
Наткнулся на замечательную статью, как крупные медиа используют эксплойты в Google для монетизации своего авторитета:
https://link.medium.com/WoX1dvfqbV
Суть в том, что если ваш сайт мега-известный в каком-то регионе, то создание на нем новых "проектов" (в том числе не связанных между собой) это намного интересная идея, чем создание отдельных доменов под проект. Так как Google уже доверяет домену и будет давать ему трафик, практически, независимо от качества контента. И на этом делаются миллионы.
Самый распространенный способ — коллаборация медиа с купонаторами. На новостных изданиях создаются поддомены для заработка на промо-кодах. И это тренд во всех странах.
discountcode.dailymail.co.uk - Промо-коды на известнейшем медиа в Великобритании, 2.2 млн трафика в месяц в начале прошлого года, 4 млн/мес. в конце 2018, сейчас 3 млн трафика, судя по симиларвебу. Ориентировочный заработок с этого проекта 1.5 млн. долларов в месяц.
gutscheine.focus.de - Промо-коды на известном издании в Германии, около 2 млн трафика, примерно 800 тыс. долларов в месяц с партнерки.
codepromo.lexpress.fr - Аналогичное во Франции, 1.5 млн трафика и около 600 тыс. долларов.
promokod.kp.ru - Юзает даже Комсомольская Правда. Заработки, правда, не такие большие, по оценкам автора всего 65 000 долларов в месяц, но штат редакторов уже окупается.
torg.mail.ru/promokod - Мэйл.ру не могли пропустить этот тренд. Сколько у них там трафика неизвестно, но должно быть прилично.
И по всему миру таких медиа-сайтов сотня, как минимум. Интересно, что среди них нет США, Австралии и Канады.
https://docs.google.com/spreadsheets/d/1cOGItdfAAeSUCK4OueBGS1-J4ZFPBrU1dyxgB2URpEs/edit#gid=0
У проектов более 90% трафика идет из поиска. Можно предположить, что у них могут быть крутые ссылки или контент, но это не так. Контент там посредственный, много мусорных ссылок. Топы держатся за счет авторитетов самих доменов. После медицинского апдейта в прошлом году все эти сайты выиграли в трафике.
Но это еще не все.
Купоны это хорошо, но можно ведь создавать разные проекты. Это и используют.
Партнерки под Амазон? Пожалуйста
vergleich.bild.de - проект крупнейшей немецкой газеты
thewirecutter.com - отдельный проект New York Times c 10млн трафика
Заработок на ставках? А давайте
betting.dailymail.co.uk
betting.ekstrabladet.dk
Может дейтинг? А почему бы и нет
soulmates.theguardian.com
В общем, такие краткие тренды SEO в Google 2019 :)
Статью-источник на досуге почитайте.
https://link.medium.com/WoX1dvfqbV
Суть в том, что если ваш сайт мега-известный в каком-то регионе, то создание на нем новых "проектов" (в том числе не связанных между собой) это намного интересная идея, чем создание отдельных доменов под проект. Так как Google уже доверяет домену и будет давать ему трафик, практически, независимо от качества контента. И на этом делаются миллионы.
Самый распространенный способ — коллаборация медиа с купонаторами. На новостных изданиях создаются поддомены для заработка на промо-кодах. И это тренд во всех странах.
discountcode.dailymail.co.uk - Промо-коды на известнейшем медиа в Великобритании, 2.2 млн трафика в месяц в начале прошлого года, 4 млн/мес. в конце 2018, сейчас 3 млн трафика, судя по симиларвебу. Ориентировочный заработок с этого проекта 1.5 млн. долларов в месяц.
gutscheine.focus.de - Промо-коды на известном издании в Германии, около 2 млн трафика, примерно 800 тыс. долларов в месяц с партнерки.
codepromo.lexpress.fr - Аналогичное во Франции, 1.5 млн трафика и около 600 тыс. долларов.
promokod.kp.ru - Юзает даже Комсомольская Правда. Заработки, правда, не такие большие, по оценкам автора всего 65 000 долларов в месяц, но штат редакторов уже окупается.
torg.mail.ru/promokod - Мэйл.ру не могли пропустить этот тренд. Сколько у них там трафика неизвестно, но должно быть прилично.
И по всему миру таких медиа-сайтов сотня, как минимум. Интересно, что среди них нет США, Австралии и Канады.
https://docs.google.com/spreadsheets/d/1cOGItdfAAeSUCK4OueBGS1-J4ZFPBrU1dyxgB2URpEs/edit#gid=0
У проектов более 90% трафика идет из поиска. Можно предположить, что у них могут быть крутые ссылки или контент, но это не так. Контент там посредственный, много мусорных ссылок. Топы держатся за счет авторитетов самих доменов. После медицинского апдейта в прошлом году все эти сайты выиграли в трафике.
Но это еще не все.
Купоны это хорошо, но можно ведь создавать разные проекты. Это и используют.
Партнерки под Амазон? Пожалуйста
vergleich.bild.de - проект крупнейшей немецкой газеты
thewirecutter.com - отдельный проект New York Times c 10млн трафика
Заработок на ставках? А давайте
betting.dailymail.co.uk
betting.ekstrabladet.dk
Может дейтинг? А почему бы и нет
soulmates.theguardian.com
В общем, такие краткие тренды SEO в Google 2019 :)
Статью-источник на досуге почитайте.
Гугл больше не поддерживает разметку rel=prev/next (и уже несколько лет). Поисковик обрабатывает страницы пагинации как и любые другие страницы на сайте. Официальная документация про эту разметку удалена с хелпа гугла, а в старом блог-посте добавлена пометка, что пост устарел.
Официальный анонс:
https://twitter.com/googlewmc/status/1108726443251519489
В общем, rel=prev/next Google не использует вообще нигде. А если вас интересует Яндекс, то он этот тег никогда и не поддерживал.
via @devakatalk
Официальный анонс:
https://twitter.com/googlewmc/status/1108726443251519489
В общем, rel=prev/next Google не использует вообще нигде. А если вас интересует Яндекс, то он этот тег никогда и не поддерживал.
via @devakatalk
{kind=link}
Привет! Соскучились по выпускам "На диване"?
Держите новую серию.
Самые важные SEO-факторы, чтобы быть ТОП-1
https://youtu.be/IDiUvmdj7gw
via @devakatalk
Держите новую серию.
Самые важные SEO-факторы, чтобы быть ТОП-1
https://youtu.be/IDiUvmdj7gw
via @devakatalk
{kind=link}
Макс Пастухов распродает свои базы ключевиков для создания нового продукта.
https://pastukhov.com/src
— полный комплект всех баз ключевых слов
— большое обновление английской базы (свежие данные + 4.5 миллиарда англоязычных кеев)
— возможность получить все базы в текстовом виде для парсинга и импорта в свои системы, а также
— исходники оболочки под Windows и онлайн-сервиса (с подробной инструкцией и разбором алгоритмов).
— бесплатный пожизненный апдейт
Всего за 14700 рублей.
https://pastukhov.com/src
— полный комплект всех баз ключевых слов
— большое обновление английской базы (свежие данные + 4.5 миллиарда англоязычных кеев)
— возможность получить все базы в текстовом виде для парсинга и импорта в свои системы, а также
— исходники оболочки под Windows и онлайн-сервиса (с подробной инструкцией и разбором алгоритмов).
— бесплатный пожизненный апдейт
Всего за 14700 рублей.
Сегодня вышел анонс, что Дзен наконец-то изменил алгоритм подбора материалов для ленты. И теперь, вроде как, стало лучше и для пользователей и для авторов.
https://zen.yandex.ru/media/zenmag/alfa-centavra--novyi-algoritm-iandeksdzena-5c8bb4a817bca800b1877ca5
"Дзен стал точнее подбирать пользователям публикации, а главное – научился делать это намного быстрее. Усовершенствованные технологии машинного обучения теперь выбирают статьи из огромного объема документов – на порядок больше, чем раньше. Так что теперь качественные публикации в Дзене получат больше внимания, а нишевые и молодые каналы быстрее наберут заинтересованную аудиторию."
В Яндекс.Дзене всегда была одна большая проблема — в топе находятся записи с кликбейтными заголовками. Решил проверить со стороны пользователя, что изменилось, зашел в Дзен. Что вы думаете я увидел там в ТОПе? 😬
Обсуждение на VC: vc.ru/media/62115
https://zen.yandex.ru/media/zenmag/alfa-centavra--novyi-algoritm-iandeksdzena-5c8bb4a817bca800b1877ca5
"Дзен стал точнее подбирать пользователям публикации, а главное – научился делать это намного быстрее. Усовершенствованные технологии машинного обучения теперь выбирают статьи из огромного объема документов – на порядок больше, чем раньше. Так что теперь качественные публикации в Дзене получат больше внимания, а нишевые и молодые каналы быстрее наберут заинтересованную аудиторию."
В Яндекс.Дзене всегда была одна большая проблема — в топе находятся записи с кликбейтными заголовками. Решил проверить со стороны пользователя, что изменилось, зашел в Дзен. Что вы думаете я увидел там в ТОПе? 😬
Обсуждение на VC: vc.ru/media/62115
{kind=link}
В Google имеется два алгоритма для лучшего понимания смысла поисковых запросов и текстов — это RankBrain и Neural Matching.
RankBrain был анонсирован в 2015 году и по словам гуглоидов являлся третьим наиболее значимым фактором ранжирования. Этот алгоритм использует искусственный интеллект для обработки поисковых результатов, в основном для редких запросов (которые никогда раньше не вводили в Google, соответственно, нет статистики, а таких запросов до 20% от всех) и является частью большого алгоритма Колибри. RankBrain может из запросов извлекать сущности и факты, сопоставлять их и искать взаимосвязи, в результате показывать на первых местах даже те важные сайты, где не встречались слова из исходного запроса.
Алгоритм Neural Matching анонсировали в конце пошлого года. Он помогает понимать концепты и сопоставлять поисковые запросы с документами. Классический пример — запрос "почему мой телевизор выглядит странно". В данном случае Google понимает, что речь об "эффекте мыльной оперы" и в первую очередь будет показывать документы про это. По заявлениям гугла Neural Matching алгоритм используется для 30% запросов.
В чем же различие этих алгоритмов? Судя по описанию, оба они используют машинное обучение и оба лучше понимают смысл текстов. Google в лице Дени Салливана объяснил разницу:
https://twitter.com/searchliaison/status/1108776357385789441
RankBrain помогает лучше соотносить страницы с концептами. Это значит, что Google может находить лучшие релевантные документы, даже если они не содержат ключевых слов из запроса. Так как понимает, что страница относится к другим словам и концептам.
Neural Matching помогает лучше соотносить слова с поисковыми запросами. Типа системы супер-синонимов. Где синонимы это слова, очень близко связанные с другими словами.
Есть небольшая путаница, что с чем соотносится, так как в разных анонсах Google формулировал определения по-разному. Но в целом, оба алгоритма про понимание текстов, слов и их взаимосвязей (как в запросах, так и в документах).
via @devakatalk
RankBrain был анонсирован в 2015 году и по словам гуглоидов являлся третьим наиболее значимым фактором ранжирования. Этот алгоритм использует искусственный интеллект для обработки поисковых результатов, в основном для редких запросов (которые никогда раньше не вводили в Google, соответственно, нет статистики, а таких запросов до 20% от всех) и является частью большого алгоритма Колибри. RankBrain может из запросов извлекать сущности и факты, сопоставлять их и искать взаимосвязи, в результате показывать на первых местах даже те важные сайты, где не встречались слова из исходного запроса.
Алгоритм Neural Matching анонсировали в конце пошлого года. Он помогает понимать концепты и сопоставлять поисковые запросы с документами. Классический пример — запрос "почему мой телевизор выглядит странно". В данном случае Google понимает, что речь об "эффекте мыльной оперы" и в первую очередь будет показывать документы про это. По заявлениям гугла Neural Matching алгоритм используется для 30% запросов.
В чем же различие этих алгоритмов? Судя по описанию, оба они используют машинное обучение и оба лучше понимают смысл текстов. Google в лице Дени Салливана объяснил разницу:
https://twitter.com/searchliaison/status/1108776357385789441
RankBrain помогает лучше соотносить страницы с концептами. Это значит, что Google может находить лучшие релевантные документы, даже если они не содержат ключевых слов из запроса. Так как понимает, что страница относится к другим словам и концептам.
Neural Matching помогает лучше соотносить слова с поисковыми запросами. Типа системы супер-синонимов. Где синонимы это слова, очень близко связанные с другими словами.
Есть небольшая путаница, что с чем соотносится, так как в разных анонсах Google формулировал определения по-разному. Но в целом, оба алгоритма про понимание текстов, слов и их взаимосвязей (как в запросах, так и в документах).
via @devakatalk
Интересно, что в Google есть очень короткий SERP, а есть очень длинный. Например, по запросу "рецепт тыквенного супа" на первой странице появляется 17-19 результатов. И есть вероятность, что по инфо-запросам выдача будет более растянутой.
Некоторые специалисты, считают, что в Google в ближайшее время может появиться бесконечная прокрутка SERP. Как сейчас происходит с блоком "также спрашивают".
Только представьте, будет всего одна бесконечная страница поисковой выдачи, напичканная рекламными блоками и различными колдунщиками. Это, конечно, создаст трудности для сервисов проверки позиций. Но будут как-то выкручиваться.
В общем, многие текущие события предвещают бесконечную прокрутку результатов поиска. Будьте к этому готовы!
Некоторые специалисты, считают, что в Google в ближайшее время может появиться бесконечная прокрутка SERP. Как сейчас происходит с блоком "также спрашивают".
Только представьте, будет всего одна бесконечная страница поисковой выдачи, напичканная рекламными блоками и различными колдунщиками. Это, конечно, создаст трудности для сервисов проверки позиций. Но будут как-то выкручиваться.
В общем, многие текущие события предвещают бесконечную прокрутку результатов поиска. Будьте к этому готовы!
{kind=link}
Если ваш сайт просел после мартовского апдейта в Google или после его апдейтов в прошлом году, то:
— Пересмотрите свои тексты. Действительно ли они написаны для людей и нужны там, где вы их размещаете? Уберите или перепишите весь слабый текст.
— Избавьтесь на сайте от малоинформативного или шаблонного контента.
— Просканируйте сайт любым краулером, найдите технические ошибки, и пофиксите их всех.
— Проанализируйте, какие всплывашки на вашем сайте показываются посетителям. Нет ли в них агрессивной рекламы, не ухудшают ли они пользовательский опыт?
— В целом проведите юзабилити-анализ вашего сайта, возможно есть узкие места, где пользователи постоянно спотыкаются.
— Убедитесь, что ваши посадочные страницы решают информационную потребность пользователя, который заходит на них по продвигаемым вами запросам.
— Для инфо-разделов убедитесь, что их авторами являются эксперты и это понятно посетителям, и через разметку поисковым роботам. Любой контент принадлежит автору и гуглу важно наличие экспертизы.
— И пересмотрите обратные ссылки. Они должны быть сделаны человеком и для человека.
Реализация всех этих пунктов не только вернет трафик сайту, но и заложит большой потенциал на будущее!
Отличного и продуктивного вам дня!
— Пересмотрите свои тексты. Действительно ли они написаны для людей и нужны там, где вы их размещаете? Уберите или перепишите весь слабый текст.
— Избавьтесь на сайте от малоинформативного или шаблонного контента.
— Просканируйте сайт любым краулером, найдите технические ошибки, и пофиксите их всех.
— Проанализируйте, какие всплывашки на вашем сайте показываются посетителям. Нет ли в них агрессивной рекламы, не ухудшают ли они пользовательский опыт?
— В целом проведите юзабилити-анализ вашего сайта, возможно есть узкие места, где пользователи постоянно спотыкаются.
— Убедитесь, что ваши посадочные страницы решают информационную потребность пользователя, который заходит на них по продвигаемым вами запросам.
— Для инфо-разделов убедитесь, что их авторами являются эксперты и это понятно посетителям, и через разметку поисковым роботам. Любой контент принадлежит автору и гуглу важно наличие экспертизы.
— И пересмотрите обратные ссылки. Они должны быть сделаны человеком и для человека.
Реализация всех этих пунктов не только вернет трафик сайту, но и заложит большой потенциал на будущее!
Отличного и продуктивного вам дня!
{kind=link}
Автоматизировать линкбилдинг - плохая затея. Но вот lun.ua с этим как-то работают и буквально через 10 мин Влад Моргун расскажет, как они измеряют «качество» физическими метриками ссылок. Готовьте вопросы:
https://youtu.be/ZJF0NASNi4Y
https://youtu.be/ZJF0NASNi4Y
⭐️⭐️⭐️⭐️⭐️ Оценки рейтинга
Интересно, что когда мы чему-то даем оценку в цифрах, то опираемся на свой культурный опыт, в частности на школьную систему оценок, к которой привыкли. В русскоязычных странах единица — означает плохо, а пятерка — отлично. Аналогичная система есть и в других странах, но не во всех она одинакова.
Возможно, вы замечали, что вам ставят одну звезду в рейтинге, но при этом пишут отличный отзыв? :) Оказывается, для некоторых стран 1 (единица) это наивысшая оценка. Среди них Германия, Австрия, Чехия.
https://ru.wikipedia.org/wiki/Система_оценивания_знаний#Чехия
Исключение разве что составляет тематика гостиничного бизнеса, где все привыкли, что чем больше звезд, тем лучше сервис. Но в других случаях, когда захотите использовать звездочки, имейте в виду, с какой аудиторией работаете.
Кроме звезд полезно использовать и другие метки (цвет, эмодзи, текстовые подписи).
P.S. Кстати, та же тема с восприятием таких символов, как палец вверх 👍🏻 или вниз 👎🏻. Теперь я знаю, что на канале у меня не хейтеры дают дизлайки, а просто лайкают добрые сеошники из Греции и Ближнего Востока :)
Интересно, что когда мы чему-то даем оценку в цифрах, то опираемся на свой культурный опыт, в частности на школьную систему оценок, к которой привыкли. В русскоязычных странах единица — означает плохо, а пятерка — отлично. Аналогичная система есть и в других странах, но не во всех она одинакова.
Возможно, вы замечали, что вам ставят одну звезду в рейтинге, но при этом пишут отличный отзыв? :) Оказывается, для некоторых стран 1 (единица) это наивысшая оценка. Среди них Германия, Австрия, Чехия.
https://ru.wikipedia.org/wiki/Система_оценивания_знаний#Чехия
Исключение разве что составляет тематика гостиничного бизнеса, где все привыкли, что чем больше звезд, тем лучше сервис. Но в других случаях, когда захотите использовать звездочки, имейте в виду, с какой аудиторией работаете.
Кроме звезд полезно использовать и другие метки (цвет, эмодзи, текстовые подписи).
P.S. Кстати, та же тема с восприятием таких символов, как палец вверх 👍🏻 или вниз 👎🏻. Теперь я знаю, что на канале у меня не хейтеры дают дизлайки, а просто лайкают добрые сеошники из Греции и Ближнего Востока :)
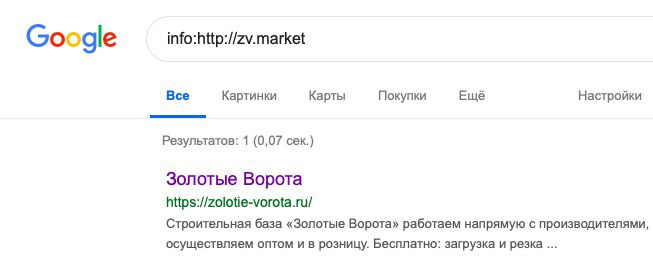
Вслед за rel=prev/next Google отменяет поддержку оператора info:, к которому мы так привыкли, проверяя склейку зеркал или урлов. Вместо функции этого оператора предлагают использовать URL Inspection Tool в поисковой консоли, соответственно, конкурентов уже никак не проверить.
https://webmasters.googleblog.com/2019/03/how-to-discover-suggest-google-selected.html
На данный момент оператор еще работает. Отключение будет в ближайшее время.
via @devakatalk
https://webmasters.googleblog.com/2019/03/how-to-discover-suggest-google-selected.html
На данный момент оператор еще работает. Отключение будет в ближайшее время.
via @devakatalk
{kind=link}
У нас с Игорем новый выпуск "На диване". Поговорили о популярных seo-мифах, которые мешают расти вашему сайту:
https://youtu.be/ZgMfyHSPMYw
https://youtu.be/ZgMfyHSPMYw
{kind=link}
Вчера основатель Ahrefs сообщил у себя в Твиттере, что мечтает создать конкурента Google. Две вещи, которые Диме сильно не нравятся с текущим поисковиком:
1. Отсутствие приватности
2. Заработок на чужом контенте
И вроде как мечту он уже готов реализовать, создать приватный поисковик и делиться заработком с издателями 90/10, не хватает только несколько разработчиков Rust & OCaml и тех, кто умеет работать с биг-дата, применяя ML.
Чувствуется вдохновленность Димы продуктами и идеологией Павла Дурова. Но последний пока не поддержал идею. Зато ее поддержали многие зарубежные сеошники, в том числе Брайан Дин и Цирус Шепард.
Но есть два момента, которые умышленно или неумышленно не были освещены в исходном треде.
1. Google это не просто краулер-поисковик. Это целая экосистема, внедренная в жизнь большей части планеты. У гугла есть операционная система, мобильные устройства, браузер, голосовой ассистент, карты, переводчик, мессенджер и множество других продуктов, органично взаимодействующих друг с другом и с поиском. А также 100,000 умнейших сотрудников и инженеров по всему миру. Сотрудничество в властями и различными брендами.
Если бы Google был просто краулером с отчетами, как Ahrefs, то это была бы совсем другая история. У Ahrefs есть нормальные серверные ресурсы и, возможно, пару миллионов долларов на новый проект. Но пока что это звучит как - не знаем, куда развиваться дальше.
2. Если ребят действительно волнует Profit Share, то почему бы это сначала не внедрить в Ahrefs? Он ведь тоже зарабатывает, сканируя и перепродавая чужие данные. Хотя бы открыли партнерку, которая была закрыта еще в 2013 году, как только Ahrefs понял, что может и без партнеров нормально развиваться.
Единственное объяснение вчерашнему посту Димы — привлечение внимания и возможных инвестиций. То, что ребятам удастся конкурировать с Google, я сильно сомневаюсь. Лучше продолжайте развивать Ahrefs, с этим у вас получается хорошо.
1. Отсутствие приватности
2. Заработок на чужом контенте
И вроде как мечту он уже готов реализовать, создать приватный поисковик и делиться заработком с издателями 90/10, не хватает только несколько разработчиков Rust & OCaml и тех, кто умеет работать с биг-дата, применяя ML.
Чувствуется вдохновленность Димы продуктами и идеологией Павла Дурова. Но последний пока не поддержал идею. Зато ее поддержали многие зарубежные сеошники, в том числе Брайан Дин и Цирус Шепард.
Но есть два момента, которые умышленно или неумышленно не были освещены в исходном треде.
1. Google это не просто краулер-поисковик. Это целая экосистема, внедренная в жизнь большей части планеты. У гугла есть операционная система, мобильные устройства, браузер, голосовой ассистент, карты, переводчик, мессенджер и множество других продуктов, органично взаимодействующих друг с другом и с поиском. А также 100,000 умнейших сотрудников и инженеров по всему миру. Сотрудничество в властями и различными брендами.
Если бы Google был просто краулером с отчетами, как Ahrefs, то это была бы совсем другая история. У Ahrefs есть нормальные серверные ресурсы и, возможно, пару миллионов долларов на новый проект. Но пока что это звучит как - не знаем, куда развиваться дальше.
2. Если ребят действительно волнует Profit Share, то почему бы это сначала не внедрить в Ahrefs? Он ведь тоже зарабатывает, сканируя и перепродавая чужие данные. Хотя бы открыли партнерку, которая была закрыта еще в 2013 году, как только Ahrefs понял, что может и без партнеров нормально развиваться.
Единственное объяснение вчерашнему посту Димы — привлечение внимания и возможных инвестиций. То, что ребятам удастся конкурировать с Google, я сильно сомневаюсь. Лучше продолжайте развивать Ahrefs, с этим у вас получается хорошо.
История одного приватного поисковика
Сейчас существует несколько приватных поисковых систем. Самые распространенные из них: DuckDuckGo, Qwant и StartPage. Но сегодня мы узнаем об еще одной — Findx, которая просуществовала ровно 3 года и была закрыта в конце 2018.
Приватная ПС это та, которая не собирает пользовательские данные, не гоняется с рекламой за пользователем, не продает/передает эти данные третьей стороне. Очень актуально в свете современных тенденций в области персональных данных. Но затрудняет монетизацию поиска.
DuckDuckGo (https://duckduckgo.com/) — один из популярных приватных поисковиков, так как встроен по умолчанию в браузер Tor. 20 млн. посетителей в сутки, около половины это США/Канада, остальной трафик размазан по Европе. Подтягивает данные из 400 источников, в том числе Bing, Yahoo и Яндекс. Монетизируется по партнерке с провайдерами поисковых данных.
StartPage (https://www.startpage.com/) — по сути тот же Google (данные берутся с него), но без логгирования/сохранения истории поиска. 3.5 млн. посетителей в сутки, сопоставимо с популярностью Яндекса в Турции, основной трафик это Германия, США, Франция и немного других европейских стран.
Qwant (https://www.qwant.com/) — разрабатывался как европейская альтернатива Google, но стал популярным только во Франции. 2 млн посетителей в сутки, отсутствие рекламы в принципе, наличие бесконечной прокрутки вместо пагинации. Сервис монетизируется за счет продажи своих технологий другим фирмам/сайтам, но это не точно. Некоторые источники утверждают, что Qwant это не поисковик, а просто прокси, так как результаты очень похожи на результаты Bing и Google.
Metager (https://metager.de/) — небольшой приватный немецкий поисковик. Кстати, на нем активно рекламится немецкий seo-сервис Sistrix. Неприбыльная организация, вместо рекламы использует партнерские ссылки и активно просит пользователей задонатить. Тянет данные с Bing и Scopia.
Findx (https://findx.com/) — задумывалась как опенсорсная приватная поисковая система, так и не вышла из беты, закрывшись в конце прошлого года. Ниже опыт создателя Findx для тех, кто думает организовать свой поисковик.
1/2
Сейчас существует несколько приватных поисковых систем. Самые распространенные из них: DuckDuckGo, Qwant и StartPage. Но сегодня мы узнаем об еще одной — Findx, которая просуществовала ровно 3 года и была закрыта в конце 2018.
Приватная ПС это та, которая не собирает пользовательские данные, не гоняется с рекламой за пользователем, не продает/передает эти данные третьей стороне. Очень актуально в свете современных тенденций в области персональных данных. Но затрудняет монетизацию поиска.
DuckDuckGo (https://duckduckgo.com/) — один из популярных приватных поисковиков, так как встроен по умолчанию в браузер Tor. 20 млн. посетителей в сутки, около половины это США/Канада, остальной трафик размазан по Европе. Подтягивает данные из 400 источников, в том числе Bing, Yahoo и Яндекс. Монетизируется по партнерке с провайдерами поисковых данных.
StartPage (https://www.startpage.com/) — по сути тот же Google (данные берутся с него), но без логгирования/сохранения истории поиска. 3.5 млн. посетителей в сутки, сопоставимо с популярностью Яндекса в Турции, основной трафик это Германия, США, Франция и немного других европейских стран.
Qwant (https://www.qwant.com/) — разрабатывался как европейская альтернатива Google, но стал популярным только во Франции. 2 млн посетителей в сутки, отсутствие рекламы в принципе, наличие бесконечной прокрутки вместо пагинации. Сервис монетизируется за счет продажи своих технологий другим фирмам/сайтам, но это не точно. Некоторые источники утверждают, что Qwant это не поисковик, а просто прокси, так как результаты очень похожи на результаты Bing и Google.
Metager (https://metager.de/) — небольшой приватный немецкий поисковик. Кстати, на нем активно рекламится немецкий seo-сервис Sistrix. Неприбыльная организация, вместо рекламы использует партнерские ссылки и активно просит пользователей задонатить. Тянет данные с Bing и Scopia.
Findx (https://findx.com/) — задумывалась как опенсорсная приватная поисковая система, так и не вышла из беты, закрывшись в конце прошлого года. Ниже опыт создателя Findx для тех, кто думает организовать свой поисковик.
1/2
Мечтой разработчиков Findx было создание альтернативы Google, независимого приватного поисковика. Ребята разработали сам движок, десктопный браузер и ряд расширений и мобильных приложений. Оглядываясь в прошлое, создатели полагают, что запустили проект слишком рано, люди только сейчас начали активно говорить о приватности.
Основные причины, которые не дали проекту развиваться:
— Между приватностью и удобством, люди предпочитают удобство. Очень сложно сражаться с монополией и удобством гугла.
— Большой проблемой Findx был выбор опенсорс-проекта Gigablast, который имел кучу багов и им управлял один человек, который постоянно исчезал.
— Собственный поисковик жрет много ресурсов, нужны дата-центры, умные краулеры, большие объемы дискового хранилища, умные алгоритмы ранжирования. И все это нужно уметь быстро масштабировать.
— Краулить интернет не так просто. Из-за багов в работе краулера Findx занесли в черные списки Project Honeypot, которые используются всеми популярными CDN-провайдерами. Робот не видел половину сайтов интернета, так как CDN-провайдеры блокировали доступ "плохому боту".
— Большие проекты типа LinkedIn, Quora, Yelp, Github, Facebook и пр. открывают доступ к сканированию своего контента только определенным ботам типа Google и Bing. Из-за этого Findx не мог давать пользователям всегда хорошие результаты поиска.
— Количество спама и вредоносных страниц в сети намного больше, чем вы думаете. И программно их определить сложно. В Google работают тысячи асессоров, чтобы решить эту проблему.
— Есть ряд технических сложностей в понимании поискового запроса и поиска релевантных ответов на разных языках, а в Европе языков очень много. Findx лучше всего работал с датским языком, так как сотрудничал с одним из датских лингвистов.
— Монетизировать приватный поиск сложно. Рекламодатели хотят знать инфу о пользователях, чтобы настраивать таргетинг. Были попытки сотрудничать с Bing и Yahoo, как делают другие приватные поисковики, но тем не интересны проекты без большого трафика. Это убило всю идею монетизации.
Все эти причины сделали Findx нежизнеспособным. Разработчик пожелал удачи Диме Герасименко в недавнем твиттер-треде.
2/2
Основные причины, которые не дали проекту развиваться:
— Между приватностью и удобством, люди предпочитают удобство. Очень сложно сражаться с монополией и удобством гугла.
— Большой проблемой Findx был выбор опенсорс-проекта Gigablast, который имел кучу багов и им управлял один человек, который постоянно исчезал.
— Собственный поисковик жрет много ресурсов, нужны дата-центры, умные краулеры, большие объемы дискового хранилища, умные алгоритмы ранжирования. И все это нужно уметь быстро масштабировать.
— Краулить интернет не так просто. Из-за багов в работе краулера Findx занесли в черные списки Project Honeypot, которые используются всеми популярными CDN-провайдерами. Робот не видел половину сайтов интернета, так как CDN-провайдеры блокировали доступ "плохому боту".
— Большие проекты типа LinkedIn, Quora, Yelp, Github, Facebook и пр. открывают доступ к сканированию своего контента только определенным ботам типа Google и Bing. Из-за этого Findx не мог давать пользователям всегда хорошие результаты поиска.
— Количество спама и вредоносных страниц в сети намного больше, чем вы думаете. И программно их определить сложно. В Google работают тысячи асессоров, чтобы решить эту проблему.
— Есть ряд технических сложностей в понимании поискового запроса и поиска релевантных ответов на разных языках, а в Европе языков очень много. Findx лучше всего работал с датским языком, так как сотрудничал с одним из датских лингвистов.
— Монетизировать приватный поиск сложно. Рекламодатели хотят знать инфу о пользователях, чтобы настраивать таргетинг. Были попытки сотрудничать с Bing и Yahoo, как делают другие приватные поисковики, но тем не интересны проекты без большого трафика. Это убило всю идею монетизации.
Все эти причины сделали Findx нежизнеспособным. Разработчик пожелал удачи Диме Герасименко в недавнем твиттер-треде.
2/2
{kind=link}
Forwarded from SEO-специалист (seospecialist)
Пока мы размышляли про создание поисковика, Яндекс выкатил обновку для справочника: теперь, при регистрации компании в Яндекс.Справочнике, не обязательно указывать фактический адрес.
Продвижение по регионам пойдет куда проще и продуктивнее. Спасибо, Яндекс (не думал, что когда-то так напишу)
Продвижение по регионам пойдет куда проще и продуктивнее. Спасибо, Яндекс (не думал, что когда-то так напишу)
{kind=link}
Forwarded from SEO 404: про маркетинг та життя з Михайлом Щербачовим
И у Google бывают провалы. Я не говорю о закрытии Inbox и Google Plus.
154 закрытых продукта. Все что хотели сделать и не получилось.
Набрел случайно на ссылку https://killedbygoogle.com/
Там можно посмотреть весь список убитых Гуглом продуктов.
Осторожно! Можно залипнуть.
154 закрытых продукта. Все что хотели сделать и не получилось.
Набрел случайно на ссылку https://killedbygoogle.com/
Там можно посмотреть весь список убитых Гуглом продуктов.
Осторожно! Можно залипнуть.
Помните тот эксперимент с поведенческими факторами?
По запросу "seopro" продвигать украинский сайт в русском гугле - плохая затея, особенно, если по семантике видно, что людям нужны плагины.
Но, спустя 1 месяц, страница курса - 1 место! 🧐
— 25.02 - 19 позиция
— 26.02 - 18
— 28.02 - вылетело из топа до 20.03 из-за отрицательной функции перехода
— 20.03 - железно 1 позиция
Так что индуская стратегия с размещением скрина гугла с нужным запросом на билбордах вполне работает. 😃
P.S. Спасибо всем, кто принял участие в эксперименте. 👍🏻
По запросу "seopro" продвигать украинский сайт в русском гугле - плохая затея, особенно, если по семантике видно, что людям нужны плагины.
Но, спустя 1 месяц, страница курса - 1 место! 🧐
— 25.02 - 19 позиция
— 26.02 - 18
— 28.02 - вылетело из топа до 20.03 из-за отрицательной функции перехода
— 20.03 - железно 1 позиция
Так что индуская стратегия с размещением скрина гугла с нужным запросом на билбордах вполне работает. 😃
P.S. Спасибо всем, кто принял участие в эксперименте. 👍🏻
{kind=link}
Смотреть чужие ТЗ для копирайтеров интересно, но вам мало чем поможет. Так как ТЗ это всего лишь способ коммуникации с копирайтером, который зависит от внутренних процессов в компании, от традиций и предпочтений. Чужие процессы внедрить у себя - не получится.
3 направления взаимодействия с копирайтерами:
1. Поиск специалиста
ТЗ на этом этапе не нужно. А нужны некие критерии, по которым вы отберете несколько человек. Возможно, это будет опыт работы в какой-то нише, профессия, рекомендации, расценки, примеры работ.
2. Проверка качества текста, который способен произвести выбранный вами специалист
Здесь нужно составить тестовое ТЗ для всех, в котором указать, куда вам нужен текст, кто целевая аудитория, какие ключевые слова необходимо использовать, какой объем и другие пожелания. На выходе получите ряд текстов, которые теперь можно сравнить методом "пристального взгляда" (или любым другим, если у вас есть особый метод проверки качества) и оставить нескольких копирайтеров из всех для дальнейшей работы.
3. Постоянное взаимодействие с выбранными копирайтерами
И вот на этом этапе нужно объяснить копирайтерам, договориться с ними, как вы будете взаимодействовать, что хотите получить и в каком формате. Тут полезно составить внутренние инструкции. А ТЗ будет уже включать просто необходимые начальные данные для работы. Например, в ТЗ вы можете указывать желаемый объем текста и список ключевых слов, нужные заголовки и структура материала, если он объемный.
Некоторые проверяют копирайтеров на живых проектах, что тоже хорошо. Каждому копирайтеру дается свой раздел и позже наблюдают, какой из разделов лучше развивается (по seo-метрикам). Но на этом этапе копирайтер уже должен быть ознакомлен с внутренними инструкциями. И, все-таки, без предварительного "отсева" по качеству такие живые тесты могут погубить проект.
Итак, вам понадобится 3 документа. Первый составляете один раз - это тестовое ТЗ для копирайтера, без лишней информации, просто чтобы проверить качество. Второй документ - внутренняя инструкция со всеми необходимыми подробностями, касающихся как текстов, так и источников данных, оформления, подбора изображений и других деталей, в зависимости от проекта и размера вашей команды. И третий документ это просто заявка на новый текст, которую ваш копирайтер уже знает как обработать. Смотреть чужие заявки на текст без знания других документов и особенностей проекта - плохая затея. Составляйте свои!
P.S. Больше подробностей по взаимодействию с копирайтерами есть в курсе о семантическом проектировании сайтов - semantica.devaka.ru
3 направления взаимодействия с копирайтерами:
1. Поиск специалиста
ТЗ на этом этапе не нужно. А нужны некие критерии, по которым вы отберете несколько человек. Возможно, это будет опыт работы в какой-то нише, профессия, рекомендации, расценки, примеры работ.
2. Проверка качества текста, который способен произвести выбранный вами специалист
Здесь нужно составить тестовое ТЗ для всех, в котором указать, куда вам нужен текст, кто целевая аудитория, какие ключевые слова необходимо использовать, какой объем и другие пожелания. На выходе получите ряд текстов, которые теперь можно сравнить методом "пристального взгляда" (или любым другим, если у вас есть особый метод проверки качества) и оставить нескольких копирайтеров из всех для дальнейшей работы.
3. Постоянное взаимодействие с выбранными копирайтерами
И вот на этом этапе нужно объяснить копирайтерам, договориться с ними, как вы будете взаимодействовать, что хотите получить и в каком формате. Тут полезно составить внутренние инструкции. А ТЗ будет уже включать просто необходимые начальные данные для работы. Например, в ТЗ вы можете указывать желаемый объем текста и список ключевых слов, нужные заголовки и структура материала, если он объемный.
Некоторые проверяют копирайтеров на живых проектах, что тоже хорошо. Каждому копирайтеру дается свой раздел и позже наблюдают, какой из разделов лучше развивается (по seo-метрикам). Но на этом этапе копирайтер уже должен быть ознакомлен с внутренними инструкциями. И, все-таки, без предварительного "отсева" по качеству такие живые тесты могут погубить проект.
Итак, вам понадобится 3 документа. Первый составляете один раз - это тестовое ТЗ для копирайтера, без лишней информации, просто чтобы проверить качество. Второй документ - внутренняя инструкция со всеми необходимыми подробностями, касающихся как текстов, так и источников данных, оформления, подбора изображений и других деталей, в зависимости от проекта и размера вашей команды. И третий документ это просто заявка на новый текст, которую ваш копирайтер уже знает как обработать. Смотреть чужие заявки на текст без знания других документов и особенностей проекта - плохая затея. Составляйте свои!
P.S. Больше подробностей по взаимодействию с копирайтерами есть в курсе о семантическом проектировании сайтов - semantica.devaka.ru
content-digitalnn.pdf
3.9 MB
Правильное SEO это не о продвижении сайта по запросу, а о понимании, что хочет видеть пользователь и создание именно такого контента.
Моя презентация со вчерашнего выступления на Digital Оттепели про то, как подружить контент и SEO.
Моя презентация со вчерашнего выступления на Digital Оттепели про то, как подружить контент и SEO.