
Вдогонку к саммри по AWS:
- AWS Fargate — технология, которая позволяет использовать контейнер, как минимальную вычислительную единицу и не париться, что происходит "под ним" (via @otakusid)
Описание
- AWS S3 Select — SQL select для S3 и Glacier (via @otakusid)
https://aws.amazon.com/blogs/aws/s3-glacier-select/
- T2 Unlimited инстансы. Суть та же, что с Elastic File System, только с CPU performance
Описание
#aws
- AWS Fargate — технология, которая позволяет использовать контейнер, как минимальную вычислительную единицу и не париться, что происходит "под ним" (via @otakusid)
Описание
- AWS S3 Select — SQL select для S3 и Glacier (via @otakusid)
https://aws.amazon.com/blogs/aws/s3-glacier-select/
- T2 Unlimited инстансы. Суть та же, что с Elastic File System, только с CPU performance
Описание
#aws
UPD по базам данных:
- Master-master Aurorа, при чём мастера можно делать в разных AZ:
https://aws.amazon.com/about-aws/whats-new/2017/11/sign-up-for-the-preview-of-amazon-aurora-multi-master/
- Serverless Aurora: БД скейлится в зависимости от нужд приложения. Как говорят, больше нет необходимости менеджить сами инстансы под БД
https://aws.amazon.com/about-aws/whats-new/2017/11/sign-up-for-the-preview-of-amazon-aurora-serverless
- DynamoDB Global Tables: мультирегиональная NoSQL DB
https://aws.amazon.com/about-aws/whats-new/2017/11/aws-launches-amazon-dynamodb-global-tables
- DynamoDB Backup & Restore: можно полностью забэкапить свою DynamoDB по запросу
https://aws.amazon.com/about-aws/whats-new/2017/11/aws-launches-amazon-dynamodb-backup-and-restore
#aws
- Master-master Aurorа, при чём мастера можно делать в разных AZ:
https://aws.amazon.com/about-aws/whats-new/2017/11/sign-up-for-the-preview-of-amazon-aurora-multi-master/
- Serverless Aurora: БД скейлится в зависимости от нужд приложения. Как говорят, больше нет необходимости менеджить сами инстансы под БД
https://aws.amazon.com/about-aws/whats-new/2017/11/sign-up-for-the-preview-of-amazon-aurora-serverless
- DynamoDB Global Tables: мультирегиональная NoSQL DB
https://aws.amazon.com/about-aws/whats-new/2017/11/aws-launches-amazon-dynamodb-global-tables
- DynamoDB Backup & Restore: можно полностью забэкапить свою DynamoDB по запросу
https://aws.amazon.com/about-aws/whats-new/2017/11/aws-launches-amazon-dynamodb-backup-and-restore
#aws
И опять AWS!
Теперь можно пирить VPC из разных регионов!
https://aws.amazon.com/about-aws/whats-new/2017/11/announcing-support-for-inter-region-vpc-peering/
#aws
Теперь можно пирить VPC из разных регионов!
https://aws.amazon.com/about-aws/whats-new/2017/11/announcing-support-for-inter-region-vpc-peering/
#aws
Amazon
Announcing Support for Inter-Region VPC Peering
И ещё немного про AWS.
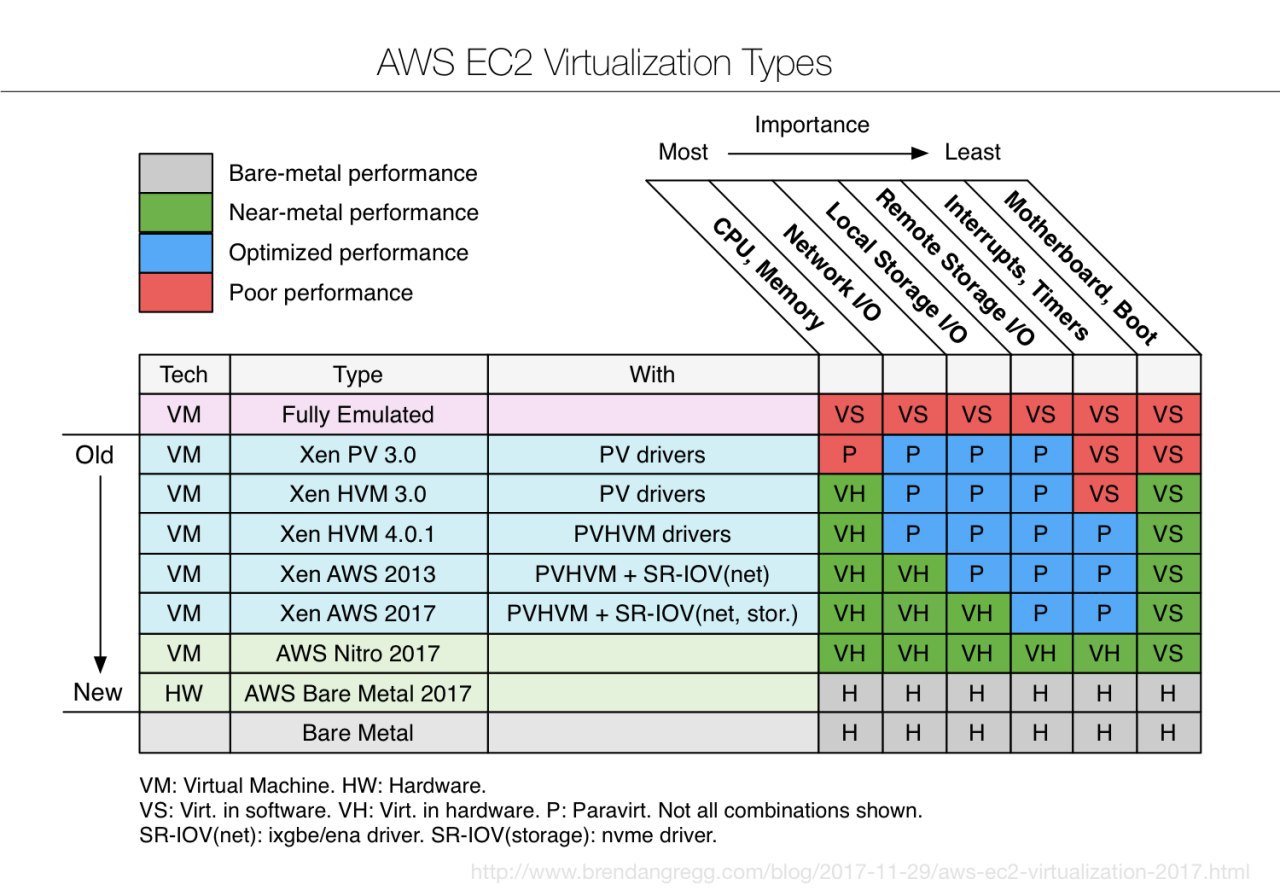
Brendan Gregg написал статью про эволюцию виртуализации AWS Кроме того, там есть диаграмма, которая показывает производительность каждого типа виртуализации
И вдогонку его же слайды с AWS re:Invent о том, как в Netflix тюнили EC2 инстансы:
https://www.slideshare.net/brendangregg/how-netflix-tunes-ec2-instances-for-performance
#aws #slides
Brendan Gregg написал статью про эволюцию виртуализации AWS Кроме того, там есть диаграмма, которая показывает производительность каждого типа виртуализации
И вдогонку его же слайды с AWS re:Invent о том, как в Netflix тюнили EC2 инстансы:
https://www.slideshare.net/brendangregg/how-netflix-tunes-ec2-instances-for-performance
#aws #slides
{kind=link}
Я понимаю, что вы уже немного подустали от новостей AWS
Поэтому предлагаю почитать о необычной миграции: из Google Cloud в Digital Ocean
https://lugassy.net/goodbye-google-cloud-hello-digital-ocean-a4ca1c8b7ac8
Поэтому предлагаю почитать о необычной миграции: из Google Cloud в Digital Ocean
https://lugassy.net/goodbye-google-cloud-hello-digital-ocean-a4ca1c8b7ac8
Medium
Goodbye Google Cloud, Hello Digital Ocean!
Launching cloud instances should be fun. Like invoicing customers.
А вот и видео с AWS re:Invent подогнали:
https://www.youtube.com/user/AmazonWebServices/playlists
Amazon пока что, наверное, самые быстрые в этом плане. Ещё и по тематическим плейлистам разложили: вообще красота!
#aws #slides
https://www.youtube.com/user/AmazonWebServices/playlists
Amazon пока что, наверное, самые быстрые в этом плане. Ещё и по тематическим плейлистам разложили: вообще красота!
#aws #slides
Занятная статья от Aerospike про тюнинг сети для Amazon EC2 инстансов (а XDR у Aerospike трафика гоняет дай боже!)
https://www.aerospike.com/blog/boosting-amazon-ec2-network-for-high-throughput/
Они пришли, во-первых, к тому, что запускать Aerospike лучше всего на r3 типе инстансов.
Во-вторых, на производительность сети на инстансах до 4xlarge тюнтнг с помощью Receive Packet Steering (RPS) даёт приблизительно такой же прирост производительности, как подключение нескольких Elastic Network Interfaces. А вот на более "толстых" инстансах несколько ENI уже куда эффективней RPS
#aerospike #networking #database #aws
https://www.aerospike.com/blog/boosting-amazon-ec2-network-for-high-throughput/
Они пришли, во-первых, к тому, что запускать Aerospike лучше всего на r3 типе инстансов.
Во-вторых, на производительность сети на инстансах до 4xlarge тюнтнг с помощью Receive Packet Steering (RPS) даёт приблизительно такой же прирост производительности, как подключение нескольких Elastic Network Interfaces. А вот на более "толстых" инстансах несколько ENI уже куда эффективней RPS
#aerospike #networking #database #aws
Аудиодоклад (подкаст?) про мониторинг и кэширование в Twitter от Yao Yue:
https://www.infoq.com/podcasts/yao-yue-twitter-cache#.WcFKf0WTZUU.twitter
Если вам интересны какие-то конкретные вопросы, там указаны тезисы и временная метка на которой их проговаривают. Удобно, если нет желания слушать все полчаса
#monitoring
https://www.infoq.com/podcasts/yao-yue-twitter-cache#.WcFKf0WTZUU.twitter
Если вам интересны какие-то конкретные вопросы, там указаны тезисы и временная метка на которой их проговаривают. Удобно, если нет желания слушать все полчаса
#monitoring
InfoQ
Twitter's Yao Yue on Latency, Performance Monitoring, & Caching at Scale
Yao Yue spent the majority of her career working on caching systems at Twitter. She created a performance team that deals with edge performance outliers often exposed by the enormous scale of Twitter. In this podcast, she discusses standing up the performance…
Стали доступны слайды, видео и фотки с PuppetConf 2017
https://puppet.com/blog/puppetconf-2017-videos-slides-and-photos-are-ready-you
#slides
https://puppet.com/blog/puppetconf-2017-videos-slides-and-photos-are-ready-you
#slides
Puppet
The PuppetConf 2017 videos, slides and photos are ready for you
The videos, slides and photos from PuppetConf 2017 are here! Relive the conference, rewatch your favorite sessions, and see the ones you missed.
Forwarded from Українська девопсарня
интересная статья о том как работают с кешами в Etsy. https://codeascraft.com/2017/11/30/how-etsy-caches/
Если коротко, то ребята используют Ketama в качестве реализации consisten hashing. Это библиотека на C или Java с обвязками для разных популярных языков программирования, которая делает hash ring (вот неплохая статья о hash ring), которую, впрочем, критикуют за то что при добавлении новой ноды требуется заново вычислять все кольцо, а значения не перераспределюятся равномерно, так что лучше использовать какой-то md5 в качестве хеш функции и большее количество бакетов.
Вторая часть статьи о так называемом “cache smearing” - технике когда к самым популярным ключам добавляют немного случайных данных, чтобы положить их сразу в несколько бакетов и читать не с одной ноды, а с нескольких. Сам механизм вычисления какой ключ популярный и как именно они добавляют случайные значения не опубликован.
Если коротко, то ребята используют Ketama в качестве реализации consisten hashing. Это библиотека на C или Java с обвязками для разных популярных языков программирования, которая делает hash ring (вот неплохая статья о hash ring), которую, впрочем, критикуют за то что при добавлении новой ноды требуется заново вычислять все кольцо, а значения не перераспределюятся равномерно, так что лучше использовать какой-то md5 в качестве хеш функции и большее количество бакетов.
Вторая часть статьи о так называемом “cache smearing” - технике когда к самым популярным ключам добавляют немного случайных данных, чтобы положить их сразу в несколько бакетов и читать не с одной ноды, а с нескольких. Сам механизм вычисления какой ключ популярный и как именно они добавляют случайные значения не опубликован.
Etsy Engineering
Etsy Engineering | How Etsy caches: hashing, Ketama, and cache smearing
At Etsy, we rely heavily on memcached and Varnish as caching tiers to improve performance and reduce load. Database and search...
👍1
Lyft зарелизили cni-ipvlan-vpc-k8s: IPvlan для Kubernetes в AWS
https://eng.lyft.com/announcing-cni-ipvlan-vpc-k8s-ipvlan-overlay-free-kubernetes-networking-in-aws-95191201476e
В сопутствующей статье они описали, с какими проблемами пришлось столкнуться при деплое Kubernetes в AWS VPC: ограничение в 50 маршрутов роут-таблицы для VPC, что ведёт к развертыванию своих overlay сетей с BGP и профурсетками.
И, соответственно, как они это решали с помощью ENI, но так, чтобы не только упростить конфигурацию, но и сохранить производительность сети на должном уровне
В общем, если вы разворачиваете Kubernetes в AWS, вам это будет полезно at scale
P.S: Lyft -- это как Uber, только чуточку дешевле и покрывает только США
#kubernetes #aws #networking
https://eng.lyft.com/announcing-cni-ipvlan-vpc-k8s-ipvlan-overlay-free-kubernetes-networking-in-aws-95191201476e
В сопутствующей статье они описали, с какими проблемами пришлось столкнуться при деплое Kubernetes в AWS VPC: ограничение в 50 маршрутов роут-таблицы для VPC, что ведёт к развертыванию своих overlay сетей с BGP и профурсетками.
И, соответственно, как они это решали с помощью ENI, но так, чтобы не только упростить конфигурацию, но и сохранить производительность сети на должном уровне
В общем, если вы разворачиваете Kubernetes в AWS, вам это будет полезно at scale
P.S: Lyft -- это как Uber, только чуточку дешевле и покрывает только США
#kubernetes #aws #networking
Medium
Announcing cni-ipvlan-vpc-k8s: IPvlan overlay-free Kubernetes Networking in AWS
Lyft is pleased to announce the initial open source release of our IPvlan-based CNI networking stack for running Kubernetes at scale in…
Вы любите сервисные сетки (service mesh)? Но Linkerd со Scala как-то не оч? Те же ребята написали mesh на Rust & Go! Назывется Conduit
Зачем переписывать себя? Потому что у Conduit очень узкая специализация. Это service mesh специально для Kubernetes!
Почитать можно тут:
https://buoyant.io/2017/12/05/introducing-conduit/
Пока в альфа-версии, но попробовать уже можно
#kubernetes
Зачем переписывать себя? Потому что у Conduit очень узкая специализация. Это service mesh специально для Kubernetes!
Почитать можно тут:
https://buoyant.io/2017/12/05/introducing-conduit/
Пока в альфа-версии, но попробовать уже можно
#kubernetes
linkerd.io
Introducing Conduit
Conduit is now part of Linkerd! Read more >
Today, we’re very happy to introduce Conduit, our new open source service mesh for Kubernetes.
We’ve built Conduit from the ground up to be the fastest, lightest, simplest, and most secure service mesh in the world.…
Today, we’re very happy to introduce Conduit, our new open source service mesh for Kubernetes.
We’ve built Conduit from the ground up to be the fastest, lightest, simplest, and most secure service mesh in the world.…
Посмотрите этот замечательный доклад на Velocity Conf от шикарной Julia Grace:
Julia — Head of Infrastructure Engineering в Slack — рассказывает о то, как построить процессы в Infrastructure Team. Потому что все модные тулзы, конечно, помогают нам доставлять продукт быстрее (и как следствие возвращать инвестиции раньше). Однако, даже используя все самые новые и модные вещи, вам будет очень сложно развернуься без нормально отлаженых процессов.
Кстати, рекомендую подписаться на неё в Twitter
#culture #agile
Julia — Head of Infrastructure Engineering в Slack — рассказывает о то, как построить процессы в Infrastructure Team. Потому что все модные тулзы, конечно, помогают нам доставлять продукт быстрее (и как следствие возвращать инвестиции раньше). Однако, даже используя все самые новые и модные вещи, вам будет очень сложно развернуься без нормально отлаженых процессов.
Кстати, рекомендую подписаться на неё в Twitter
#culture #agile
O’Reilly Media
10,000 messages a minute
Lessons learned from building engineering teams under pressure.
Ian Lewis объясняет, что такое container runtime, какие они бывают и почему это словосочетание вызывает путанницу
Если тезисно:
- у самого понятия "runtime" тоже несколько определений.
- в статье опираются на то, что рантайм — это некая сущность, которая поддерживает исполнение. Пример: HotSpot Runtime в Java
- таким образом есть low level и high level рантаймы
- первые позволяют вам лишь запускать контейнеры (lxc, runc)
- вторые уже содержат какие-то API, фичи вокруг менеджмента имаджей и проч
to be continued
Часть I:
https://www.ianlewis.org/en/container-runtimes-part-1-introduction-container-r
#containers
Если тезисно:
- у самого понятия "runtime" тоже несколько определений.
- в статье опираются на то, что рантайм — это некая сущность, которая поддерживает исполнение. Пример: HotSpot Runtime в Java
- таким образом есть low level и high level рантаймы
- первые позволяют вам лишь запускать контейнеры (lxc, runc)
- вторые уже содержат какие-то API, фичи вокруг менеджмента имаджей и проч
to be continued
Часть I:
https://www.ianlewis.org/en/container-runtimes-part-1-introduction-container-r
#containers
Ian Lewis
Container Runtimes Part 1: An Introduction to Container Runtimes
One of the terms you hear a lot when dealing with containers is “container runtime”. “Container runtime” can have different meanings to different people so it’s no wonder that it’s such a confusing and vaguely understood term, even within the container community.
Окей, вы настроили мониторинг. У вас есть куча метрик, которые даже собраны в красивые дашборды
Куда смотреть? Надо ли будить половину команды, если вырос
Конечно, это всё очень индивидуально, и у разных людей разные мнения по поводу "золотых сигналов". Т.е индикаторов, что у нас сейчас всё overall good или overall bad. Почитать о разных мнениях можно тут:
https://medium.com/devopslinks/how-to-monitor-the-sre-golden-signals-1391cadc7524
В кратце о методах:
Google: Latency, Traffic, Errors, and Saturation
Brendan Gregg: Utilization, Saturation, and Errors
Tom Wilkie: Rate, Errors, and Duration
Ну а дальше уже в статье всё разжёвано детальней
#monitoring #observability
Куда смотреть? Надо ли будить половину команды, если вырос
cpu_wio на 7% бэкэндов? А на 20%? Или мы просто будем сомтреть на valid_response_p95_rate и алерить по данной метрике?Конечно, это всё очень индивидуально, и у разных людей разные мнения по поводу "золотых сигналов". Т.е индикаторов, что у нас сейчас всё overall good или overall bad. Почитать о разных мнениях можно тут:
https://medium.com/devopslinks/how-to-monitor-the-sre-golden-signals-1391cadc7524
В кратце о методах:
Google: Latency, Traffic, Errors, and Saturation
Brendan Gregg: Utilization, Saturation, and Errors
Tom Wilkie: Rate, Errors, and Duration
Ну а дальше уже в статье всё разжёвано детальней
#monitoring #observability
{kind=link}
Amazon теперь предупреждает, если у вас есть шанс выйти за пределы бесплатного лимита (free tier)
Удобно для ведения pet-проектов и просто знакомства с платформой
#aws
Удобно для ведения pet-проектов и просто знакомства с платформой
#aws
Amazon
AWS Free Tier usage alerts automatically notify you when you are forecasted to exceed your AWS service usage limits
Forwarded from devdigest // azure (Azure News Bot)
Hackernoon опубликовал интересное сраванение Azure Container Instances и AWS Fargate
https://hackernoon.com/azure-container-instances-vs-aws-fargate-3216607f63f4
https://hackernoon.com/azure-container-instances-vs-aws-fargate-3216607f63f4
Hackernoon
Azure Container Instances vs. AWS Fargate | Hacker Noon
Чёт я как-то заэтсамое и получился перерыв. Нехорошо.
Я на днях в Титтвере наткнулся на интересную дискуссию о том, стоит ли теперь всем париться OPS задачами. Но перед тем как сюда её загонять, надо как-то собрать всё воедино. А надо же ещё и работу работать.
Так что почитайте пока про SRE с точки зрения NewRelic, а я сегодня-завтра твиттерскую дискуссию в постик оформлю
https://blog.newrelic.com/2017/10/30/site-reliability-engineer-sre/
Я на днях в Титтвере наткнулся на интересную дискуссию о том, стоит ли теперь всем париться OPS задачами. Но перед тем как сюда её загонять, надо как-то собрать всё воедино. А надо же ещё и работу работать.
Так что почитайте пока про SRE с точки зрения NewRelic, а я сегодня-завтра твиттерскую дискуссию в постик оформлю
https://blog.newrelic.com/2017/10/30/site-reliability-engineer-sre/
New Relic Blog
New Relic: The Rise of Site Reliability Engineers
As the Site Reliability Engineer (SRE) role continues to evolve and expand, we examine the history, proliferation, and particular iteration of Site Reliability Engineering inside New Relic.