
Немного о метриках ℹ️
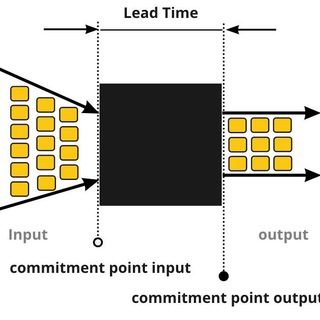
Time to Market (TTM, T2M) — это время от фиксации идеи до реализации
Lead Time — это время от принятия обязательств взять в работу, до решения задачи (релиз)
Существует понятия
Customer Lead Time и System Lead Time
Customer Lead Time — время ожидания клиента от момента принятия обязательств по задаче до ее решения
System Lead Time — это время решения задачи которое находится на том участке системы доставки ценности которым можем управлять (напрмиер за счет ограничений)
В идеале Customer Lead Time = System Lead Time, в таком случае мы можем говорить просто о Lead Time
Если есть разница между Customer Lead Time и System Lead Time, то очень вероятно в такой системе есть "Отложенный Commitment"
Когда в головах заказчика время не совпадает с тем, что в голове у разработчиков. Ведет к конфликтам.
Throughput — это достаточно широкое понятие. Но отличается тем, что обозначает "полную пропускную способность"
Допустим если возьмем трубу без дефектов, и запустим туда воду, то Throughput будет эквивалентен формуле скорости прохождения потока воды через сечение трубы.
Но, если в трубе будут дефекты, и она где-то будет протекать, то Throughput останется прежним, однако в конце трубы мы не получим соответствие доставленной воды этому самому Throughput.
А получим фактический Delivery Rate.
Всю ту воду, что мы потеряли, можем объединить в понятие Discard Rate
Так вот есть эквивалентная формула, где
И Throughput — это максимально возможный Delivery Rate.
Отсюда понятно, что есть качественная метрика потока по количеству
Throughput — на самом деле как понятие, может служить не только как мера для всей системы, но и отдельного участка.
Например, пропускная способность тестирования — сколько в максимуме могут обработать задач тестировщики, вне зависимости эти задачи пойдут в треш или в завершенные.
Delivery Rate — это же именно то что поставили в конце всего пути
На разных сайтах и литературе чаще встречаемся с понятием Throughput
по двум причинам
1. Имеют в виду либо конкретный участок пути ценности
2. Либо потому что имеют в виду максимальные возможности системы
Time to Market (TTM, T2M) — это время от фиксации идеи до реализации
Lead Time — это время от принятия обязательств взять в работу, до решения задачи (релиз)
Существует понятия
Customer Lead Time и System Lead Time
Customer Lead Time — время ожидания клиента от момента принятия обязательств по задаче до ее решения
System Lead Time — это время решения задачи которое находится на том участке системы доставки ценности которым можем управлять (напрмиер за счет ограничений)
В идеале Customer Lead Time = System Lead Time, в таком случае мы можем говорить просто о Lead Time
Если есть разница между Customer Lead Time и System Lead Time, то очень вероятно в такой системе есть "Отложенный Commitment"
Когда в головах заказчика время не совпадает с тем, что в голове у разработчиков. Ведет к конфликтам.
Throughput — это достаточно широкое понятие. Но отличается тем, что обозначает "полную пропускную способность"
Допустим если возьмем трубу без дефектов, и запустим туда воду, то Throughput будет эквивалентен формуле скорости прохождения потока воды через сечение трубы.
Но, если в трубе будут дефекты, и она где-то будет протекать, то Throughput останется прежним, однако в конце трубы мы не получим соответствие доставленной воды этому самому Throughput.
А получим фактический Delivery Rate.
Всю ту воду, что мы потеряли, можем объединить в понятие Discard Rate
Так вот есть эквивалентная формула, где
Throughput = Delivery Rate + Discard RateИ Throughput — это максимально возможный Delivery Rate.
Отсюда понятно, что есть качественная метрика потока по количеству
Delivery Effiency = Delivery Rate / ThroughputThroughput — на самом деле как понятие, может служить не только как мера для всей системы, но и отдельного участка.
Например, пропускная способность тестирования — сколько в максимуме могут обработать задач тестировщики, вне зависимости эти задачи пойдут в треш или в завершенные.
Delivery Rate — это же именно то что поставили в конце всего пути
На разных сайтах и литературе чаще встречаемся с понятием Throughput
по двум причинам
1. Имеют в виду либо конкретный участок пути ценности
2. Либо потому что имеют в виду максимальные возможности системы
👍11
Работают ли Story Points (предективная оценка) для оценки времени выполнения?
Не раз уже разбирал проблему оценки в Story Points с ИТ руководителями и Тимлидами. И вот опять приходится показывать, что нет смысла в том, чтобы использовать Story Points для оценки времени выполнения работ.
Корреляция между временем выполнения Lead Time и Story Points, как это показано на картинке является отсутствующей.
Хорошая корреляция между SP и LT показала бы точки которые лежат в этой синей трапеции.
Еще больше о проблеме оценки смотрите в видео https://www.youtube.com/watch?v=cw1U5XXXuiI
Как планировать используя статистику смотрите тут
https://www.youtube.com/watch?v=U6ih0RSvtkI
Почему для команд и проектов находящихся в разной стадии развития нужны разные параметры метрик и в общем разный набор метрик, можно подчеркнуть из этого доклада
https://www.youtube.com/watch?v=d4po83pIK00
Поэтому, используйте Story Points для ответа на вопрос — что сейчас стоит взять в работу (по нашей относительной оценке), используйте их для прекрасного упражнения декомпозиции — Planning Pocker.
Но, не используйте Story Points для оценки результата работы сотрудников и оценки времени выполнения задач!
#recommendation
#интересное
#доклады
Не раз уже разбирал проблему оценки в Story Points с ИТ руководителями и Тимлидами. И вот опять приходится показывать, что нет смысла в том, чтобы использовать Story Points для оценки времени выполнения работ.
Корреляция между временем выполнения Lead Time и Story Points, как это показано на картинке является отсутствующей.
Хорошая корреляция между SP и LT показала бы точки которые лежат в этой синей трапеции.
Еще больше о проблеме оценки смотрите в видео https://www.youtube.com/watch?v=cw1U5XXXuiI
Как планировать используя статистику смотрите тут
https://www.youtube.com/watch?v=U6ih0RSvtkI
Почему для команд и проектов находящихся в разной стадии развития нужны разные параметры метрик и в общем разный набор метрик, можно подчеркнуть из этого доклада
https://www.youtube.com/watch?v=d4po83pIK00
Поэтому, используйте Story Points для ответа на вопрос — что сейчас стоит взять в работу (по нашей относительной оценке), используйте их для прекрасного упражнения декомпозиции — Planning Pocker.
Но, не используйте Story Points для оценки результата работы сотрудников и оценки времени выполнения задач!
#recommendation
#интересное
#доклады
👍8🔥5
Выяснил что чат в первый раз был присоединён как-то не правильно.
По этому к первым двум сообщениям дискуссии не прикрепились..
Ситуация была исправлена. Чат прикрепился.
Справедливо было отмечено то, что в посте про Story Points не рассказано, что за картинка и как ее получили.
По этому сделаю следующий пост о том, как собирал данные для проверки корреляции Story Points с Lead Time
По этому к первым двум сообщениям дискуссии не прикрепились..
Ситуация была исправлена. Чат прикрепился.
Справедливо было отмечено то, что в посте про Story Points не рассказано, что за картинка и как ее получили.
По этому сделаю следующий пост о том, как собирал данные для проверки корреляции Story Points с Lead Time
👍7
После поста про Story Points и время
справедливо отметили следующие тезисы
- Картинка обладает такой шкалой X, что по ней судить о корреляции графически не верно же
- Как вообще собираются данные?
Начну с того как собираются данные.
В нашей компании основной трекер задач это JIRA. По этому данные мы собираем по БД JIRA.
Они проходят через череду ETL процессов до конечной системы анализа, она называется у нас T-Meter.
— "Как вообще собираете данные?"
Для случая рассматриваемого на картинке эти состояния имеют следующую последовательность
Все статусы в квадратных скобках учтены при расчете Lead Time. Считаем сумму времени проведенное в этих статусах.
В этой команде используется правило: "Story Points в этой команде оценивается как 1 человеко-час."
для Story Points — берем значения из полей, где указали пользователи эти значения
— "Картинка обладает такой шкалой X, что по ней судить о корреляции графически не верно же"
Картинку отношения SP и LT пересобрал в Excel и добавил расчет корреляции Спирмена для наглядности.
Корреляция Спирмена (для не нормальных распределений) показывает то, что использовать эти SP для прогнозирования времени выполнения нет смысла.
Для понимания на сколько корреляция оправдана есть такая шкала как шкала Чеддока
Вывод: Корреляции нет. Использовать Story Points для прогнозирования времени фактического выполнения задач не имеет смысла.
Смысл использовать Story Points может появится либо для другой задачи, либо в пересмотре в принципе подхода оценки и ее задачи.
😉 О том как можно прогнозировать время выполнения расскажу в следующей посте.
#интересное
справедливо отметили следующие тезисы
- Картинка обладает такой шкалой X, что по ней судить о корреляции графически не верно же
- Как вообще собираются данные?
Начну с того как собираются данные.
В нашей компании основной трекер задач это JIRA. По этому данные мы собираем по БД JIRA.
Они проходят через череду ETL процессов до конечной системы анализа, она называется у нас T-Meter.
— "Как вообще собираете данные?"
Для случая рассматриваемого на картинке эти состояния имеют следующую последовательность
| Waiting Approval | -> [Ready to Develop]->[Developing]->[Ready to Testing]->[Testing]->[Final Review]->| *Done* |Все статусы в квадратных скобках учтены при расчете Lead Time. Считаем сумму времени проведенное в этих статусах.
В этой команде используется правило: "Story Points в этой команде оценивается как 1 человеко-час."
для Story Points — берем значения из полей, где указали пользователи эти значения
— "Картинка обладает такой шкалой X, что по ней судить о корреляции графически не верно же"
Картинку отношения SP и LT пересобрал в Excel и добавил расчет корреляции Спирмена для наглядности.
Корреляция Спирмена (для не нормальных распределений) показывает то, что использовать эти SP для прогнозирования времени выполнения нет смысла.
Для понимания на сколько корреляция оправдана есть такая шкала как шкала Чеддока
|Значение. |Интерпретация|
|-------------|-------------|
|от 0 до 0,3 |очень слабая |
|от 0,3 до 0,5| слабая |
|от 0,5 до 0,7| средняя |
|от 0,7 до 0,9| высокая |
|от 0,9 до 1 |очень высокая|
Вывод: Корреляции нет. Использовать Story Points для прогнозирования времени фактического выполнения задач не имеет смысла.
Смысл использовать Story Points может появится либо для другой задачи, либо в пересмотре в принципе подхода оценки и ее задачи.
😉 О том как можно прогнозировать время выполнения расскажу в следующей посте.
#интересное
Вариант № 1. По Lead Time и схожести
Мы можем использовать прошлый опыт по задачам с похожим контекстом и изучить их Lead Time. Построив распределение по этим задачам, мы сможем прогнозировать время выполнения задачи с определенной вероятностью.
Недостатки:
* Необходимо учитывать изменения контекста со временем, и оценка будет актуальна только при стабильной организации процесса работы. Можно использовать контрольную карту для наблюдения за стабильностью.
* Lead Time отвечает на вопрос о времени выполнения задачи и вероятности, но не говорит о количестве задач, которые можно взять на выполнение.
* Для крупных проектов сложно найти аналогии.
* Распределение имеет логарифмический вид, поэтому нельзя просто взять среднее значение.
* Требуется хорошо настроенная система сбора метрик или использование современных трекеров задач, таких как kaiten.ru, где уже предусмотрены сбор метрик.
Плюсы:
* Дает наиболее достоверные данные по срокам выполнения задачи
* Легко найти риски, которые могут произойти по аналогии с задачами попадающими в "хвост" распределения
* При понимании dead line позволяет лучше выбрать стратегию принятия решения
* Легко показать другим по факту как долго делается работа.
Мы можем использовать прошлый опыт по задачам с похожим контекстом и изучить их Lead Time. Построив распределение по этим задачам, мы сможем прогнозировать время выполнения задачи с определенной вероятностью.
Недостатки:
* Необходимо учитывать изменения контекста со временем, и оценка будет актуальна только при стабильной организации процесса работы. Можно использовать контрольную карту для наблюдения за стабильностью.
* Lead Time отвечает на вопрос о времени выполнения задачи и вероятности, но не говорит о количестве задач, которые можно взять на выполнение.
* Для крупных проектов сложно найти аналогии.
* Распределение имеет логарифмический вид, поэтому нельзя просто взять среднее значение.
* Требуется хорошо настроенная система сбора метрик или использование современных трекеров задач, таких как kaiten.ru, где уже предусмотрены сбор метрик.
Плюсы:
* Дает наиболее достоверные данные по срокам выполнения задачи
* Легко найти риски, которые могут произойти по аналогии с задачами попадающими в "хвост" распределения
* При понимании dead line позволяет лучше выбрать стратегию принятия решения
* Легко показать другим по факту как долго делается работа.
❤1
Вариант No 2. По пропускной способности подобию.
Вы можете посмотреть в статистике сколько задач делали за какой-то период и какие это работы
Если сделать график распределения по пропускной способности, то в этом случае мы получим распределение которое должно подчинятся нормальному закону.
Так же можно использовать моделирование методом Монте-Карло. Особенно для случая с вероятными рисками.
Вот пример кода на JS для расчета вероятности завершения сроков проекта
https://gist.github.com/pavelpower/97625088b6cdbde9cfdd4f181fb33a39
А тут подсчет плотности вероятности количества работ на итерацию
https://gist.github.com/pavelpower/dc824f3d31ab6c29bd9ff307b927d73f
Для моделирования с учетом рисков можно использовать эту форму https://rodrigozr.github.io/ProjectForecaster/ сделанную по лекалам Троя Магиннеса.
Минусы:
* Метод будет хорошо работать если вы в часто берете разные по объему и типу задачи, чтобы количество выполняемой работы имело хорошее нормальное распределение. Либо у вас должны быть однотипные работы, что так же повлияет на распределение в сторону его нормальности. В случае если вы последовательно делали один тип работ, потом другой, то данные одного эксперимента вам нельзя использовать для другого.
* При использовании Монте-Карло, нужно перебрать несколько начальных условий, чтобы лучше понимать влияние рисков. Недостаточно одной модуляции и об этом можно легко забыть.
* Не отвечает на вопрос когда закончится конкретная задача
* В случае проведения изменений, статистика будет бесполезна.
Плюсы:
* Сбор данные по пропускной способности простой
* Позволяет промоделировать сроки завершения крупного проекта разбив его на отдельные типы работ по аналогии с прошлым опытом.
* Так же можно определить ограничение количества работ с учетом фактической пропускной способности
* Можно использовать для построения диалога по срокам. Хотя есть возможности для манипуляции из-за разницы в постановке начальных условий
#артефакты
Вы можете посмотреть в статистике сколько задач делали за какой-то период и какие это работы
Если сделать график распределения по пропускной способности, то в этом случае мы получим распределение которое должно подчинятся нормальному закону.
Так же можно использовать моделирование методом Монте-Карло. Особенно для случая с вероятными рисками.
Вот пример кода на JS для расчета вероятности завершения сроков проекта
https://gist.github.com/pavelpower/97625088b6cdbde9cfdd4f181fb33a39
А тут подсчет плотности вероятности количества работ на итерацию
https://gist.github.com/pavelpower/dc824f3d31ab6c29bd9ff307b927d73f
Для моделирования с учетом рисков можно использовать эту форму https://rodrigozr.github.io/ProjectForecaster/ сделанную по лекалам Троя Магиннеса.
Минусы:
* Метод будет хорошо работать если вы в часто берете разные по объему и типу задачи, чтобы количество выполняемой работы имело хорошее нормальное распределение. Либо у вас должны быть однотипные работы, что так же повлияет на распределение в сторону его нормальности. В случае если вы последовательно делали один тип работ, потом другой, то данные одного эксперимента вам нельзя использовать для другого.
* При использовании Монте-Карло, нужно перебрать несколько начальных условий, чтобы лучше понимать влияние рисков. Недостаточно одной модуляции и об этом можно легко забыть.
* Не отвечает на вопрос когда закончится конкретная задача
* В случае проведения изменений, статистика будет бесполезна.
Плюсы:
* Сбор данные по пропускной способности простой
* Позволяет промоделировать сроки завершения крупного проекта разбив его на отдельные типы работ по аналогии с прошлым опытом.
* Так же можно определить ограничение количества работ с учетом фактической пропускной способности
* Можно использовать для построения диалога по срокам. Хотя есть возможности для манипуляции из-за разницы в постановке начальных условий
#артефакты
Стоит ли рассказать подробнее о том как работает метод Монте-Карло?
Final Results
85%
Да, это было бы интересно
9%
Нет, давай лучше про наблюдения за командами
6%
Может быть
Метод Монте-Карло
Понимаю, что в рамках поста в Telegram очень сложно будет уместить объяснение работы Монте-Карло.
Поэтому описал статью отдельно 👉 тут
В статье привел примеры как можно моделировать завершение проекта используя данные пропускной способности.
Постарался сделать самый простой пример.
Который можно использовать для развития своих идей моедлирования.
Добавил и пример с возможными наступления и рисков.
Конечно, это не единственный способ. Однако для большенства случаев он вполне подходящий.
В статье привел пример кода на JavaScript который можно запустить даже в браузере.
Но, а если у вас нет навыков программирования, вы можете воспользоваться готовой формой Rodrigo Rosaulo создавший удобную форму на сонове работ Troy Magennis' и Dimitar Bakardzhiev
Если вам статья понравилась дайте знать - поставьте свой emoji.
Будут вопросы, задавайте в тред (прикрепленный чатик к каналу)
#статья
#артефакты
Понимаю, что в рамках поста в Telegram очень сложно будет уместить объяснение работы Монте-Карло.
Поэтому описал статью отдельно 👉 тут
В статье привел примеры как можно моделировать завершение проекта используя данные пропускной способности.
Постарался сделать самый простой пример.
Который можно использовать для развития своих идей моедлирования.
Добавил и пример с возможными наступления и рисков.
Конечно, это не единственный способ. Однако для большенства случаев он вполне подходящий.
В статье привел пример кода на JavaScript который можно запустить даже в браузере.
Но, а если у вас нет навыков программирования, вы можете воспользоваться готовой формой Rodrigo Rosaulo создавший удобную форму на сонове работ Troy Magennis' и Dimitar Bakardzhiev
Если вам статья понравилась дайте знать - поставьте свой emoji.
Будут вопросы, задавайте в тред (прикрепленный чатик к каналу)
#статья
#артефакты
🔥18👍8⚡1🍾1
Статью про Монте-Карло, начали активно копировать и пересылать.
Спасибо, значит было не зря.
Сообщество Delivery Managers из Тинькофф предоставили Open Source площадку, где docisaurus оформлении получилось чуточку улучшить описание.
К тому же статья будет рядом с другой полезной информацией на этом сайте
#артефакты
#статья
Спасибо, значит было не зря.
Сообщество Delivery Managers из Тинькофф предоставили Open Source площадку, где docisaurus оформлении получилось чуточку улучшить описание.
К тому же статья будет рядом с другой полезной информацией на этом сайте
#артефакты
#статья
deliverymanager.ru
Метод Монте-Карло | Деливери менеджер
Как работает метод Монте-Карло
🔥16❤1👍1
Пока готовил статью про Монте-Карло, хотел найти ответ на вопрос — "можно ли найти хороший существующий пример изложения?". Но, на момент написания статьи не нашел.
А тут из закрамов достал книгу Scrumban, Аджая Редди.
И в качестве справочной информации достаточно подробно расписан метод, и даже с формулами.
Книга вполне себе хороша тем, что в ней много информации не только про Scrumban, где для меня есть спорные моменты, но и дополнительными разделами посвященные метрикам.
#интересное
#прокниги
А тут из закрамов достал книгу Scrumban, Аджая Редди.
И в качестве справочной информации достаточно подробно расписан метод, и даже с формулами.
Книга вполне себе хороша тем, что в ней много информации не только про Scrumban, где для меня есть спорные моменты, но и дополнительными разделами посвященные метрикам.
#интересное
#прокниги
👍10🔥1
А тем временем вышел подкаст с небольшим юмором, про оценки с моим участием.
Называется “Письма Лиды Таймовой”
Вместе с ним обсудили:
🔶 что такое оценка и почему оценка задачи — частый запрос;
🔶 как проходят тренинги по оценкам задач;
🔶 часы, сторипойнты или No estimate? Как оценивать задачи и стоит ли это делать?
🔶 почему человечество до сих пор не изобрело идеального похода по оценке?
Где разбираем с авторами подкаста проблему оценок и прогнозирования
#подкаст
Называется “Письма Лиды Таймовой”
Вместе с ним обсудили:
🔶 что такое оценка и почему оценка задачи — частый запрос;
🔶 как проходят тренинги по оценкам задач;
🔶 часы, сторипойнты или No estimate? Как оценивать задачи и стоит ли это делать?
🔶 почему человечество до сих пор не изобрело идеального похода по оценке?
Где разбираем с авторами подкаста проблему оценок и прогнозирования
#подкаст
Интересная история происходит у меня на глазах. Коллеги хотят сделать алгоритм, который будет самостоятельно оценивать задачи которые попадают в трекер.
За основу материала для наблюдения коллеги взяли статистику по Lead Time команды.
И для решения своей задачи выдвинули гипотезу "H":
"В гистограмме Lead Time обнаруженные моды являются обособленным признаком сложности решаемых задач, а значит выделив эти мо́ды можно определить сложность решаемой задачи."
Живой пример распределения смотри на картинке
Мо́да — одно или несколько значений во множестве наблюдений, которое встречается наиболее часто (мода = типичность)
На картинке явно видны отличные мо́ды.
Чтобы далее верно решать задачу, нам нужно сформулировать "обратную" нулевую гипотезу "H0":
"Мо́ды в частотной диаграмме Lead Time не являются признаком сложности решаемой задачи, и связаны с другими явлениями".
Опровержение нулевой гипотезы нам поможет определить то, что утверждение мо́ды — это проявление признака сложности задач, является верным утверждением.
И, тогда выделив обособленные группы задач по этим мо́дам, мы можем найти признаки категории сложности задачи.
Что позволит создать алгоритм оценки задач.
Давайте вместе с вами попробуем помочь коллегам с решением задачи и ответим на вопрос ниже:
#интересное
За основу материала для наблюдения коллеги взяли статистику по Lead Time команды.
И для решения своей задачи выдвинули гипотезу "H":
"В гистограмме Lead Time обнаруженные моды являются обособленным признаком сложности решаемых задач, а значит выделив эти мо́ды можно определить сложность решаемой задачи."
Живой пример распределения смотри на картинке
Мо́да — одно или несколько значений во множестве наблюдений, которое встречается наиболее часто (мода = типичность)
На картинке явно видны отличные мо́ды.
Чтобы далее верно решать задачу, нам нужно сформулировать "обратную" нулевую гипотезу "H0":
"Мо́ды в частотной диаграмме Lead Time не являются признаком сложности решаемой задачи, и связаны с другими явлениями".
Опровержение нулевой гипотезы нам поможет определить то, что утверждение мо́ды — это проявление признака сложности задач, является верным утверждением.
И, тогда выделив обособленные группы задач по этим мо́дам, мы можем найти признаки категории сложности задачи.
Что позволит создать алгоритм оценки задач.
Давайте вместе с вами попробуем помочь коллегам с решением задачи и ответим на вопрос ниже:
#интересное