
Сбер обучил русский GPT 🎉
Большие модельки потихоньку продвигаются и в русский язык. О цифрах:
1. 600Гб текстов – Omnia Russica+пикабу+22centry+banki.ru
1. GPT-Large на 700млн параметров. Кстати это меньше, чем самый большой GPT-2, но зато помещается в память.
1. 128 V100, тренировали 2 недели на Christophari. В Google Cloud такое стоило бы примерно $100 тысяч.
Из статьи интересно, что оказывается, сбер уже использует GPT в проде для болталки. Очень смело, но зато теперь можно ждать лулзов и историй про то, как кого-то очень изощнённо куда-то послала колонка сбера.
Что грустно, это то, что модельку не поэвалюировали на прикладных задачах классификации/перевода итд (в чём собственно и заключается вся соль GPT-N, N>1).
Пример генерации:
Context: на словах ты лев толстой
ruGPT3Large: а в сущности, - ты тоже не дурак, просто так же, как и твой человек, то есть твоя "жизнь", а также как и ты думаешь по-настоящему "ты" и есть твои "жизнь" или "выбор" в отношении твоего положения.
Всё это добро доступно через Transformers (huggingface.co/sberbank-ai), код есть на гитхабе, в посте ещё сказали про то, что почищенный датасет тоже должен быть доступен, но я его не нашёл.
Большие модельки потихоньку продвигаются и в русский язык. О цифрах:
1. 600Гб текстов – Omnia Russica+пикабу+22centry+banki.ru
1. GPT-Large на 700млн параметров. Кстати это меньше, чем самый большой GPT-2, но зато помещается в память.
1. 128 V100, тренировали 2 недели на Christophari. В Google Cloud такое стоило бы примерно $100 тысяч.
Из статьи интересно, что оказывается, сбер уже использует GPT в проде для болталки. Очень смело, но зато теперь можно ждать лулзов и историй про то, как кого-то очень изощнённо куда-то послала колонка сбера.
Что грустно, это то, что модельку не поэвалюировали на прикладных задачах классификации/перевода итд (в чём собственно и заключается вся соль GPT-N, N>1).
Пример генерации:
Context: на словах ты лев толстой
ruGPT3Large: а в сущности, - ты тоже не дурак, просто так же, как и твой человек, то есть твоя "жизнь", а также как и ты думаешь по-настоящему "ты" и есть твои "жизнь" или "выбор" в отношении твоего положения.
Всё это добро доступно через Transformers (huggingface.co/sberbank-ai), код есть на гитхабе, в посте ещё сказали про то, что почищенный датасет тоже должен быть доступен, но я его не нашёл.
tokenizer = AutoTokenizer.from_pretrained("sberbank-ai/rugpt3large_based_on_gpt2")
model = AutoModel.from_pretrained("sberbank-ai/rugpt3large_based_on_gpt2")Хабр
Сбер выложил русскоязычную модель GPT-3 Large с 760 миллионами параметров в открытый доступ
Последнее десятилетие в области компьютерных технологий ознаменовалось началом новой «весны искусственного интеллекта». Впрочем, ситуацию в индустрии в наши дни...
mT5: A massively multilingual pre-trained text-to-text transformer
Xue et al. [Google]
arxiv.org/abs/2010.11934
Продолжение идей T5, но теперь не только для английского. Напомним, что T5 это seq2seq моделька обученная на вариации MLM (SpanBERT), которая при файнтюнинге всё ещё остаётся seq2seq даже для задач классификации (моделька учится предсказывать слово, обозначающее класс). Ещё она огромная, до этого уже можно было догадаться.
Так вот для mT5 - мультиязычной версии T5 собрали датасет mC4 размером в 6 триллионов слов, что вроде бы должно весить около 12Tb (а помните, когда One Billion Words считался большим датасетом?). Что важно, это то, что в этом датасете содержится более 100 языков и что там на удивление много неанглийского, а русский вообще стоит на втором месте. В результате на всём этом обучается новая моделька в 13 миллиардов параметров и она обходит все текущие модели на мультиязычных датасетах, даже включая XLM(-R), при тренировке которых использовались параллельные данные и обходит довольно значительно (в среднем на 2-3 пункта).
Сама статья довольно скучная, по сути в этом TL;DR она вся и описана. Зато код выложен и модельки тоже, жалко что не в 🤗-формате. Где вы правда будете их запускать - это отдельный вопрос.
За наводку на статью спасибо @someotherusername
Xue et al. [Google]
arxiv.org/abs/2010.11934
Продолжение идей T5, но теперь не только для английского. Напомним, что T5 это seq2seq моделька обученная на вариации MLM (SpanBERT), которая при файнтюнинге всё ещё остаётся seq2seq даже для задач классификации (моделька учится предсказывать слово, обозначающее класс). Ещё она огромная, до этого уже можно было догадаться.
Так вот для mT5 - мультиязычной версии T5 собрали датасет mC4 размером в 6 триллионов слов, что вроде бы должно весить около 12Tb (а помните, когда One Billion Words считался большим датасетом?). Что важно, это то, что в этом датасете содержится более 100 языков и что там на удивление много неанглийского, а русский вообще стоит на втором месте. В результате на всём этом обучается новая моделька в 13 миллиардов параметров и она обходит все текущие модели на мультиязычных датасетах, даже включая XLM(-R), при тренировке которых использовались параллельные данные и обходит довольно значительно (в среднем на 2-3 пункта).
Сама статья довольно скучная, по сути в этом TL;DR она вся и описана. Зато код выложен и модельки тоже, жалко что не в 🤗-формате. Где вы правда будете их запускать - это отдельный вопрос.
За наводку на статью спасибо @someotherusername
GitHub
GitHub - google-research/multilingual-t5
Contribute to google-research/multilingual-t5 development by creating an account on GitHub.
Data Augmentation in NLP: Best Practices From a Kaggle Master
Очень давно ждал чего-то такого. Готовая библиотека для аугментаций в NLP. Как правило завести аугментации текстов сложно и эффект от них слишком малый, чтобы прямо заниматься этим. А теперь вроде бы можно в пару строчек кода.
Например, если вы хотите докинуть контекстных синонимов с помощью берта, то можете сделать так:
Это может выдать что-то такое:
Так что давайте все выполняем
Ссылка на гитхаб библиотеки
Ссылка на документацию
Очень давно ждал чего-то такого. Готовая библиотека для аугментаций в NLP. Как правило завести аугментации текстов сложно и эффект от них слишком малый, чтобы прямо заниматься этим. А теперь вроде бы можно в пару строчек кода.
Например, если вы хотите докинуть контекстных синонимов с помощью берта, то можете сделать так:
import nlpaug.augmenter.word as naw
aug = naw.ContextualWordEmbsAug(model_path='bert-base-uncased', action='insert')
augmented_text = aug.augment('this is a text')Это может выдать что-то такое:
this is currently a text
Что довольно неплохо с учётом того, что вы сделали это в три строчки кода включая импорт.Так что давайте все выполняем
pip install nlpaug и играемся с этим.Ссылка на гитхаб библиотеки
Ссылка на документацию
neptune.ai
Data Augmentation in NLP: Best Practices From a Kaggle Master
Insights on NLP data augmentation techniques, contrasts with vision, and best practices from a Kaggle master.
Example-Driven Intent Prediction with Observers
Mehri et al. [Amazon]
arxiv.org/abs/2010.08684
Интересная статья по классификации текста. В статье две идеи: example-driven prediction и observers.
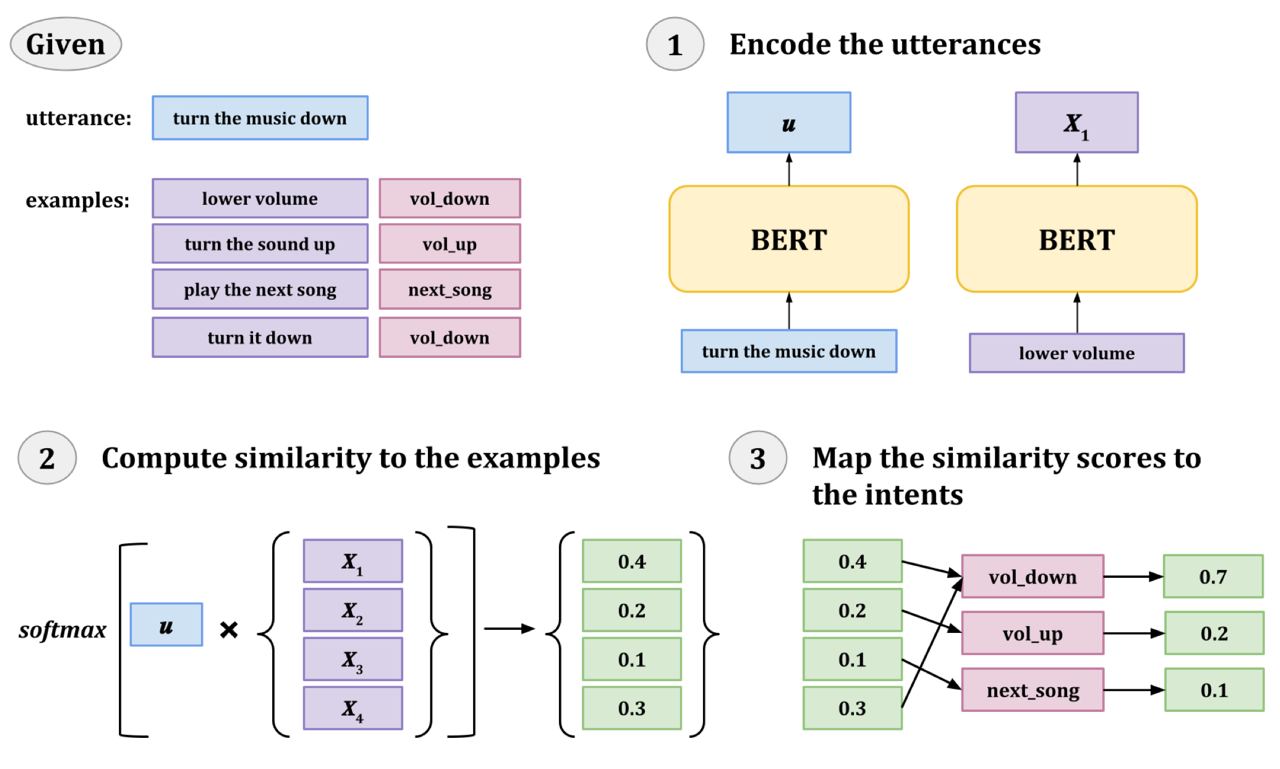
Example-driven prediction: давайте не будем делать выходной слой сетки (голову BERT) и вместо этого возьмём представление CLS токена и посравниваем его с небольшим числом примеров из нашего датасета. Получим similarity scores, потом засофтмаксим их - таким образом мы получим вероятности того, что input имеет тот же класс, что и каждый из примеров. А классы примеров мы знаем. Последний шаг - сложить one-hot вектора классов каждого примера с весами вероятностей из предыдушего шага. На выходе получим вероятность каждого класса. Идея изображена на картинке снизу.
Почему это интересно, это потому что мы не добавляем параметры в BERT и трениуем только сам трансформер, что забавно. Но вторая причина ещё интереснее - после такого обучения сетки мы можем делать инференс на классах, которых в обучающей выборке не было. По сути сетка ведь просто учит хорошую метрику. Идея подхода похожа на такой "гладкий" KNN.
Observers: мы знаем, что CLS часто смотрит сам на себя. Мы также знаем, что токены слов часто смотрят на CLS (возможно, в случаях, когда они хотят проигнорировать инпут). В результате каждый смотрит на каждого и как то это всё сложно. Авторы предлагают добавить новых вспомогательных токенов в BERT, которые будут как СLS, но, в отличие от CLS токенам слов будет запрещено на них смотреть. Таким образом observers занимаются только аггрегацией информации из векторов слов.
Результаты: используя оба метода вместе получаем SOTA на нескольких intent prediction датасетах в стандартном сетапе и в 10-shot сетапе. Не очень большое улучшение, но стабильное. Более интересные реузльтаты в предсказании интентов, отсутствующих в обучающей выборке - улучшение на десятки пунктов относительно бейзлайнов (хотя бейзлайны, конечно, кривые - нужно было сравнивать с каким-нибудь metric-learning подходом).
Mehri et al. [Amazon]
arxiv.org/abs/2010.08684
Интересная статья по классификации текста. В статье две идеи: example-driven prediction и observers.
Example-driven prediction: давайте не будем делать выходной слой сетки (голову BERT) и вместо этого возьмём представление CLS токена и посравниваем его с небольшим числом примеров из нашего датасета. Получим similarity scores, потом засофтмаксим их - таким образом мы получим вероятности того, что input имеет тот же класс, что и каждый из примеров. А классы примеров мы знаем. Последний шаг - сложить one-hot вектора классов каждого примера с весами вероятностей из предыдушего шага. На выходе получим вероятность каждого класса. Идея изображена на картинке снизу.
Почему это интересно, это потому что мы не добавляем параметры в BERT и трениуем только сам трансформер, что забавно. Но вторая причина ещё интереснее - после такого обучения сетки мы можем делать инференс на классах, которых в обучающей выборке не было. По сути сетка ведь просто учит хорошую метрику. Идея подхода похожа на такой "гладкий" KNN.
Observers: мы знаем, что CLS часто смотрит сам на себя. Мы также знаем, что токены слов часто смотрят на CLS (возможно, в случаях, когда они хотят проигнорировать инпут). В результате каждый смотрит на каждого и как то это всё сложно. Авторы предлагают добавить новых вспомогательных токенов в BERT, которые будут как СLS, но, в отличие от CLS токенам слов будет запрещено на них смотреть. Таким образом observers занимаются только аггрегацией информации из векторов слов.
Результаты: используя оба метода вместе получаем SOTA на нескольких intent prediction датасетах в стандартном сетапе и в 10-shot сетапе. Не очень большое улучшение, но стабильное. Более интересные реузльтаты в предсказании интентов, отсутствующих в обучающей выборке - улучшение на десятки пунктов относительно бейзлайнов (хотя бейзлайны, конечно, кривые - нужно было сравнивать с каким-нибудь metric-learning подходом).
{kind=link}
Пост с мотивацией. У OpenAI есть программа OpenAI Scholars, где они набирают около десятка людей каждые полгода, чтобы учить их делать рисёч в DL. Причём людей без опыта в ML.
На страничке OpenAI Scholars Spring 2020: Final Projects можно посмотреть какие проекты можно получить за полгода изучения ML. И они довольно классные, не уровня статей на топовых конференциях, но именно то, что достижимо как отличный курсовой проект. Например probing GPT-2 на синтаксис или получение GraphQL query из описания на английском. Советую посмотреть блогпосты/видео и начинать фигачить что-то такое же, потому что если люди без знания ML смогли выучить всё и сделать такие классные проекты, вы тоже можете.
На страничке OpenAI Scholars Spring 2020: Final Projects можно посмотреть какие проекты можно получить за полгода изучения ML. И они довольно классные, не уровня статей на топовых конференциях, но именно то, что достижимо как отличный курсовой проект. Например probing GPT-2 на синтаксис или получение GraphQL query из описания на английском. Советую посмотреть блогпосты/видео и начинать фигачить что-то такое же, потому что если люди без знания ML смогли выучить всё и сделать такие классные проекты, вы тоже можете.
Openai
OpenAI Scholars
We’re providing 6–10 stipends and mentorship to individuals from underrepresented groups to study deep learning full-time for 3 months and open-source a project.
DeepPavlov Product Roadmap — 2020H2 and Look At 2021
Думаю с диппавловым в той или иной степени знакомы почти все NLP разрабы в России. Так вот, они представили свой роадмап на 2021 и там есть интересные штуки.
1. GUI для создания интентов
1. Дашбоард для аналитики диалогов вашего бота
1. Улучшение поддержки конфигов RASA
1. Упрощение конфигов Agent
1. Миграция кучи всего разработанного для Alexa Challange в либу
Думаю с диппавловым в той или иной степени знакомы почти все NLP разрабы в России. Так вот, они представили свой роадмап на 2021 и там есть интересные штуки.
1. GUI для создания интентов
1. Дашбоард для аналитики диалогов вашего бота
1. Улучшение поддержки конфигов RASA
1. Упрощение конфигов Agent
1. Миграция кучи всего разработанного для Alexa Challange в либу
Medium
DeepPavlov Product Roadmap — 2020H2 and Look At 2021
We’re fast approaching the end of 2020, and we’re excited to share our perspective on this year as well as what lies ahead for DeepPavlov…
The story behind Paranoid Transformer 🔥🔥
GPT generator + BERT filter + hand-writing generation RNN
https://medium.com/altsoph/paranoid-transformer-80a960ddc90a
GPT generator + BERT filter + hand-writing generation RNN
https://medium.com/altsoph/paranoid-transformer-80a960ddc90a
Medium
PARANOID TRANSFORMER
The pre-order of my book, Paranoid Transformer, generated by a bunch of neural networks, is now open. Here is the story…
Residual Energy-Based Models for Text Generation
Deng et al. [FAIR]
arxiv.org/abs/2004.11714
Новая интересная статья по генерации текста. Авторы предлагают вместо стандартного авторегрессионного моделирования перейти к моделированию ненормализованной вероятности (энергии) целого предложения.
Но напрямую это сделать нельзя, тк непонятно, как геренировать примеры плохих последовательностей. Поэтому они параметризуют модель как
То есть E(x) обучается как дискриминатор учащийся различать между реальными текстами и текстами, сгенерированными LM. По сути мы получили GAN, описаный в терминах energy-based models (EBM).
Как всегда, у GAN есть проблема семплирования - как геренировать текст с помощью обученной модели. Для этого авторы (используя немного матана) показывают, что сэмплирование текста длины K из этой EBM эквивалентно тому, если мы 1) сгеренируем несколько текстов длины K из языковой модели; 2) используя получишиеся семплы, оценим матожидание энергии E всей последовательности (там чуть сложнее, но идея такая); 3) используя нашу оценку энергии мы получим "подкорректированное" функцией энергии вероятностное распределение следующего слова и теперь будем семплировать из этих вероятностей. Причём по-идее эта коррекция (тк она смотрит планирует будущее на K-1 токен больше) должна улучшить языковую модель, которая только думает про следующее слово.
В качестве LM использовался обученный трансформер. В качестве дискриминатора использовался BERT (предобученный с нуля, на том же датасете, что и LM, чтобы не было читерства).
Последний момент состоит в том, что оценивать перплексию у такой модели напрямую нельзя, тк мы моделируем ненормализованные вероятности. Авторы придумали метод, который позволяет оценить её с помощью того, что мы геренируем очень много достаточно длинных текстов и вычисляем вероятности для подсчёта перплексии из статистик сгеренированных текстов.
Результаты:
1. чуть лучше перплексия, чем у языковой модели такого же размера как LM + BERT
1. человеческая оценка качества текстов сгеренированных новой моделью тоже выше, чем у всех бейзлайнов
1. чуть более разнообразные n-gram чем у языковых моделей, но ещё далеко до человека
Deng et al. [FAIR]
arxiv.org/abs/2004.11714
Новая интересная статья по генерации текста. Авторы предлагают вместо стандартного авторегрессионного моделирования перейти к моделированию ненормализованной вероятности (энергии) целого предложения.
Но напрямую это сделать нельзя, тк непонятно, как геренировать примеры плохих последовательностей. Поэтому они параметризуют модель как
p(x) = LM(x) * exp(-E(x)), где LM - обычная (обученная) авторегрессионная языковая модель, оценивающая вероятность следующего слова, а E(x) - функция энергии, оценивающая всю последовательность. И качестве "плохих" последовательностей во время обучения E берут то, что геренирует LM.То есть E(x) обучается как дискриминатор учащийся различать между реальными текстами и текстами, сгенерированными LM. По сути мы получили GAN, описаный в терминах energy-based models (EBM).
Как всегда, у GAN есть проблема семплирования - как геренировать текст с помощью обученной модели. Для этого авторы (используя немного матана) показывают, что сэмплирование текста длины K из этой EBM эквивалентно тому, если мы 1) сгеренируем несколько текстов длины K из языковой модели; 2) используя получишиеся семплы, оценим матожидание энергии E всей последовательности (там чуть сложнее, но идея такая); 3) используя нашу оценку энергии мы получим "подкорректированное" функцией энергии вероятностное распределение следующего слова и теперь будем семплировать из этих вероятностей. Причём по-идее эта коррекция (тк она смотрит планирует будущее на K-1 токен больше) должна улучшить языковую модель, которая только думает про следующее слово.
В качестве LM использовался обученный трансформер. В качестве дискриминатора использовался BERT (предобученный с нуля, на том же датасете, что и LM, чтобы не было читерства).
Последний момент состоит в том, что оценивать перплексию у такой модели напрямую нельзя, тк мы моделируем ненормализованные вероятности. Авторы придумали метод, который позволяет оценить её с помощью того, что мы геренируем очень много достаточно длинных текстов и вычисляем вероятности для подсчёта перплексии из статистик сгеренированных текстов.
Результаты:
1. чуть лучше перплексия, чем у языковой модели такого же размера как LM + BERT
1. человеческая оценка качества текстов сгеренированных новой моделью тоже выше, чем у всех бейзлайнов
1. чуть более разнообразные n-gram чем у языковых моделей, но ещё далеко до человека
The Private AI Series
courses.openmined.org
Пока что непонятно, что это такое, но обещают бесплатный курс, который научит вас differential privacy и другим классным методам работы с данными, без прямого доступа к данным. Выглядит слишком пафосно, чтобы курс был очень глубоким и действительно погружающим в эту тему, но у них есть шансы популяризировать эти подходы и познакомить огромное количество людей с проблемами, которые эти подходы решают.
Запуск в январе, я записался, посмотрим что будет интересного.
И чтобы в этом посте было что-то действительно полезное, вот вам ссылка на вводную лекцию по differential privacy в MIT, которую читает автор openminded.
courses.openmined.org
Пока что непонятно, что это такое, но обещают бесплатный курс, который научит вас differential privacy и другим классным методам работы с данными, без прямого доступа к данным. Выглядит слишком пафосно, чтобы курс был очень глубоким и действительно погружающим в эту тему, но у них есть шансы популяризировать эти подходы и познакомить огромное количество людей с проблемами, которые эти подходы решают.
Запуск в январе, я записался, посмотрим что будет интересного.
И чтобы в этом посте было что-то действительно полезное, вот вам ссылка на вводную лекцию по differential privacy в MIT, которую читает автор openminded.
YouTube
Introducing The Private AI Series
Beginning in January 2021 - OpenMined will begin offering a series of free course on privacy technology. In this video - you will learn about the skills this series can teach you and why they are so important both to the future of AI progress and to society…
Немного TL;DR статей с EMNLP 2020, который идёт прямо сейчас.
With Little Power Comes Great Responsibility
If you have minor improvements, test on big datasets. Do not trust WNLI, MRPC and SST-2 if your improvements are less than +2 points (+5 on WNLI). Trust +1 BLEU point change only if your test set if bigger than 3000.
COGS: A Compositional Generalization Challenge Based on Semantic Interpretation
Nobody expected that :sarcasm:, but it looks like transformers and LSTMs do not generalize well on the out-of-distribution lexical/structural variations.
An Analysis of Natural Language Inference Benchmarks through the Lens of Negation
Transformers also does not seem to understand negation. They also expanded SNLI and MNLI to have more negation (current datasets have 3-20% of sentences with negation while in the wild the numbers should be around 30%). On some of the new datasets model perform worse than random (?).
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
An interesting way to visualize a dataset. Shows what data in your dataset is easy/hard to learn and allows to inspect for labelling mistakes. Looks nice too 😄
With Little Power Comes Great Responsibility
If you have minor improvements, test on big datasets. Do not trust WNLI, MRPC and SST-2 if your improvements are less than +2 points (+5 on WNLI). Trust +1 BLEU point change only if your test set if bigger than 3000.
COGS: A Compositional Generalization Challenge Based on Semantic Interpretation
Nobody expected that :sarcasm:, but it looks like transformers and LSTMs do not generalize well on the out-of-distribution lexical/structural variations.
An Analysis of Natural Language Inference Benchmarks through the Lens of Negation
Transformers also does not seem to understand negation. They also expanded SNLI and MNLI to have more negation (current datasets have 3-20% of sentences with negation while in the wild the numbers should be around 30%). On some of the new datasets model perform worse than random (?).
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
An interesting way to visualize a dataset. Shows what data in your dataset is easy/hard to learn and allows to inspect for labelling mistakes. Looks nice too 😄
ACL Anthology
With Little Power Comes Great Responsibility
Dallas Card, Peter Henderson, Urvashi Khandelwal, Robin Jia, Kyle Mahowald, Dan Jurafsky. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
Forwarded from b b
Хотел бы докинуть в общую копилку всяких интересностей с EMNLP: там был очень интересный обзорный туториал по высокопроизводительному NLP, по которому можно посмотреть слайды (https://gabrielilharco.com/publications/EMNLP_2020_Tutorial__High_Performance_NLP.pdf)
Чего-то сверхнового для тех, кто в теме, там, наверное, нет, но для тех, кто так и не разобрался в разных видах дистилляции и pruning'а (типа меня), может быть познавательно.
Чего-то сверхнового для тех, кто в теме, там, наверное, нет, но для тех, кто так и не разобрался в разных видах дистилляции и pruning'а (типа меня), может быть познавательно.
Классный тред с подборкой статей с прошедшего EMNLP
Советую прямо зайтв в него и потыкать в ссылки на TL;DR статей от самих авторов с картинками и прочим. А для тех, кто ленивый, вот TL;DR прямо тут:
1. Attention is Not Only a Weight: Analyzing Transformers with Vector Norms - маленькие векторы с большим attention score на них остаются маленькими (кстати мы уже разбирали эту статью пару месяцев назад)
1. BLEU might be Guilty but References are not Innocent - BLEU гораздо лучше коррелирует с человеческим мнением, если мы просто нагенерируем для много reference translations через парафразы
1. Grounded Compositional Outputs for Adaptive Language Modeling - хитрый способ добавлять информацию в языковые модели используя дополнительные источники данных
1. How do Decisions Emerge across Layers in Neural Models? Interpretation with Differentiable Masking - новый способ интерпретации моделек
1. How Much Knowledge Can You Pack Into the Parameters of a Language Model? - closed-book QA с огромными T5-моделями, ответы тем лучше, чем модель больше
1. Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models - можно трансферить предтренированные модельки между различными доменами (музыка, текст, код) и оно даже будет как-то работать. Очень классная статья, нужно найти больше времени, чтобы её разобрать подробнее. В паре слов - вы можете натренировать BERT не на тексте, а на музыке и применить его для текстов.
1. OCR Post Correction for Endangered Language Texts - хитрые способы применять OCR для редких языков
1. Pareto Probing: Trading Off Accuracy for Complexity - в основном в probing tasks используются мега простые модельки, но у этого есть свои минусы. В статье обсуждают tradeoff между пробингом простыми и сложными моделями и показывают, что надо работать где-то посредине.
1. Quantifying Intimacy in Language - очень забавная статья, где смотрели на статистику интимных разговоров в книгах, фильмах, твиттере и реддите.
1. Reformulating Unsupervised Style Transfer as Paraphrase Generation - два в одном: и хороший обзор методов style-transfer и новая SOTA
1. Scaling Hidden Markov Language Models - оживление HMM с помощью нейросетевой репараметризации, показали что большие HMM могут быть competitive с сетками
1. Sparse Text Generation - используйте sparsemax для генерации и будет вам счастье
1. With Little Power Comes Great Responsibility - уже обозревали выше, основная идея - если у вас маленькое улучшение метрик, тестируйтесь на больших датасетах
Советую прямо зайтв в него и потыкать в ссылки на TL;DR статей от самих авторов с картинками и прочим. А для тех, кто ленивый, вот TL;DR прямо тут:
1. Attention is Not Only a Weight: Analyzing Transformers with Vector Norms - маленькие векторы с большим attention score на них остаются маленькими (кстати мы уже разбирали эту статью пару месяцев назад)
1. BLEU might be Guilty but References are not Innocent - BLEU гораздо лучше коррелирует с человеческим мнением, если мы просто нагенерируем для много reference translations через парафразы
1. Grounded Compositional Outputs for Adaptive Language Modeling - хитрый способ добавлять информацию в языковые модели используя дополнительные источники данных
1. How do Decisions Emerge across Layers in Neural Models? Interpretation with Differentiable Masking - новый способ интерпретации моделек
1. How Much Knowledge Can You Pack Into the Parameters of a Language Model? - closed-book QA с огромными T5-моделями, ответы тем лучше, чем модель больше
1. Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models - можно трансферить предтренированные модельки между различными доменами (музыка, текст, код) и оно даже будет как-то работать. Очень классная статья, нужно найти больше времени, чтобы её разобрать подробнее. В паре слов - вы можете натренировать BERT не на тексте, а на музыке и применить его для текстов.
1. OCR Post Correction for Endangered Language Texts - хитрые способы применять OCR для редких языков
1. Pareto Probing: Trading Off Accuracy for Complexity - в основном в probing tasks используются мега простые модельки, но у этого есть свои минусы. В статье обсуждают tradeoff между пробингом простыми и сложными моделями и показывают, что надо работать где-то посредине.
1. Quantifying Intimacy in Language - очень забавная статья, где смотрели на статистику интимных разговоров в книгах, фильмах, твиттере и реддите.
1. Reformulating Unsupervised Style Transfer as Paraphrase Generation - два в одном: и хороший обзор методов style-transfer и новая SOTA
1. Scaling Hidden Markov Language Models - оживление HMM с помощью нейросетевой репараметризации, показали что большие HMM могут быть competitive с сетками
1. Sparse Text Generation - используйте sparsemax для генерации и будет вам счастье
1. With Little Power Comes Great Responsibility - уже обозревали выше, основная идея - если у вас маленькое улучшение метрик, тестируйтесь на больших датасетах
Twitter
Sabrina J. Mielke
I finally watched all the talks I wanted to, ended up importing 56 papers to my bib, and now present to you: 🎉 My 13 favorite papers (sorted alphabetically) at #EMNLP2020! 🔥 [1/15]
Forwarded from Deleted Account
Всем, привет! В ближайший четверг в 17:00 состоится семинар лаборатории нейросетей и глубокого обучения МФТИ на котором Анна Роджерс представит бертологический доклад. Приглашаю всех заинтересованных :) ссылку на зум сброшу в канал перед семинаром.
When BERT plays the lottery, all tickets are winning!
The lottery ticket hypothesis was originally developed for randomly initialized models, but might it also apply to pre-trained Transformers? If the “good” subnetworks exist, can they tell us anything about how BERT achieves its performance?
https://arxiv.org/pdf/2005.00561 (edited)
When BERT plays the lottery, all tickets are winning!
The lottery ticket hypothesis was originally developed for randomly initialized models, but might it also apply to pre-trained Transformers? If the “good” subnetworks exist, can they tell us anything about how BERT achieves its performance?
https://arxiv.org/pdf/2005.00561 (edited)
Поговорим про мультиязычные модели перевода.
Сейчас им приходится часто делать zero-shot. Условно, модель может перевести с индонезийского на татарский, несмотря на то, что на такой языковой паре не обучалась. Энкодер мапит все языки в единое пространство, а декодер умеет из этого пространства декодить (Wu et al, 2016). Но получается так себе.
Мы знаем, что лучшее решение zero-shot задач - это найти нормальный датасет, где не придётся заниматься zero-shot. Facebook в своей статье намайнил такой датасет для 2 тысяч пар языков, а Google показал что даже когда мы работаем всего с 6 языками и 36 парами, есть много тонкостей обучения, которые стоит учитывать.
Beyond English-Centric Multilingual Machine Translation
Fan et al. [Facebook]
arxiv.org/abs/2010.11125
1. LASER-вектора находят предложения, которые являются переводами друг друга
1. Пары майнятся из отсеянных через правила и LASER пар документов
1. Преимущественно ищутся предложения между языками из одной группы и для bridge languages, которые эти группы соединяют
1. Прменяеют backtranslation для пар, где данных меньше всгео
В результате получили датасет на 100 языков и 2200 направлений первода, 7.5B предложений.
На всём этом обучется модель размером 1.2B параметров, для этого применяются много технических хитростей для распараллеливания на GPU, в том числе модификации архитектуры трансформера. Также заметили, что от большего числа языковых пар расширяется количество данных, доступных для низкоресурсных языков. Благодаря этому пара английский-белорусский улучшилась с 3 до 13 BLEU.
Complete Multilingual Neural Machine Translation
Freitag and Firat [Google]
https://arxiv.org/abs/2010.10239
Датасет: UN, 6 языков, для которых есть паралелльные данные, но для некоторых пар их мало.
Показали, что стандартный способ семплинга примеров при тренировке, у учётом частоты языковых пар, на самом деле семплирует больше английского, чем нужно (тк у английского много пар со всеми). Предложили новый вид семплинга, который зависит не от пары, а от языка.
Обычно проблема мультиязычных моделей заключается в том, что высокоресурсные языки теряют в качестве по сравнению с двуязычным бейзлайном. Интересный результат этой статьи, что если использовать правильный семплинг и большое число языковых пар, этого эффекта не наблюдается. Показали это на UN (36 пар) и на внутреннем датасете (20 тысяч пар).
Сейчас им приходится часто делать zero-shot. Условно, модель может перевести с индонезийского на татарский, несмотря на то, что на такой языковой паре не обучалась. Энкодер мапит все языки в единое пространство, а декодер умеет из этого пространства декодить (Wu et al, 2016). Но получается так себе.
Мы знаем, что лучшее решение zero-shot задач - это найти нормальный датасет, где не придётся заниматься zero-shot. Facebook в своей статье намайнил такой датасет для 2 тысяч пар языков, а Google показал что даже когда мы работаем всего с 6 языками и 36 парами, есть много тонкостей обучения, которые стоит учитывать.
Beyond English-Centric Multilingual Machine Translation
Fan et al. [Facebook]
arxiv.org/abs/2010.11125
1. LASER-вектора находят предложения, которые являются переводами друг друга
1. Пары майнятся из отсеянных через правила и LASER пар документов
1. Преимущественно ищутся предложения между языками из одной группы и для bridge languages, которые эти группы соединяют
1. Прменяеют backtranslation для пар, где данных меньше всгео
В результате получили датасет на 100 языков и 2200 направлений первода, 7.5B предложений.
На всём этом обучется модель размером 1.2B параметров, для этого применяются много технических хитростей для распараллеливания на GPU, в том числе модификации архитектуры трансформера. Также заметили, что от большего числа языковых пар расширяется количество данных, доступных для низкоресурсных языков. Благодаря этому пара английский-белорусский улучшилась с 3 до 13 BLEU.
Complete Multilingual Neural Machine Translation
Freitag and Firat [Google]
https://arxiv.org/abs/2010.10239
Датасет: UN, 6 языков, для которых есть паралелльные данные, но для некоторых пар их мало.
Показали, что стандартный способ семплинга примеров при тренировке, у учётом частоты языковых пар, на самом деле семплирует больше английского, чем нужно (тк у английского много пар со всеми). Предложили новый вид семплинга, который зависит не от пары, а от языка.
Обычно проблема мультиязычных моделей заключается в том, что высокоресурсные языки теряют в качестве по сравнению с двуязычным бейзлайном. Интересный результат этой статьи, что если использовать правильный семплинг и большое число языковых пар, этого эффекта не наблюдается. Показали это на UN (36 пар) и на внутреннем датасете (20 тысяч пар).
Forwarded from DeepPavlov notifications
Всем привет 😃
В прошлый четверг состоялся открытый семинар нашей лаборатории, на котором Анна Роджерс представила бертологический доклад: “When BERT plays the lottery, all tickets are winning!”
The lottery ticket hypothesis was originally developed for randomly initialized models, but might it also apply to pre-trained Transformers? If the “good” subnetworks exist, can they tell us anything about how BERT achieves its performance?
The original paper can be found here https://arxiv.org/pdf/2005.00561
Для тех, кто пропустил доклад, доступна запись по 👉 ссылке.
В прошлый четверг состоялся открытый семинар нашей лаборатории, на котором Анна Роджерс представила бертологический доклад: “When BERT plays the lottery, all tickets are winning!”
The lottery ticket hypothesis was originally developed for randomly initialized models, but might it also apply to pre-trained Transformers? If the “good” subnetworks exist, can they tell us anything about how BERT achieves its performance?
The original paper can be found here https://arxiv.org/pdf/2005.00561
Для тех, кто пропустил доклад, доступна запись по 👉 ссылке.
YouTube
Seminar #3. When BERT plays the lottery, all tickets are winning!
In the talk, Anna Rogers presented the paper: When BERT plays the lottery, all tickets are winning!
The lottery ticket hypothesis was originally developed for randomly initialized models, but might it also apply to pre-trained Transformers? If the “good”…
The lottery ticket hypothesis was originally developed for randomly initialized models, but might it also apply to pre-trained Transformers? If the “good”…
F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax
Choi et al.
arxiv.org/abs/2009.09417
TL;DR
Представили новый метод обучения языковых моделей, которые генерируют более разнообразный текст - чаще используют средне и низкочастоные слова. Для этого вместо рассчёта одного софтмакса, считается K+1 софтмакс где один из них подсчитан на всем словаре, а K - на группах высоко/средне/низкочастотных слов (слова разбиты на K групп по частоте). Финальная вероятность получается равна произведению софтмакса со всем словарём на софтмакс, где есть вероятность требуемого слова.
Плюс придумали новый метод семплинга, учитывающего энтропию языка. В результате более хорошие Distinct и другие метрики разнообразности при довольно хорошей перплексии. Также частота геренируемых высоко/средне/низкочастотных токенов гораздо ближе к человеческой.
Choi et al.
arxiv.org/abs/2009.09417
TL;DR
Представили новый метод обучения языковых моделей, которые генерируют более разнообразный текст - чаще используют средне и низкочастоные слова. Для этого вместо рассчёта одного софтмакса, считается K+1 софтмакс где один из них подсчитан на всем словаре, а K - на группах высоко/средне/низкочастотных слов (слова разбиты на K групп по частоте). Финальная вероятность получается равна произведению софтмакса со всем словарём на софтмакс, где есть вероятность требуемого слова.
Плюс придумали новый метод семплинга, учитывающего энтропию языка. В результате более хорошие Distinct и другие метрики разнообразности при довольно хорошей перплексии. Также частота геренируемых высоко/средне/низкочастотных токенов гораздо ближе к человеческой.
Forwarded from ODS Events
На Data Ёлке 🎄вас ждёт много интересного!
19 декабря в 15:00 в прямом эфире будут подведены итоги первого цикла технологического конкурса Up Great «ПРО//ЧТЕНИЕ», направленного на преодоление технологического барьера в области машинной обработки естественного языка. 🗣
Задача конкурса — создать системы искусственного интеллекта для выявления смысловых, логических и фактических ошибок в текстах на русском и английском языках. Чтобы победить в конкурсе и выиграть приз в 100 млн руб. 🤑, алгоритм должен справиться с задачей не хуже преподавателя. Испытания конкурса проводятся регулярно до тех пор, пока одна из команд не покажет результат, соответствующий способностям человека, но не позднее конца 2022 года.
Возможно, ещё не поздно принять участие — узнаем в субботу в 15:00. 🗓
Следите за дальнейшими анонсами - вас ждут приятные сюрпризы! 😉
19 декабря в 15:00 в прямом эфире будут подведены итоги первого цикла технологического конкурса Up Great «ПРО//ЧТЕНИЕ», направленного на преодоление технологического барьера в области машинной обработки естественного языка. 🗣
Задача конкурса — создать системы искусственного интеллекта для выявления смысловых, логических и фактических ошибок в текстах на русском и английском языках. Чтобы победить в конкурсе и выиграть приз в 100 млн руб. 🤑, алгоритм должен справиться с задачей не хуже преподавателя. Испытания конкурса проводятся регулярно до тех пор, пока одна из команд не покажет результат, соответствующий способностям человека, но не позднее конца 2022 года.
Возможно, ещё не поздно принять участие — узнаем в субботу в 15:00. 🗓
Следите за дальнейшими анонсами - вас ждут приятные сюрпризы! 😉
{kind=link}