
Моделька, которая переводит ваш код с одного языка программирования на другой (C++ <=> Java <=> Python). Без параллельной разметки для обучения. Использовали те же самые алгоритмы, которые применяются для unsupervised перевода в человеческих языках и они неплохо работают.
Забавно как сделали тестсет - набрали примеры алгоритмов на geeksforgeeks, там есть примеры имплементаций на разных языках.
подробнее в треде
twitter.com/GuillaumeLample/status/1269982022413570048
Забавно как сделали тестсет - набрали примеры алгоритмов на geeksforgeeks, там есть примеры имплементаций на разных языках.
подробнее в треде
twitter.com/GuillaumeLample/status/1269982022413570048
Twitter
Guillaume Lample
Unsupervised Translation of Programming Languages. Feed a model with Python, C++, and Java source code from GitHub, and it automatically learns to translate between the 3 languages in a fully unsupervised way. https://t.co/FpUL886KS7 with @MaLachaux @b_roziere…
Forwarded from Ridvan
Сдую пыль со старого поста про неумение в гит в ДС.
Пожалуй лучшее что видел на этот счет это видео Глеба Михайлова https://www.youtube.com/watch?v=0cGIiA0AjNw&t=1s
Совершенно годный контент, на мой взгляд, да еще и на русском
Пожалуй лучшее что видел на этот счет это видео Глеба Михайлова https://www.youtube.com/watch?v=0cGIiA0AjNw&t=1s
Совершенно годный контент, на мой взгляд, да еще и на русском
YouTube
GIT для Дата Саентиста
Мой курс по SQL: https://glebmikhaylov.com/sql
------------------------------------------------------
Посмотри видос и впиши git в свою жизнь. И в резюме).
ПОДДЕРЖАТЬ СОЗДАНИЕ ВИДОСОВ: https://www.glebmikhaylov.com/donate
0:07 Зачем учить git?
1:13 Интуитивное…
------------------------------------------------------
Посмотри видос и впиши git в свою жизнь. И в резюме).
ПОДДЕРЖАТЬ СОЗДАНИЕ ВИДОСОВ: https://www.glebmikhaylov.com/donate
0:07 Зачем учить git?
1:13 Интуитивное…
Forwarded from Data Science by ODS.ai 🦜
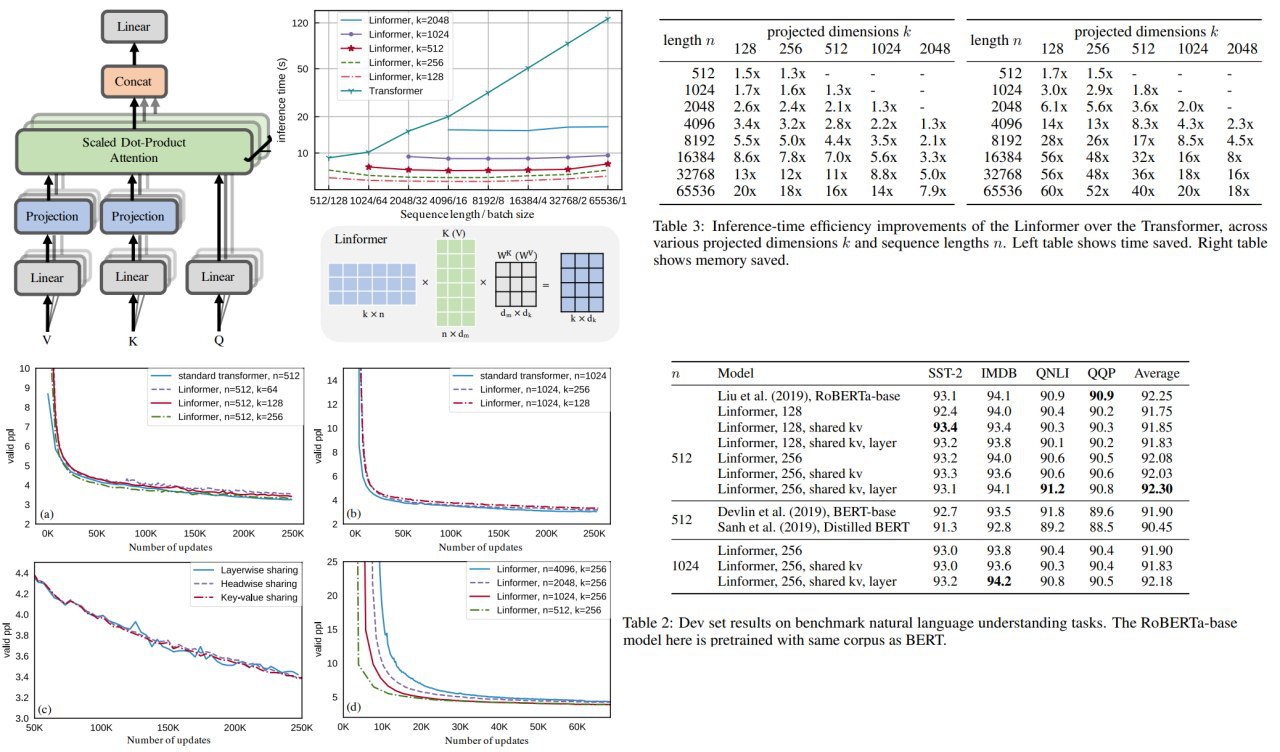
Linformer: Self-Attention with Linear Complexity
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
For experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
O(N^2) to O(N) in both time and space.Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
n and stride kFor experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
{kind=link}
Forwarded from Tatiana Shavrina
Вышел Russian SuperGLUE!
Лидерборд : https://russiansuperglue.com
Код: https://github.com/RussianNLP/RussianSuperGLUE
Чтобы правильно оценивать русскоязычные языковые модели, такие как популярные сейчас BERT, RoBERTa, XLNet и т.д., нужно иметь какие-то объективные метрики. Подходов, как это делать, не так много, а для русского языка их не было. Представлен Russian SuperGLUE - бенчмарк для задачи общего понимания языка (General Language Understanding) и дальнейшего развития моделей на русском.
Набор новых задач для оценки моделей:
1. LiDiRus (Linguistic Diagnostic for Russian) или просто общая диагностика — её мы полностью адаптировали с английского варианта.
2. DaNetQA — набор вопросов на здравый смысл и знание, с да-нет ответом.
3. RCB (Russian Commitment Bank) — классификация наличия причинно-следственных связей между текстом и гипотезой из него.
4. PARus (Plausible Alternatives for Russian) — целеполагание, выбор из альтернативных вариантов на основе здравого смысла.
5. MuSeRC (Multi-Sentence Reading Comprehension) — машинное чтение. Задания содержат текст и вопрос к нему, но такой, на который можно ответить, сделав вывод из текста.
6. RuCoS (Russian reading comprehension with Commonsense) — тоже задача на машинное чтение. Модели даётся новостной текст, а также его краткое содержание с пропуском — пропуск нужно восстановить, выбрав из вариантов.
7. TERRa (Textual Entailment Recognition for Russian) — классификация причинно-следственных связей между предложениями (собрали с нуля по новостям и худлиту).
8. RUSSE (Russian Semantic Evaluation) — задача распознавания смысла слова в контексте (word sense disambiguation). Взят из RUSSE
9. RWSD (Russian Winograd Schema Dataset) — задания на логику, с добавленными неоднозначностями («Если бы у Ивана был осёл, он бы его бил»). Создан по аналогии с Winograd Schema.
Разработчики и энтузиасты приглашаются представить свои модели на лидерборде!
Пост на habr https://habr.com/ru/company/sberbank/blog/506058/
Optimizing Data usage via Differentiable Rewards
Wang, Pham et al. [CMU and Google Brain]
arxiv.org/abs/1911.10088
Идея: разнные данные по-разному полезны, давайте натренируем RL агента выбирать те, которые уменьшают лосс на dev-сете сильнее всего
Предположение: dev больше похож на test, чем train
Кому это надо: да почти всем, у кого плохое качество разметки. Вы размечаете свой большой train как можете, а dev очень-очень аккуратно (например, сами или требуете более высокий overlap от разметчиков)
Конкретный сигнал на обучение агента: похожесть градиента датапоинта на градииент на dev-сете.
Экспериментировали на классификации изображений и на низкоресурсном машинном переводе. Переводили с азейбайджанского, белорусского, галисийского и словацкого на английский. Тренировались на датасете из турецкого, русского, португальского и чешского, а низкоресурсные использовали в качестве dev. В среднем их метод добавляет меньше 0.5 BLEU, но когда ваш BLEU = 11, это довольно много.
Wang, Pham et al. [CMU and Google Brain]
arxiv.org/abs/1911.10088
Идея: разнные данные по-разному полезны, давайте натренируем RL агента выбирать те, которые уменьшают лосс на dev-сете сильнее всего
Предположение: dev больше похож на test, чем train
Кому это надо: да почти всем, у кого плохое качество разметки. Вы размечаете свой большой train как можете, а dev очень-очень аккуратно (например, сами или требуете более высокий overlap от разметчиков)
Конкретный сигнал на обучение агента: похожесть градиента датапоинта на градииент на dev-сете.
Экспериментировали на классификации изображений и на низкоресурсном машинном переводе. Переводили с азейбайджанского, белорусского, галисийского и словацкого на английский. Тренировались на датасете из турецкого, русского, португальского и чешского, а низкоресурсные использовали в качестве dev. В среднем их метод добавляет меньше 0.5 BLEU, но когда ваш BLEU = 11, это довольно много.
The Level 3 AI Assistant Conference
June 18, 2020 | Online
www.l3-ai.dev
Бесплатная конфа по Conversational AI. Из интересных для меня докладов нашёл:
1. Testing: The Art of Challenging Chatbots, Botium
1. Designing Practical NLP Solutions, Explosion.ai (создатели spaCy)
1. From Research to Production – Our Process at Rasa, Rasa
1. Distilling BERT, Rasa
1. Current Research in Conversational AI, много спикеров включая Rachael Tatman, Thomas Wolf и Anna Rogers
1. Google's Meena: Open Dialog systems, Google
Выглядит неплохо, надо регистрироваться.
June 18, 2020 | Online
www.l3-ai.dev
Бесплатная конфа по Conversational AI. Из интересных для меня докладов нашёл:
1. Testing: The Art of Challenging Chatbots, Botium
1. Designing Practical NLP Solutions, Explosion.ai (создатели spaCy)
1. From Research to Production – Our Process at Rasa, Rasa
1. Distilling BERT, Rasa
1. Current Research in Conversational AI, много спикеров включая Rachael Tatman, Thomas Wolf и Anna Rogers
1. Google's Meena: Open Dialog systems, Google
Выглядит неплохо, надо регистрироваться.
DL in NLP
API OpenAI Очень странная штука, но выглядит забавно. openai.com/blog/openai-api/
UPD по OpenAI API.
Много кто, включая меня, решили что это какая-то непонятная замена вашему любимому zsh. Это не так, это API по всем тем моделькам, которые не помещаются на вашу GPU. Replika уже внедрила GPT-3 к себе в прод и получили заметный скачок в метриках (см график).
Вы тоже можете запросить доступ в бету для своего продукта / рисёча.
Обсуждение в ODS с разрабами из реплики.
Много кто, включая меня, решили что это какая-то непонятная замена вашему любимому zsh. Это не так, это API по всем тем моделькам, которые не помещаются на вашу GPU. Replika уже внедрила GPT-3 к себе в прод и получили заметный скачок в метриках (см график).
Вы тоже можете запросить доступ в бету для своего продукта / рисёча.
Обсуждение в ODS с разрабами из реплики.
VirTex: Learning Visual Representations from Textual Annotations
Desai and Johnson [University of Michigan]
arxiv.org/abs/2006.06666v1
TL;DR предобучение для задач CV на задаче image captioning более sample-efficient, чем предобучение на ImageNet-классификации.
Обучали resnet+transformer lm. В качестве задачи выбрали комбинацию forward LM и backward LM, аналогично ELMo. Хотели попробовать MLM тоже, но не умеестились в compute.
Много людей считают, что связывание CV и NLP будет очень активно развиваться в ближайшие пару лет, я с ними согласен.
Desai and Johnson [University of Michigan]
arxiv.org/abs/2006.06666v1
TL;DR предобучение для задач CV на задаче image captioning более sample-efficient, чем предобучение на ImageNet-классификации.
Обучали resnet+transformer lm. В качестве задачи выбрали комбинацию forward LM и backward LM, аналогично ELMo. Хотели попробовать MLM тоже, но не умеестились в compute.
Много людей считают, что связывание CV и NLP будет очень активно развиваться в ближайшие пару лет, я с ними согласен.
Одной строкой:
1. Релиз AllenNLP 1.0
1. Специализация по NLP от deeplearning.ai
1. Насколько сильнно twitter влияет на цитируемость статьи
1. Релиз PyTorch Lightning⚡0.8
1. L3AI идёт прямо сейчас, подключайтесь
спасибо @someotherusername за ссылки
1. Релиз AllenNLP 1.0
1. Специализация по NLP от deeplearning.ai
1. Насколько сильнно twitter влияет на цитируемость статьи
1. Релиз PyTorch Lightning⚡0.8
1. L3AI идёт прямо сейчас, подключайтесь
спасибо @someotherusername за ссылки
Medium
Announcing AllenNLP 1.0
The 1.0 version of AllenNLP is the culmination of several months of work from our engineering team. The AllenNLP library has had…
Memory Transformer
Burtsev and Sapunov
arxiv.org/abs/2006.11527
Cтатья от iPavlov и Intento в которой экспериентирют с пустыми токенами в трансформерах. По аналогии с SEP токенами, добавляют по 10-30 MEM токенов. Интуиция тут такая, что потенциально туда трансформер может складывать полезную инфоормацию, например какое-то сжатое описание всего текста. В экспериментах с WMT14 en-de смогло докинуть 1 BLEU к ванильному трансформеру в Base версии. Визуализация attention MEM токенов намекает на то, что они действительно хранят глобальный контекст а так же выполняют с ними операции типа чтения, записи и копирования.
В том числе экспериментировали с более сложным подходом в котором key и value использюется эмбеддинги памяти, а не эмбеддинги токенов, но не зашло.
Результаты довольно неожиданные в контексте свежих статей по интерпретации attention, которые показали, что CLS и SEP используются как своеобразные "выключатели" голов. Было бы интересно посмотреть не только на веса attention, но и на нормы аутпутов, как в статье Atteniton Module is Not Only a Weight.
Burtsev and Sapunov
arxiv.org/abs/2006.11527
Cтатья от iPavlov и Intento в которой экспериентирют с пустыми токенами в трансформерах. По аналогии с SEP токенами, добавляют по 10-30 MEM токенов. Интуиция тут такая, что потенциально туда трансформер может складывать полезную инфоормацию, например какое-то сжатое описание всего текста. В экспериментах с WMT14 en-de смогло докинуть 1 BLEU к ванильному трансформеру в Base версии. Визуализация attention MEM токенов намекает на то, что они действительно хранят глобальный контекст а так же выполняют с ними операции типа чтения, записи и копирования.
В том числе экспериментировали с более сложным подходом в котором key и value использюется эмбеддинги памяти, а не эмбеддинги токенов, но не зашло.
Результаты довольно неожиданные в контексте свежих статей по интерпретации attention, которые показали, что CLS и SEP используются как своеобразные "выключатели" голов. Было бы интересно посмотреть не только на веса attention, но и на нормы аутпутов, как в статье Atteniton Module is Not Only a Weight.
Forwarded from Catalyst | Community
I am trilled to announce our second post - BERT Distillation with Catalyst.
Distilling BERT models can minimize loss, reduce model sizes, and speed up inferences. Check it out!
Huge thank you to Nikita for this great tutorial.
https://medium.com/pytorch/bert-distillation-with-catalyst-c6f30c985854?source=friends_link&sk=1a28469ac8c0e6e6ad35bd26dfd95dd9
Distilling BERT models can minimize loss, reduce model sizes, and speed up inferences. Check it out!
Huge thank you to Nikita for this great tutorial.
https://medium.com/pytorch/bert-distillation-with-catalyst-c6f30c985854?source=friends_link&sk=1a28469ac8c0e6e6ad35bd26dfd95dd9
Medium
BERT Distillation with Catalyst
How to distill BERT with Catalyst.
Статьи в одну строчку:
1. arxiv.org/abs/2006.13979 - мультиязычный претренинг а-ля XLM можно успешно использовать для предобучения моделей распознавания речи (twitter)
1. arxiv.org/abs/2006.13484 - тренировка BERT за 54 минуты с помощью больших батчей, LAMB + Nesterov и нового lr schedule
1. arxiv.org/abs/2006.14170 - нецентрализованный differentially private метод тренировки NLP моделей
1. arxiv.org/abs/2006.12005 - GAN для контролируемой генерации текста, который работает плохо, но зато быстро
1. arxiv.org/abs/1901.06436 - латентное графовое представление для машинного перевода
1. arxiv.org/abs/2006.13979 - мультиязычный претренинг а-ля XLM можно успешно использовать для предобучения моделей распознавания речи (twitter)
1. arxiv.org/abs/2006.13484 - тренировка BERT за 54 минуты с помощью больших батчей, LAMB + Nesterov и нового lr schedule
1. arxiv.org/abs/2006.14170 - нецентрализованный differentially private метод тренировки NLP моделей
1. arxiv.org/abs/2006.12005 - GAN для контролируемой генерации текста, который работает плохо, но зато быстро
1. arxiv.org/abs/1901.06436 - латентное графовое представление для машинного перевода
Twitter
Alexis Conneau
Unsupervised Cross-lingual Representation Learning for Speech Recognition: https://t.co/zyz4Z3mWBV Our self-supervised learning approach learns cross-lingual speech representations by pretraining a single model from the raw waveform in multiple languages.
Forwarded from Soslan Tabuev
Свежий обзор зоопарка трансформеров от Григория Сапунова на онлайн-конфе GDG DevParty Russia:
https://www.youtube.com/watch?v=KZ9NXYcXVBY
https://www.youtube.com/watch?v=KZ9NXYcXVBY
YouTube
Григорий Сапунов | Transformer Zoo
Плейлист Mobile: https://www.youtube.com/playlist?list=PLGlZ_ld11os_JyZ6xVAWEZ-rnxrLjrGH5
Плейлист Web: https://www.youtube.com/playlist?list=PLGlZ_ld11os-nnB5CG_p6brIUWMGXU5Tr
Плейлист Cloud: https://www.youtube.com/playlist?list=PLGlZ_ld11os8QYBOSM8KU3INh244iFXKK…
Плейлист Web: https://www.youtube.com/playlist?list=PLGlZ_ld11os-nnB5CG_p6brIUWMGXU5Tr
Плейлист Cloud: https://www.youtube.com/playlist?list=PLGlZ_ld11os8QYBOSM8KU3INh244iFXKK…