
Kinda longread about optimizations of JS code in the environments, where JIT compilation is not available e.g. iOS, gaming consoles, serverless environments, etc.
The main idea is to run JS inside WebAssembly instance.
Wizer pre-initializer is used as an example here.
Even though, information from here might be not very useful for the people, who run JS in a "traditional" way I.e. in a browser. However, I personally think this is an interesting read for those who build JS-powered serverless services as well as those who deploy JS code to portable devices.
Also, it's important to mark that such an approach could be used for other run other runtimes like Python, Ruby, or Lua.
#programming
The main idea is to run JS inside WebAssembly instance.
Wizer pre-initializer is used as an example here.
Even though, information from here might be not very useful for the people, who run JS in a "traditional" way I.e. in a browser. However, I personally think this is an interesting read for those who build JS-powered serverless services as well as those who deploy JS code to portable devices.
Also, it's important to mark that such an approach could be used for other run other runtimes like Python, Ruby, or Lua.
#programming
Bytecode Alliance
Making JavaScript run fast on WebAssembly
JavaScript in the browser runs many times faster than it did two decades ago. And that happened because the browser vendors spent that time working on intensive performance optimizations.
Stargz Snapshotter is a non-core containerd project which allows you to lazy load container images and speed up start up time.
It works with
You can read more about
#containers
It works with
stargz (seekable tar.gz) image format. Also, it has a converter that optimizes images for better loading (since you will need to communicate with a remote fs) You can read more about
stargz format in the buildkit documentation#containers
Medium
Startup Containers in Lightning Speed with Lazy Image Distribution on Containerd
Introducing containerd non-core subproject Stargz Snapshotter
There is a saying that there are only two ways to learn something: to build it or to fix it.
Sam Lewis have built his own mesh VPN solution to learn better how those mesh VPNs work. And also because he could.
He put it all into a blog post. So, you can find some insights about mesh VPNs there. Probably, you won't even need to build your own.
In any case, this is not a tool you should get into production right away. Just an interesting read. No more, no less.
#networking #security #vpn
Sam Lewis have built his own mesh VPN solution to learn better how those mesh VPNs work. And also because he could.
He put it all into a blog post. So, you can find some insights about mesh VPNs there. Probably, you won't even need to build your own.
In any case, this is not a tool you should get into production right away. Just an interesting read. No more, no less.
#networking #security #vpn
www.samlewis.me
Sam Lewis
Sam Lewis is a Melbourne based geek who develops cool bits of code. He likes data, embedded stuff and AFL.
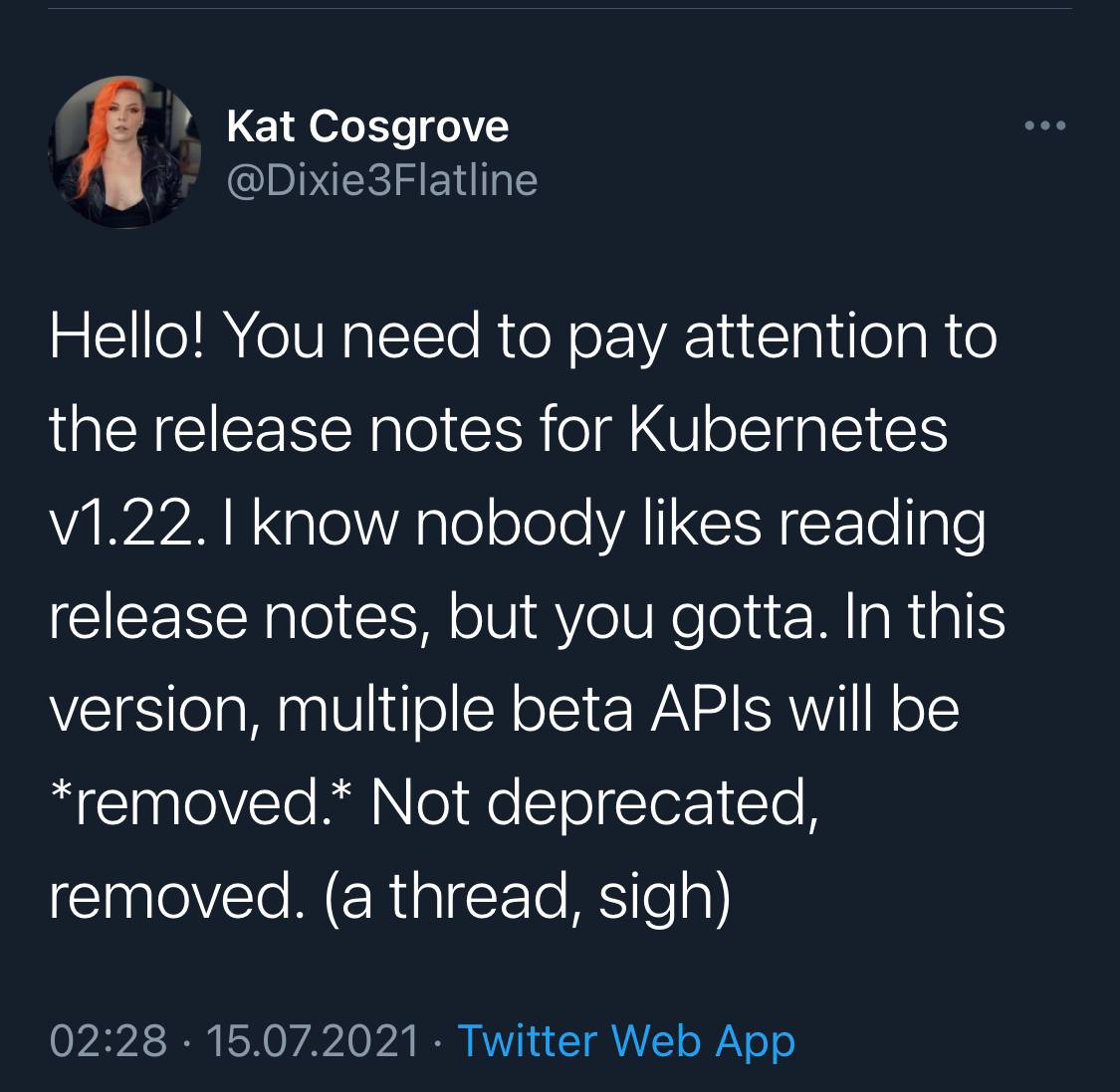
Be extra careful upgrading Kubernetes to v1.22. A lot of API beta versions are completely removed in that release.
Among them:
- Ingress
- CustomResourceDefinition
- ValidatingWebhookConfiguration
- MutatingWebhookConfiguration
- CertificateSigningRequest
There are some more that you can find in the release notes. Also, release notes contain the information on how to upgrade to more stable API versions.
#kubernetes
Among them:
- Ingress
- CustomResourceDefinition
- ValidatingWebhookConfiguration
- MutatingWebhookConfiguration
- CertificateSigningRequest
There are some more that you can find in the release notes. Also, release notes contain the information on how to upgrade to more stable API versions.
#kubernetes
{kind=link}
A small neat write up on learnings about incident responses
Key takeaways:
- Declare incidents on smaller things. Division between SEV1 and SEV3 incidents helps you to track system health better. As well a bunch of smaller problems may lead to a critical failure. Also, such problems are usually easy to fix one by one.
- Decrease the time between the incident and postmortem analysis. Analysis will be much more accurate, when you have a fresh memory of what has happened.
- Alert on symptoms, not causes. Alert only if your users (external or internal) have issues, not when CPU utilization is high
#observability
Key takeaways:
- Declare incidents on smaller things. Division between SEV1 and SEV3 incidents helps you to track system health better. As well a bunch of smaller problems may lead to a critical failure. Also, such problems are usually easy to fix one by one.
- Decrease the time between the incident and postmortem analysis. Analysis will be much more accurate, when you have a fresh memory of what has happened.
- Alert on symptoms, not causes. Alert only if your users (external or internal) have issues, not when CPU utilization is high
#observability
FireHydrant
Pragmatic Incident Response: 3 Lessons Learned from Failures
Lessons learned from the front line that you actually immediately use in your incident management process.
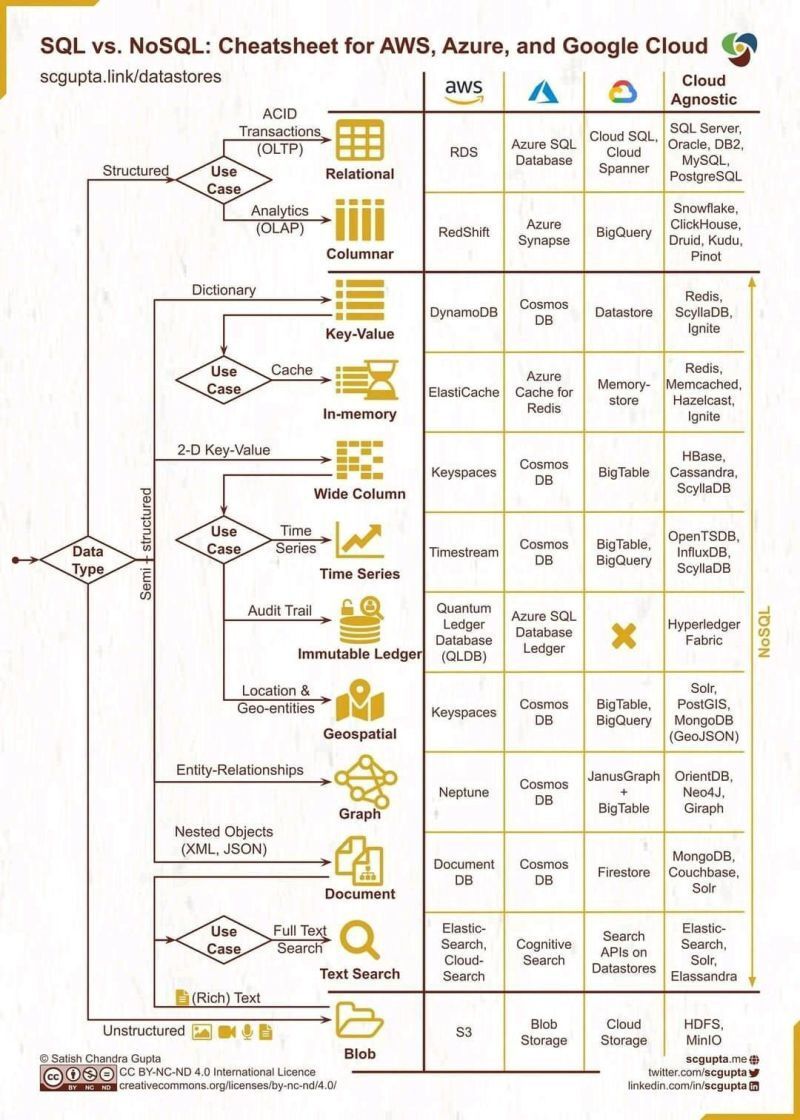
Data storage cheatsheet for public clouds and cloud-agnostic services as well.
This obviously not a full list of all the available databases. However, it provides some insights on what the Big Three cloud vendors provide as well as some open-source alternatives.
#databases
This obviously not a full list of all the available databases. However, it provides some insights on what the Big Three cloud vendors provide as well as some open-source alternatives.
#databases
{kind=link}
Alongside with Lambda@Edge and CloudFlare Workers Fastly presents their own Compute@Edge solution.
Now you can run JavaScript code on Fastly's edge locations. They also promise zero cold starts for this service and high level of isolation & security because the technology that creates and destroys a sandbox for each individual request from JavaScript compiled through WebAssembly.
#cdn #edge
Now you can run JavaScript code on Fastly's edge locations. They also promise zero cold starts for this service and high level of isolation & security because the technology that creates and destroys a sandbox for each individual request from JavaScript compiled through WebAssembly.
#cdn #edge
Fastly
Fastly Launches New Era of Highly-Secure Serverless JavaScript With Zero Cold Starts
Fastly’s edge cloud platform helps the world’s most popular digital businesses keep pace with their customer expectations by delivering fast, secure, and scalable online experiences.
Kent Beck is arguing that not all the things can be changed by setting the incentives.
Moreover, wrong or vague incentives can bring more harm than good. For example, when you push for TDD and incentify people simply to write tests, they would. However, a lot of those tests will be bad tests.
Being very careful and patient while creating incentives is crucial not only for technical organization, but for any organization in general.
#culture
Moreover, wrong or vague incentives can bring more harm than good. For example, when you push for TDD and incentify people simply to write tests, they would. However, a lot of those tests will be bad tests.
Being very careful and patient while creating incentives is crucial not only for technical organization, but for any organization in general.
#culture
Substack
Incentives Change Marginal Behavior
It’s not all about incentives. Incentives matter. Incentives are one of the key lessons of economics. People don’t just act, they act for reasons. It’s not Brownian buying & selling & inventing & marketing. & cheating & conniving & colluding for no reason…
Not some technical news, but important ones.
Google is delaying return to the office till mid-October at least in the US.
Also, once campuses are fully re-opened, they will demand any person to come in to be fully vaccinated. This is important because a lot of smaller companies tend to copy the behavior (and tech approaches) from the industry giants. Therefore, many other companies will delay the return as well.
Also, this a loud and clear signal regarding the vaccination. Probably, the first one came from the private sector in the IT industry.
Obviously, this article doesn't mean that Google accepts remote work. This battle is yet to be fought. However, the world has already changed. Remote work is no longer an exceptional benefit. More and more companies now offer a hybrid format at least. And I personally can only welcome these changes!
Google is delaying return to the office till mid-October at least in the US.
Also, once campuses are fully re-opened, they will demand any person to come in to be fully vaccinated. This is important because a lot of smaller companies tend to copy the behavior (and tech approaches) from the industry giants. Therefore, many other companies will delay the return as well.
Also, this a loud and clear signal regarding the vaccination. Probably, the first one came from the private sector in the IT industry.
Obviously, this article doesn't mean that Google accepts remote work. This battle is yet to be fought. However, the world has already changed. Remote work is no longer an exceptional benefit. More and more companies now offer a hybrid format at least. And I personally can only welcome these changes!
AP NEWS
Google delays return to office, mandates vaccines
SAN RAMON, Calif. (AP) — Google is postponing a return to the office for most workers until mid-October and rolling out a policy that will eventually require everyone to be vaccinated once its sprawling campuses are fully reopened.
Flant has officially announced their Deckhouse solution to bootstrap ready to use Kubernetes platforms.
I've already written about it here: https://t.iss.one/catops/1723
So, not to repeat myself too much: I think this is a move in the right direction. I expect more and more Kubernetes distributions in the future, just like it happened to Linux.
People need platforms, not orchestrators!
#kubernetes
I've already written about it here: https://t.iss.one/catops/1723
So, not to repeat myself too much: I think this is a move in the right direction. I expect more and more Kubernetes distributions in the future, just like it happened to Linux.
People need platforms, not orchestrators!
#kubernetes
Medium
Announcing Deckhouse, the Kubernetes Platform from Flant is now generally available
Today, we are delighted to announce the first Open Source release of Deckhouse. Developing and operating the platform in numerous, very…
Forwarded from AWS Notes
CDK Construct Hub:
https://aws.amazon.com/blogs/developer/construct-hub-preview/
#CDK
https://aws.amazon.com/blogs/developer/construct-hub-preview/
Construct Hub is a one-stop destination for finding, reusing and sharing constructs authored by AWS, AWS Partner Network partners, third parties, and the developer community.CDK constructs are cloud architecture building blocks and patterns that you can use to stand up complete production-ready cloud applications.#CDK
Amazon
Construct Hub Developer Preview | Amazon Web Services
We are excited to announce the Construct Hub developer preview. It is a one-stop destination for finding, reusing and sharing constructs authored by AWS, AWS Partner Network partners, third parties, and the developer community. In the preview version of the…
"When I see a door with a push sign, I pull first to avoid conflicts" - anonymous
In version 2.23 of git, two new commands have been introduced: git switch and git restore. Both are aimed to replace ambiguous behavior of git checkout. Although, the original checkout command is still available.
Switch works the same way as checkout on branches and restore as checkout on files.
Why? Because the previous implementation was confusing.
#git
In version 2.23 of git, two new commands have been introduced: git switch and git restore. Both are aimed to replace ambiguous behavior of git checkout. Although, the original checkout command is still available.
Switch works the same way as checkout on branches and restore as checkout on files.
Why? Because the previous implementation was confusing.
#git
Banterly
New in Git: switch and restore
To my surprise, I recently found out about 2 new additions to the list of high-level commands: git restore and git switch
I remember being on a meetup in the Twitter HQ where people were talking about the success of Finagle and eventually presented an idea and some first versions of Linkerd.
It was in 2017 and now Linkerd is a graduated project of CNCF.
Congratulations!
These is an interesting part:
Linkerd is the first service mesh to rise to the level of graduation. But Linkerd has a long history of firsts: Linkerd was the first service mesh project and the one to coin the term itself. It was the first project to enter the CNCF’s inception (now sandbox) phase. It was the first CNCF project to adopt Rust
P.S. A nostalgic photo from the Twitter HQ
#networking
It was in 2017 and now Linkerd is a graduated project of CNCF.
Congratulations!
These is an interesting part:
Linkerd is the first service mesh to rise to the level of graduation. But Linkerd has a long history of firsts: Linkerd was the first service mesh project and the one to coin the term itself. It was the first project to enter the CNCF’s inception (now sandbox) phase. It was the first CNCF project to adopt Rust
P.S. A nostalgic photo from the Twitter HQ
#networking
{kind=link}
Would be nice to get this for mobile devices as well.Anyways, this is a great feature and a huge step forward!
https://twitter.com/github/status/1425505817827151872?s=28
https://twitter.com/github/status/1425505817827151872?s=28
Twitter
GitHub
🤫 New shortcut: Press . on any GitHub repo.
Welcome the new ultimate versioning convention for modern projects - 0ver!
.
.
.
.
.
.
P.S. This is a satire post. You should not do that!
.
.
.
.
.
.
P.S. This is a satire post. You should not do that!
0ver.org
ZeroVer: 0-based Versioning — zer0ver
Software's most popular versioning scheme!
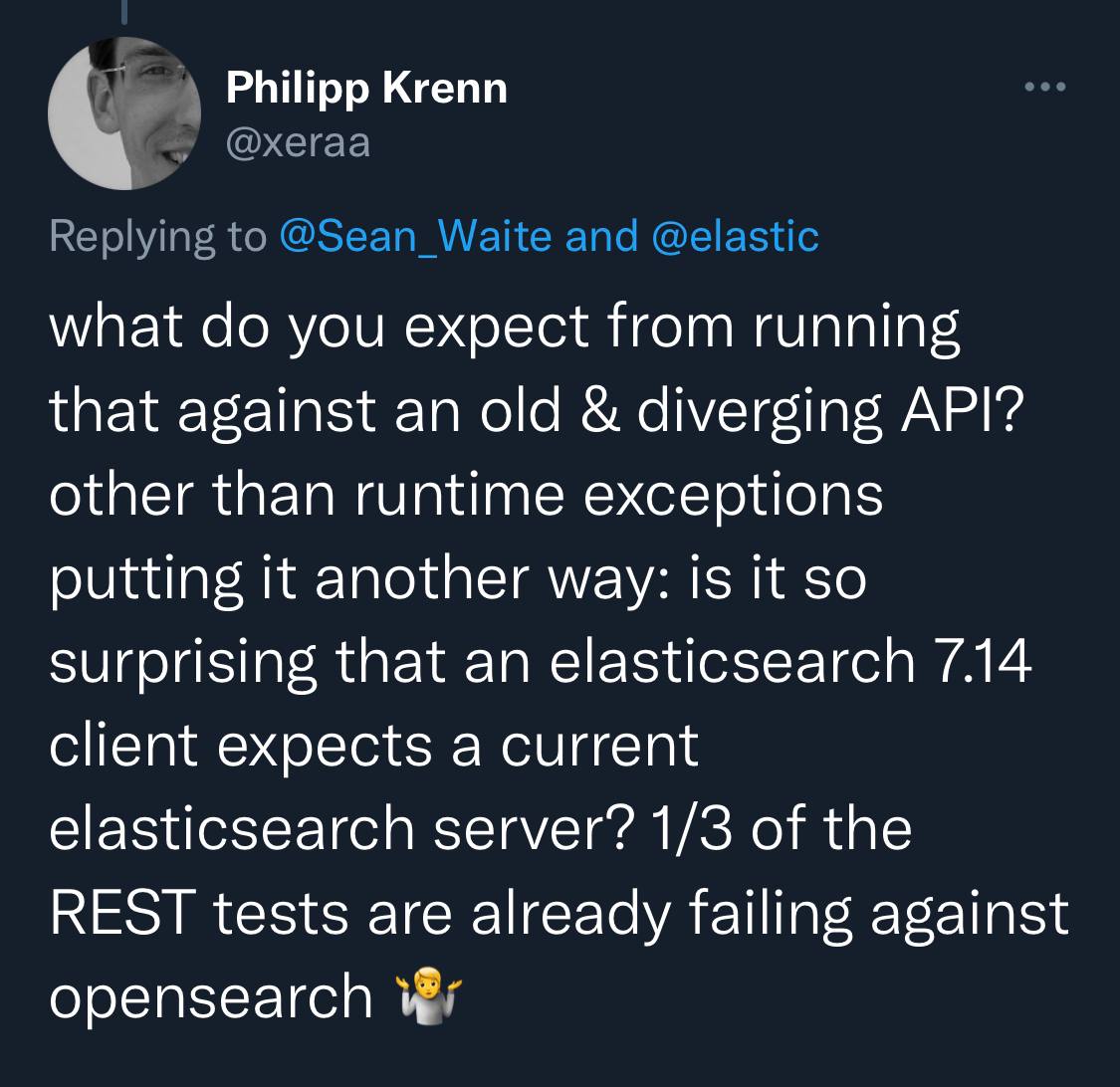
Ok, the headline is a bit clickbait, but the truth is that you have to use Elastic 7.14 in order to upgrade your client libraries. You will get an error otherwise.
On one hand, the recent change in Elastic clients do break compatibility with the older APIs and it generates some righteous anger. On another hand, supporting backward compatibility is hard. You have to make breaking changes sometimes.
In the current situation, it's especially important to understand that OpenSearch and ElasticSearch are different products now. You can keep compatibility between them for some time (this was a promise from AWS, not Elastic, actually) but it's obvious that two products diverge eventually. And Elastic is not obliged to keep their products compatible with whatsoever AWS has.
Although, Elastic did this change as per the minor version update, which kinda violates semVer principles. However, it seems to me that no one cares about the semVer principles these days (see the previous post).
#elasticsearch #aws
On one hand, the recent change in Elastic clients do break compatibility with the older APIs and it generates some righteous anger. On another hand, supporting backward compatibility is hard. You have to make breaking changes sometimes.
In the current situation, it's especially important to understand that OpenSearch and ElasticSearch are different products now. You can keep compatibility between them for some time (this was a promise from AWS, not Elastic, actually) but it's obvious that two products diverge eventually. And Elastic is not obliged to keep their products compatible with whatsoever AWS has.
Although, Elastic did this change as per the minor version update, which kinda violates semVer principles. However, it seems to me that no one cares about the semVer principles these days (see the previous post).
#elasticsearch #aws
{kind=link}
Getting back to the AWS architecture diagram from yesterday.
First of all, that was a joking post. If such an infrastructure works for them, that's OK.
The diagram is from this article, where they suggest 3 tips for working with Kinesis streams. So, if you're running Kinesis in your production systems as well, this article might be interesting for you too.
Also, they describe why did they move to such a serverless infrastructure in a series of short posts:
- An overview
- Testing and CI/CD
- Operations
There are actually more useful links for Lambda users inside those articles.
Enjoy!
#aws #serverless
First of all, that was a joking post. If such an infrastructure works for them, that's OK.
The diagram is from this article, where they suggest 3 tips for working with Kinesis streams. So, if you're running Kinesis in your production systems as well, this article might be interesting for you too.
Also, they describe why did they move to such a serverless infrastructure in a series of short posts:
- An overview
- Testing and CI/CD
- Operations
There are actually more useful links for Lambda users inside those articles.
Enjoy!
#aws #serverless
theburningmonk.com
AWS Lambda —3 pro tips for working with Kinesis streams
Learn to build production-ready serverless applications on AWS
An article about what qualities should one have to be a success part of a platform team. More precisely, which qualities should one have in that particular company.
It's a bit annoying, because this is yet another story about all-in-one engineer. However, it's even more annoying because this is particularly true.
So, a good platform engineer should:
- Handle the product management
- Be good in tech and be able to debug non-trivial things
- Sale their ideas to the rest of organization
- Build good UX
- Write decent documentation
Also, this article makes an interesting point about a purpose of the platform team. According to it, the platform team should be a "knowledge bus" inside the company. So, an organization can make sure that the knowledge it generates is not only preserved, but also shared inside the company in sustainable way.
#culture
It's a bit annoying, because this is yet another story about all-in-one engineer. However, it's even more annoying because this is particularly true.
So, a good platform engineer should:
- Handle the product management
- Be good in tech and be able to debug non-trivial things
- Sale their ideas to the rest of organization
- Build good UX
- Write decent documentation
Also, this article makes an interesting point about a purpose of the platform team. According to it, the platform team should be a "knowledge bus" inside the company. So, an organization can make sure that the knowledge it generates is not only preserved, but also shared inside the company in sustainable way.
#culture
Medium
The Platform Engineer
What does it take to run a successful platform team and what roles do platform engineers need to play?
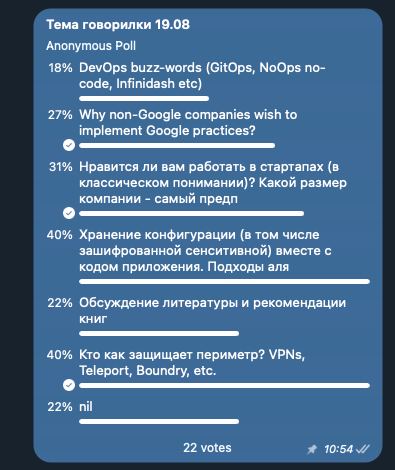
Approximately twice a month we organize a voice chat here in CatOps.
Today is one of such occasions. And today we are going to talk about secret management and how to defent the perimiter, and probably some other toipics as well.
You can join the voice chat via this link:
https://t.iss.one/catops_chat?voicechat
Voice chat is in Ukrainian/Russian
Today is one of such occasions. And today we are going to talk about secret management and how to defent the perimiter, and probably some other toipics as well.
You can join the voice chat via this link:
https://t.iss.one/catops_chat?voicechat
Voice chat is in Ukrainian/Russian
{kind=link}