Understanding the Difficulty of Training Transformers
Liu et al. [Microsoft]
arxiv.org/abs/2004.08249
Всё больше статей про анализ трансформеров, мне нравится эта тенденция.
В этой статье рассказывают про два интересных момента.
1. Вроде бы трансформеры не страдают от gradient vanishing/explosion, скорее всего благодаря residual connections (см. картинку)
2. Из-за этих же redidual connections трансформеры могут быт очень неустойчивы по параметрам. То есть небольшое изменение параметров может вызывать большое изменение предсказаний трансформера. Авторы называют это amplificaiton effect и показывают, что он сильно мешает обучению.
Также в статье предлагается хитрый способ инициализации (Admin), чтобы уменьшить amplification effect в начале обучения. Этот метод позволяет улучшить финальное качество модельки и тренировать более глубокие сети.
Статья читается не очень легко, но наверняка если закопаться поглубже можно найти ещё пару интересных вещей.
Liu et al. [Microsoft]
arxiv.org/abs/2004.08249
Всё больше статей про анализ трансформеров, мне нравится эта тенденция.
В этой статье рассказывают про два интересных момента.
1. Вроде бы трансформеры не страдают от gradient vanishing/explosion, скорее всего благодаря residual connections (см. картинку)
2. Из-за этих же redidual connections трансформеры могут быт очень неустойчивы по параметрам. То есть небольшое изменение параметров может вызывать большое изменение предсказаний трансформера. Авторы называют это amplificaiton effect и показывают, что он сильно мешает обучению.
Также в статье предлагается хитрый способ инициализации (Admin), чтобы уменьшить amplification effect в начале обучения. Этот метод позволяет улучшить финальное качество модельки и тренировать более глубокие сети.
Статья читается не очень легко, но наверняка если закопаться поглубже можно найти ещё пару интересных вещей.
{kind=link}
A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation
Shen et al. [Microsoft]
arxiv.org/abs/2009.13818
В NLP аугментации как-то до сих пор не заходят, я виню в этом людей, которые считают, что аугментированные тексты должны быть грамматически корректными. Но Shen et. al решили что это bs и попробовали следующее. Возьмём входные в BERT эмбеддинги, матричку размера
Теперь немного про подробности. В отличие от обычных аугментаций в CV в этой статье использовали несколько аугментаций каждого примера внутри батча. То есть у вас есть K примеров на входе, вы аугментируете их каждый N раз и получаете батч размера K*N, который вы и прогоняете через вашу нейросетку. Плюс к этому ауторы добавили регуляризатор, который заставлял модель предсказывать одинаковые распределения у различных аугментаций одного и того же примера (но судя по ablation studies эта штука очень мало докидывает).
Shen et al. [Microsoft]
arxiv.org/abs/2009.13818
В NLP аугментации как-то до сих пор не заходят, я виню в этом людей, которые считают, что аугментированные тексты должны быть грамматически корректными. Но Shen et. al решили что это bs и попробовали следующее. Возьмём входные в BERT эмбеддинги, матричку размера
seq_len x emb_dim и будем случайно занулять в ней (вектора целых слов) или строки (фичи). В качестве третьего подходя предлогают занулять несколько последовательно идущих слов. Идея мега простая, однако в среднем этот метод добавляет примерно 0.5 пункта на GLUE. В случае маленького датасета RTE аугментации улучили 78.7 до 82.3, что очень заметно. И главное, почти бесплатно.Теперь немного про подробности. В отличие от обычных аугментаций в CV в этой статье использовали несколько аугментаций каждого примера внутри батча. То есть у вас есть K примеров на входе, вы аугментируете их каждый N раз и получаете батч размера K*N, который вы и прогоняете через вашу нейросетку. Плюс к этому ауторы добавили регуляризатор, который заставлял модель предсказывать одинаковые распределения у различных аугментаций одного и того же примера (но судя по ablation studies эта штука очень мало докидывает).
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
Schick and Schütze, [LMU Munich]
arxiv.org/abs/2009.07118
🔥статья. Идея довольно простая: что если мы попробуем использовать языковые модели для few-shot learning более изощрённым образом? Авторы GPT-3 предлагали делать следующее: подавать несколько примеров в максимально простом виде вопрос1-ответ1 вопрос2-ответ2 вопрос3- и вот "ответ3" и должна была сгенерить LM. Очень просто и красиво, но наверняка неэффективно;
Авторы этой статьи предлагают многоступенчатый подход:
1. Под нашу задачку мы составляем несколько pattern-verbalizer pairs. Паттерн это по сути какой-то вопрос, а verbalizer - это ограниченный сет ответов на этот вопрос (e.g. yes/no). Например под задачу entailment паттерн может быть
2. Дальше мы используя размеченные примеры и составленные патерны файнтюним MLM. А точнее даже несколько MLM, чтобы потом составить ансамбль.
3. Проводим дистилляцию этого ансамбля на soft лейблах (вероятностях, а не классах). Получаем перфоманс сопоставимый с самым большим GPT-3 🦾
От себя хочу добавить идеологических отличий от GPT:
1. Надо обучать модельку (даже несколько моделек)
1. Есть ручная работа по созданию PVP pairs
1. Нужны дополнительные тексты на которых вы будете дисстилировать
Но несмотря на это, подход кажется очень рабочим и применимым в реальных задачах. Советую почитать статью подробнее, там должно быть много дополнительных интересных деталей.
Schick and Schütze, [LMU Munich]
arxiv.org/abs/2009.07118
🔥статья. Идея довольно простая: что если мы попробуем использовать языковые модели для few-shot learning более изощрённым образом? Авторы GPT-3 предлагали делать следующее: подавать несколько примеров в максимально простом виде вопрос1-ответ1 вопрос2-ответ2 вопрос3- и вот "ответ3" и должна была сгенерить LM. Очень просто и красиво, но наверняка неэффективно;
Авторы этой статьи предлагают многоступенчатый подход:
1. Под нашу задачку мы составляем несколько pattern-verbalizer pairs. Паттерн это по сути какой-то вопрос, а verbalizer - это ограниченный сет ответов на этот вопрос (e.g. yes/no). Например под задачу entailment паттерн может быть
<sentence1>? \[MASK], <sentence2>, а в качестве verbalizer класс entailment мапится на yes, а not-entailment мапится на no (пример на картинке). MLM выдаёт вам вероятности слов на месте [MASK] и вы сравниваете вероятность слов yes и no.2. Дальше мы используя размеченные примеры и составленные патерны файнтюним MLM. А точнее даже несколько MLM, чтобы потом составить ансамбль.
3. Проводим дистилляцию этого ансамбля на soft лейблах (вероятностях, а не классах). Получаем перфоманс сопоставимый с самым большим GPT-3 🦾
От себя хочу добавить идеологических отличий от GPT:
1. Надо обучать модельку (даже несколько моделек)
1. Есть ручная работа по созданию PVP pairs
1. Нужны дополнительные тексты на которых вы будете дисстилировать
Но несмотря на это, подход кажется очень рабочим и применимым в реальных задачах. Советую почитать статью подробнее, там должно быть много дополнительных интересных деталей.
Посмотрел в свои сохранённые сообщения и оказалось, что есть много интересного. Поэтому одной стокой.
NLP:
1. The ultimate guide to encoder-decoder models (part1, part2, part3, part4)
1. Миникурс по вариационному выводу в NLP от Wilker Aziz
1. Long Range Arena : A Benchmark for Efficient Transformers - статья, где сравнивают между собой длинные трансформеры (спойлер: используйте Big Bird если не важна скорость и Performer если важна, не используйте Reformer вообще)
1. Nearest Neighbor Machine Translation - +2 BLEU почти бесплатно к вашей уже натренированной модели. Вы предварительно создаёте базу переводов (на основе вашего тренировочного сета) и примешиваете её хиддены к своим во время инференса.
1. RL + NLP + текстовые игры = ❤️, в статье учили бота, обусловленного некой мотивацией, заданной описанием персоны, проходить квесты
1. Multi-Modal Open-Domain Dialogue - статья от группы Jason Weston в FAIR в которой фьюзят огромные языковые модели и Faster R-CNN. Очень подробно описано как тестировали модель, что очень сложно в диалоговых задачах.
not NLP:
1. Вышла новая версия курса по RL от Thomas Simonini, теперь есть более весёлые environment'ы на Unity и UE4
1. Как делать ограничения на параметры в вашей моделе на торче (вдруг вы заходите, чтобы ваши матрицы были строго положительными). Чтение поста гарантирует улучшение вашего скила на pytorch (или нет)
1. An Image is Worth 16x16 Words - Полностью трансформерная сетка для computer vision (совсем без свёрток), которая не только работает лучше, но и тренируется в 5 раз быстрее
NLP:
1. The ultimate guide to encoder-decoder models (part1, part2, part3, part4)
1. Миникурс по вариационному выводу в NLP от Wilker Aziz
1. Long Range Arena : A Benchmark for Efficient Transformers - статья, где сравнивают между собой длинные трансформеры (спойлер: используйте Big Bird если не важна скорость и Performer если важна, не используйте Reformer вообще)
1. Nearest Neighbor Machine Translation - +2 BLEU почти бесплатно к вашей уже натренированной модели. Вы предварительно создаёте базу переводов (на основе вашего тренировочного сета) и примешиваете её хиддены к своим во время инференса.
1. RL + NLP + текстовые игры = ❤️, в статье учили бота, обусловленного некой мотивацией, заданной описанием персоны, проходить квесты
1. Multi-Modal Open-Domain Dialogue - статья от группы Jason Weston в FAIR в которой фьюзят огромные языковые модели и Faster R-CNN. Очень подробно описано как тестировали модель, что очень сложно в диалоговых задачах.
not NLP:
1. Вышла новая версия курса по RL от Thomas Simonini, теперь есть более весёлые environment'ы на Unity и UE4
1. Как делать ограничения на параметры в вашей моделе на торче (вдруг вы заходите, чтобы ваши матрицы были строго положительными). Чтение поста гарантирует улучшение вашего скила на pytorch (или нет)
1. An Image is Worth 16x16 Words - Полностью трансформерная сетка для computer vision (совсем без свёрток), которая не только работает лучше, но и тренируется в 5 раз быстрее
{kind=link}
{kind=link}
Хороший и объемный туториал по файнтюнингу моделек в NLP.
• Loading data, single or multiple files, csv, txt or dataframes, train/test splits
• Processing data with 11 text processing functions
• Tokenizing data for use with MobileBERT
• Saving processed data to disk
• Datasets tips and tricks along the way
Comprehensive Language Model Fine Tuning
• Loading data, single or multiple files, csv, txt or dataframes, train/test splits
• Processing data with 11 text processing functions
• Tokenizing data for use with MobileBERT
• Saving processed data to disk
• Datasets tips and tricks along the way
Comprehensive Language Model Fine Tuning
ntentional
Comprehensive Language Model Fine Tuning, Part 1: 🤗 Datasets library [Updated]
Get your data ready to train with the 🤗 Datasets library, plus Datasets implementation tips and tricks
Firing a cannon at sparrows: BERT vs. logreg (DataFest 2020)
Презентация от Юры Кашницкого по BERT и тому как использовать его с Catalyst. А так же о том, что логрег всё ещё тащит для простых задач классификации.
Презентация от Юры Кашницкого по BERT и тому как использовать его с Catalyst. А так же о том, что логрег всё ещё тащит для простых задач классификации.
YouTube
Yury Kashnitsky - Firing a cannon at sparrows: BERT vs. logreg (DataFest 2020)
There is a Golden Rule in NLP, at least when it comes to classification tasks: “Always start with a tfidf-logreg baseline”. Elaborating a bit, that’s building a logistic regression model on top of tf-idf (term frequency - inverse document frequency) text…
Рубрика «Читаем статьи за вас». Июль — август 2020 года
Статьи из подборки:
1 High-Resolution Neural Face Swapping for Visual Effects
2. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
3. Thieves on Sesame Street! Model Extraction of BERT-based APIs
4. Time-Aware User Embeddings as a Service
5. Are Labels Necessary for Neural Architecture Search?
6. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
7. Data Shapley: Equitable Valuation of Data for Machine Learning
8. Language-agnostic BERT Sentence Embedding
9. Self-Supervised Learning for Large-Scale Unsupervised Image Clustering
10. Batch-Channel Normalization and Weight Standardization
Статьи из подборки:
1 High-Resolution Neural Face Swapping for Visual Effects
2. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
3. Thieves on Sesame Street! Model Extraction of BERT-based APIs
4. Time-Aware User Embeddings as a Service
5. Are Labels Necessary for Neural Architecture Search?
6. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
7. Data Shapley: Equitable Valuation of Data for Machine Learning
8. Language-agnostic BERT Sentence Embedding
9. Self-Supervised Learning for Large-Scale Unsupervised Image Clustering
10. Batch-Channel Normalization and Weight Standardization
Хабр
Рубрика «Читаем статьи за вас». Июль — август 2020 года
Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше вс...
Возможно, лучшая визуализация того, как работает трансформер. Во всех примерах визуализировано в том числе и батч-измерение. И ноутбучек прилагается.
https://github.com/mertensu/transformer-tutorial
https://github.com/mertensu/transformer-tutorial
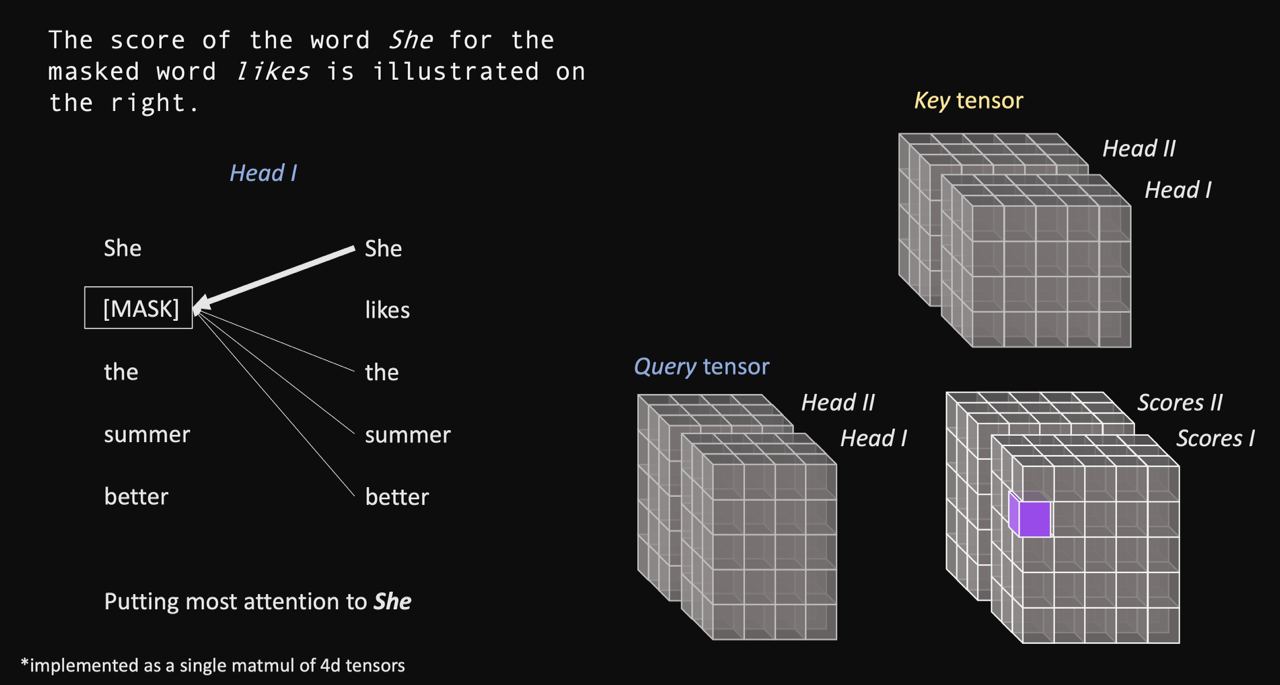{kind=link}
QA модельки очень интересные, и классно, что они всё больше просачиваются в реальную жизнь. @sparakhin рассказывает как они разрабатывали такую модель для магазина фотовидеотехники. Собирание датасета, USE, берты, дисстиляция - всё как вы любите. Думаю если будут вопросы, можете даже поспрашивать автора в нашем чате.
Его словами про пост:
"Мы тут рассказываем про то, как применяли QA (MRC) модельки для своего домена — photo & video cameras online store. Рассказываем немного про модельку, как размечали данные, файнтюнили, и ускоряли (деталей возможно не так много как хотелось бы, так как статья в корпоративном блоге).
Возможно что-то будет интересно, например, как мы использовали knowledge distillation для неразмеченных данных + в конце полезные ссылки по теме."
https://blog.griddynamics.com/question-answering-system-using-bert
Его словами про пост:
"Мы тут рассказываем про то, как применяли QA (MRC) модельки для своего домена — photo & video cameras online store. Рассказываем немного про модельку, как размечали данные, файнтюнили, и ускоряли (деталей возможно не так много как хотелось бы, так как статья в корпоративном блоге).
Возможно что-то будет интересно, например, как мы использовали knowledge distillation для неразмеченных данных + в конце полезные ссылки по теме."
https://blog.griddynamics.com/question-answering-system-using-bert
YouTube
Grid Dynamics – Camera Question-Answer Demo
Is it possible for language models to achieve language understanding? My current answer is, essentially, “Well, we don’t currently have compelling reasons to think they can’t.”
То ли это происходит из-за хайпа, то ли из-за действительно необычных результатов BERT и GPT-2, но стало появляться всё больше и больше рассуждений на тему того, могут ли эти модели добиться "понимания языка". Как всегда проблема тут в определениях – мы не знаем, что такое "понимать".
Раньше у нас были какие-то мысленные эксперименты типа теста тьюринга, или китайской комнаты, но сейчас обе эти задачи если и не решены, то довольно хорошо сходятся к своим решениям. GLUE был очередной попыткой оценивать то, насколько модели "понимают" язык, но BERT его досольно быстро сломал, и сейчас датасет по сути просто используется как стандартный бенчмарк. Потом пришёл GPT-2 и выполнил фаталити, тк показал, что в принципе просто большая языковая модель может решать любые NLP задачи без дополнительной тренировки. GPT-3 показал, что мы даже можем добиваться около-SOTA результатов, опять же – без какой-либо дополнительной тренировки.
Сегодня, в ruder newsletter #53 я наткнулся на две интересных статьи. Первая из них (ACL) очень громко утверждает, что языковые модели не могут понимать смысл и приводит мысленный эксперимент, который иллюстрирует их идею. Вторая (Medium) говорит, что у нас может быть и есть какие-то представления о том, что такое "смысл" и понимание, но они слишком расплывчатые и противоречивые, чтобы мы могли утверждать, что язык это что-то большее, чем языковая модель. Например в первой статье авторы сделали то, что я бы назвал "доказательство определением", где сами термины форма и смысл были подобраны так, чтобы языковые модели (которые тренируются только на форме, по опредлению) не могут понять смысл, который в свою очередь (по определению) что-то что нельзя получить из формы.
Несмотря на это странное начало, я бы рекомендовал почитать обе статьи - будет ещё одна тема, на которую можно пофилософствовать за чашечкой кофе или не кофе.
То ли это происходит из-за хайпа, то ли из-за действительно необычных результатов BERT и GPT-2, но стало появляться всё больше и больше рассуждений на тему того, могут ли эти модели добиться "понимания языка". Как всегда проблема тут в определениях – мы не знаем, что такое "понимать".
Раньше у нас были какие-то мысленные эксперименты типа теста тьюринга, или китайской комнаты, но сейчас обе эти задачи если и не решены, то довольно хорошо сходятся к своим решениям. GLUE был очередной попыткой оценивать то, насколько модели "понимают" язык, но BERT его досольно быстро сломал, и сейчас датасет по сути просто используется как стандартный бенчмарк. Потом пришёл GPT-2 и выполнил фаталити, тк показал, что в принципе просто большая языковая модель может решать любые NLP задачи без дополнительной тренировки. GPT-3 показал, что мы даже можем добиваться около-SOTA результатов, опять же – без какой-либо дополнительной тренировки.
Сегодня, в ruder newsletter #53 я наткнулся на две интересных статьи. Первая из них (ACL) очень громко утверждает, что языковые модели не могут понимать смысл и приводит мысленный эксперимент, который иллюстрирует их идею. Вторая (Medium) говорит, что у нас может быть и есть какие-то представления о том, что такое "смысл" и понимание, но они слишком расплывчатые и противоречивые, чтобы мы могли утверждать, что язык это что-то большее, чем языковая модель. Например в первой статье авторы сделали то, что я бы назвал "доказательство определением", где сами термины форма и смысл были подобраны так, чтобы языковые модели (которые тренируются только на форме, по опредлению) не могут понять смысл, который в свою очередь (по определению) что-то что нельзя получить из формы.
Несмотря на это странное начало, я бы рекомендовал почитать обе статьи - будет ещё одна тема, на которую можно пофилософствовать за чашечкой кофе или не кофе.
newsletter.ruder.io
ML and NLP starter toolkit, Low-resource NLP toolkit, "Can a LM understand natural language?", The next generation of NLP benchmarks
Hi all,It has been a while... I hope you're doing well in these crazy and strange times.COVID-19 has affected each of us in unpredictable ways 😷. I'm fortunate to be healthy but my energy has been lower overall ⚡️. Coupled with life and work keeping me busy…
Сбер обучил русский GPT 🎉
Большие модельки потихоньку продвигаются и в русский язык. О цифрах:
1. 600Гб текстов – Omnia Russica+пикабу+22centry+banki.ru
1. GPT-Large на 700млн параметров. Кстати это меньше, чем самый большой GPT-2, но зато помещается в память.
1. 128 V100, тренировали 2 недели на Christophari. В Google Cloud такое стоило бы примерно $100 тысяч.
Из статьи интересно, что оказывается, сбер уже использует GPT в проде для болталки. Очень смело, но зато теперь можно ждать лулзов и историй про то, как кого-то очень изощнённо куда-то послала колонка сбера.
Что грустно, это то, что модельку не поэвалюировали на прикладных задачах классификации/перевода итд (в чём собственно и заключается вся соль GPT-N, N>1).
Пример генерации:
Context: на словах ты лев толстой
ruGPT3Large: а в сущности, - ты тоже не дурак, просто так же, как и твой человек, то есть твоя "жизнь", а также как и ты думаешь по-настоящему "ты" и есть твои "жизнь" или "выбор" в отношении твоего положения.
Всё это добро доступно через Transformers (huggingface.co/sberbank-ai), код есть на гитхабе, в посте ещё сказали про то, что почищенный датасет тоже должен быть доступен, но я его не нашёл.
Большие модельки потихоньку продвигаются и в русский язык. О цифрах:
1. 600Гб текстов – Omnia Russica+пикабу+22centry+banki.ru
1. GPT-Large на 700млн параметров. Кстати это меньше, чем самый большой GPT-2, но зато помещается в память.
1. 128 V100, тренировали 2 недели на Christophari. В Google Cloud такое стоило бы примерно $100 тысяч.
Из статьи интересно, что оказывается, сбер уже использует GPT в проде для болталки. Очень смело, но зато теперь можно ждать лулзов и историй про то, как кого-то очень изощнённо куда-то послала колонка сбера.
Что грустно, это то, что модельку не поэвалюировали на прикладных задачах классификации/перевода итд (в чём собственно и заключается вся соль GPT-N, N>1).
Пример генерации:
Context: на словах ты лев толстой
ruGPT3Large: а в сущности, - ты тоже не дурак, просто так же, как и твой человек, то есть твоя "жизнь", а также как и ты думаешь по-настоящему "ты" и есть твои "жизнь" или "выбор" в отношении твоего положения.
Всё это добро доступно через Transformers (huggingface.co/sberbank-ai), код есть на гитхабе, в посте ещё сказали про то, что почищенный датасет тоже должен быть доступен, но я его не нашёл.
tokenizer = AutoTokenizer.from_pretrained("sberbank-ai/rugpt3large_based_on_gpt2")
model = AutoModel.from_pretrained("sberbank-ai/rugpt3large_based_on_gpt2")Хабр
Сбер выложил русскоязычную модель GPT-3 Large с 760 миллионами параметров в открытый доступ
Последнее десятилетие в области компьютерных технологий ознаменовалось началом новой «весны искусственного интеллекта». Впрочем, ситуацию в индустрии в наши дни...
mT5: A massively multilingual pre-trained text-to-text transformer
Xue et al. [Google]
arxiv.org/abs/2010.11934
Продолжение идей T5, но теперь не только для английского. Напомним, что T5 это seq2seq моделька обученная на вариации MLM (SpanBERT), которая при файнтюнинге всё ещё остаётся seq2seq даже для задач классификации (моделька учится предсказывать слово, обозначающее класс). Ещё она огромная, до этого уже можно было догадаться.
Так вот для mT5 - мультиязычной версии T5 собрали датасет mC4 размером в 6 триллионов слов, что вроде бы должно весить около 12Tb (а помните, когда One Billion Words считался большим датасетом?). Что важно, это то, что в этом датасете содержится более 100 языков и что там на удивление много неанглийского, а русский вообще стоит на втором месте. В результате на всём этом обучается новая моделька в 13 миллиардов параметров и она обходит все текущие модели на мультиязычных датасетах, даже включая XLM(-R), при тренировке которых использовались параллельные данные и обходит довольно значительно (в среднем на 2-3 пункта).
Сама статья довольно скучная, по сути в этом TL;DR она вся и описана. Зато код выложен и модельки тоже, жалко что не в 🤗-формате. Где вы правда будете их запускать - это отдельный вопрос.
За наводку на статью спасибо @someotherusername
Xue et al. [Google]
arxiv.org/abs/2010.11934
Продолжение идей T5, но теперь не только для английского. Напомним, что T5 это seq2seq моделька обученная на вариации MLM (SpanBERT), которая при файнтюнинге всё ещё остаётся seq2seq даже для задач классификации (моделька учится предсказывать слово, обозначающее класс). Ещё она огромная, до этого уже можно было догадаться.
Так вот для mT5 - мультиязычной версии T5 собрали датасет mC4 размером в 6 триллионов слов, что вроде бы должно весить около 12Tb (а помните, когда One Billion Words считался большим датасетом?). Что важно, это то, что в этом датасете содержится более 100 языков и что там на удивление много неанглийского, а русский вообще стоит на втором месте. В результате на всём этом обучается новая моделька в 13 миллиардов параметров и она обходит все текущие модели на мультиязычных датасетах, даже включая XLM(-R), при тренировке которых использовались параллельные данные и обходит довольно значительно (в среднем на 2-3 пункта).
Сама статья довольно скучная, по сути в этом TL;DR она вся и описана. Зато код выложен и модельки тоже, жалко что не в 🤗-формате. Где вы правда будете их запускать - это отдельный вопрос.
За наводку на статью спасибо @someotherusername
GitHub
GitHub - google-research/multilingual-t5
Contribute to google-research/multilingual-t5 development by creating an account on GitHub.
Data Augmentation in NLP: Best Practices From a Kaggle Master
Очень давно ждал чего-то такого. Готовая библиотека для аугментаций в NLP. Как правило завести аугментации текстов сложно и эффект от них слишком малый, чтобы прямо заниматься этим. А теперь вроде бы можно в пару строчек кода.
Например, если вы хотите докинуть контекстных синонимов с помощью берта, то можете сделать так:
Это может выдать что-то такое:
Так что давайте все выполняем
Ссылка на гитхаб библиотеки
Ссылка на документацию
Очень давно ждал чего-то такого. Готовая библиотека для аугментаций в NLP. Как правило завести аугментации текстов сложно и эффект от них слишком малый, чтобы прямо заниматься этим. А теперь вроде бы можно в пару строчек кода.
Например, если вы хотите докинуть контекстных синонимов с помощью берта, то можете сделать так:
import nlpaug.augmenter.word as naw
aug = naw.ContextualWordEmbsAug(model_path='bert-base-uncased', action='insert')
augmented_text = aug.augment('this is a text')Это может выдать что-то такое:
this is currently a text
Что довольно неплохо с учётом того, что вы сделали это в три строчки кода включая импорт.Так что давайте все выполняем
pip install nlpaug и играемся с этим.Ссылка на гитхаб библиотеки
Ссылка на документацию
neptune.ai
Data Augmentation in NLP: Best Practices From a Kaggle Master
Insights on NLP data augmentation techniques, contrasts with vision, and best practices from a Kaggle master.
Example-Driven Intent Prediction with Observers
Mehri et al. [Amazon]
arxiv.org/abs/2010.08684
Интересная статья по классификации текста. В статье две идеи: example-driven prediction и observers.
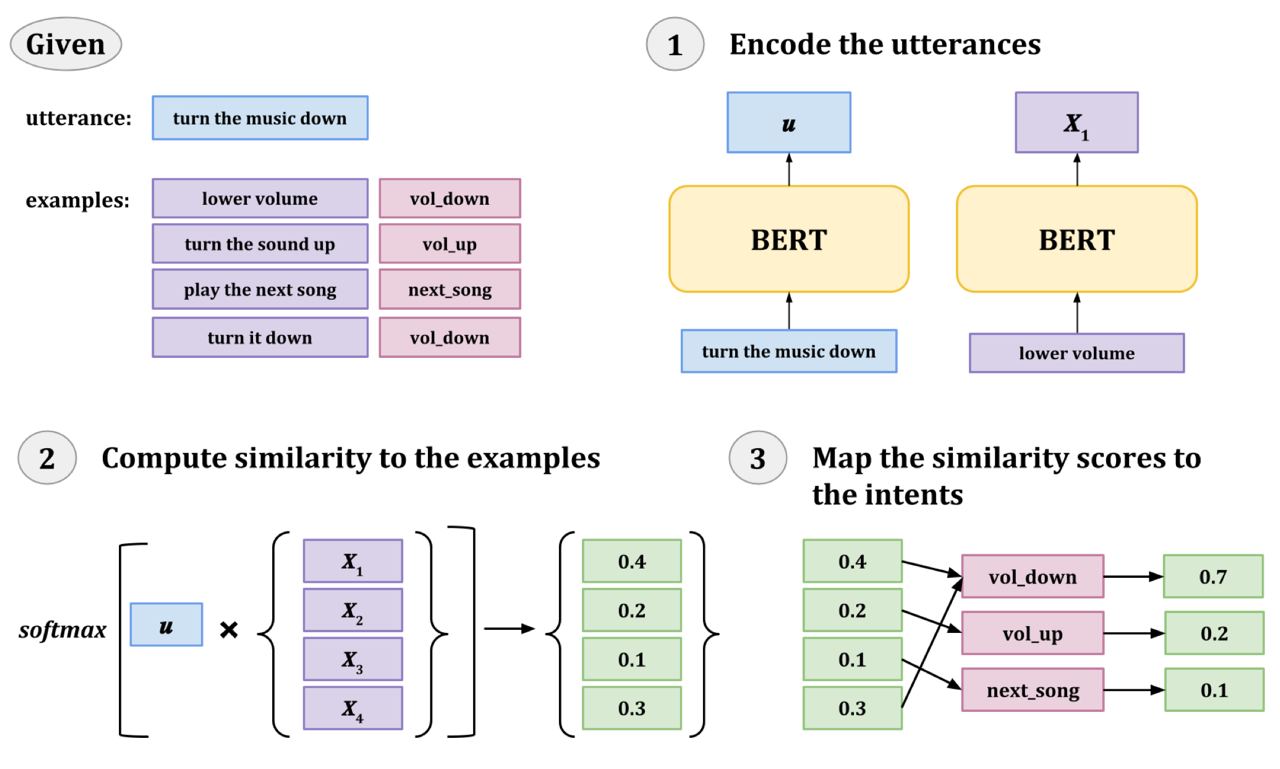
Example-driven prediction: давайте не будем делать выходной слой сетки (голову BERT) и вместо этого возьмём представление CLS токена и посравниваем его с небольшим числом примеров из нашего датасета. Получим similarity scores, потом засофтмаксим их - таким образом мы получим вероятности того, что input имеет тот же класс, что и каждый из примеров. А классы примеров мы знаем. Последний шаг - сложить one-hot вектора классов каждого примера с весами вероятностей из предыдушего шага. На выходе получим вероятность каждого класса. Идея изображена на картинке снизу.
Почему это интересно, это потому что мы не добавляем параметры в BERT и трениуем только сам трансформер, что забавно. Но вторая причина ещё интереснее - после такого обучения сетки мы можем делать инференс на классах, которых в обучающей выборке не было. По сути сетка ведь просто учит хорошую метрику. Идея подхода похожа на такой "гладкий" KNN.
Observers: мы знаем, что CLS часто смотрит сам на себя. Мы также знаем, что токены слов часто смотрят на CLS (возможно, в случаях, когда они хотят проигнорировать инпут). В результате каждый смотрит на каждого и как то это всё сложно. Авторы предлагают добавить новых вспомогательных токенов в BERT, которые будут как СLS, но, в отличие от CLS токенам слов будет запрещено на них смотреть. Таким образом observers занимаются только аггрегацией информации из векторов слов.
Результаты: используя оба метода вместе получаем SOTA на нескольких intent prediction датасетах в стандартном сетапе и в 10-shot сетапе. Не очень большое улучшение, но стабильное. Более интересные реузльтаты в предсказании интентов, отсутствующих в обучающей выборке - улучшение на десятки пунктов относительно бейзлайнов (хотя бейзлайны, конечно, кривые - нужно было сравнивать с каким-нибудь metric-learning подходом).
Mehri et al. [Amazon]
arxiv.org/abs/2010.08684
Интересная статья по классификации текста. В статье две идеи: example-driven prediction и observers.
Example-driven prediction: давайте не будем делать выходной слой сетки (голову BERT) и вместо этого возьмём представление CLS токена и посравниваем его с небольшим числом примеров из нашего датасета. Получим similarity scores, потом засофтмаксим их - таким образом мы получим вероятности того, что input имеет тот же класс, что и каждый из примеров. А классы примеров мы знаем. Последний шаг - сложить one-hot вектора классов каждого примера с весами вероятностей из предыдушего шага. На выходе получим вероятность каждого класса. Идея изображена на картинке снизу.
Почему это интересно, это потому что мы не добавляем параметры в BERT и трениуем только сам трансформер, что забавно. Но вторая причина ещё интереснее - после такого обучения сетки мы можем делать инференс на классах, которых в обучающей выборке не было. По сути сетка ведь просто учит хорошую метрику. Идея подхода похожа на такой "гладкий" KNN.
Observers: мы знаем, что CLS часто смотрит сам на себя. Мы также знаем, что токены слов часто смотрят на CLS (возможно, в случаях, когда они хотят проигнорировать инпут). В результате каждый смотрит на каждого и как то это всё сложно. Авторы предлагают добавить новых вспомогательных токенов в BERT, которые будут как СLS, но, в отличие от CLS токенам слов будет запрещено на них смотреть. Таким образом observers занимаются только аггрегацией информации из векторов слов.
Результаты: используя оба метода вместе получаем SOTA на нескольких intent prediction датасетах в стандартном сетапе и в 10-shot сетапе. Не очень большое улучшение, но стабильное. Более интересные реузльтаты в предсказании интентов, отсутствующих в обучающей выборке - улучшение на десятки пунктов относительно бейзлайнов (хотя бейзлайны, конечно, кривые - нужно было сравнивать с каким-нибудь metric-learning подходом).
{kind=link}