внимание, что в отзывах говорят что курс поверностный и в нём недостаточно матана, чтобы понять как работают трансформеры.
Coursera
Natural Language Processing with Attention Models
Offered by DeepLearning.AI. In Course 4 of the Natural ... Enroll for free.
Forwarded from Мишин Лернинг 🇺🇦🇮🇱
This media is not supported in your browser
VIEW IN TELEGRAM
🤖🐶 Boston Dynamics сделали робото-cover на клип The Rolling Stones в честь 40-летия выхода альбома Tattoo You 🔊
Fast Model Editing at Scale
Mitchell et al., [Stanford]
Представьте себе, что вы ClosedAI, большая суперкорпорация по тренировке языковых моделей. Вы скачиваете весь интернет и тренируете ваш GPT-42, тратя миллиарды долларов на электричество. После чего вы спрашиваете у модели "Who is the prime minister of the UK?" и она отвечает вам "Theresa May". Это грустный, но релеалистичный сценарий.
Менять какие-то факты в классических knowledge graphs легко — меняете ссылку с сущности UK prime minister на другого человека. Но в нейросетках это нетривиальная задача. Если вы просто зафайнтюните модель на одном примере, модель просто переобучится и например всё ещё будет отвечать "Theresa May" на вопрос "Who is the UK PM?". Ещё модель может изменить свои ответы на вопросы, которые вообще с этим не связаны.
Исследователи из Стенфорда предлагают натренировать нейросеть, которая будет модифицировать градиенты файнтюнинга таким образом, чтобы модель действительно апдейтила своё знание — не влияя на несвязанные с этим вопросы, но изменяя ответ для всех связанных. Однако возникает проблема, что если у вас в модели 10B параметров, то даже линейный слой, для их модицикации будет 100B.
Авторы решают это тем, что представляют градиент параметров через downstream gradient слоёв. Если вы помните бэкпроп, то градиент в линейном слое равен X.T @ dL/d(out). Где dL/d(out) — это downstream gradient размера hidden, что сильно меньше самого градиента размера hidden, hidden. Так как X.T мы знаем, то достаточно модифицировать dL/d(out). По-моему гениальное решение, я год назад занимался похожим проектом и не думаю, что когда-нибудь додумался бы до этого.
Этот трюк позволяет использовать подход даже для очень больших моделей, таких как T5-XXL 10B. При сравнении с альтернативными подходами, этот метод показывает себя лучше и в смысле генерализации на перефразирования вопроса и в смысле сохранения ответов на несвязанные вопросы.
Mitchell et al., [Stanford]
Представьте себе, что вы ClosedAI, большая суперкорпорация по тренировке языковых моделей. Вы скачиваете весь интернет и тренируете ваш GPT-42, тратя миллиарды долларов на электричество. После чего вы спрашиваете у модели "Who is the prime minister of the UK?" и она отвечает вам "Theresa May". Это грустный, но релеалистичный сценарий.
Менять какие-то факты в классических knowledge graphs легко — меняете ссылку с сущности UK prime minister на другого человека. Но в нейросетках это нетривиальная задача. Если вы просто зафайнтюните модель на одном примере, модель просто переобучится и например всё ещё будет отвечать "Theresa May" на вопрос "Who is the UK PM?". Ещё модель может изменить свои ответы на вопросы, которые вообще с этим не связаны.
Исследователи из Стенфорда предлагают натренировать нейросеть, которая будет модифицировать градиенты файнтюнинга таким образом, чтобы модель действительно апдейтила своё знание — не влияя на несвязанные с этим вопросы, но изменяя ответ для всех связанных. Однако возникает проблема, что если у вас в модели 10B параметров, то даже линейный слой, для их модицикации будет 100B.
Авторы решают это тем, что представляют градиент параметров через downstream gradient слоёв. Если вы помните бэкпроп, то градиент в линейном слое равен X.T @ dL/d(out). Где dL/d(out) — это downstream gradient размера hidden, что сильно меньше самого градиента размера hidden, hidden. Так как X.T мы знаем, то достаточно модифицировать dL/d(out). По-моему гениальное решение, я год назад занимался похожим проектом и не думаю, что когда-нибудь додумался бы до этого.
Этот трюк позволяет использовать подход даже для очень больших моделей, таких как T5-XXL 10B. При сравнении с альтернативными подходами, этот метод показывает себя лучше и в смысле генерализации на перефразирования вопроса и в смысле сохранения ответов на несвязанные вопросы.
Тут говорят, что Microsoft теперь тоже даёт API к GPT-3 через Azure. Называется это OpenAI Service. По факту он всё так же закрыт как и API от OpenAI, так как invintation only, но может быть будут более бодро раздавать (всё ещё жду свой GPT-3 токен, который запросил больше года назад).
Согласно официальному FAQ, разница с OpenAI такова: OpenAI Service brings together OpenAI API and Azure enterprise-level security, compliance, and regional availability (то есть для нормальных людей никакой).
За наводку спасибо @addmeto
Согласно официальному FAQ, разница с OpenAI такова: OpenAI Service brings together OpenAI API and Azure enterprise-level security, compliance, and regional availability (то есть для нормальных людей никакой).
За наводку спасибо @addmeto
Microsoft
Azure OpenAI in Foundry Models | Microsoft Azure
Access and fine-tune the latest AI reasoning and multimodal models, integrate AI agents, and deploy secure, enterprise-ready generative AI solutions.
Прямо сейчас идёт T0 Discussion with Victor Sanh
Общаются на тему Т0, который мы разбирали пару недель назад, с одним из главных авторов.
Общаются на тему Т0, который мы разбирали пару недель назад, с одним из главных авторов.
YouTube
T0 Discussion with Victor Sanh
Forwarded from DNative — блог Ткачука про SMM
— Почти все рекламинуемые каналы созданы 21-22 октября, либо конец октября
— Все на «очень широкие и популярные темы»
— Все а-ля паблики, без авторов
— Все выглядят одинаково и созданы под копирку
Возможно это какая-то новая будущая огромная медиа-сеть пабликов, на которую выделили большой рекламный бюджет.
Ожидание от рекламы в TG: большие бренды, адекватные рекламные кампании, креатив
Реальность рекламы в TG: паблики гонят себе трафик с топовых каналов за копейки.
Павел, браво! Запуск прошёл прекрасно.
Простое сравнение.
Когда Instagram запускал первые рекламные кампании, Кевин Систром (основатель Instagram) ЛИЧНО отсматривал рекламные объявления, давал по ним правки и не пропускал то, что по его мнению не отражало ценности Instagram.
— Все на «очень широкие и популярные темы»
— Все а-ля паблики, без авторов
— Все выглядят одинаково и созданы под копирку
Возможно это какая-то новая будущая огромная медиа-сеть пабликов, на которую выделили большой рекламный бюджет.
Ожидание от рекламы в TG: большие бренды, адекватные рекламные кампании, креатив
Реальность рекламы в TG: паблики гонят себе трафик с топовых каналов за копейки.
Павел, браво! Запуск прошёл прекрасно.
Простое сравнение.
Когда Instagram запускал первые рекламные кампании, Кевин Систром (основатель Instagram) ЛИЧНО отсматривал рекламные объявления, давал по ним правки и не пропускал то, что по его мнению не отражало ценности Instagram.
MLSpace
github.com/abhishekkrthakur/mlspace
Интересный заход на работу с окружениями от Abhishek Thakur, специфичный для ML. Устанавливает за вас Nvidia driver, CUDA и CUDNN нужных версий, ставит дефолтные вещи типа torch и jupyter. Под капотом этой штуки докер, но интерфейс больше похож на conda.
На данный момент это наверное даже не альфа версия, а просто идея. Я пока что не рекомендую использовать MLSpace, но советую обратить внимание. Сейчас документация частично отсутствует, единственный backend это torch с GPU, код выглядит очень сыро, работает только под Ubuntu.
Мне нравится идея, очень уж много часов своей жизни я убил на установку/переустановку Nvidia-штук.
github.com/abhishekkrthakur/mlspace
Интересный заход на работу с окружениями от Abhishek Thakur, специфичный для ML. Устанавливает за вас Nvidia driver, CUDA и CUDNN нужных версий, ставит дефолтные вещи типа torch и jupyter. Под капотом этой штуки докер, но интерфейс больше похож на conda.
На данный момент это наверное даже не альфа версия, а просто идея. Я пока что не рекомендую использовать MLSpace, но советую обратить внимание. Сейчас документация частично отсутствует, единственный backend это torch с GPU, код выглядит очень сыро, работает только под Ubuntu.
Мне нравится идея, очень уж много часов своей жизни я убил на установку/переустановку Nvidia-штук.
GitHub
GitHub - abhishekkrthakur/mlspace: MLSpace: Hassle-free machine learning & deep learning development
MLSpace: Hassle-free machine learning & deep learning development - GitHub - abhishekkrthakur/mlspace: MLSpace: Hassle-free machine learning & deep learning development
Large Language Models Can Be Strong Differentially Private Learners
Li et al. [Stanford]
arxiv.org/abs/2110.05679
Есть такая вещь как differential privacy. Это математическое понятие приватности, которое очень грубо можно описать как "убирание или добавление одного примера в датасет не изменяет финальную модель". То есть, например, по модели, вы не можете понять, использовались ли для её обучения данные определённого человека.
Большинство моделей с которыми мы работаем сейчас не являются дифференциально приватными, вплоть до того, что иногда можно заставить модель выдавать куски тренировочного сета дословно. Но тематика приватности становится всё более горячей и всё больше людей работают над ней. Например, существует алгоритм опримизации Differentially Private SGD (DP-SGD). Идея состоит в том, чтобы ограничить влияние каждого примера из датасета через ограничение максимальго градиента, который мы можем куммулятвно получить от них за время обучения. Плюсом к этому ещё в градиенты добавляется определённое количество шума.
Проблема с DP-SGD в том, что для больших моделей обычно он работает сильно хуже обычного SGD. Для решения этой проблемы используют кучу хаков. И вот теперь мы наконец доходим до идеи этой статьи: оказывается если вы правильно подобрали гиперпараметры DP-SGD, то большие модели не только тренируются хорошо, но и позволяют получать более высокое качество (при том же уровне приватности), чем модели поменьше. Экспериментировали с GLUE, E2E и DART.
Вообще в DL на удивление часто видишь, как хорошие гиперпараметры со старыми методами работают на уровне или даже лучше, чем новые более сложные методы.
Li et al. [Stanford]
arxiv.org/abs/2110.05679
Есть такая вещь как differential privacy. Это математическое понятие приватности, которое очень грубо можно описать как "убирание или добавление одного примера в датасет не изменяет финальную модель". То есть, например, по модели, вы не можете понять, использовались ли для её обучения данные определённого человека.
Большинство моделей с которыми мы работаем сейчас не являются дифференциально приватными, вплоть до того, что иногда можно заставить модель выдавать куски тренировочного сета дословно. Но тематика приватности становится всё более горячей и всё больше людей работают над ней. Например, существует алгоритм опримизации Differentially Private SGD (DP-SGD). Идея состоит в том, чтобы ограничить влияние каждого примера из датасета через ограничение максимальго градиента, который мы можем куммулятвно получить от них за время обучения. Плюсом к этому ещё в градиенты добавляется определённое количество шума.
Проблема с DP-SGD в том, что для больших моделей обычно он работает сильно хуже обычного SGD. Для решения этой проблемы используют кучу хаков. И вот теперь мы наконец доходим до идеи этой статьи: оказывается если вы правильно подобрали гиперпараметры DP-SGD, то большие модели не только тренируются хорошо, но и позволяют получать более высокое качество (при том же уровне приватности), чем модели поменьше. Экспериментировали с GLUE, E2E и DART.
Вообще в DL на удивление часто видишь, как хорошие гиперпараметры со старыми методами работают на уровне или даже лучше, чем новые более сложные методы.
{kind=link}
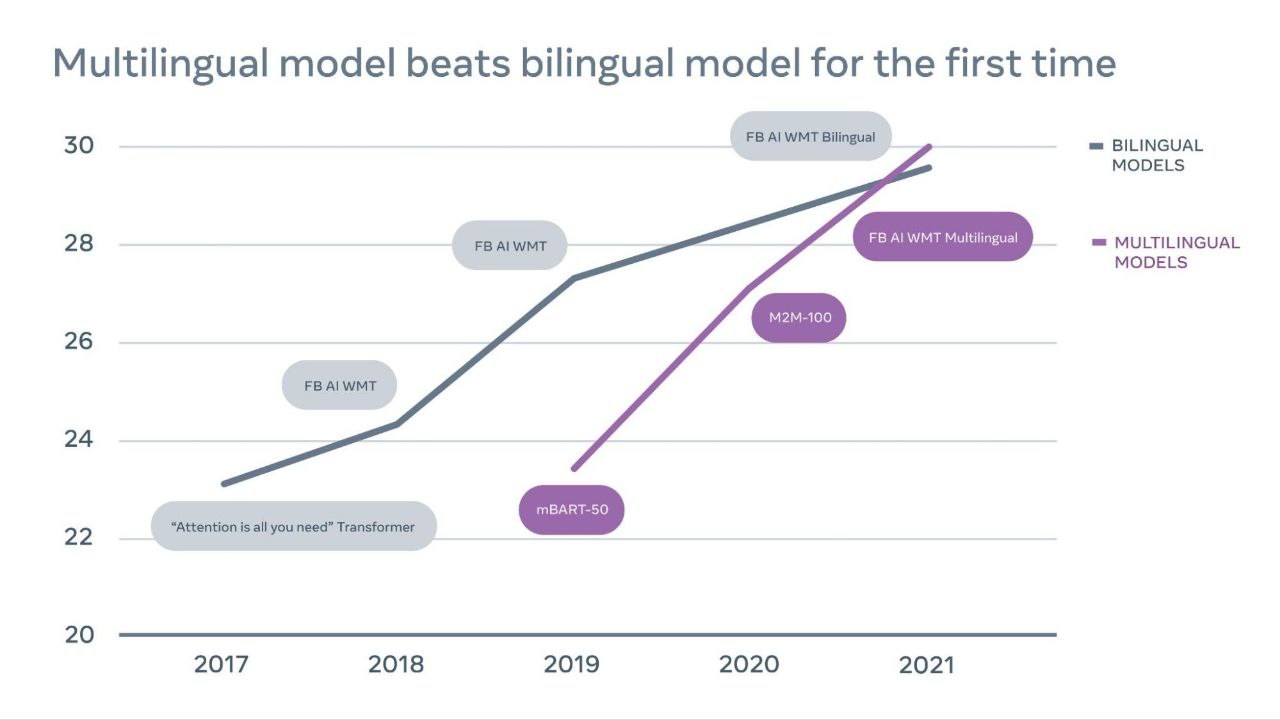
Мультиязычная модель машинного перевода от FAIR превзошла двуязычные модели на соревновании WMT-21.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
{kind=link}