
Next Thursday on 30th of September we gonna have our usual voice chat, but in unusual format.
I’ve invited a few guests from people operation teams for a fireside chat about contr-offers.
Langugages: Ukrainian and Russian.
The first hour will be a discussion between guests with a recording and then we’ll turn off the recording and open the discussion for everybody as always.
So, in case you have any questions regardign contr-offers or hiring process in general (or maybe you’re looking for a job?), you can leave your question via this link:
https://app.sli.do/event/9gepm5pf
tl;dr:
What: CatOps fireside chat with people operation team members about contr-offers
When: Thursday, 30th of September
Where: Here in Telegram. A voice chat will take place in our discussions group. I will post a link here before we start.
Languages: Ukrainian, Russian
P.S. The recording will be available in mid October because I’ll be traveling a bit. So, if you don’t want to wait that long, you’d better join live!
#event
I’ve invited a few guests from people operation teams for a fireside chat about contr-offers.
Langugages: Ukrainian and Russian.
The first hour will be a discussion between guests with a recording and then we’ll turn off the recording and open the discussion for everybody as always.
So, in case you have any questions regardign contr-offers or hiring process in general (or maybe you’re looking for a job?), you can leave your question via this link:
https://app.sli.do/event/9gepm5pf
tl;dr:
What: CatOps fireside chat with people operation team members about contr-offers
When: Thursday, 30th of September
Where: Here in Telegram. A voice chat will take place in our discussions group. I will post a link here before we start.
Languages: Ukrainian, Russian
P.S. The recording will be available in mid October because I’ll be traveling a bit. So, if you don’t want to wait that long, you’d better join live!
#event
app.sli.do
Join Slido: Enter #code to vote and ask questions
Participate in a live poll, quiz or Q&A. No login required.
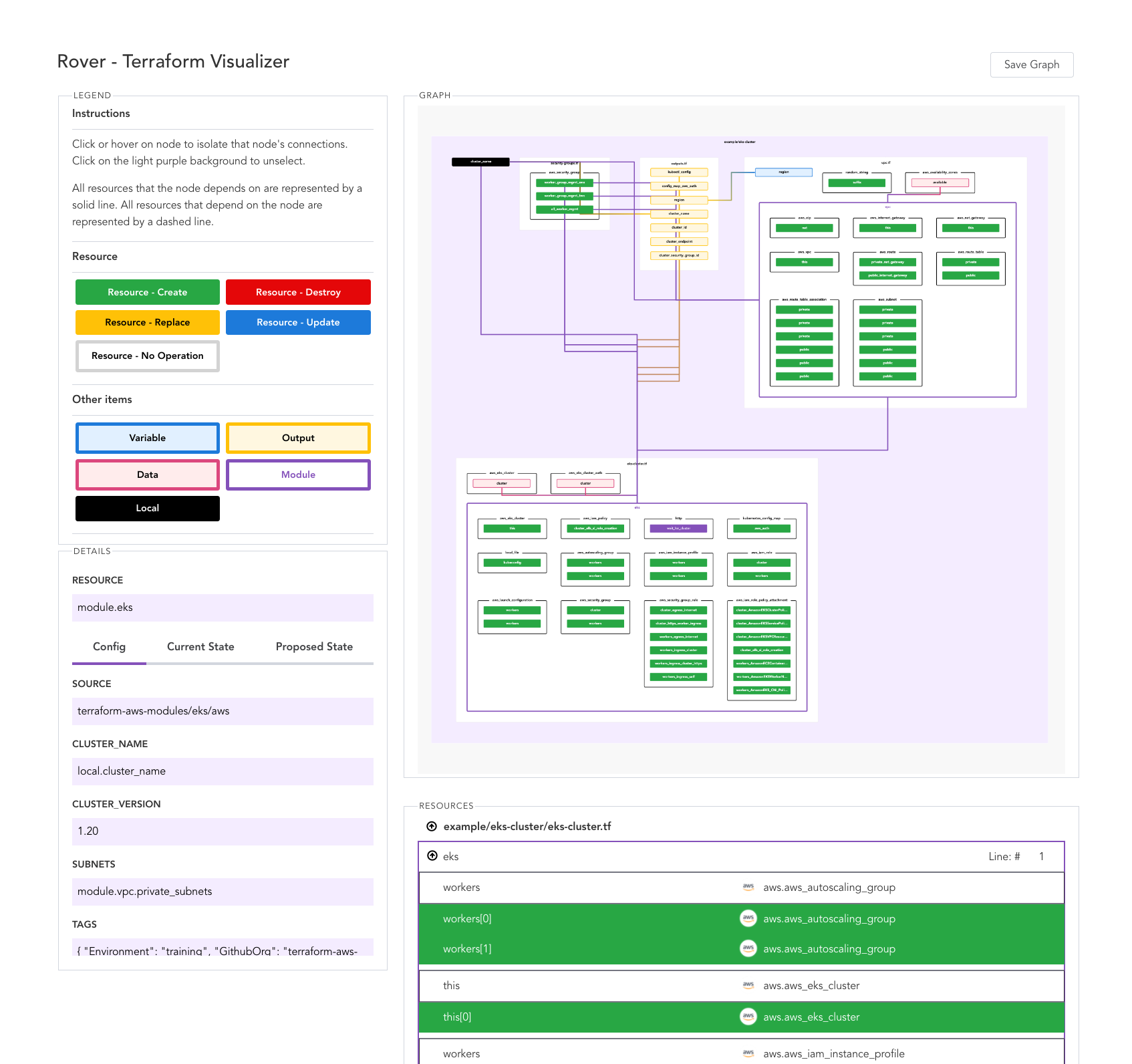
Rover is a tool to visuzlize your Terraform resources and their relations for better understanding of what's going on in your systems.
Rover:
- Generates a
- Parses the
- Consumes the rso, map, and graph to generate an interactive configuration and state visualization hosts on
#terraform #toolz
Rover:
- Generates a
plan file and parses the configuration in the root directory.- Parses the
plan and configuration files to generate three items: the resource overview (rso), the resource map (map), and the resource graph (graph).- Consumes the rso, map, and graph to generate an interactive configuration and state visualization hosts on
localhost:9000.#terraform #toolz
{kind=link}
You can now use Application Load Balancer as the target for Network Load Balancer in AWS.
From the document itself:
#aws
From the document itself:
configuration combines the features of both load balancers and offers the following advantages:
- You can use the layer 7 request-based routing feature of the Application Load Balancer in combination with features that the Network Load Balancer supports, such as endpoint services (AWS PrivateLink) and static IP addresses.
- The configuration works well for applications that use multi-protocol connections, such as media services using HTTP for signaling, and RTP to stream content.
- You can use this feature with an internal or internet-facing Application Load Balancer as the target of an internal or internet-facing Network Load Balancer.
#aws
Amazon
Use an Application Load Balancer as a target of a Network Load Balancer - Elastic Load Balancing
Learn how to use an Application Load Balancer as the target of a Network Load Balancer.
Here you can get a free copy of Chaos Engineering book by Casey Rosenthal & Nora Jones in exchange for your personal data.
#books
#books
Verica
Free Copy of Chaos Engineering: System Resiliency in Practice
Get the entire 275-page book of Chaos Engineering from O'Reilly for free, compliments of Verica. Click to get yours today.
Just want to remind you that tomorrow we're going to have a voice chat about counter offers.
You still can put your question here:
https://app.sli.do/event/9gepm5pf/live/questions
Hear you tomorrow!
#event
You still can put your question here:
https://app.sli.do/event/9gepm5pf/live/questions
Hear you tomorrow!
#event
Telegram
CatOps
Next Thursday on 30th of September we gonna have our usual voice chat, but in unusual format.
I’ve invited a few guests from people operation teams for a fireside chat about contr-offers.
Langugages: Ukrainian and Russian.
The first hour will be a discussion…
I’ve invited a few guests from people operation teams for a fireside chat about contr-offers.
Langugages: Ukrainian and Russian.
The first hour will be a discussion…
Just in 5 minutes we’re starting the live discussion about counter offers!
You can join via this link:
https://t.iss.one/catops_chat?voicechat=fe301b35ab320101fc
Language: Ukrainian / Russian
P.S. You can still ask your question in Slido:
https://app.sli.do/event/9gepm5pf
#event
You can join via this link:
https://t.iss.one/catops_chat?voicechat=fe301b35ab320101fc
Language: Ukrainian / Russian
P.S. You can still ask your question in Slido:
https://app.sli.do/event/9gepm5pf
#event
Telegram
CatOps Chat
Chat of the @catops channel
Friday material.
Here's a Gist for pre-commit hook that detects words from a disallowed list and blocks the commit.
No more fucks in your code!
Here's a Gist for pre-commit hook that detects words from a disallowed list and blocks the commit.
No more fucks in your code!
Gist
Pre-commit hook to prevent dummy text from being committed
Pre-commit hook to prevent dummy text from being committed - fartgun.txt
SpiceDB is now open source!
But, what's SpiceDB anyways? It is a production-ready implementation of Google’s Zanzibar paper. Zanzibar is a distributed relationship-based authorization system that Google uses to manage permissions for most of their core cloud products.
It has some nice additions to it as well. It can use various backends, output valuable metrics, etc.
Also, it can compute inverse permissions for a user. It means that you can not only ask the question: “does user have permission to access resource?” With SpiceDB you can additionally ask: “which resources can user access?”.
#security #oss #auth
But, what's SpiceDB anyways? It is a production-ready implementation of Google’s Zanzibar paper. Zanzibar is a distributed relationship-based authorization system that Google uses to manage permissions for most of their core cloud products.
It has some nice additions to it as well. It can use various backends, output valuable metrics, etc.
Also, it can compute inverse permissions for a user. It means that you can not only ask the question: “does user have permission to access resource?” With SpiceDB you can additionally ask: “which resources can user access?”.
#security #oss #auth
Authzed
SpiceDB, the Google Zanzibar open source solution | AuthZed.com
Discover SpiceDB, a Google Zanzibar open source solution. SpiceDB is a production-ready, scalable and globally replicated permissions engine based on the Google Zanzibar paper.
Operator Builder is an extension of Kubebuilder to facilitate development and maintenance of Kubernetes operators.
For example, it can generate а CRD based on special markers in your static YAML. So, you can convert a subset of basic k8s resources into a custom one.
#kubernetes
For example, it can generate а CRD based on special markers in your static YAML. So, you can convert a subset of basic k8s resources into a custom one.
#kubernetes
GitHub
GitHub - vmware-archive/operator-builder: A Kubebuilder plugin to accelerate the development of Kubernetes operators
A Kubebuilder plugin to accelerate the development of Kubernetes operators - GitHub - vmware-archive/operator-builder: A Kubebuilder plugin to accelerate the development of Kubernetes operators
Very detailed post by Cloudflare, what happens with Facebook yesterday.
It's good time to remember (or learn) how BGP and DNS works
It's good time to remember (or learn) how BGP and DNS works
The Cloudflare Blog
Understanding how Facebook disappeared from the Internet
Today at 1651 UTC, we opened an internal incident entitled "Facebook DNS lookup returning SERVFAIL" because we were worried that something was wrong with our DNS resolver 1.1.1.1. But as we were about to post on our public status page we realized something…
Humble Bundle books on infrastructure and OPS by O'Reilly
As usual, you can pay different amount of money to unlock items in the bundle. These bundle contains:
>= €1:
- Database Reliability Engineering
- Dynamic Reteaming, 2nd Edition
- Learning Kali Linux
- Prometheus: Up & Running
- Jenkins 2: Up and Running
>= €8.54:
- €1 bundle +
- Migrating to AWS: A Manager's Guide, 1st Edition
- Terraform: Up & Running, 2nd Edition
- Learning Apache OpenWhisk
- Cybersecurity Ops with Bash
- Seeking SRE
>= €15.38:
- All from above +
- Kubernetes Operators
- Kubernetes Best Practices
- Learning Helm
- Distributed Systems with Node.js
- Distributed Tracing in Practice
#books
As usual, you can pay different amount of money to unlock items in the bundle. These bundle contains:
>= €1:
- Database Reliability Engineering
- Dynamic Reteaming, 2nd Edition
- Learning Kali Linux
- Prometheus: Up & Running
- Jenkins 2: Up and Running
>= €8.54:
- €1 bundle +
- Migrating to AWS: A Manager's Guide, 1st Edition
- Terraform: Up & Running, 2nd Edition
- Learning Apache OpenWhisk
- Cybersecurity Ops with Bash
- Seeking SRE
>= €15.38:
- All from above +
- Kubernetes Operators
- Kubernetes Best Practices
- Learning Helm
- Distributed Systems with Node.js
- Distributed Tracing in Practice
#books
Humble Bundle
Humble Book Bundle: Infrastructure and Ops by O'Reilly
We’ve teamed up with O'Reilly to help you mold our modern world with books like Kubernetes Operators & Learning Helm. Pay what you want & support charity!
{kind=link}
We had a hiring sync up meeting recently to improve the interviewing process and formalize the expectations for each grade.
In nutshell, we brainstormed a long list of competences, which we expect a candidate to have and then tried to align on them and also agree on how good should one be in each of those competences to be put in each grade.
Some interesting insights happened there. My favorite is that we all agreed that a candidate should seek new knowledge: read books and articles, keep an eye on the industry, etc. However, the purpose for seeking knowledge is different for each grade!
We expect junior engineers to be generally curious and seek knowledge for fun or because something is interesting, or because it's a trendy thing.
Later in their career, we expect one to seek knowledge in order to get things done, become a better engineer in their area and eventually become a senior in that field.
On a senior level we think that people are seeking knowledge to keep their project moving forward and become an expert.
And eventually people on the positions beyond senior are seeking knowledge to elevate others and make the whole company moving faster.
Of course, many of these things are overlapping. A junior engineer can totally care about a project and find the ways to improve it, as well as senior+ engineer can seek new knowledge to broaden their scope.
However, this whole idea of change from "discover things to improve myself" to "discover things to improve others" pulls some internal strings of myself.
#culture
In nutshell, we brainstormed a long list of competences, which we expect a candidate to have and then tried to align on them and also agree on how good should one be in each of those competences to be put in each grade.
Some interesting insights happened there. My favorite is that we all agreed that a candidate should seek new knowledge: read books and articles, keep an eye on the industry, etc. However, the purpose for seeking knowledge is different for each grade!
We expect junior engineers to be generally curious and seek knowledge for fun or because something is interesting, or because it's a trendy thing.
Later in their career, we expect one to seek knowledge in order to get things done, become a better engineer in their area and eventually become a senior in that field.
On a senior level we think that people are seeking knowledge to keep their project moving forward and become an expert.
And eventually people on the positions beyond senior are seeking knowledge to elevate others and make the whole company moving faster.
Of course, many of these things are overlapping. A junior engineer can totally care about a project and find the ways to improve it, as well as senior+ engineer can seek new knowledge to broaden their scope.
However, this whole idea of change from "discover things to improve myself" to "discover things to improve others" pulls some internal strings of myself.
#culture
A series of articles by Rookout on developer tools for working with a Kubernetes cluster.
- Part I: Helm, Kustomize, and Skaffold
- Part II: Skaffold, Tilt, and Garden
- Part III: Lens, VSCode, IntelliJ & Gitpod
- Part IV: Docker, BuildKit, Buildpacks, Jib & Kaniko
- Part V: Development Machines
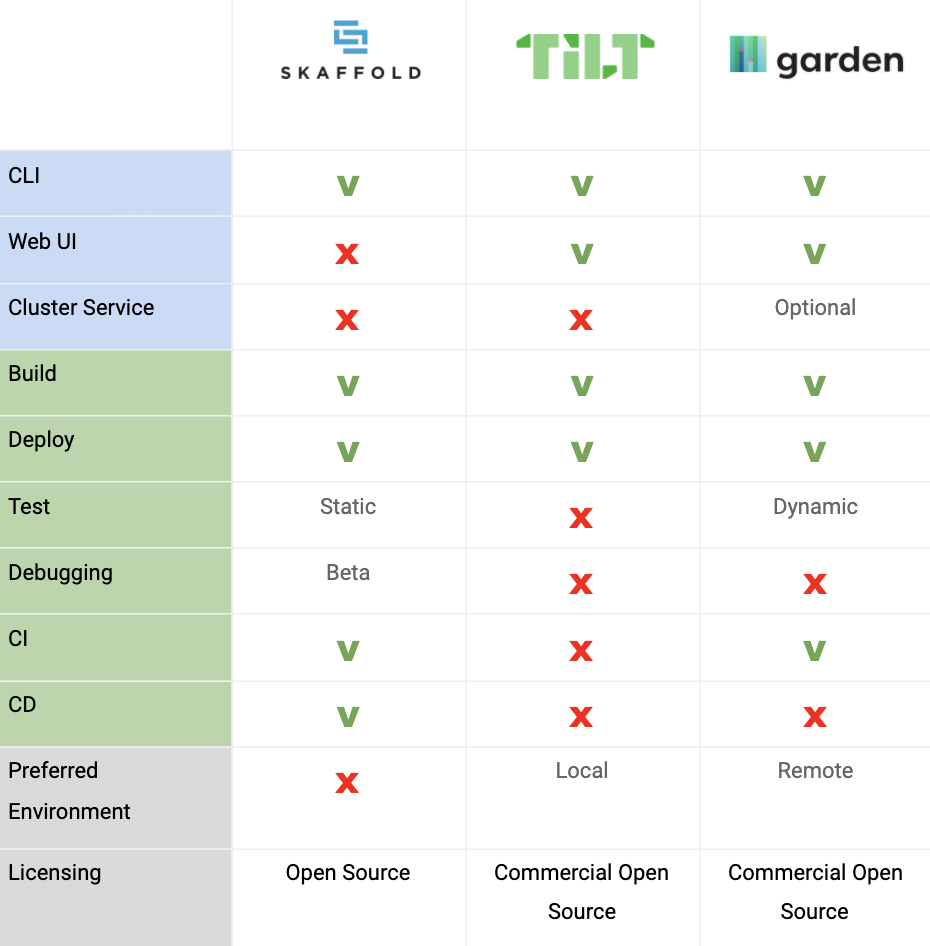
The second part is particularly interesting because of the comparison table.
#kubernetes
- Part I: Helm, Kustomize, and Skaffold
- Part II: Skaffold, Tilt, and Garden
- Part III: Lens, VSCode, IntelliJ & Gitpod
- Part IV: Docker, BuildKit, Buildpacks, Jib & Kaniko
- Part V: Development Machines
The second part is particularly interesting because of the comparison table.
#kubernetes
{kind=link}
In less than a week will start HashiConf Global
So, we have great proposal for our community - talk with Hashimoto and Dadgar on HUG Kyiv later this year in convenient for us time zone.
And, in the brightest future, we would like HashiCorp to listen to the opinion of our community.
This can't be done without your help! Please, find 5 minutes to make the big thing real - vote for HUG Kyiv!
#event
So, we have great proposal for our community - talk with Hashimoto and Dadgar on HUG Kyiv later this year in convenient for us time zone.
And, in the brightest future, we would like HashiCorp to listen to the opinion of our community.
This can't be done without your help! Please, find 5 minutes to make the big thing real - vote for HUG Kyiv!
#event
{kind=link}
{kind=link}
Here is the awesome list of GitHub Actions both official and community-driven.
So, if you were looking into working with GHA, that might be a good thing to check. Also, if you're using GHA already, you may find some common actions to remove some repeated lines of code in your pipelines.
P.S. If you are not interested in GitHub Actions, but still adore the idea of YAML based CI, I just want to remind you that you can use YAML to configure Jenkins pipelines as well
#cicd #github #gha #jenkins
So, if you were looking into working with GHA, that might be a good thing to check. Also, if you're using GHA already, you may find some common actions to remove some repeated lines of code in your pipelines.
P.S. If you are not interested in GitHub Actions, but still adore the idea of YAML based CI, I just want to remind you that you can use YAML to configure Jenkins pipelines as well
#cicd #github #gha #jenkins
GitHub
GitHub - sdras/awesome-actions: A curated list of awesome actions to use on GitHub
A curated list of awesome actions to use on GitHub - sdras/awesome-actions
From our subscribers.
10 trends of real-world container use by DataDog.
1. ~90% of Kubernetes users leverage cloud-managed services
2. Amazon ECS users are shifting to Fargate
3. The average number of pods per organization has doubled
4. Host density is 3 times higher on Kubernetes than on Amazon ECS
5. Pod auto-scaling is becoming more popular
6. Organizations are deploying more stateful workloads on containers
7. Organizations running container environments create more monitors
8. Organizations are starting to replace Docker with containerd as their preferred runtime for Kubernetes
9. OpenShift adoption is growing rapidly
10. NGINX, Redis, and Postgres are the top three container images
More details are in the report.
#trends #containers
10 trends of real-world container use by DataDog.
1. ~90% of Kubernetes users leverage cloud-managed services
2. Amazon ECS users are shifting to Fargate
3. The average number of pods per organization has doubled
4. Host density is 3 times higher on Kubernetes than on Amazon ECS
5. Pod auto-scaling is becoming more popular
6. Organizations are deploying more stateful workloads on containers
7. Organizations running container environments create more monitors
8. Organizations are starting to replace Docker with containerd as their preferred runtime for Kubernetes
9. OpenShift adoption is growing rapidly
10. NGINX, Redis, and Postgres are the top three container images
More details are in the report.
#trends #containers
Datadog
10 insights on real world container use | Datadog
Our latest report examines more than 2.4 billion containers run by tens of thousands of Datadog customers to understand the state of the container ecosystem.
Finally! The recording of our voice chat about counter-offers is available online!
Our chat was in the mix of Ukrainian and Russian. You can listen to it on:
- Anchor
- Spotify
- Apple Podcasts
Unfortunately, Google Podcasts haven’t approved us yet. Hopefully, you’d be able to listen to this chat there soon.
You can also “watch” it on YouTube. I used quotes, because this is really just an audio with a static image.
TBH, I cannot promise when any other voice chats like this one will take place. In any case, though. Hit “like”, “subscribe”, all those usual things. Just in case we have more.
P.S. The next voice chat will be this Thursday! 17:00 UTC as usual in our discussions group
#voice_chat
Our chat was in the mix of Ukrainian and Russian. You can listen to it on:
- Anchor
- Spotify
- Apple Podcasts
Unfortunately, Google Podcasts haven’t approved us yet. Hopefully, you’d be able to listen to this chat there soon.
You can also “watch” it on YouTube. I used quotes, because this is really just an audio with a static image.
TBH, I cannot promise when any other voice chats like this one will take place. In any case, though. Hit “like”, “subscribe”, all those usual things. Just in case we have more.
P.S. The next voice chat will be this Thursday! 17:00 UTC as usual in our discussions group
#voice_chat
Spotify for Creators
CatOps • A podcast on Spotify for Podcasters
DevOps & other issues
This is a good and very important article on SRE structure - SRE Doesn’t Scale.
The main idea is, well, as it's stated in the title, that providing so-called "SRE support" doesn't scale well. It requires a lot of resources and manpower, and the majority of those resources are wasted in ad-hoc firefighting and context switch.
To solve this problem, a platform itself should be "productized" or "commodified". I.e. your platform should become an internal product. So, users of this platform can interact with it via APIs and ask for changes via feature requests and bug reports. As well as, your users will be able to share some good practices on how to interact with your platform among themselves.
Some notable quotes:
> Even Google, who has infinite money and an endless recruiting pipeline, says the SRE model—as it is often described by the people we encounter referencing the book—does not scale with microservices. Instead, they go on to describe a more tractable, framework-oriented model to address this through things like codified best practices, reusable solutions, standardization of tools and patterns, and, more generally, what I describe as the “productization” of infrastructure and operations.
> For some reason, this little detail gets lost and, consequently, we see groups attempting to throw people at the problem, such as embedding an SRE on each team. In practice, this usually means two things: 1) hiring a whole bunch of SREs—which even Google admits to being difficult and costly—and 2) this person typically just becomes the “whipping boy” for the team. More often than not, this individual is some poor ops person who gets labeled “SRE.”
And my favorite:
> In fact, many groups are probably better off simply removing “SRE” and “DevOps” from their vocabulary altogether because they often end up being distracting buzzwords.
#culture
The main idea is, well, as it's stated in the title, that providing so-called "SRE support" doesn't scale well. It requires a lot of resources and manpower, and the majority of those resources are wasted in ad-hoc firefighting and context switch.
To solve this problem, a platform itself should be "productized" or "commodified". I.e. your platform should become an internal product. So, users of this platform can interact with it via APIs and ask for changes via feature requests and bug reports. As well as, your users will be able to share some good practices on how to interact with your platform among themselves.
Some notable quotes:
> Even Google, who has infinite money and an endless recruiting pipeline, says the SRE model—as it is often described by the people we encounter referencing the book—does not scale with microservices. Instead, they go on to describe a more tractable, framework-oriented model to address this through things like codified best practices, reusable solutions, standardization of tools and patterns, and, more generally, what I describe as the “productization” of infrastructure and operations.
> For some reason, this little detail gets lost and, consequently, we see groups attempting to throw people at the problem, such as embedding an SRE on each team. In practice, this usually means two things: 1) hiring a whole bunch of SREs—which even Google admits to being difficult and costly—and 2) this person typically just becomes the “whipping boy” for the team. More often than not, this individual is some poor ops person who gets labeled “SRE.”
And my favorite:
> In fact, many groups are probably better off simply removing “SRE” and “DevOps” from their vocabulary altogether because they often end up being distracting buzzwords.
#culture
Brave New Geek
SRE Doesn’t Scale
We encounter a lot of organizations talking about or attempting to implement SRE as part of our consulting at Real Kinetic. We’ve even discussed and debated ourselves, ad nauseam, how we can apply …