
Cloudflare One: непонятно
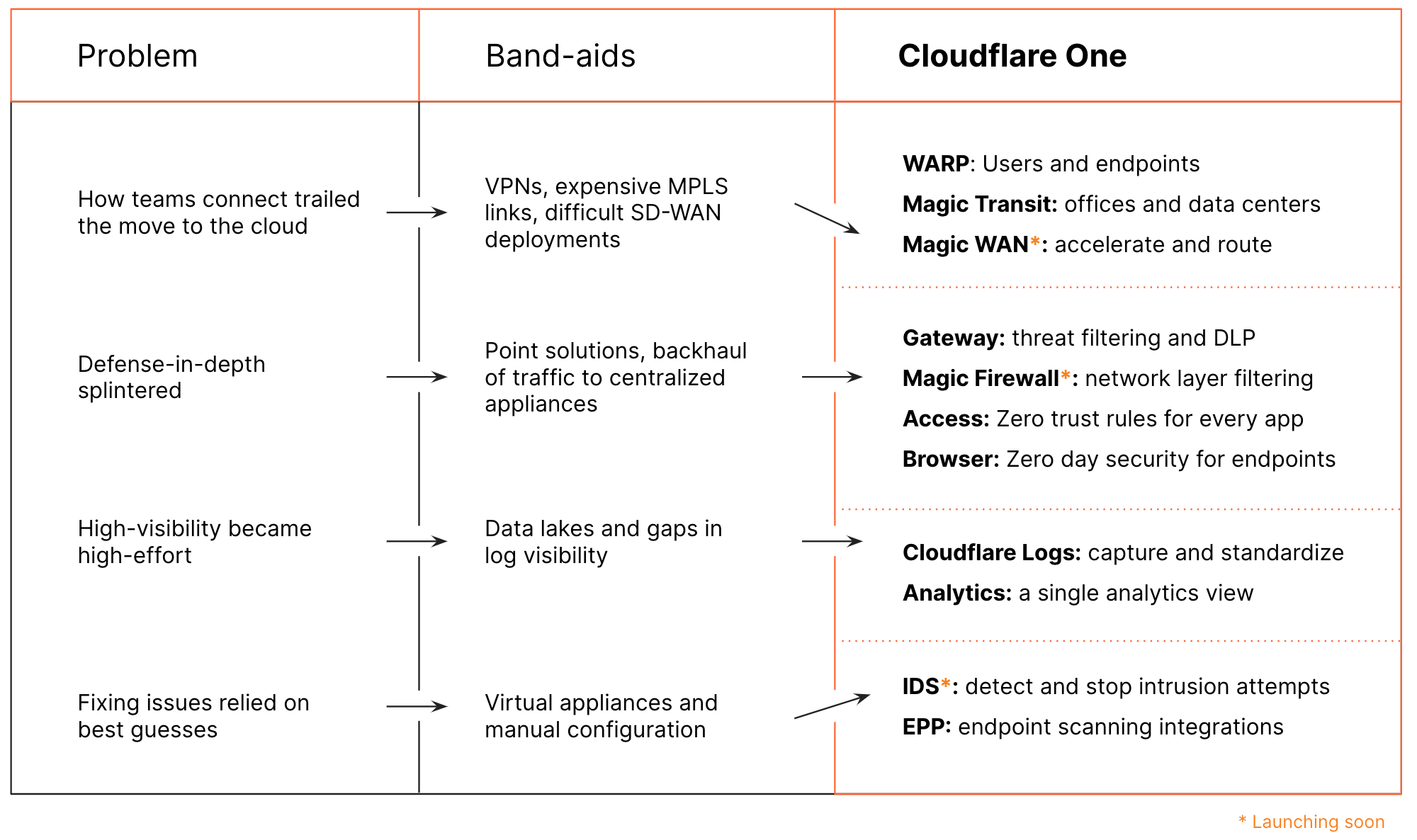
Непонятная ситуация получается: я думал что Cloudflare One - это продукт для zero-trust enterprise VPN. Оказалось, что это совсем не так: Cloudflare One - это набор продуктов под общим названием, которые вместе реализуют solution для корпоративного доступа к внутренним ресурсам.
В Cloudflare One входят:
- Cloudflare Access
- Cloudflare Gateway
- Cloudflare Magic Transit, Magic WAN, Magic Firewall, WARP
- Cloudflare Logs, Browser, Analytics
Более детально можно посмотреть в таблице:
https://blog.cloudflare.com/content/images/2020/10/image1-10.png
Все фичи стоят $14/user в месяц, как и у ближайших конкурентов.
Я честно пытался найти какой-то кейс имплементации, или найти пример каким образом это все можно слепить в кучу и построить защищенный доступ к внутренним ресурсам, но… Не нашел. В целом, интернет знает только о статье в блоге:
https://blog.cloudflare.com/cloudflare-one/
В статье есть архитектура, общее описание, и в принципе, все.
Мягко сказать - я немного разочарован, т.к. ожидал увидеть намного больше информации, доклады, презентации, сравнения с основными компетиторами - но, к сожалению, нет.
Сейчас этот бандл выглядит как альтернативный вариант реализации zero-trust access, и я надеюсь, что в ближайшем будущем он станет более прозрачным.
Непонятная ситуация получается: я думал что Cloudflare One - это продукт для zero-trust enterprise VPN. Оказалось, что это совсем не так: Cloudflare One - это набор продуктов под общим названием, которые вместе реализуют solution для корпоративного доступа к внутренним ресурсам.
В Cloudflare One входят:
- Cloudflare Access
- Cloudflare Gateway
- Cloudflare Magic Transit, Magic WAN, Magic Firewall, WARP
- Cloudflare Logs, Browser, Analytics
Более детально можно посмотреть в таблице:
https://blog.cloudflare.com/content/images/2020/10/image1-10.png
Все фичи стоят $14/user в месяц, как и у ближайших конкурентов.
Я честно пытался найти какой-то кейс имплементации, или найти пример каким образом это все можно слепить в кучу и построить защищенный доступ к внутренним ресурсам, но… Не нашел. В целом, интернет знает только о статье в блоге:
https://blog.cloudflare.com/cloudflare-one/
В статье есть архитектура, общее описание, и в принципе, все.
Мягко сказать - я немного разочарован, т.к. ожидал увидеть намного больше информации, доклады, презентации, сравнения с основными компетиторами - но, к сожалению, нет.
Сейчас этот бандл выглядит как альтернативный вариант реализации zero-trust access, и я надеюсь, что в ближайшем будущем он станет более прозрачным.
{kind=link}
Atlassian: journey to the cloud (end support for all server products)
На днях случайно узнал, что Atlassian двигается в сторону cloud-only, и объявил о прекращении продаж лицензий и поддержки всех серверных продуктов.
🔸2 февраля 2021 года:
- прекращают продавать новые лицензии на серверные продукты
- апдейтят прайсинг
🔸 2 февраля 2024 года:
- полностью прекращают поддержку всех серверных продуктов
По сути, это значит что нужно думать и планировать миграцию в облако.
Из первого, что приходит на ум и активно используется в компаниях:
- Jira
- Confluence
- Bitbucket.
Так что создайте таску в Jira ”Move self-hosted Jira to cloud Jira” 😁
UPD: В коментах к посту отписали, что "Jira Datacenter edition will work"
https://www.atlassian.com/blog/announcements/journey-to-cloud
На днях случайно узнал, что Atlassian двигается в сторону cloud-only, и объявил о прекращении продаж лицензий и поддержки всех серверных продуктов.
🔸2 февраля 2021 года:
- прекращают продавать новые лицензии на серверные продукты
- апдейтят прайсинг
🔸 2 февраля 2024 года:
- полностью прекращают поддержку всех серверных продуктов
По сути, это значит что нужно думать и планировать миграцию в облако.
Из первого, что приходит на ум и активно используется в компаниях:
- Jira
- Confluence
- Bitbucket.
Так что создайте таску в Jira ”Move self-hosted Jira to cloud Jira” 😁
UPD: В коментах к посту отписали, что "Jira Datacenter edition will work"
https://www.atlassian.com/blog/announcements/journey-to-cloud
Work Life by Atlassian
Accelerating our journey to the cloud, together
To focus on the world-class cloud experience you deserve, we are simplifying our self-managed offerings.
Universal sports & games HACKATHON vol.2
Совсем скоро (27-29.11.2020) пройдет онлайн-хакатон, нужно будет предложить решение для разных проблем и получить $1500.
Проблемы, которые предлагают решить на хакатоне:
👉 сбор статистики (например, логов) на AWS: очень DevOps-related (helm install EFK == $1500)
👉 computer vision для сбора информации на спортивных событиях
👉 решения для интерактива с онлайн меропрятиями (виртуальное присутствие)
👉 анализ эмоций человека (тут выглядит как ML модель в Kubeflow, например)
👉 сервис автоматического подсчета рекламных появлений в стриме (тоже разложить на фреймы, прогнать в модели, получить результат, и все это завернуть в Airflow/Kubeflow)
Регистрация еще пару дней, советую ворваться в декабрь проактивно ☄️☄️☄️
Совсем скоро (27-29.11.2020) пройдет онлайн-хакатон, нужно будет предложить решение для разных проблем и получить $1500.
Проблемы, которые предлагают решить на хакатоне:
👉 сбор статистики (например, логов) на AWS: очень DevOps-related (helm install EFK == $1500)
👉 computer vision для сбора информации на спортивных событиях
👉 решения для интерактива с онлайн меропрятиями (виртуальное присутствие)
👉 анализ эмоций человека (тут выглядит как ML модель в Kubeflow, например)
👉 сервис автоматического подсчета рекламных появлений в стриме (тоже разложить на фреймы, прогнать в модели, получить результат, и все это завернуть в Airflow/Kubeflow)
Регистрация еще пару дней, советую ворваться в декабрь проактивно ☄️☄️☄️
{kind=link}
Prometheus vs VictoriaMetrics benchmark on node_exporter metrics
В статье делают бенчмарк Promethes vs VictoriaMetrics и данными с node_exporter (наверное, самым популярным экспортером в экосистеме:
https://valyala.medium.com/prometheus-vs-victoriametrics-benchmark-on-node-exporter-metrics-4ca29c75590f
🔹Результаты:
- Prometheus нужно в 7 раз больше дискового пространства
- Prometheus использует в 6 раз больше IO на чтение на нагрузке
- CPU usage одинаковый
- Prometheus нужно в 5 раз больше оперативной памяти
🔹 Выводы:
Сева, с днем рождения! Ты делаешь очень крутой продукт, который нужен всем, кто ищет long-term storage для Prometheus (т.е. вообще всем) - огромное тебе спасибо за это! Возможно, в какой-то момент можно будет даже отказаться от Prometheus в пользу vmagent, и от Alertmanager в пользу vmalert.
Очень круто осознавать, что ты у нас есть - человек, инженер, стратег и первопроходец, который учил делать мониторинг на самых зачатках DevOps митапов. Ура! 🥳
В статье делают бенчмарк Promethes vs VictoriaMetrics и данными с node_exporter (наверное, самым популярным экспортером в экосистеме:
https://valyala.medium.com/prometheus-vs-victoriametrics-benchmark-on-node-exporter-metrics-4ca29c75590f
🔹Результаты:
- Prometheus нужно в 7 раз больше дискового пространства
- Prometheus использует в 6 раз больше IO на чтение на нагрузке
- CPU usage одинаковый
- Prometheus нужно в 5 раз больше оперативной памяти
🔹 Выводы:
Сева, с днем рождения! Ты делаешь очень крутой продукт, который нужен всем, кто ищет long-term storage для Prometheus (т.е. вообще всем) - огромное тебе спасибо за это! Возможно, в какой-то момент можно будет даже отказаться от Prometheus в пользу vmagent, и от Alertmanager в пользу vmalert.
Очень круто осознавать, что ты у нас есть - человек, инженер, стратег и первопроходец, который учил делать мониторинг на самых зачатках DevOps митапов. Ура! 🥳
Medium
Prometheus vs VictoriaMetrics benchmark on node_exporter metrics
Recently single-node VictoriaMetrics gained support for scraping Prometheus targets. This made possible to run apples-to-apples benchmark…
Uklon Build-up: DevOps Edition
17 декабря в рамках этого митапа будет 3 доклада:
- How to migrate your data from on-premises to AWS easily
- Uklon: The hard way from a single PC to the cloud
- Deployments in Uklon: From Laptop to Production with GitOps
Ребята из Uklon готовят последние 2 доклада, и мне это показалось очень интересным.
Uber считают очень технологичной компанией, но еще не FAANG уровня. На митапе будет интересно посмотреть, насколько технологичен Uklon (comparing to Uber), какие проблемы приходится им решать, и можно будет спросить, почему авто на карте плывет через дома и озера (иногда).
В целом, выглядит супер интересно: на месте Uklon я бы пробовал работать в таких направлениях:
1. Строить лучший сервис на локальном рынке
2. Пробовать технологично перепрыгнуть Uber, в какой-то узкой области
Каждый из этих вариантов крутой, первый - масштабированием на другие рынки, второй - потенциальным поглощением от более крупных акул.
В любом случае я жду интересных докладов:
https://uklon.cloud-builders.tech/
UDP: (на днях расскажу как узнать все что было на KubeCon за 20 минут)
17 декабря в рамках этого митапа будет 3 доклада:
- How to migrate your data from on-premises to AWS easily
- Uklon: The hard way from a single PC to the cloud
- Deployments in Uklon: From Laptop to Production with GitOps
Ребята из Uklon готовят последние 2 доклада, и мне это показалось очень интересным.
Uber считают очень технологичной компанией, но еще не FAANG уровня. На митапе будет интересно посмотреть, насколько технологичен Uklon (comparing to Uber), какие проблемы приходится им решать, и можно будет спросить, почему авто на карте плывет через дома и озера (иногда).
В целом, выглядит супер интересно: на месте Uklon я бы пробовал работать в таких направлениях:
1. Строить лучший сервис на локальном рынке
2. Пробовать технологично перепрыгнуть Uber, в какой-то узкой области
Каждый из этих вариантов крутой, первый - масштабированием на другие рынки, второй - потенциальным поглощением от более крупных акул.
В любом случае я жду интересных докладов:
https://uklon.cloud-builders.tech/
UDP: (на днях расскажу как узнать все что было на KubeCon за 20 минут)
KubeCon North America 2020 за 40 минут
Обещал рассказать, как узнать все что было на KubeCon North America 2020 за 20 минут, но потом заметил, что там оказывается две части:
1 часть 👉 https://www.youtube.com/watch?v=vwI1NVVNcxM
2 часть 👉 https://www.youtube.com/watch?v=zYAe0X-WRjg
Копирую кусок содержания из первой части:
09:21 Declarative Testing Clusters with KUTTL
10:38 Taking Envoy Beyond C++ with WebAssembly
11:30 Telco Stack: Observability приносит ясность в мир 5G
12:40 Новый подход к логированию в виде стека: Fluent Bit + PostgreSQL (FPS)
13:38 Is the Edge More Important Than the Service Mesh?
14:43 Kubernetes Networking by Google
Также могу поделиться дополнительной практикой после просмотра саммари конференций: всегда полезно зайти и посмотреть расписание (agenda), выбрать интересные штуки, и почитать о них текстом.
TODO: подписаться на канал Дениса Васильева и ждать обзор KubeCon из другого локейшна
Обещал рассказать, как узнать все что было на KubeCon North America 2020 за 20 минут, но потом заметил, что там оказывается две части:
1 часть 👉 https://www.youtube.com/watch?v=vwI1NVVNcxM
2 часть 👉 https://www.youtube.com/watch?v=zYAe0X-WRjg
Копирую кусок содержания из первой части:
09:21 Declarative Testing Clusters with KUTTL
10:38 Taking Envoy Beyond C++ with WebAssembly
11:30 Telco Stack: Observability приносит ясность в мир 5G
12:40 Новый подход к логированию в виде стека: Fluent Bit + PostgreSQL (FPS)
13:38 Is the Edge More Important Than the Service Mesh?
14:43 Kubernetes Networking by Google
Также могу поделиться дополнительной практикой после просмотра саммари конференций: всегда полезно зайти и посмотреть расписание (agenda), выбрать интересные штуки, и почитать о них текстом.
TODO: подписаться на канал Дениса Васильева и ждать обзор KubeCon из другого локейшна
YouTube
Kubernetes Digest: KubeCon North America 2020
Дайджест первого дня конференции KubeCon North America 2020
В этом эпизоде сделаем краткий обзор тем обсуждаемых на конференции - если вас заинтересует что-то более подробно - дайте знать в комментариях.
Мы прогуляемся с вами по виртуальным стартап холлам…
В этом эпизоде сделаем краткий обзор тем обсуждаемых на конференции - если вас заинтересует что-то более подробно - дайте знать в комментариях.
Мы прогуляемся с вами по виртуальным стартап холлам…
Amazon Managed Service for Prometheus (AMP)
Вчера нашел AMP, о котором так давно были слухи! 🔥
Умеет в AWS ECS, AWS EKS, on-premise K8S.
По идее, можно подключить к Amazon Managed Service for Grafana и легко получить минимальный HA стек. И даже с учетом лимитейшнов, которые я описываю внизу - можно настроить алерты в Grafana, и так поехать до того момента, пока не появится аналог PrometheusAlertRule.
Preview release limitations:
- No way to configure long-term storage + retention duration - 150 days
- No Alertmanager and alert rules
https://aws.amazon.com/prometheus/
Вчера нашел AMP, о котором так давно были слухи! 🔥
Умеет в AWS ECS, AWS EKS, on-premise K8S.
По идее, можно подключить к Amazon Managed Service for Grafana и легко получить минимальный HA стек. И даже с учетом лимитейшнов, которые я описываю внизу - можно настроить алерты в Grafana, и так поехать до того момента, пока не появится аналог PrometheusAlertRule.
Preview release limitations:
- No way to configure long-term storage + retention duration - 150 days
- No Alertmanager and alert rules
https://aws.amazon.com/prometheus/
Amazon
Container Environment Monitoring Service - Amazon Managed Service for Prometheus - AWS
Amazon Managed Service for Prometheus is a monitoring and alerting service that makes it easier to monitor containerized applications and infrastructure securely, at scale.
leves.fyi - software engineering salaries in Ukraine
Неожиданно, и очень воодушевляет - на levels.fyi появился раздел с зарплатами в нашей стране.
До этого момента я считал, что этим сервисом пользуются только в США, и только для FAANG (для примерного определения сколько просить и торговаться за каждый уровень).
Итого, мы получаем - сервис, в котором можно будет выбрать город (Киев, Львов, Одесса), специализацию, компанию - и посмотреть реальный рейндж зарплат на интересующую должность. Для примера - в сервисе нет Беларуси, Эстонии, Португалии, Польши (!), и еще ряда стран.
Сейчас есть 13 сабмитов, ждем намного больше и небольшого повышения средней компенсации по отрасли.
P.S. Очень жду первый FAANG с инжиниринг офисом в Украине + совсем скоро расскажу о собеседовании в HotJar
https://www.levels.fyi/Salaries/Software-Engineer/Ukraine/
Неожиданно, и очень воодушевляет - на levels.fyi появился раздел с зарплатами в нашей стране.
До этого момента я считал, что этим сервисом пользуются только в США, и только для FAANG (для примерного определения сколько просить и торговаться за каждый уровень).
Итого, мы получаем - сервис, в котором можно будет выбрать город (Киев, Львов, Одесса), специализацию, компанию - и посмотреть реальный рейндж зарплат на интересующую должность. Для примера - в сервисе нет Беларуси, Эстонии, Португалии, Польши (!), и еще ряда стран.
Сейчас есть 13 сабмитов, ждем намного больше и небольшого повышения средней компенсации по отрасли.
P.S. Очень жду первый FAANG с инжиниринг офисом в Украине + совсем скоро расскажу о собеседовании в HotJar
https://www.levels.fyi/Salaries/Software-Engineer/Ukraine/
Levels.fyi
Software Engineer Salary in Ukraine
The average Software Engineer salary range in Ukraine is from UAH 1,575,560 to UAH 2,757,230. View Software Engineer salaries across top companies broken down by base pay, stock, and bonus.
DevOps дайджест #34: AWS re:Invent, Kubernetes deprecating Docker, Prometheus vs VictoriaMetrics
Крайний дайджест в этом году + вероятно, самый интересный по апдейтам.
Отличный способ начать день с пользой!)
Целый год для вас над дайджестами работали:
- Влад Волошин, Preply
- Алексей Асютин, thredUP
- Андрей Савельев, UCloud
- Дмитрий Горбунов, Gazelle Global
Огромное спасибо этим героям! 🔥
Пусть SLA 99,999% станет реальностью, и появятся первые вакансии FAANG в 2021. Ура! 💥
С наступающим Новым Годом! 🥳
https://dou.ua/forums/topic/32377/
Крайний дайджест в этом году + вероятно, самый интересный по апдейтам.
Отличный способ начать день с пользой!)
Целый год для вас над дайджестами работали:
- Влад Волошин, Preply
- Алексей Асютин, thredUP
- Андрей Савельев, UCloud
- Дмитрий Горбунов, Gazelle Global
Огромное спасибо этим героям! 🔥
Пусть SLA 99,999% станет реальностью, и появятся первые вакансии FAANG в 2021. Ура! 💥
С наступающим Новым Годом! 🥳
https://dou.ua/forums/topic/32377/
ДОУ
DevOps дайджест #34: AWS re:Invent, Kubernetes deprecating Docker, Prometheus vs VictoriaMetrics
В выпуске: большой обзор на AWS, CentOS 8 + Atlassian self-hosted прекращают поддерживать, tobs, Hashicorp Waypoint и Hashicorp Boundary, PostgreSQL 13, и SRE вакансии в Dropbox.
Site Reliability Engineer, Tesla
👉 Для инженеров из США:
Мой хороший друг ищет себе в команду SRE.
Лучше писать сразу в личку за деталями: @supersupermacho
👉 Для инженеров не из США:
Также есть вакансии в Европе, куда мы можем подаваться.
https://www.tesla.com/careers/search/job/site-reliability-engineer-digital-experience-57288
UPD: Кто бы куда хотел? В Европу или США? Или дома всегда лучше?
👉 Для инженеров из США:
Мой хороший друг ищет себе в команду SRE.
Лучше писать сразу в личку за деталями: @supersupermacho
👉 Для инженеров не из США:
Также есть вакансии в Европе, куда мы можем подаваться.
https://www.tesla.com/careers/search/job/site-reliability-engineer-digital-experience-57288
UPD: Кто бы куда хотел? В Европу или США? Или дома всегда лучше?
Документація Kubernetes - help wanted
Відкриття дня - документація для Kubernetes українською 🇺🇦
https://kubernetes.io/uk/docs/home/
Виглядає так, що документацію тільки почали перекладати (команда Вови Цапа із SHALB) і їм, ймовірно, не завадить допомога:
https://github.com/kubernetes/website/commits/master/README-uk.md
Дуже крута ініціатива!
Відкриття дня - документація для Kubernetes українською 🇺🇦
https://kubernetes.io/uk/docs/home/
Виглядає так, що документацію тільки почали перекладати (команда Вови Цапа із SHALB) і їм, ймовірно, не завадить допомога:
https://github.com/kubernetes/website/commits/master/README-uk.md
Дуже крута ініціатива!
Kubernetes
Документація Kubernetes
Kubernetes — рушій оркестрування контейнерів, створений для автоматичного розгортання, масштабування і управління контейнеризованими застосунками, є проєктом з відкритим вихідним кодом. Цей проєкт знаходиться під егідою Cloud Native Computing Foundation.
Что там случилось с Elasticsearch?
Супер кратко:
Elastic поменял лицензию для продуктов, и они перестали быть open source. Комьюнити это не понравилось.
Теперь вышел Amazon, у которого война с Elastic, и сказал - мы форкнем, и будем дальше развивать Elasticsearch + Kibana с ALv2 лицензией.
Итого, факты:
- Elastic announced moving Apache 2.0-licensed source code to be under Server Side Public License
- Elasticsearch 7.11 будет уже под SSPL, т.е. не open-source
- Elasticsearch 7.10.x, который еще ALv2 - будет получать секьюрити апдейты до May 11th, 2022
- AWS will step up to create and maintain a ALv2-licensed fork of open source Elasticsearch and Kibana
Кто бы мог подумать 🤔
https://aws.amazon.com/blogs/opensource/stepping-up-for-a-truly-open-source-elasticsearch
Супер кратко:
Elastic поменял лицензию для продуктов, и они перестали быть open source. Комьюнити это не понравилось.
Теперь вышел Amazon, у которого война с Elastic, и сказал - мы форкнем, и будем дальше развивать Elasticsearch + Kibana с ALv2 лицензией.
Итого, факты:
- Elastic announced moving Apache 2.0-licensed source code to be under Server Side Public License
- Elasticsearch 7.11 будет уже под SSPL, т.е. не open-source
- Elasticsearch 7.10.x, который еще ALv2 - будет получать секьюрити апдейты до May 11th, 2022
- AWS will step up to create and maintain a ALv2-licensed fork of open source Elasticsearch and Kibana
Кто бы мог подумать 🤔
https://aws.amazon.com/blogs/opensource/stepping-up-for-a-truly-open-source-elasticsearch
Amazon
Stepping up for a truly open source Elasticsearch | Amazon Web Services
Last week, Elastic announced they will change their software licensing strategy, and will not release new versions of Elasticsearch and Kibana under the Apache License, Version 2.0 (ALv2). Instead, new versions of the software will be offered under the Elastic…
driftctl - Take control of infrastructure drift
Driftctl is a open-source CLI that tracks, analyzes, prioritizes, and warns of infrastructure drift.
Features:
- Scan cloud provider and map resources with IaC code
- Analyze diff, and warn about drift and unwanted unmanaged resources
- Allow users to ignore resources
- Multiple output formats
Example usage:
https://github.com/cloudskiff/driftctl
Driftctl is a open-source CLI that tracks, analyzes, prioritizes, and warns of infrastructure drift.
Features:
- Scan cloud provider and map resources with IaC code
- Analyze diff, and warn about drift and unwanted unmanaged resources
- Allow users to ignore resources
- Multiple output formats
Example usage:
$ driftctl scan --from tfstate://terraform.tfstate
https://github.com/cloudskiff/driftctl
GitHub
GitHub - snyk/driftctl: Detect, track and alert on infrastructure drift
Detect, track and alert on infrastructure drift. Contribute to snyk/driftctl development by creating an account on GitHub.
ДевОпс Инженер: работа
Когда мне в личку прилетают интересные вакансии - я всегда грущу, потому что не хочу спамить в основной канал. У нас уже была вакансия с Tesla, вакансии с HotJar и куча местных opportunity с вознаграждением > 5000$.
Чтобы не грустить, и спокойно делиться с вами крутыми вакансиями, я придумал сделать отдельную филию канала - @devopsengineerwork 👈
Там уже есть первая вакансия с вилкой 5000$ - 6500$. Я буду продолжать туда постить вкусности.
@devopsengineerwork 💸
Когда мне в личку прилетают интересные вакансии - я всегда грущу, потому что не хочу спамить в основной канал. У нас уже была вакансия с Tesla, вакансии с HotJar и куча местных opportunity с вознаграждением > 5000$.
Чтобы не грустить, и спокойно делиться с вами крутыми вакансиями, я придумал сделать отдельную филию канала - @devopsengineerwork 👈
Там уже есть первая вакансия с вилкой 5000$ - 6500$. Я буду продолжать туда постить вкусности.
@devopsengineerwork 💸
GCP Config Connector & AWS Controllers for Kubernetes: GitOps для инфраструктуры
Как бы я не любил Terraform, но если посмотреть правде в глаза - он не всегда удобен, и есть проблемы, которые HashiCorp еще нужно решить.
Одна из серьезных проблем - Wall of Confusion, который мы построили снова. Есть инфраструктура в Terraform, туда доступ только у DevOps, есть чарты в репозитории каждой апки - там может что-то поправить и разработчик приложения, и DevOps. Но в инфраструктуру разработчику нельзя. Грустно.
Почему нельзя разработчику в Terraform инфраструктуру? У каждого свой вариант:
- не актуальный стейт, половина ресурсов с изменениями
- непонятная структура даже для самих DevOps
- нужно обучать девелоперов, в том числе и в модули
- разница приоритетов: по сути DevOps команда осталась Ops, и только она отвечает за стабильность
Вторая серьезная проблема - неймспейсы. Большинство инженеров не слышали, что в Terraform есть неймспейсы, а те кто слышали - стараются их не использовать.
Неймспейсы в Terraform были созданы как ответ на запрос "хотим точно такую же инфру, только без копипасты". Как результат - Terraform рождает кучу месса, остаются те же проблемы с неактуальностью стейта, суперсложно завернуть его в Jenkins/Atlantis и т.п. и т.д.
Получается, что задача создать динамический environment (как прод, например) и потушить его после какого-то действия по задумке - easy, а в реализации - ламучий мрак.
И в этот момент где-то далеко виднеется GitOps для инфраструктуры. После того, как все заценили ArgoCD и все прелести GitOps подхода - мы увидели первые зачатки реализаций GitOps, но уже для инфраструктуры.
В чем суть и как работает:
- мы устанавливаем в Kubernetes cluster контроллер (aka operator с новыми CRD)
- имплементим инфраструктурные зависимости внутри чарта с помощью CRD
- деплоим в кластер, контроллер подхватывает манифесты и деплоит вместе с приложением
Таким образом, мы получаем GitOps для инфраструктуры:
- можно конфигурить апку и зависимости вместе
- отдать это девелоперам, которым понятно YAML и не понятно HCL
- врапнуть чем угодно (helm/kustomize/jsonnet etc)
Стоит заметить что GCP немного впереди и уже работает (реализация - Config Connector), а AWS пока не догоняет - половина ресурсов в Beta, а вторая половина совсем не реализована. Я отлично вижу как определенные рутинные и неудобные куски выносятся из Terraform и врапаются любой билд тулой, например:
- вместо мануального менеджмента IAM делаем отдельный реп, показываем девелоперам как пользоваться, и ставим апруверами SecOps —> вообще убираем себя из этого флоу
- также выносим куски с ASg, размерами инстансов, тестовыми инстансами и т.п.
- делаем амбрелла чарт, который умеет инклудить приложения компании и докидывает туда зависимости (временные S3, SQS, RDS, etc) и делаем динамический энв на PR
Уже доступные ресурсы можно посмотреть по ссылкам:
👉 https://cloud.google.com/config-connector/docs/reference/overview
👉 https://aws-controllers-k8s.github.io/community/services/
Как бы я не любил Terraform, но если посмотреть правде в глаза - он не всегда удобен, и есть проблемы, которые HashiCorp еще нужно решить.
Одна из серьезных проблем - Wall of Confusion, который мы построили снова. Есть инфраструктура в Terraform, туда доступ только у DevOps, есть чарты в репозитории каждой апки - там может что-то поправить и разработчик приложения, и DevOps. Но в инфраструктуру разработчику нельзя. Грустно.
Почему нельзя разработчику в Terraform инфраструктуру? У каждого свой вариант:
- не актуальный стейт, половина ресурсов с изменениями
- непонятная структура даже для самих DevOps
- нужно обучать девелоперов, в том числе и в модули
- разница приоритетов: по сути DevOps команда осталась Ops, и только она отвечает за стабильность
Вторая серьезная проблема - неймспейсы. Большинство инженеров не слышали, что в Terraform есть неймспейсы, а те кто слышали - стараются их не использовать.
Неймспейсы в Terraform были созданы как ответ на запрос "хотим точно такую же инфру, только без копипасты". Как результат - Terraform рождает кучу месса, остаются те же проблемы с неактуальностью стейта, суперсложно завернуть его в Jenkins/Atlantis и т.п. и т.д.
Получается, что задача создать динамический environment (как прод, например) и потушить его после какого-то действия по задумке - easy, а в реализации - ламучий мрак.
И в этот момент где-то далеко виднеется GitOps для инфраструктуры. После того, как все заценили ArgoCD и все прелести GitOps подхода - мы увидели первые зачатки реализаций GitOps, но уже для инфраструктуры.
В чем суть и как работает:
- мы устанавливаем в Kubernetes cluster контроллер (aka operator с новыми CRD)
- имплементим инфраструктурные зависимости внутри чарта с помощью CRD
- деплоим в кластер, контроллер подхватывает манифесты и деплоит вместе с приложением
Таким образом, мы получаем GitOps для инфраструктуры:
- можно конфигурить апку и зависимости вместе
- отдать это девелоперам, которым понятно YAML и не понятно HCL
- врапнуть чем угодно (helm/kustomize/jsonnet etc)
Стоит заметить что GCP немного впереди и уже работает (реализация - Config Connector), а AWS пока не догоняет - половина ресурсов в Beta, а вторая половина совсем не реализована. Я отлично вижу как определенные рутинные и неудобные куски выносятся из Terraform и врапаются любой билд тулой, например:
- вместо мануального менеджмента IAM делаем отдельный реп, показываем девелоперам как пользоваться, и ставим апруверами SecOps —> вообще убираем себя из этого флоу
- также выносим куски с ASg, размерами инстансов, тестовыми инстансами и т.п.
- делаем амбрелла чарт, который умеет инклудить приложения компании и докидывает туда зависимости (временные S3, SQS, RDS, etc) и делаем динамический энв на PR
Уже доступные ресурсы можно посмотреть по ссылкам:
👉 https://cloud.google.com/config-connector/docs/reference/overview
👉 https://aws-controllers-k8s.github.io/community/services/
Google Cloud
Config Connector resources | Config Connector Documentation | Google Cloud
Yaroslav Molochko: Self-healing in prod do you really need AI for that?
Ярослав - отличный пример, как действительно нужно деливерить world-class решения, строить карьеру, делать CNCF митапы и пушить KubeFlow.
До этого доклада Ярослав Молочко был простым Head of Engineering, а потом стал настоящим Director of Engineering.
В докладе - дизайн self-healing приложений, а сегодня - день роджения Ярослава.
Ура!
https://www.youtube.com/watch?v=Byj11BVmeZs
Ярослав - отличный пример, как действительно нужно деливерить world-class решения, строить карьеру, делать CNCF митапы и пушить KubeFlow.
До этого доклада Ярослав Молочко был простым Head of Engineering, а потом стал настоящим Director of Engineering.
В докладе - дизайн self-healing приложений, а сегодня - день роджения Ярослава.
Ура!
https://www.youtube.com/watch?v=Byj11BVmeZs
YouTube
Self-healing in prod do you really need AI for that? (Yaroslav Molochko, Ukraine) [RU]
When you deal with production, idea of self-healing sounds really attractive, or maybe your VP is claiming that all his peers already doing AI, and we should do the same.
Doesn’t matter what is the reason – but there are big chances that you don’t need AI/ML…
Doesn’t matter what is the reason – but there are big chances that you don’t need AI/ML…
Собеседования по DevOps с Всеволодом Поляковым
Всеволод Поляков о DevOps собеседованиях: о чем спрашивают, как готовиться, do's & don'ts + небольшое спонтанное mock interview с одним из участников встречи.
https://www.youtube.com/watch?v=5CHzunac4MI
Всеволод Поляков о DevOps собеседованиях: о чем спрашивают, как готовиться, do's & don'ts + небольшое спонтанное mock interview с одним из участников встречи.
https://www.youtube.com/watch?v=5CHzunac4MI
YouTube
Співбесіди для DevOps інженерів з Всеволодом Поляковим
Всеволод Поляков про DevOps співбесіди: про що запитують, як готуватися, do's & don'ts + невеличке спонтанне mock interview з одним з учасників зустрічі.
Всеволод - DevOps консультант, TeamLead, працював з такими компаніями як Grammarly, Ring, Amazon, засновник…
Всеволод - DevOps консультант, TeamLead, працював з такими компаніями як Grammarly, Ring, Amazon, засновник…
DevOps Days Kyiv 2021!
20-22 апреля у нас DevOps Days Kyiv 2021 🔥
Конференция в онлайн формате (проходит вечером, удобно после работы), и бесплатно.
Будут какие-то очень важные спикеры из других стран, например автор книги ”Kubernetes: Up and Running: Dive Into the Future of Infrastructure”, но я об этом не хочу особо упоминать.
Я уже вижу топовых спикеров, и уже очень хочу их услышать 💥:
- Сева Поляков - Marketing in DevOps
- Ярослав Молочко - Humble reflection on future of DevOps
- Антон Кошевой - The way to China. Cheat Sheet
- Влад Волошин - Cooperation between multiple infrastructure teams
- Вова Цап - Infrastructure Templating with cluster.dev
Какие люди в одном месте!
Однозначно приду на конфу, и рекомендую регистрироваться:
https://devopsdays.com.ua/
20-22 апреля у нас DevOps Days Kyiv 2021 🔥
Конференция в онлайн формате (проходит вечером, удобно после работы), и бесплатно.
Будут какие-то очень важные спикеры из других стран, например автор книги ”Kubernetes: Up and Running: Dive Into the Future of Infrastructure”, но я об этом не хочу особо упоминать.
Я уже вижу топовых спикеров, и уже очень хочу их услышать 💥:
- Сева Поляков - Marketing in DevOps
- Ярослав Молочко - Humble reflection on future of DevOps
- Антон Кошевой - The way to China. Cheat Sheet
- Влад Волошин - Cooperation between multiple infrastructure teams
- Вова Цап - Infrastructure Templating with cluster.dev
Какие люди в одном месте!
Однозначно приду на конфу, и рекомендую регистрироваться:
https://devopsdays.com.ua/
DevOpsDays -
DevOpsDays: AI Chapter - DevOpsDays
DevOpsDays Ukraine is part of the worldwide DevOpsDays community. This June, we’re hosting virtual talks by speakers, Ignite sessions from the DevOps community around the world, and kicking off Open Space discussions.