
Forwarded from Gopher Academy
☝️👆👆👆
دوستان عزیز، این پستی که ریپلای کردم بهروزرسانی میشه ✨
میتونید ادامهی مقالات این بخش رو همیشه از همینجا دنبال کنید و بخونید 📚
🔗 لینک کانالهامون:
https://t.iss.one/addlist/AJ7rh2IzIh02NTI0
💰 لینک حمایت مالی:
https://www.coffeete.ir/mrbardia72
🚀لینک تلگرام بوست:
https://t.iss.one/boost/gopher_academy
دوستان عزیز، این پستی که ریپلای کردم بهروزرسانی میشه ✨
میتونید ادامهی مقالات این بخش رو همیشه از همینجا دنبال کنید و بخونید 📚
🔗 لینک کانالهامون:
https://t.iss.one/addlist/AJ7rh2IzIh02NTI0
💰 لینک حمایت مالی:
https://www.coffeete.ir/mrbardia72
🚀لینک تلگرام بوست:
https://t.iss.one/boost/gopher_academy
Forwarded from a pessimistic researcher (Kc)
یعنی اگر Patrick Cousot بشم، Radhia Cousot میشه برام؟
Forwarded from linuxtnt(linux tips and tricks) (hosein seilany https://seilany.ir/)
نحوه ایجاد نام مستعار (میانبر) برای دستورات رایج در لینوکس
در واقع آموزش alias در لینوکس در پست زیر است:
https://learninghive.ir/alias/
در واقع آموزش alias در لینوکس در پست زیر است:
https://learninghive.ir/alias/
Forwarded from Sadra Codes
Wtf is “Vibe Coding”? Either code, or get the f out of the room. 🥸
Audio
رادیوجادی ۲۰۰ - هکرهای انانیموس و ۴چن و بقیه قصههاشون
در شماره ۲۰۰ رادیو جادی بالاخره سراغ بحث اصلی میریم: هکرهای ناشناس و فروم افسانهای ۴چن. توی این شماره براتون از تاریخ می گم و از خاطره و از مبارزه علیه کسانی که نمیخوان اینترنت، اینترنت ما باشه!
ما ناشناس هستیم، ما یک ارتش هستیم، ما نمیبخشیم، ما فراموش نمیکنیم، منتظر ما باشید!
ولی شایدم ببخشیم... اما به یک شرط!
#پادکست #رادیوجادی
https://youtu.be/C-ZK0GB1J9c
در شماره ۲۰۰ رادیو جادی بالاخره سراغ بحث اصلی میریم: هکرهای ناشناس و فروم افسانهای ۴چن. توی این شماره براتون از تاریخ می گم و از خاطره و از مبارزه علیه کسانی که نمیخوان اینترنت، اینترنت ما باشه!
ما ناشناس هستیم، ما یک ارتش هستیم، ما نمیبخشیم، ما فراموش نمیکنیم، منتظر ما باشید!
ولی شایدم ببخشیم... اما به یک شرط!
#پادکست #رادیوجادی
https://youtu.be/C-ZK0GB1J9c
Forwarded from 🎄 یک برنامه نویس تنبل (Lazy 🌱)
Forwarded from 🎄 یک برنامه نویس تنبل (Lazy 🌱)
Forwarded from دستاوردهای یادگیری عمیق(InTec)
اینو میگم که دیگه اتفاق نیوفته؛
روی کدهای
باید از
واقعا فکر نمیکردم هیجوقت لازم بشه این نکته رو بگم تا اینکه امروز دیدم یک شرکتی که درآمدش هم تو ایران کم نیست داره
قبل از اینکه با لقب سنیورتون همرو ... کنید؛ حداقل ۲ تا مطلب طراحی سیستم بخونید.
پیونشت (شما گفتید) :
روزای اول بعضی شرکتها رفته بودن سراغ
روی کدهای
LLM توی بکند و فرانت long polling جواب نیستا!باید از
SSE استفاده کنید.واقعا فکر نمیکردم هیجوقت لازم بشه این نکته رو بگم تا اینکه امروز دیدم یک شرکتی که درآمدش هم تو ایران کم نیست داره
long poll استفاده میکنه بجای SSE توی سرویسهای LLM اش.قبل از اینکه با لقب سنیورتون همرو ... کنید؛ حداقل ۲ تا مطلب طراحی سیستم بخونید.
پیونشت (شما گفتید) :
روزای اول بعضی شرکتها رفته بودن سراغ
web-socket برای سرویس دهی.Forwarded from DevTwitter | توییت برنامه نویسی
This media is not supported in your browser
VIEW IN TELEGRAM
بعد ازینکه تونستم هوش مصنوعی ollama رو با مدل gemma3 تو کامپیوتر خودم اجرا کنم ، به کمک claude کدی نوشتم که با api ای که خود ollama روی localhost میده ارتباط برقرار میکنه و اینجوری میتونم api هوش مصنوعی خودم رو رایگان داشته باشم ، اصنم سنگین نیست و منابع خیلی کمی رو مصرف میکنه
@DevTwitter | <گربهی برنامهنویس/>
@DevTwitter | <گربهی برنامهنویس/>
Forwarded from PhiloLearn | فیلولرن
{kind=link}
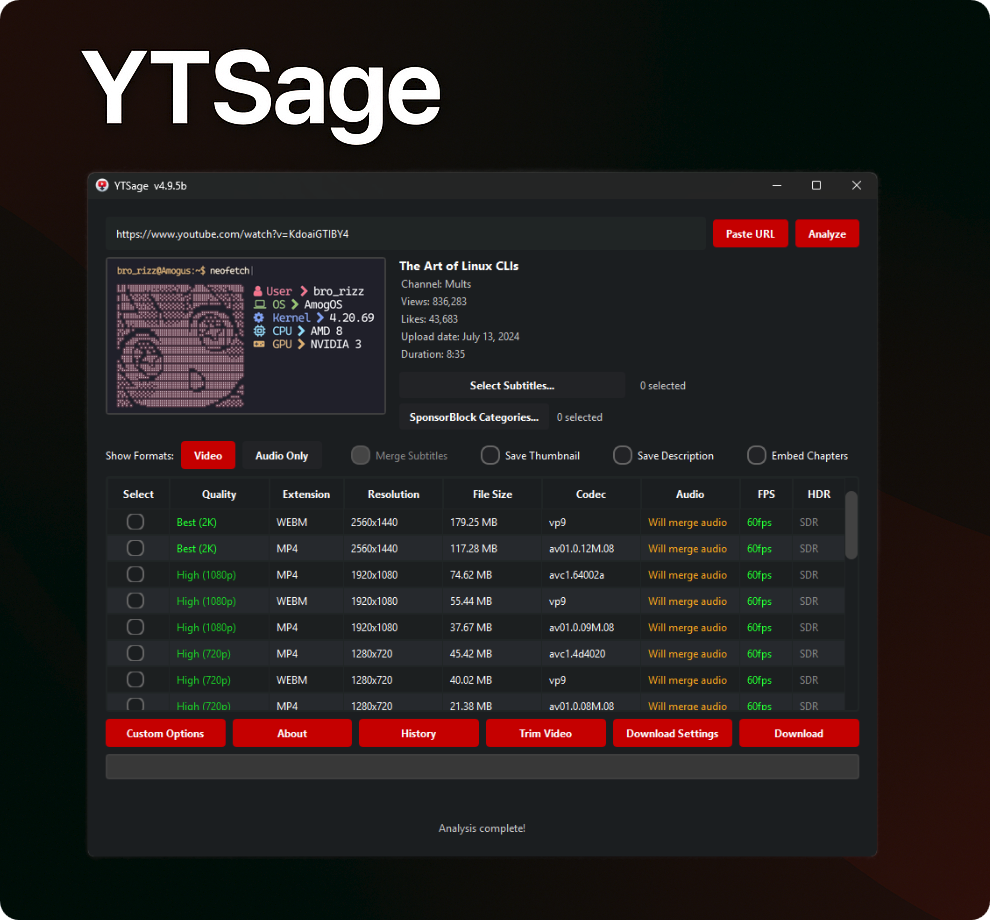
YTSage یه نرمافزار خیلی ساده و مدرن برای دانلود از یوتیوبه که با PySide6 ساخته شده. باهاش میتونی ویدیو رو تو هر کیفیتی بگیری، فقط صداشو دربیاری، زیرنویسشو دانلود کنی، چسبوندن زیرنویس، ذخیره کردن تامبنیل یا توضیحات ویدیو انجام بدی. روی ویندوز، لینوکس و مک هم راحت نصب میشه و بدون دردسر بالا میاد 🤦🏻♂️😂.
🔹 شروع سریع
کافیه اینو بزنی:
🔹 روش استفاده
۱. برنامه رو اجرا کن.
۲. لینک ویدیو یا پلیلیست یوتیوب رو بنداز توش.
۳. فرمت مورد نظرت رو انتخاب کن (ویدیو یا فقط صدا).
۴. اگه حال داشتی، آپشنای اضافه مثل گرفتن زیرنویس یا حذف اسپانسر رو فعال کن.
۵. مسیر ذخیره رو مشخص کن و بزن روی دانلود.
💙 @PhiloLearn
🔹 شروع سریع
کافیه اینو بزنی:
python3 -m venv venv
source venv/bin/activate
pip install ytsage
🔹 روش استفاده
۱. برنامه رو اجرا کن.
۲. لینک ویدیو یا پلیلیست یوتیوب رو بنداز توش.
۳. فرمت مورد نظرت رو انتخاب کن (ویدیو یا فقط صدا).
۴. اگه حال داشتی، آپشنای اضافه مثل گرفتن زیرنویس یا حذف اسپانسر رو فعال کن.
۵. مسیر ذخیره رو مشخص کن و بزن روی دانلود.
💙 @PhiloLearn
Forwarded from Ninja Learn | نینجا لرن (Mohammad)
طبیعیه وقتی قهوه میخورم انگار چیت ذهن زدم؟
(چاکراهام باز میشه انگار 😂)
(چاکراهام باز میشه انگار 😂)
Forwarded from Linuxor ?
This media is not supported in your browser
VIEW IN TELEGRAM
ابزار و فریمورک MobSF یکی از معروف ترین ابزار های بررسی امنیت اپلیکیشنهای موبایل هستش هم اندروید رو پشتیبانی میکنه، هم iOS و حتی Windows. هم قابلیت تحلیل ایستا (Static Analysis) داره یعنی اپلیکیشن رو بدون اجرا کردنش بررسی میکنه. فایل APK یا IPA رو باز میکنه، نگاه میکنه چه مجوزهایی میخواد، چه APIهایی استفاده کرده، آیا کد مشکوکی داره یا نه. هم تحلیل پویا (Dynamic Analysis) که اپ رو اجرا میکنه و رفتارش رو زیر نظر میگیره؛ مثلا میبینه چه جاهایی به اینترنت وصل میشه، دادهها چطور منتقل میشن، یا برنامه چه واکنشی نسبت به حملهها نشون میده.
برای نصبش هم یه اسکریپت داره اونو باید اجرا کنید (اگه داکر دارید که با یه کامند داکری بالا میآد)
github.com/MobSF/Mobile-Security-Framework-MobSF
از اینجا هم میتونید یه سری مستندات و راهنمایی ها دربارش بخونید :
mobsf.github.io/docs
@Linuxor
برای نصبش هم یه اسکریپت داره اونو باید اجرا کنید (اگه داکر دارید که با یه کامند داکری بالا میآد)
github.com/MobSF/Mobile-Security-Framework-MobSF
از اینجا هم میتونید یه سری مستندات و راهنمایی ها دربارش بخونید :
mobsf.github.io/docs
@Linuxor
Forwarded from NetSentinel24Support
🚨 اگر میخوای قبل از همه بفهمی سایت یا سرورت Down شده و اولین نفر از Down Time باخبر شی
🔒 اگر میخوای قبل از منقضی شدن SSL سایتت، متوجه بشی و Renew کنی SSL رو
⚡️ اگر دوست داری UP Time یک پورت از سرورت رو بررسی کنی
📊 اگر میخوای مطمئن باشی سرورات همیشه زیر نظرن و گزارشگیری داشته باشی
🤖 مجموعهی ما میتونه کمکت کنه!
🚀 شروع کن با ربات: @NetSentinel24Bot
📌 کانال: @NetSentinel24
🤙 پشتیبانی: @NetSentinel24Support
🔥 حرفهایها همیشه یه نگهبان دارن!
🔒 اگر میخوای قبل از منقضی شدن SSL سایتت، متوجه بشی و Renew کنی SSL رو
⚡️ اگر دوست داری UP Time یک پورت از سرورت رو بررسی کنی
📊 اگر میخوای مطمئن باشی سرورات همیشه زیر نظرن و گزارشگیری داشته باشی
🤖 مجموعهی ما میتونه کمکت کنه!
🚀 شروع کن با ربات: @NetSentinel24Bot
📌 کانال: @NetSentinel24
🤙 پشتیبانی: @NetSentinel24Support
🔥 حرفهایها همیشه یه نگهبان دارن!
Forwarded from Linuxor ?
اینجا یه جاست که همه چیزای باحال و مفید برای طراحی و دیزاین رو جمع کرده. یعنی چه بخوای طراحی وب یا اپلیکیشن بکنی، چه بخوای یه چیزی بسازی برای ایده گرفتن، این ریپو میتونه کمکت کنه. توش لینک به عکس و ویدیوهای رایگان هست، آیکون و لوگو هست، رنگ و فونت مناسب پیدا میکنی، چیزای مرتبط با ابزارای طراحی مثل Figma و Sketch هست و حتی میتونی نمونه اولیه طراحیت رو بسازی یا با ابزارای تست تجربه کاربری ببینی کاربران چه حسی دارن. بهطور خلاصه، دیگه لازم نیست دنبال این چیزا تو اینترنت بگردی، همه چیز یه جاست و میتونی پروژهت رو راحتتر و سریعتر پیش ببری.
github.com/gztchan/awesome-design
@Linuxor
github.com/gztchan/awesome-design
@Linuxor
Forwarded from DevTwitter | توییت برنامه نویسی
مایکروسافت یک فریمورک جامع چندزبانه برای ساخت، اورکستریشن و دیپلوی ایجنتهای هوش مصنوعی ارائه کرده است.
- بر پایهی Semantic Kernel و AutoGen
- پشتیبانی از .NET و Python
- از ایجنتهای ساده تا ورکفلوهای چندایجنتی با گراف اورکستریشن
https://github.com/microsoft/agent-framework?tab=readme-ov-file
@DevTwitter | <Sam92/>
- بر پایهی Semantic Kernel و AutoGen
- پشتیبانی از .NET و Python
- از ایجنتهای ساده تا ورکفلوهای چندایجنتی با گراف اورکستریشن
https://github.com/microsoft/agent-framework?tab=readme-ov-file
@DevTwitter | <Sam92/>
Forwarded from Linuxor ?
یه چیز باحال؛ بیاین فرض کنیم هوش مصنوعی جای سایت هایی مثل stackoverflow رو بگیره و کلا حذفشون کنه. اینم میدونیم که مدل های هوش مصنوعی از روی اینها ترین شدن و چیزی فراتر از اینا نمیدونن؛ سوال اصلی اینه به مرور زمان مشکلات جدید که پیش میان چطوری حل میشن؟ بالاخره باید بازخورد های انسانی توی این فرایند دخیل باشن :)
توی بد ترین حالت سال های آینده اگه همینطوری پیش بره باید یه جایی درست بشه که هوش مصنوعی بیاد توش و سوالای مهمی که کاربرا ازش پرسیدن و نتونسته جواب بده و نیاز به تجربه داره رو از آدما بپرسه :)
@Linuxor
توی بد ترین حالت سال های آینده اگه همینطوری پیش بره باید یه جایی درست بشه که هوش مصنوعی بیاد توش و سوالای مهمی که کاربرا ازش پرسیدن و نتونسته جواب بده و نیاز به تجربه داره رو از آدما بپرسه :)
@Linuxor
Forwarded from 🎄 یک برنامه نویس تنبل (Lazy 🌱)
Forwarded from Linuxor ?
Forwarded from Reza Jafari
چطور بفهمیم مدلمون در Production درست کار میکنه وقتی Label نداریم؟
وقتی یه machine learning model رو میبری تو production و دیگه label در دسترس نداری، داستان ارزیابی خیلی فرق میکنه. اینجا دیگه نمیتونی مثل محیط آزمایشی به راحتی با معیارهایی مثل accuracy یا recall مدل رو بسنجی. پس باید به سراغ روشهای غیرمستقیم بری. یکی از مهمترین کارها پایش دادهها و خروجی مدل هست. یعنی باید ببینی دادههای ورودی هنوز شبیه دادههای زمان آموزش هستن یا نه. برای این کار از روشهایی مثل KL-divergence یا PSI استفاده میکنن. همینطور خروجیهای مدل رو بررسی میکنی؛ مثلاً توزیع احتمالات یا مقادیر پیشبینی شده. اگه الگوها تغییر عجیب و غریبی داشتن، احتمالاً مدل داره از مسیر اصلی خارج میشه. یه موضوع دیگه هم بحث uncertainty یا confidence مدله؛ اگه مدل یه دفعه خیلی مطمئن یا برعکس خیلی مردد شد، اونم یه زنگ خطره.
از طرف دیگه همیشه میتونی به فکر گرفتن label جزئی یا دستی باشی. روشهایی مثل active learning کمک میکنن که فقط یه بخش کوچیک از پیشبینیها رو به کارشناس یا آدم واقعی بدی برای برچسبگذاری. حتی میتونی توی سیستم shadow testing یا spot checking پیادهسازی کنی که بخشی از دادهها رو برای بررسی انسانی نگه داری. اینجوری یه تصویر نسبی از عملکرد مدل پیدا میکنی بدون اینکه همه دادهها رو نیاز به برچسب داشته باشی.
یه راه خیلی کاربردی دیگه اینه که به جای label مستقیم، سراغ KPIهای بیزنسی بری. مثلاً با A/B testing نسخههای مختلف مدل رو روی کاربرها امتحان کنی و ببینی کدوم بهتر روی معیارهایی مثل conversion rate یا CTR اثر میذاره. توی سیستمهای recommendation یا ads هم میتونی از روشهای off-policy evaluation استفاده کنی و با دادههای گذشته تخمین بزنی اگه مدل جدید بود، چه نتایجی میگرفتی.
علاوه بر این، بحث سازگاری و توافق هم مهمه. مثلاً میتونی چند مدل مختلف رو همزمان اجرا کنی و هر وقت اختلاف زیادی بین خروجیها دیدی، بفهمی یه جای کار میلنگه. یا با قوانین قطعی و دانش حوزه (domain knowledge) مقایسه کنی؛ مثلاً مدلی که پیشبینی منفی برای چیزی میده که ذاتاً نمیتونه منفی باشه، معلومه اشتباه داره. همینطور تستهای consistency هم جواب میده؛ یعنی ورودی رو کمی تغییر بدی (مثلاً تصویر رو بچرخونی یا متن رو paraphrase کنی) و ببینی مدل همچنان پایدار جواب میده یا نه.
در کنار اینها میتونی از weak supervision یا pseudo-labeling کمک بگیری. یعنی یا با قوانین ساده یه جور label مصنوعی درست کنی یا پیشبینیهای خیلی مطمئن مدل رو به عنوان برچسب موقت در نظر بگیری و با یه مدل دوم بررسی کنی که چقدر با هم هماهنگن.
یه سناریوی دیگه هم پایش بلندمدته. توی بعضی حوزهها مثل fraud detection یا churn prediction، label با تأخیر به دست میاد. پس باید پیشبینیهای الان رو ذخیره کنی تا بعداً که برچسب واقعی رسید، بتونی کیفیت مدل رو بسنجی. یا اینکه از روش canary release استفاده کنی، یعنی اول مدل رو روی یه بخش کوچیک از کاربرها امتحان کنی، اگه همهچیز اوکی بود کمکم برای همه rollout کنی.
در نهایت بسته به نوع مسئله هم روشهای خاص خودش رو داره. مثلاً تو classification باید حواست به تعادل کلاسها و calibration باشه، تو regression میانگین و واریانس خروجیها مهم میشه، تو recommendation بیشتر سراغ شاخصهایی مثل CTR یا زمان تعامل (dwell time) میری، و تو anomaly detection نرخ anomaly رو در طول زمان دنبال میکنی.
خلاصه اینکه وقتی label نداری، ارزیابی مستقیم ممکن نیست. پس باید ترکیبی از پایش داده و خروجیها، گرفتن label جزئی یا با تأخیر، بررسی KPIهای بیزنسی و تستهای سازگاری رو استفاده کنی تا مطمئن بشی مدل توی production هنوز درست و سالم کار میکنه.
🔤 🔤 🔤 🔤 🔤 🔤 🔤
🥇 اهورا اولین اپراتور هوش مصنوعی راهبردی ایران در حوزه ارائه خدمات و سرویسهای زیرساخت هوش مصنوعی
🌐 لینک ارتباط با اهورا
@reza_jafari_ai
وقتی یه machine learning model رو میبری تو production و دیگه label در دسترس نداری، داستان ارزیابی خیلی فرق میکنه. اینجا دیگه نمیتونی مثل محیط آزمایشی به راحتی با معیارهایی مثل accuracy یا recall مدل رو بسنجی. پس باید به سراغ روشهای غیرمستقیم بری. یکی از مهمترین کارها پایش دادهها و خروجی مدل هست. یعنی باید ببینی دادههای ورودی هنوز شبیه دادههای زمان آموزش هستن یا نه. برای این کار از روشهایی مثل KL-divergence یا PSI استفاده میکنن. همینطور خروجیهای مدل رو بررسی میکنی؛ مثلاً توزیع احتمالات یا مقادیر پیشبینی شده. اگه الگوها تغییر عجیب و غریبی داشتن، احتمالاً مدل داره از مسیر اصلی خارج میشه. یه موضوع دیگه هم بحث uncertainty یا confidence مدله؛ اگه مدل یه دفعه خیلی مطمئن یا برعکس خیلی مردد شد، اونم یه زنگ خطره.
از طرف دیگه همیشه میتونی به فکر گرفتن label جزئی یا دستی باشی. روشهایی مثل active learning کمک میکنن که فقط یه بخش کوچیک از پیشبینیها رو به کارشناس یا آدم واقعی بدی برای برچسبگذاری. حتی میتونی توی سیستم shadow testing یا spot checking پیادهسازی کنی که بخشی از دادهها رو برای بررسی انسانی نگه داری. اینجوری یه تصویر نسبی از عملکرد مدل پیدا میکنی بدون اینکه همه دادهها رو نیاز به برچسب داشته باشی.
یه راه خیلی کاربردی دیگه اینه که به جای label مستقیم، سراغ KPIهای بیزنسی بری. مثلاً با A/B testing نسخههای مختلف مدل رو روی کاربرها امتحان کنی و ببینی کدوم بهتر روی معیارهایی مثل conversion rate یا CTR اثر میذاره. توی سیستمهای recommendation یا ads هم میتونی از روشهای off-policy evaluation استفاده کنی و با دادههای گذشته تخمین بزنی اگه مدل جدید بود، چه نتایجی میگرفتی.
علاوه بر این، بحث سازگاری و توافق هم مهمه. مثلاً میتونی چند مدل مختلف رو همزمان اجرا کنی و هر وقت اختلاف زیادی بین خروجیها دیدی، بفهمی یه جای کار میلنگه. یا با قوانین قطعی و دانش حوزه (domain knowledge) مقایسه کنی؛ مثلاً مدلی که پیشبینی منفی برای چیزی میده که ذاتاً نمیتونه منفی باشه، معلومه اشتباه داره. همینطور تستهای consistency هم جواب میده؛ یعنی ورودی رو کمی تغییر بدی (مثلاً تصویر رو بچرخونی یا متن رو paraphrase کنی) و ببینی مدل همچنان پایدار جواب میده یا نه.
در کنار اینها میتونی از weak supervision یا pseudo-labeling کمک بگیری. یعنی یا با قوانین ساده یه جور label مصنوعی درست کنی یا پیشبینیهای خیلی مطمئن مدل رو به عنوان برچسب موقت در نظر بگیری و با یه مدل دوم بررسی کنی که چقدر با هم هماهنگن.
یه سناریوی دیگه هم پایش بلندمدته. توی بعضی حوزهها مثل fraud detection یا churn prediction، label با تأخیر به دست میاد. پس باید پیشبینیهای الان رو ذخیره کنی تا بعداً که برچسب واقعی رسید، بتونی کیفیت مدل رو بسنجی. یا اینکه از روش canary release استفاده کنی، یعنی اول مدل رو روی یه بخش کوچیک از کاربرها امتحان کنی، اگه همهچیز اوکی بود کمکم برای همه rollout کنی.
در نهایت بسته به نوع مسئله هم روشهای خاص خودش رو داره. مثلاً تو classification باید حواست به تعادل کلاسها و calibration باشه، تو regression میانگین و واریانس خروجیها مهم میشه، تو recommendation بیشتر سراغ شاخصهایی مثل CTR یا زمان تعامل (dwell time) میری، و تو anomaly detection نرخ anomaly رو در طول زمان دنبال میکنی.
خلاصه اینکه وقتی label نداری، ارزیابی مستقیم ممکن نیست. پس باید ترکیبی از پایش داده و خروجیها، گرفتن label جزئی یا با تأخیر، بررسی KPIهای بیزنسی و تستهای سازگاری رو استفاده کنی تا مطمئن بشی مدل توی production هنوز درست و سالم کار میکنه.
@reza_jafari_ai
Please open Telegram to view this post
VIEW IN TELEGRAM