
We had a hiring sync up meeting recently to improve the interviewing process and formalize the expectations for each grade.
In nutshell, we brainstormed a long list of competences, which we expect a candidate to have and then tried to align on them and also agree on how good should one be in each of those competences to be put in each grade.
Some interesting insights happened there. My favorite is that we all agreed that a candidate should seek new knowledge: read books and articles, keep an eye on the industry, etc. However, the purpose for seeking knowledge is different for each grade!
We expect junior engineers to be generally curious and seek knowledge for fun or because something is interesting, or because it's a trendy thing.
Later in their career, we expect one to seek knowledge in order to get things done, become a better engineer in their area and eventually become a senior in that field.
On a senior level we think that people are seeking knowledge to keep their project moving forward and become an expert.
And eventually people on the positions beyond senior are seeking knowledge to elevate others and make the whole company moving faster.
Of course, many of these things are overlapping. A junior engineer can totally care about a project and find the ways to improve it, as well as senior+ engineer can seek new knowledge to broaden their scope.
However, this whole idea of change from "discover things to improve myself" to "discover things to improve others" pulls some internal strings of myself.
#culture
In nutshell, we brainstormed a long list of competences, which we expect a candidate to have and then tried to align on them and also agree on how good should one be in each of those competences to be put in each grade.
Some interesting insights happened there. My favorite is that we all agreed that a candidate should seek new knowledge: read books and articles, keep an eye on the industry, etc. However, the purpose for seeking knowledge is different for each grade!
We expect junior engineers to be generally curious and seek knowledge for fun or because something is interesting, or because it's a trendy thing.
Later in their career, we expect one to seek knowledge in order to get things done, become a better engineer in their area and eventually become a senior in that field.
On a senior level we think that people are seeking knowledge to keep their project moving forward and become an expert.
And eventually people on the positions beyond senior are seeking knowledge to elevate others and make the whole company moving faster.
Of course, many of these things are overlapping. A junior engineer can totally care about a project and find the ways to improve it, as well as senior+ engineer can seek new knowledge to broaden their scope.
However, this whole idea of change from "discover things to improve myself" to "discover things to improve others" pulls some internal strings of myself.
#culture
A series of articles by Rookout on developer tools for working with a Kubernetes cluster.
- Part I: Helm, Kustomize, and Skaffold
- Part II: Skaffold, Tilt, and Garden
- Part III: Lens, VSCode, IntelliJ & Gitpod
- Part IV: Docker, BuildKit, Buildpacks, Jib & Kaniko
- Part V: Development Machines
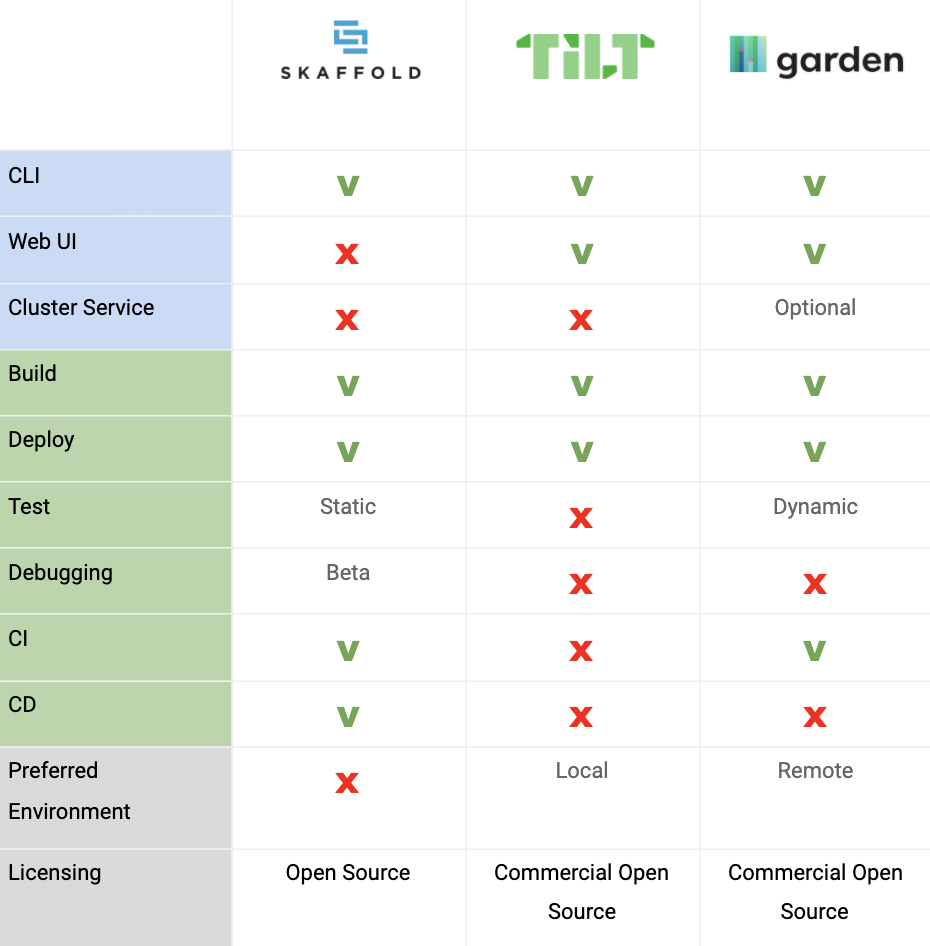
The second part is particularly interesting because of the comparison table.
#kubernetes
- Part I: Helm, Kustomize, and Skaffold
- Part II: Skaffold, Tilt, and Garden
- Part III: Lens, VSCode, IntelliJ & Gitpod
- Part IV: Docker, BuildKit, Buildpacks, Jib & Kaniko
- Part V: Development Machines
The second part is particularly interesting because of the comparison table.
#kubernetes
{kind=link}
In less than a week will start HashiConf Global
So, we have great proposal for our community - talk with Hashimoto and Dadgar on HUG Kyiv later this year in convenient for us time zone.
And, in the brightest future, we would like HashiCorp to listen to the opinion of our community.
This can't be done without your help! Please, find 5 minutes to make the big thing real - vote for HUG Kyiv!
#event
So, we have great proposal for our community - talk with Hashimoto and Dadgar on HUG Kyiv later this year in convenient for us time zone.
And, in the brightest future, we would like HashiCorp to listen to the opinion of our community.
This can't be done without your help! Please, find 5 minutes to make the big thing real - vote for HUG Kyiv!
#event
{kind=link}
{kind=link}
Here is the awesome list of GitHub Actions both official and community-driven.
So, if you were looking into working with GHA, that might be a good thing to check. Also, if you're using GHA already, you may find some common actions to remove some repeated lines of code in your pipelines.
P.S. If you are not interested in GitHub Actions, but still adore the idea of YAML based CI, I just want to remind you that you can use YAML to configure Jenkins pipelines as well
#cicd #github #gha #jenkins
So, if you were looking into working with GHA, that might be a good thing to check. Also, if you're using GHA already, you may find some common actions to remove some repeated lines of code in your pipelines.
P.S. If you are not interested in GitHub Actions, but still adore the idea of YAML based CI, I just want to remind you that you can use YAML to configure Jenkins pipelines as well
#cicd #github #gha #jenkins
GitHub
GitHub - sdras/awesome-actions: A curated list of awesome actions to use on GitHub
A curated list of awesome actions to use on GitHub - sdras/awesome-actions
From our subscribers.
10 trends of real-world container use by DataDog.
1. ~90% of Kubernetes users leverage cloud-managed services
2. Amazon ECS users are shifting to Fargate
3. The average number of pods per organization has doubled
4. Host density is 3 times higher on Kubernetes than on Amazon ECS
5. Pod auto-scaling is becoming more popular
6. Organizations are deploying more stateful workloads on containers
7. Organizations running container environments create more monitors
8. Organizations are starting to replace Docker with containerd as their preferred runtime for Kubernetes
9. OpenShift adoption is growing rapidly
10. NGINX, Redis, and Postgres are the top three container images
More details are in the report.
#trends #containers
10 trends of real-world container use by DataDog.
1. ~90% of Kubernetes users leverage cloud-managed services
2. Amazon ECS users are shifting to Fargate
3. The average number of pods per organization has doubled
4. Host density is 3 times higher on Kubernetes than on Amazon ECS
5. Pod auto-scaling is becoming more popular
6. Organizations are deploying more stateful workloads on containers
7. Organizations running container environments create more monitors
8. Organizations are starting to replace Docker with containerd as their preferred runtime for Kubernetes
9. OpenShift adoption is growing rapidly
10. NGINX, Redis, and Postgres are the top three container images
More details are in the report.
#trends #containers
Datadog
10 insights on real world container use | Datadog
Our latest report examines more than 2.4 billion containers run by tens of thousands of Datadog customers to understand the state of the container ecosystem.
Finally! The recording of our voice chat about counter-offers is available online!
Our chat was in the mix of Ukrainian and Russian. You can listen to it on:
- Anchor
- Spotify
- Apple Podcasts
Unfortunately, Google Podcasts haven’t approved us yet. Hopefully, you’d be able to listen to this chat there soon.
You can also “watch” it on YouTube. I used quotes, because this is really just an audio with a static image.
TBH, I cannot promise when any other voice chats like this one will take place. In any case, though. Hit “like”, “subscribe”, all those usual things. Just in case we have more.
P.S. The next voice chat will be this Thursday! 17:00 UTC as usual in our discussions group
#voice_chat
Our chat was in the mix of Ukrainian and Russian. You can listen to it on:
- Anchor
- Spotify
- Apple Podcasts
Unfortunately, Google Podcasts haven’t approved us yet. Hopefully, you’d be able to listen to this chat there soon.
You can also “watch” it on YouTube. I used quotes, because this is really just an audio with a static image.
TBH, I cannot promise when any other voice chats like this one will take place. In any case, though. Hit “like”, “subscribe”, all those usual things. Just in case we have more.
P.S. The next voice chat will be this Thursday! 17:00 UTC as usual in our discussions group
#voice_chat
Spotify for Creators
CatOps • A podcast on Spotify for Podcasters
DevOps & other issues
This is a good and very important article on SRE structure - SRE Doesn’t Scale.
The main idea is, well, as it's stated in the title, that providing so-called "SRE support" doesn't scale well. It requires a lot of resources and manpower, and the majority of those resources are wasted in ad-hoc firefighting and context switch.
To solve this problem, a platform itself should be "productized" or "commodified". I.e. your platform should become an internal product. So, users of this platform can interact with it via APIs and ask for changes via feature requests and bug reports. As well as, your users will be able to share some good practices on how to interact with your platform among themselves.
Some notable quotes:
> Even Google, who has infinite money and an endless recruiting pipeline, says the SRE model—as it is often described by the people we encounter referencing the book—does not scale with microservices. Instead, they go on to describe a more tractable, framework-oriented model to address this through things like codified best practices, reusable solutions, standardization of tools and patterns, and, more generally, what I describe as the “productization” of infrastructure and operations.
> For some reason, this little detail gets lost and, consequently, we see groups attempting to throw people at the problem, such as embedding an SRE on each team. In practice, this usually means two things: 1) hiring a whole bunch of SREs—which even Google admits to being difficult and costly—and 2) this person typically just becomes the “whipping boy” for the team. More often than not, this individual is some poor ops person who gets labeled “SRE.”
And my favorite:
> In fact, many groups are probably better off simply removing “SRE” and “DevOps” from their vocabulary altogether because they often end up being distracting buzzwords.
#culture
The main idea is, well, as it's stated in the title, that providing so-called "SRE support" doesn't scale well. It requires a lot of resources and manpower, and the majority of those resources are wasted in ad-hoc firefighting and context switch.
To solve this problem, a platform itself should be "productized" or "commodified". I.e. your platform should become an internal product. So, users of this platform can interact with it via APIs and ask for changes via feature requests and bug reports. As well as, your users will be able to share some good practices on how to interact with your platform among themselves.
Some notable quotes:
> Even Google, who has infinite money and an endless recruiting pipeline, says the SRE model—as it is often described by the people we encounter referencing the book—does not scale with microservices. Instead, they go on to describe a more tractable, framework-oriented model to address this through things like codified best practices, reusable solutions, standardization of tools and patterns, and, more generally, what I describe as the “productization” of infrastructure and operations.
> For some reason, this little detail gets lost and, consequently, we see groups attempting to throw people at the problem, such as embedding an SRE on each team. In practice, this usually means two things: 1) hiring a whole bunch of SREs—which even Google admits to being difficult and costly—and 2) this person typically just becomes the “whipping boy” for the team. More often than not, this individual is some poor ops person who gets labeled “SRE.”
And my favorite:
> In fact, many groups are probably better off simply removing “SRE” and “DevOps” from their vocabulary altogether because they often end up being distracting buzzwords.
#culture
Brave New Geek
SRE Doesn’t Scale
We encounter a lot of organizations talking about or attempting to implement SRE as part of our consulting at Real Kinetic. We’ve even discussed and debated ourselves, ad nauseam, how we can apply …
HashiConf Global starts in 5 minutes!
If you have not yet registered and voting to HUG Kyiv, here are YouTube broadcast links:
Day 1 - PDT Broadcast: Track 1 | Track 2 | Track 3
Day 2 - PDT Broadcast: Track 1 | Track 2 | Track 3
P.S. If you're Ukrainian, and your browser not cached live.hashiconf.com/schedule token, HashiCorp very-very apologize to all of us. They tried to block occupied by Russia territories but blocked full Ukraine...
No chance to fix that issue today - the site supports only 2-letter country restrictions. HashiCorp promises to fix it for the next event and apologize yet another time.
If you have not yet registered and voting to HUG Kyiv, here are YouTube broadcast links:
Day 1 - PDT Broadcast: Track 1 | Track 2 | Track 3
Day 2 - PDT Broadcast: Track 1 | Track 2 | Track 3
P.S. If you're Ukrainian, and your browser not cached live.hashiconf.com/schedule token, HashiCorp very-very apologize to all of us. They tried to block occupied by Russia territories but blocked full Ukraine...
No chance to fix that issue today - the site supports only 2-letter country restrictions. HashiCorp promises to fix it for the next event and apologize yet another time.
{kind=link}
CatOps
In less than a week will start HashiConf Global So, we have great proposal for our community - talk with Hashimoto and Dadgar on HUG Kyiv later this year in convenient for us time zone. And, in the brightest future, we would like HashiCorp to listen to…
Who won? We won!
Wiil be officially announced at Second Day of HashiConf Global that will start at 19:00 Kyiv TZ (16:00 UTC)
Wiil be officially announced at Second Day of HashiConf Global that will start at 19:00 Kyiv TZ (16:00 UTC)
Nginx playground by Julia Evans.
It works just like any other code playground out there, but for Nginx configurations.
Could be useful if you want to test a change without rolling new machines.
#nginx
It works just like any other code playground out there, but for Nginx configurations.
Could be useful if you want to test a change without rolling new machines.
#nginx
During our previous voice chat we briefly mentioned Wardley mapping.
This is an approach to map a strategy for product or process development.
Here's an awesome list of Wardley Maps, which contains a handful of resources that can help you get into mapping or improve your mapping skills.
#mapping #management
This is an approach to map a strategy for product or process development.
Here's an awesome list of Wardley Maps, which contains a handful of resources that can help you get into mapping or improve your mapping skills.
#mapping #management
GitHub
GitHub - wardley-maps-community/awesome-wardley-maps: Wardley maps community hub. Useful Wardley mapping resources
Wardley maps community hub. Useful Wardley mapping resources - wardley-maps-community/awesome-wardley-maps
And here is the video that inspired one of our subscribers to learn about Wardley mapping:
https://www.youtube.com/watch?v=2IW9L1uNMCs
https://www.youtube.com/watch?v=2IW9L1uNMCs
YouTube
Crossing the River by Feeling the Stones • Simon Wardley • GOTO 2018
This presentation was recorded at GOTO Copenhagen 2018. #gotocon #gotocph
https://gotocph.com
Simon Wardley - Researcher for The Leading Edge Forum @simonwardley
ABSTRACT
Deng Xiaoping once described managing the economy as crossing the river by feeling…
https://gotocph.com
Simon Wardley - Researcher for The Leading Edge Forum @simonwardley
ABSTRACT
Deng Xiaoping once described managing the economy as crossing the river by feeling…
There are multiple ways to define, which technology to use in a company or a project.
Sometimes, the decision-making point is simply "I have experience working with the technology A". This is especially common, when a company size is not that big and impact of such decisions seems not very broad.
However, if you're choosing a cache solution, and you're choosing between Memcached and Redis, this article may help you to make a more informed one.
#redis #memcached #cache
Sometimes, the decision-making point is simply "I have experience working with the technology A". This is especially common, when a company size is not that big and impact of such decisions seems not very broad.
However, if you're choosing a cache solution, and you're choosing between Memcached and Redis, this article may help you to make a more informed one.
#redis #memcached #cache
engineering.kablamo.com.au
Memcached vs Redis - More Different Than You Would Expect | Insights from the Kablamo Team.
Insights from the Kablamo Engineering Team
🔥1
Noice!
If you're using EC2 Auto Scaling or EC2 Fleet, now you can just tell it "gimme nodes with 2 to 4 vCPUs and 16 to 64 Gigs of RAM", instead of defining instance types explicitly!
It's available with the new Attribute-Based Instance Type Selection feature
#aws
If you're using EC2 Auto Scaling or EC2 Fleet, now you can just tell it "gimme nodes with 2 to 4 vCPUs and 16 to 64 Gigs of RAM", instead of defining instance types explicitly!
It's available with the new Attribute-Based Instance Type Selection feature
#aws
Amazon
New – Attribute-Based Instance Type Selection for EC2 Auto Scaling and EC2 Fleet | Amazon Web Services
The first AWS service I used, more than ten years ago, was Amazon Elastic Compute Cloud (Amazon EC2). Over time, EC2 has added a wide selection of instance types optimized to fit different use cases, with a varying combination of CPU/GPU, memory, storage…
Forwarded from DevOps Deflope News
Пару дней назад вышел новый Technology Radar от ThoughtWorks (https://a.e42.link/j1qLb).
На этот раз много пунктов относится к инфраструктуре и командообразованию, также немалое количество пунктов про удаленную работу:
— 4 ключевые метрики DORA перешли в Adopt и рекомендуются для применения всеми. Если у вас нет дашборда для их отслеживания можно периодически раз в квартал проходить DORA quick check: https://a.e42.link/j1qWj
— Платформенные команды также перешли в Adopt и рекомендуются как хороший подход. Важно отметить, что платформенная команда это не переименованные operations, а команда разработки точно такая же как и любые другие команды разработки — со своим product owner, продуктовым планированием, разбиением на фичи, работой с бэклогом, и т.д. Одним словом, платформенная команда — это команда разработки, которая пишет продукт для использования внутри компании другими командами
— Учитывание когнитивной нагрузки команд в проектировании архитектуры. Про это уже говорилось в предыдущем радаре и в книге https://a.e42.link/j1qW8 — кто еще не знаком с концепцией и подходом очень рекомендуем ознакомиться
— Remote mob-programming. Это как парное программирование, только больше чем вдвоем и не в одной комнате у доски, а удаленное. Парное программирование мы применяли с отличными результатами как раз через Zoom — оно хорошо подходит для случая когда не совсем ясно как именно и что писать, гораздо лучше чем параллельная работа с синками через каждые 2-3 часа.
— В блоке Assess появилось использование Kubernetes Operator для управления ресурсами за пределами Kubernetes. В предыдущих радарах уже упоминались инструменты для этого, теперь на радаре появилась и сама практика. Также в этом радаре появился и Crossplane (https://a.e42.link/j1qWT)
— В блоке Trial по-прежнему находится https://a.e42.link/j1qWz (инструмент для построения внутренних технологических порталов и витрин),
— Также в этом же блоке появились Clickhouse, Kafka REST Proxy, Kafka Mirrormaker 2.0, OPA Gatekeeper for Kubernetes и Sealed Secrets
— Из Assess в Trial поднялись GitHub Actions, K3s и Pulumi
— Написание скриптов командной строки на Clojure: Babashka (https://a.e42.link/j1qWY) — за счет использования GraalVM обещают, что он стартует мгновенно, а не как другие JVM-приложения
— ExternalDNS для синхронизации ингрессов с DNS-провайдерами появился в Assess
— Batect (https://a.e42.link/j1qWt) как способ настройки окружений локальных и тестовых
— Berglas (https://a.e42.link/j1qWm) для управления секретами в GCP
— Dive (https://a.e42.link/j1qWZ) — сканнер оптимальности сборки докер-образов. Может отслеживать неэффективность послойной сборки и вычислять «лишний» объем образа (например файлы создаются в нижнем слое, а затем удаляются в верхнем слое)
— Lens (https://a.e42.link/j1qWp) как UI для Kubernetes перешел в Trial
— cert-manager (https://a.e42.link/j1qWl) наконец-то появился на радаре
— Появились аж 2 инструмента для тестирования инфракода: Conftest (https://a.e42.link/j1qWB) и Regula (https://a.e42.link/j1qWn). Оба используют язык Open Policy Agent для написания тестов. Такие тесты могут использоваться, например, для автоматизированного тестирования Compliance
— Появился Cosign (https://a.e42.link/j1qWG) — инструмент для подписи и проверки подписи контейнеров
— Забавно, но в этом радаре появились и современные альтернативы командам из Coreutils (под именем Modern Unix commands) наподобие ripgrep, ag, jq, httpie. Большой список таких команд можно посмотреть на https://a.e42.link/j1qWx
— Mozilla Sops (https://a.e42.link/j1qWf) для безопасного хранения шифрованных секретов в гит-репозиториях (с расшифровкой например через AWS KMS)
— Pactflow (https://a.e42.link/j1qWC) — инструмент для тестирования контрактов
— Proxyman (https://a.e42.link/j1qWk) — прокси для отладки веб-приложений
— Telepresence (https://a.e42.link/j1qWe) — инструмент для подключения локально запущенного приложения к удаленному кластеру кубернетес. Может пригодиться например для песочниц разработки
На этот раз много пунктов относится к инфраструктуре и командообразованию, также немалое количество пунктов про удаленную работу:
— 4 ключевые метрики DORA перешли в Adopt и рекомендуются для применения всеми. Если у вас нет дашборда для их отслеживания можно периодически раз в квартал проходить DORA quick check: https://a.e42.link/j1qWj
— Платформенные команды также перешли в Adopt и рекомендуются как хороший подход. Важно отметить, что платформенная команда это не переименованные operations, а команда разработки точно такая же как и любые другие команды разработки — со своим product owner, продуктовым планированием, разбиением на фичи, работой с бэклогом, и т.д. Одним словом, платформенная команда — это команда разработки, которая пишет продукт для использования внутри компании другими командами
— Учитывание когнитивной нагрузки команд в проектировании архитектуры. Про это уже говорилось в предыдущем радаре и в книге https://a.e42.link/j1qW8 — кто еще не знаком с концепцией и подходом очень рекомендуем ознакомиться
— Remote mob-programming. Это как парное программирование, только больше чем вдвоем и не в одной комнате у доски, а удаленное. Парное программирование мы применяли с отличными результатами как раз через Zoom — оно хорошо подходит для случая когда не совсем ясно как именно и что писать, гораздо лучше чем параллельная работа с синками через каждые 2-3 часа.
— В блоке Assess появилось использование Kubernetes Operator для управления ресурсами за пределами Kubernetes. В предыдущих радарах уже упоминались инструменты для этого, теперь на радаре появилась и сама практика. Также в этом радаре появился и Crossplane (https://a.e42.link/j1qWT)
— В блоке Trial по-прежнему находится https://a.e42.link/j1qWz (инструмент для построения внутренних технологических порталов и витрин),
— Также в этом же блоке появились Clickhouse, Kafka REST Proxy, Kafka Mirrormaker 2.0, OPA Gatekeeper for Kubernetes и Sealed Secrets
— Из Assess в Trial поднялись GitHub Actions, K3s и Pulumi
— Написание скриптов командной строки на Clojure: Babashka (https://a.e42.link/j1qWY) — за счет использования GraalVM обещают, что он стартует мгновенно, а не как другие JVM-приложения
— ExternalDNS для синхронизации ингрессов с DNS-провайдерами появился в Assess
— Batect (https://a.e42.link/j1qWt) как способ настройки окружений локальных и тестовых
— Berglas (https://a.e42.link/j1qWm) для управления секретами в GCP
— Dive (https://a.e42.link/j1qWZ) — сканнер оптимальности сборки докер-образов. Может отслеживать неэффективность послойной сборки и вычислять «лишний» объем образа (например файлы создаются в нижнем слое, а затем удаляются в верхнем слое)
— Lens (https://a.e42.link/j1qWp) как UI для Kubernetes перешел в Trial
— cert-manager (https://a.e42.link/j1qWl) наконец-то появился на радаре
— Появились аж 2 инструмента для тестирования инфракода: Conftest (https://a.e42.link/j1qWB) и Regula (https://a.e42.link/j1qWn). Оба используют язык Open Policy Agent для написания тестов. Такие тесты могут использоваться, например, для автоматизированного тестирования Compliance
— Появился Cosign (https://a.e42.link/j1qWG) — инструмент для подписи и проверки подписи контейнеров
— Забавно, но в этом радаре появились и современные альтернативы командам из Coreutils (под именем Modern Unix commands) наподобие ripgrep, ag, jq, httpie. Большой список таких команд можно посмотреть на https://a.e42.link/j1qWx
— Mozilla Sops (https://a.e42.link/j1qWf) для безопасного хранения шифрованных секретов в гит-репозиториях (с расшифровкой например через AWS KMS)
— Pactflow (https://a.e42.link/j1qWC) — инструмент для тестирования контрактов
— Proxyman (https://a.e42.link/j1qWk) — прокси для отладки веб-приложений
— Telepresence (https://a.e42.link/j1qWe) — инструмент для подключения локально запущенного приложения к удаленному кластеру кубернетес. Может пригодиться например для песочниц разработки
There was a question in CatOps chat regarding the resources to learn the Go programming language from scratch with the background in other technologies.
So, here is a quick ad-hoc list of resources, we came up with:
Books:
- Go in Practice
- The Go Programming Language
Courses and tutorials:
- Practical Go Lessons
- Algorythms with Go
- Go by Example
- Effective Go
Blogs:
- Three Dots Labs
Of course, you can also find a great list of learning materials in the Awesome Go list
If you would like to add to this short list - welcome in the comments!
#programming #go
So, here is a quick ad-hoc list of resources, we came up with:
Books:
- Go in Practice
- The Go Programming Language
Courses and tutorials:
- Practical Go Lessons
- Algorythms with Go
- Go by Example
- Effective Go
Blogs:
- Three Dots Labs
Of course, you can also find a great list of learning materials in the Awesome Go list
If you would like to add to this short list - welcome in the comments!
#programming #go
Telegram
CatOps Chat
Chat of the @catops channel
1Password promise two years free membership for their service for Open Source software maintenaners and their teams.
However, to get access you have to be a project lead or a core contributor for an active open source project that is at least 30 days old. We’ll also accept applications from the organisers of community meetups and events, as well as some conferences.
Open source projects need to use a standard open source license and must be non-commercial. Your project should not have paid support or pay contributors.
More details on the linked page.
#security #free_stuff
However, to get access you have to be a project lead or a core contributor for an active open source project that is at least 30 days old. We’ll also accept applications from the organisers of community meetups and events, as well as some conferences.
Open source projects need to use a standard open source license and must be non-commercial. Your project should not have paid support or pay contributors.
More details on the linked page.
#security #free_stuff
GitHub
GitHub - 1Password/for-open-source: Get a 1Password team account for free to support your open source initiatives!
Get a 1Password team account for free to support your open source initiatives! - 1Password/for-open-source
TIL:
AWS has much higher environmental impact comparing to Google Cloud and Azure.
Would it drive decisions on what cloud to chose? I don’t know. Probably not.
However, if you’re looking for a cloud provider for your pet project or a startup, this is something to consider.
#cloud #aws #gcp #azure
AWS has much higher environmental impact comparing to Google Cloud and Azure.
Would it drive decisions on what cloud to chose? I don’t know. Probably not.
However, if you’re looking for a cloud provider for your pet project or a startup, this is something to consider.
#cloud #aws #gcp #azure
Greenpeace USA
Microsoft, Google, Amazon – Who’s the Biggest Climate Hypocrite? - Greenpeace USA
Some of the world’s biggest tech companies want you to know they take climate change seriously. In fact, Amazon, Microsoft, and Google have each developed a plan to address its contributions to climate change. While each company’s plan is unique, none address…
DevOps-ish community loves Go.
So, here's a short story about simple re-arranging fields in a
#programming #go #performance
So, here's a short story about simple re-arranging fields in a
struct that saved 1/3 of memory consumption.#programming #go #performance