
Очень познавательный пост о том, как легко ваши персональные данные продают и покупают в интернете. Актуально и для России, и для Украины.
Пожалуй, ничто не сравнится с объемами данных, которые известны о нас различным государственным ведомствам. Тысячи сотрудников имеют к ним доступ, результаты чего обильно просматриваются на форумах. С одной стороны, вырисовывается четкая картина, какой информацией о нас обладают эти ведомства и с какой легкостью сотрудники могут собрать полное досье на любого человека. С другой стороны еще более живописная картина маслом: любой мошенник может собрать точно такое же досье.
Наибольшей популярностью пользуется услуга выгрузки из баз Магистраль, Сирена, Граница, Мигрант, Кронос, Спарк, Поток, комплексных баз ИБДР-ИБДФ. Пробивается все, до чего дойдет фантазия, даже ПФР.
Отдельная категория «услуг» посвящена детализации банковских счетов и движению средств на них. Часть специализируется по счетам физических лиц. Но еще больше — по юридическим лицам. Здесь мошенничество переходит в изощренные формы промышленного шпионажа и откровенного криминала. Скриншоты выкладывать не буду, так как криминальный «комплекс услуг» выходит сильно за рамки утечек данных.
Пожалуй, ничто не сравнится с объемами данных, которые известны о нас различным государственным ведомствам. Тысячи сотрудников имеют к ним доступ, результаты чего обильно просматриваются на форумах. С одной стороны, вырисовывается четкая картина, какой информацией о нас обладают эти ведомства и с какой легкостью сотрудники могут собрать полное досье на любого человека. С другой стороны еще более живописная картина маслом: любой мошенник может собрать точно такое же досье.
Наибольшей популярностью пользуется услуга выгрузки из баз Магистраль, Сирена, Граница, Мигрант, Кронос, Спарк, Поток, комплексных баз ИБДР-ИБДФ. Пробивается все, до чего дойдет фантазия, даже ПФР.
Отдельная категория «услуг» посвящена детализации банковских счетов и движению средств на них. Часть специализируется по счетам физических лиц. Но еще больше — по юридическим лицам. Здесь мошенничество переходит в изощренные формы промышленного шпионажа и откровенного криминала. Скриншоты выкладывать не буду, так как криминальный «комплекс услуг» выходит сильно за рамки утечек данных.
Хабр
Наши с вами персональные данные ничего не стоят
Я — Владимир Адошев, я путешественник, блогер и урбанист из Германии. В последние годы я также начал заниматься информационной безопасностью. Сегодня я хочу затр...
Прообраз браузерных вкладок -- средневековое устройство для одновременной работы с документами (фото сделано в библиотеке Мехико)
https://twitter.com/designinspace/status/1081049819567804416
https://twitter.com/designinspace/status/1081049819567804416
Forwarded from я просто текст
В 2012 году, вскоре после смерти отца, 33-летний житель административной столицы ЮАР Претории Джон, работающий юристом, переехал в дом своей матери Анны. Через год на пороге стали регулярно появляться странные люди.
Один из них представился частным детективом и заявил, что в доме Джона и его матери находится похищенная девочка; он отказался уходить, пока хозяева не разрешили ему обыскать все комнаты. Другие приходили в сопровождении полицейских и требовали вернуть похищенные у них телефоны и компьютеры; однажды отряд спецназа вломился в дом в поисках двух айпадов, когда 70-летняя Анна ужинала в гостиной. Приходили даже подростки, которые искали людей, оставлявших оскорбительные комментарии в их инстаграмах. Бывало, что незнакомцы стучали в дверь по семь раз за месяц.
Дальше — мощнейшая история про парадоксы цифрового тысячелетия, в которой оказывается замешанным малоизвестное американское разведывательное агентство. То есть буквально сюжет про то, как люди ткнули пальцем в карту — и испортили другим жизнь.
Оригинал: https://gizmodo.com/how-cartographers-for-the-u-s-military-inadvertently-c-1830758394
Мой пересказ в «Медузе»: https://meduza.io/feature/2019/01/12/politsiya-vse-vremya-prihodila-v-dom-yuzhnoafrikanskogo-yurista-v-poiskah-kradenogo-on-vyyasnil-vinovaty-ego-ip-adres-i-amerikanskaya-razvedka
Один из них представился частным детективом и заявил, что в доме Джона и его матери находится похищенная девочка; он отказался уходить, пока хозяева не разрешили ему обыскать все комнаты. Другие приходили в сопровождении полицейских и требовали вернуть похищенные у них телефоны и компьютеры; однажды отряд спецназа вломился в дом в поисках двух айпадов, когда 70-летняя Анна ужинала в гостиной. Приходили даже подростки, которые искали людей, оставлявших оскорбительные комментарии в их инстаграмах. Бывало, что незнакомцы стучали в дверь по семь раз за месяц.
Дальше — мощнейшая история про парадоксы цифрового тысячелетия, в которой оказывается замешанным малоизвестное американское разведывательное агентство. То есть буквально сюжет про то, как люди ткнули пальцем в карту — и испортили другим жизнь.
Оригинал: https://gizmodo.com/how-cartographers-for-the-u-s-military-inadvertently-c-1830758394
Мой пересказ в «Медузе»: https://meduza.io/feature/2019/01/12/politsiya-vse-vremya-prihodila-v-dom-yuzhnoafrikanskogo-yurista-v-poiskah-kradenogo-on-vyyasnil-vinovaty-ego-ip-adres-i-amerikanskaya-razvedka
Gizmodo
How Cartographers for the U.S. Military Inadvertently Created a House of Horrors in South Africa
The visitors started coming in 2013. The first one who came and refused to leave until he was let inside was a private investigator named Roderick. He was looking for an abducted girl, and he was convinced she was in the house.
Forwarded from Golden Chihuahua
да, это настоящий протез-щупальце из 26 суставов, разработанный компанией Alternative Limb и ученой Келли Нокс
потрясающе красивая вещь, но потом не удивляйтесь когда начнут появляться супер-злодеи с этими штуками
https://www.youtube.com/watch?v=jBSqG5DTeqU
потрясающе красивая вещь, но потом не удивляйтесь когда начнут появляться супер-злодеи с этими штуками
https://www.youtube.com/watch?v=jBSqG5DTeqU
YouTube
The Vine Arm
This prosthetic limb was created for the model and body confidence advocate Kelly Knox by the Alternative Limb Project. The arm was designed by Sophie de Oliveira Barata, with mechanical engineering by Dani Clode, 3-D modelling by Jason Taylor and electronic…
This media is not supported in your browser
VIEW IN TELEGRAM
Как вам концепт гибкого смартфона от Xiaomi? Выглядит впечатляюще, но станет ли модель массовой, сколько будет стоить и есть ли вообще спрос на такие устройства, пока непонятно.
Forwarded from Бро
Мир глазами США: занимательная инфографика показывает, о каких странах американские газеты писали чаще всего, начиная с 1900 года и по сегодня.
С флагами не очень корректно получилось — вместо флага СССР на графике флаг России, вместо флага нацистской Германии — флаг современной ФРГ. Но в принципе картина получается очень наглядная, посмотрите сами.
С флагами не очень корректно получилось — вместо флага СССР на графике флаг России, вместо флага нацистской Германии — флаг современной ФРГ. Но в принципе картина получается очень наглядная, посмотрите сами.
{kind=link}
Журналисты MIT Technology Review проанализировали, как менялись ключевые слова научных публикаций про ИИ за последние 25 лет. В выборку попали >16K статей с сайта arXiv (точнее, их абстракты — короткие резюме). Выводы:
1. Популярная в 80-х парадигма экспертных систем не оправдала ожиданий: there were simply too many rules that needed to be encoded for a system to do anything useful. В начале 2000-х эту парадигму сменило машинное обучение (графики 2, 3).
2. Нейросети стали доминирующим направлением в исследованиях ИИ лишь в середине 2010-х. До этого внимание исследователей разделяли байесовские сети, цепи Маркова, эволюционные алгоритмы и метод опорных векторов (график 4).
3. Самая горячая тема в машинном обучении сейчас — reinforcement learning, обучение с подкреплением (график 5).
4. История исследований ИИ циклична: каждое десятилетие какое-то из направлений "ловит волну" и потом точно так же сменяется другим. Профессор Педро Домингос, автор бестселлера о машинном обучении "Верховный алгоритм", считает, что эра глубокого обучения подходит к концу. Что станет the next big thing в исследованиях искусственного интеллекта? Узнаем после 2020 года.
Что ещё почитать в канале по теме:
— The biggest AI stories of 2017
— Достижения в глубоком обучении за 2017 год
— Как DeepMind создали суперпрограмму для игры в го и шахматы
— Моделирование движения человека с помощью обучения с подкреплением
— Как обучение с подкреплением позволяет компьютерам находить парадоксальные решения задач
— Фрагменты из книги "Верховный алгоритм" — о цифровом двойнике-помощнике и генетических алгоритмах
1. Популярная в 80-х парадигма экспертных систем не оправдала ожиданий: there were simply too many rules that needed to be encoded for a system to do anything useful. В начале 2000-х эту парадигму сменило машинное обучение (графики 2, 3).
2. Нейросети стали доминирующим направлением в исследованиях ИИ лишь в середине 2010-х. До этого внимание исследователей разделяли байесовские сети, цепи Маркова, эволюционные алгоритмы и метод опорных векторов (график 4).
3. Самая горячая тема в машинном обучении сейчас — reinforcement learning, обучение с подкреплением (график 5).
4. История исследований ИИ циклична: каждое десятилетие какое-то из направлений "ловит волну" и потом точно так же сменяется другим. Профессор Педро Домингос, автор бестселлера о машинном обучении "Верховный алгоритм", считает, что эра глубокого обучения подходит к концу. Что станет the next big thing в исследованиях искусственного интеллекта? Узнаем после 2020 года.
Что ещё почитать в канале по теме:
— The biggest AI stories of 2017
— Достижения в глубоком обучении за 2017 год
— Как DeepMind создали суперпрограмму для игры в го и шахматы
— Моделирование движения человека с помощью обучения с подкреплением
— Как обучение с подкреплением позволяет компьютерам находить парадоксальные решения задач
— Фрагменты из книги "Верховный алгоритм" — о цифровом двойнике-помощнике и генетических алгоритмах
MIT Technology Review
We analyzed 16,625 papers to figure out where AI is headed next
Our study of 25 years of artificial-intelligence research suggests the era of deep learning may come to an end.
Половина населения Уганды — люди моложе 15 лет.
Сделав заголовки своих электронных писем короткими, отрицательными, удивляющими и содержащими имена брендов, аналитическая компания CB Insights заработала за год на $625 000 больше.
Экипажи самолётов подвержены большему воздействию радиации, чем сотрудники атомных электростанций.
Дорогие плацебо работают лучше, чем дешёвые.
Имитация иглоукалывания имеет такой же эффект, как и настоящее иглоукалывание.
54% китайцев, рожденных после 1995 года, назвали в качестве работы мечты "лидера мнений".
Отличная подборка занимательных фактов. Enjoy.
Сделав заголовки своих электронных писем короткими, отрицательными, удивляющими и содержащими имена брендов, аналитическая компания CB Insights заработала за год на $625 000 больше.
Экипажи самолётов подвержены большему воздействию радиации, чем сотрудники атомных электростанций.
Дорогие плацебо работают лучше, чем дешёвые.
Имитация иглоукалывания имеет такой же эффект, как и настоящее иглоукалывание.
54% китайцев, рожденных после 1995 года, назвали в качестве работы мечты "лидера мнений".
Отличная подборка занимательных фактов. Enjoy.
Medium
52 things I learned in 2018
This year I edited another book, worked on fascinating projects at Fluxx, and learned learnings.
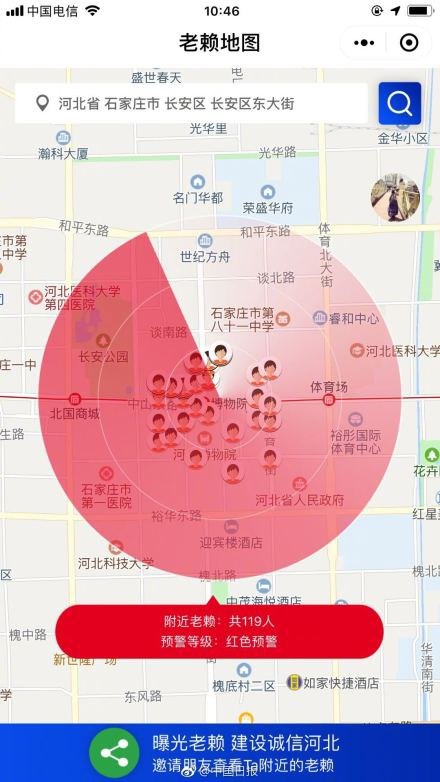
Очередная стрёмная новость из Китая.
Суд одной из северных провинций выпустил приложение, которое показывает на карте локацию должников. Приложение работает внутри мессенджера WeChat. Что именно оно показывает — точную геолокацию должников или их зарегистрированный адрес, не сообщается. Как и то, сколько и кому надо задолжать, чтобы попасть в черный список этого приложения.
Задумка такова: если вы видите, что кто-то из должников живёт не по средствам — сообщайте властям. Стук-стук!
— Подробнее о китайской системе социальных кредитов
— Как китайские перекрестки автоматически клеймят позором нарушителей
Суд одной из северных провинций выпустил приложение, которое показывает на карте локацию должников. Приложение работает внутри мессенджера WeChat. Что именно оно показывает — точную геолокацию должников или их зарегистрированный адрес, не сообщается. Как и то, сколько и кому надо задолжать, чтобы попасть в черный список этого приложения.
Задумка такова: если вы видите, что кто-то из должников живёт не по средствам — сообщайте властям. Стук-стук!
— Подробнее о китайской системе социальных кредитов
— Как китайские перекрестки автоматически клеймят позором нарушителей
{kind=link}
Forwarded from The Technodeterminist Papers
Нейросеть Google под названием AlphaStar обыграла двух профессиональных игроков в StarCraft II с общим счетом 10-1. И это новость совсем не про видеоигры.
Как известно, после того, как AlphaGo обыграла Ли Седоля в 2016 году в го, люди больше не могут конкурировать с машинами в играх с полной информацией, где все участники игры знают все, что происходит в матче. Эпоха была открыта в 1998 году Каспаровым и DeepBlue и вот сейчас подошла к концу.
Следущая проблема для машины - игры с неполной информацией, которых гораздо больше, и которые сильно приближены к реальной жизни. В реальной жизни мы практически ничем больше не занимаемся, только принимаем решения в условиях дефицита информации.
Так что как только игры машин выйдут за пределы полной информации, тут и начнется самое интересное. Утверждалось, что следующий фронтир для нейросетей покер, но некоторые видеоигры, похоже, даже более интересны.
StarCraft в частности давно стала киберспортивной дисциплиной, поскольку в ней нет очевидной выигрышной стратегией, ценится умение быстро принимать тактические решения и адаптироваться к действиям противника. И вот все это теперь умеет Google.
Плюс видеоигр для машинного обучения в том, что ИИ может учится очень быстро, разыгрывая и анализируя очень много партий, не завися от медленного аналогового мира и человеческих решений. Примерно по той же логике беспилотные автомобили могут тренировать навыки дорожного движения внутри видеоигры GTA - не очень точно, но очень быстро.
Машина должна в сжатые сроки научиться тому, чему мы научились в результате миллионов лет эволюции: адаптироваться к принятию решений в условиях неполноты информации и меняющейся ситуации.
Из истории про AlphaStar не очень понятно, насколько ограничено было поле зрение программы во время игры - человеку, играющему в StarCraft нужно управлять камерой, чтобы видеть разные части игрового поля, машина может обойтись без этого. В любом случае, программа совершала меньше действий в минуту, чем оба профессиональных игрока-человека. Интересен кейс о том, как одному из игроков удалось выиграть одну партию.
Но самое важное в этой истории в том, что игроки описывают стратегию AlphaStar в качестве "инопланетной": программа играет не так, как играют люди, и не так, как они ожидали от алгоритмов.
Это означает, что нейросети, шагнувшие в мир с неполнотой информации, дадут нам совершенно иные способы решения проблем, не похожие на те, которые предопределены эволюцией наших когнитивных систем.
Вот к чему нужно готовиться. Aliens-studies только начинаются, причем чужих воспитаем мы сами.
Как известно, после того, как AlphaGo обыграла Ли Седоля в 2016 году в го, люди больше не могут конкурировать с машинами в играх с полной информацией, где все участники игры знают все, что происходит в матче. Эпоха была открыта в 1998 году Каспаровым и DeepBlue и вот сейчас подошла к концу.
Следущая проблема для машины - игры с неполной информацией, которых гораздо больше, и которые сильно приближены к реальной жизни. В реальной жизни мы практически ничем больше не занимаемся, только принимаем решения в условиях дефицита информации.
Так что как только игры машин выйдут за пределы полной информации, тут и начнется самое интересное. Утверждалось, что следующий фронтир для нейросетей покер, но некоторые видеоигры, похоже, даже более интересны.
StarCraft в частности давно стала киберспортивной дисциплиной, поскольку в ней нет очевидной выигрышной стратегией, ценится умение быстро принимать тактические решения и адаптироваться к действиям противника. И вот все это теперь умеет Google.
Плюс видеоигр для машинного обучения в том, что ИИ может учится очень быстро, разыгрывая и анализируя очень много партий, не завися от медленного аналогового мира и человеческих решений. Примерно по той же логике беспилотные автомобили могут тренировать навыки дорожного движения внутри видеоигры GTA - не очень точно, но очень быстро.
Машина должна в сжатые сроки научиться тому, чему мы научились в результате миллионов лет эволюции: адаптироваться к принятию решений в условиях неполноты информации и меняющейся ситуации.
Из истории про AlphaStar не очень понятно, насколько ограничено было поле зрение программы во время игры - человеку, играющему в StarCraft нужно управлять камерой, чтобы видеть разные части игрового поля, машина может обойтись без этого. В любом случае, программа совершала меньше действий в минуту, чем оба профессиональных игрока-человека. Интересен кейс о том, как одному из игроков удалось выиграть одну партию.
Но самое важное в этой истории в том, что игроки описывают стратегию AlphaStar в качестве "инопланетной": программа играет не так, как играют люди, и не так, как они ожидали от алгоритмов.
Это означает, что нейросети, шагнувшие в мир с неполнотой информации, дадут нам совершенно иные способы решения проблем, не похожие на те, которые предопределены эволюцией наших когнитивных систем.
Вот к чему нужно готовиться. Aliens-studies только начинаются, причем чужих воспитаем мы сами.
Forwarded from БлоGнот
Космически обжаренный кофе — это не эпитет, а точная характеристика продукта, который планируют получить два предпринимателя — Андерс Кавалини (Anders Cavallini) и Хатем Альхафаджи (Hatem Alkhafaji). Если точнее — они планируют запуск специального космического корабля — если точнее, то суборбитальной ракеты, — который будет содержать в себе 300 кг кофейных зерен.
Оказывается, все существующие технологии обжарки зерен авторы проекта считают неидеальными — зерна постоянно находятся в неравномерном контакте с горячей поверхностью роастера (машины для обжарки) и, следовательно, обжариваются не равномерно. Поэтому идея проста — запустить ракету, которая после выхода на высоту 180-200 км над поверхностью Земли отстрелит модуль с зернами, он, не выйдя на орбиту, начнет падать на Землю. Примерно на высоте 120 км модуль войдет в плотные слои атмосферы и начнет нагреваться, а зерна внутри него, соответственно, обжариваться. При этом, поскольку содержимое будет испытывать состояние невесомости, нагрев зерен будет равномерным, что и требуется авторам. Они рассчитали, что процесс обжарки продлится около 20 минут при температуре около 200 градусов Цельсия, после чего она начнет падать из-за падения скорости аппарата, а на высоте 40 км капсула выпустит парашют и будет медленно спускаться.
Некое благородное безумство этой идеи, конечно, впечатляет, но авторы уже планируют, что они презентуют «космический» кофе в следующем году в Дубай, где размещена их компания Space Roasters. Очень интересно будет посмотреть на цену чашки или готовых зерен в рознице — ведь как-то окупить эту затею надо. Пока что они планируют привлечение капитала и скоро стартуют pre-sale (очень хочется надеяться, что не ICO).
А вот что они будут делать, если зерна окажутся пережаренными?
https://roasters.space/
Оказывается, все существующие технологии обжарки зерен авторы проекта считают неидеальными — зерна постоянно находятся в неравномерном контакте с горячей поверхностью роастера (машины для обжарки) и, следовательно, обжариваются не равномерно. Поэтому идея проста — запустить ракету, которая после выхода на высоту 180-200 км над поверхностью Земли отстрелит модуль с зернами, он, не выйдя на орбиту, начнет падать на Землю. Примерно на высоте 120 км модуль войдет в плотные слои атмосферы и начнет нагреваться, а зерна внутри него, соответственно, обжариваться. При этом, поскольку содержимое будет испытывать состояние невесомости, нагрев зерен будет равномерным, что и требуется авторам. Они рассчитали, что процесс обжарки продлится около 20 минут при температуре около 200 градусов Цельсия, после чего она начнет падать из-за падения скорости аппарата, а на высоте 40 км капсула выпустит парашют и будет медленно спускаться.
Некое благородное безумство этой идеи, конечно, впечатляет, но авторы уже планируют, что они презентуют «космический» кофе в следующем году в Дубай, где размещена их компания Space Roasters. Очень интересно будет посмотреть на цену чашки или готовых зерен в рознице — ведь как-то окупить эту затею надо. Пока что они планируют привлечение капитала и скоро стартуют pre-sale (очень хочется надеяться, что не ICO).
А вот что они будут делать, если зерна окажутся пережаренными?
https://roasters.space/
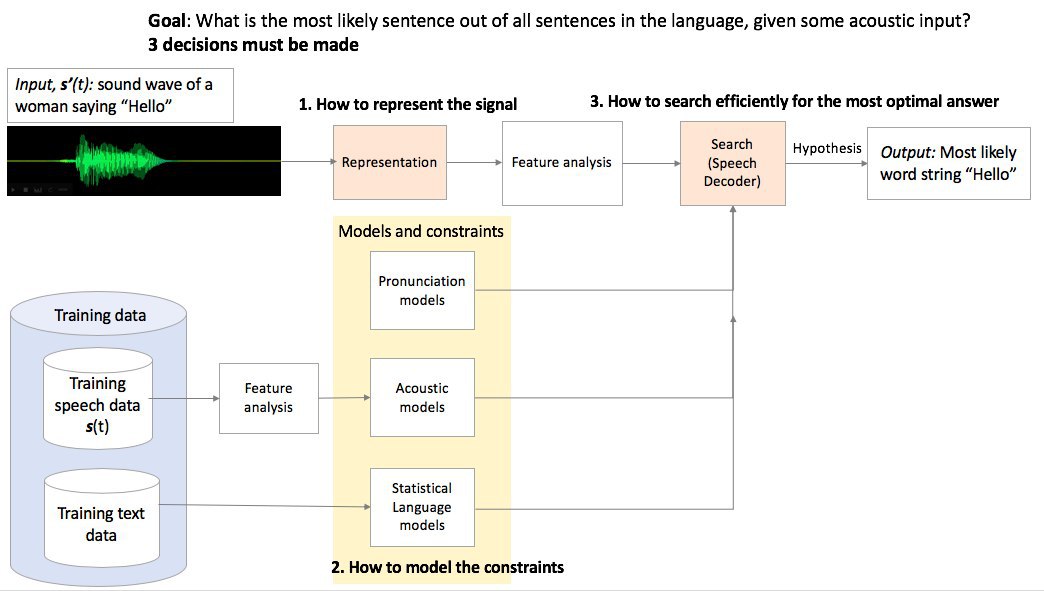
Распознавание речи — простой и естественный для человека процесс. Но как передать этот навык компьютерам? Как и распознавание визуальных образов, этот интуитивный процесс невозможно представить в виде простого компьютерного алгоритма — "если X, то Y".
Чтобы создать машинную систему распознавания речи, необходимо собрать воедино следующие компоненты:
— Цифровое преобразование входящих звуковых колебаний
— Детекция нужной звуковой дорожки и отсечение шумов (т.н. проблема "коктейльной вечеринки", когда все говорят одновременно)
— Массив данных для тренировки алгоритмов распознавания, т.е. огромное количество аудиофрагментов речи с соответствующими транскрипциями
— Акустическая модель, узнающая в потоке речи отдельные фонемы
— Модель произношения, связывающая фонемы в отдельные слова
— Языковая модель, связывающая слова в фразы и предложения
— Декодер: алгоритмы, анализирующие предположения акустической и языковой модели; результат их работы — текст с наиболее вероятной транскрипцией входящего звукового потока.
Первая часть текста о том, почему распознавание речи — это непросто. Прочитал, жду вторую.
Что ещё почитать в канале по теме:
— Смогут ли машины распознавать речь так же, как люди? Обзор от Atlantic
— Разговорные интерфейсы — одна из самых многообещающих технологий ближайших лет. Пример Китая
— Cпециалисты по ИИ, UX и продуктовому дизайну рассуждают о голосовых помощниках в беспроводных гарнитурах. Да, как фильме "Она".
— Аналитик Бенедикт Эванс сомневается в будущем голосовых помощников
— Разные казусы с голосовыми помощниками: они становятся объектами харрасмента, учат детей плохим манерам, свидетельствуют против своих владельцев, отправляют записи их разговоров случайным людям и всё время подслушивают 👂🏻
Чтобы создать машинную систему распознавания речи, необходимо собрать воедино следующие компоненты:
— Цифровое преобразование входящих звуковых колебаний
— Детекция нужной звуковой дорожки и отсечение шумов (т.н. проблема "коктейльной вечеринки", когда все говорят одновременно)
— Массив данных для тренировки алгоритмов распознавания, т.е. огромное количество аудиофрагментов речи с соответствующими транскрипциями
— Акустическая модель, узнающая в потоке речи отдельные фонемы
— Модель произношения, связывающая фонемы в отдельные слова
— Языковая модель, связывающая слова в фразы и предложения
— Декодер: алгоритмы, анализирующие предположения акустической и языковой модели; результат их работы — текст с наиболее вероятной транскрипцией входящего звукового потока.
Первая часть текста о том, почему распознавание речи — это непросто. Прочитал, жду вторую.
Что ещё почитать в канале по теме:
— Смогут ли машины распознавать речь так же, как люди? Обзор от Atlantic
— Разговорные интерфейсы — одна из самых многообещающих технологий ближайших лет. Пример Китая
— Cпециалисты по ИИ, UX и продуктовому дизайну рассуждают о голосовых помощниках в беспроводных гарнитурах. Да, как фильме "Она".
— Аналитик Бенедикт Эванс сомневается в будущем голосовых помощников
— Разные казусы с голосовыми помощниками: они становятся объектами харрасмента, учат детей плохим манерам, свидетельствуют против своих владельцев, отправляют записи их разговоров случайным людям и всё время подслушивают 👂🏻
{kind=link}
Раньше производители телевизоров зарабатывали, просто продавая свои устройства. Теперь бизнес-модель изменилась: вы можете купить "умный телевизор" очень дёшево, но его производитель потом заработает намного больше на том, что продаст доступ к вашему устройству сервисам вроде Hulu, Netflix, CBS и другим дилерам контента.
Современный телевизор — это компьютер, который вам не принадлежит. Вы не можете изменять или удалять его программное обеспечение. Журналист Atlantic пожаловался на баг: на его "умном" телевизоре Samsung начало произвольно запускаться приложение новостного канала CBS. Оказалось, что у Samsung контракт с CBS, приложение нельзя удалить (и это прописано в правилах сервиса), а жалобы на баги разработчик не принимает. Непонятно даже, кто разработчик — CBS или аутсорсинговая компания. Недовольные пользователи воюют с техподдержкой на форумах Samsung, журналист смирился и просто перезапускает телевизор, пока глюк не исчезнет. Ну а я раздумываю — нужно ли мне такое устройство дома.
Современный телевизор — это компьютер, который вам не принадлежит. Вы не можете изменять или удалять его программное обеспечение. Журналист Atlantic пожаловался на баг: на его "умном" телевизоре Samsung начало произвольно запускаться приложение новостного канала CBS. Оказалось, что у Samsung контракт с CBS, приложение нельзя удалить (и это прописано в правилах сервиса), а жалобы на баги разработчик не принимает. Непонятно даже, кто разработчик — CBS или аутсорсинговая компания. Недовольные пользователи воюют с техподдержкой на форумах Samsung, журналист смирился и просто перезапускает телевизор, пока глюк не исчезнет. Ну а я раздумываю — нужно ли мне такое устройство дома.
The Atlantic
Your TV Is Now a Computer, but Not in a Good Way
You don’t really own it, and it breaks in unpredictable ways.
Forwarded from 🎧 FunCubator - технологии развлечений (Mikhail Kalashnikov)
Инвесторы читают презентации стартапов особенным образом. Во-первых, внимательно отделяют то, что уже сделано, от предположений и фантазий. Во-вторых, все настолько привыкли к тому, как стартапы приукрашивают формулировки, что за каждой фразой видят двойное дно.
Конечно, иногда фразы ниже значат именно то, что значат. Но лучше их избегать, чтобы не вызывать неправильных ассоциаций.
Описание
У нас нет конкурентов – мы не умеем гуглить.
Делаем платформу – мы сами не знаем, что из нашего функционала людям нужно.
На основе ИИ – кто-то в команде, возможно, умеет писать скрипты на python.
Закрытая бета – ничего нельзя потрогать руками.
Слайд "Рынок" из отчета известной фирмы с растущими миллиардами – у нас нет своих инсайтов о рынке.
Таблица конкурентного сравнения, где у конкурентов мало галочек, а у стартапа много – мы делаем много лишнего, что не приносит денег.
Метрики
100К скачиваний – суммарно за три года, с нулевым ретеншном.
График роста скачиваний – с тем же успехом можно было вывести график "число месяцев работы проекта", видимо, больше ничего не растет.
Топ-10 в Apple Store – были на 10 месте один раз в позапрошлом феврале.
Топ-10 в 5 странах – Киргизия, Таджикистан, Литва, Молдова, атолл Палау.
Ретеншн до 30% – было 30% в когорте "друзья основателей" размером в 10 человек.
Топ-8 по любому показателю – ровно 8-е место.
LTV платящих пользователей – у нас плохая конверсия в платящих.
Рейтинг 5 в App Store – у нас пока всего 5 оценок.
Команда
15 лет опыта в бизнесе – занимался чем-то совсем не по тематике стартапа.
Экс-Google – работал 6 месяцев младшим аккаунтом.
Свое агентство/студия – будет и дальше отвлекаться от стартапа на заказы.
COO – этот фаундер не придумал, чем будет заниматься.
Планы
Готовы отдать до 10% – мы сами не знаем, сколько стоим, но чувствуем, что много.
Выход на точку безубыточности через 4 года – если в финмодель заложить бесконечный рост среднего чека и конверсии, то вроде бы когда-то это способно окупиться.
Нужны деньги на проверку гипотез – пока ничего нужного людям не сделано.
Ищем умные деньги – хотим, чтобы инвестор научил нас зарабатывать.
Ищем тематического инвестора – не можем объяснить людям, где тут деньги.
Есть вербальные коммиты – кто-то на фуршете однажды сказал "интересно".
Планируем партнерство с Microsoft – у всех есть знакомый в Microsoft.
Конечно, иногда фразы ниже значат именно то, что значат. Но лучше их избегать, чтобы не вызывать неправильных ассоциаций.
Описание
У нас нет конкурентов – мы не умеем гуглить.
Делаем платформу – мы сами не знаем, что из нашего функционала людям нужно.
На основе ИИ – кто-то в команде, возможно, умеет писать скрипты на python.
Закрытая бета – ничего нельзя потрогать руками.
Слайд "Рынок" из отчета известной фирмы с растущими миллиардами – у нас нет своих инсайтов о рынке.
Таблица конкурентного сравнения, где у конкурентов мало галочек, а у стартапа много – мы делаем много лишнего, что не приносит денег.
Метрики
100К скачиваний – суммарно за три года, с нулевым ретеншном.
График роста скачиваний – с тем же успехом можно было вывести график "число месяцев работы проекта", видимо, больше ничего не растет.
Топ-10 в Apple Store – были на 10 месте один раз в позапрошлом феврале.
Топ-10 в 5 странах – Киргизия, Таджикистан, Литва, Молдова, атолл Палау.
Ретеншн до 30% – было 30% в когорте "друзья основателей" размером в 10 человек.
Топ-8 по любому показателю – ровно 8-е место.
LTV платящих пользователей – у нас плохая конверсия в платящих.
Рейтинг 5 в App Store – у нас пока всего 5 оценок.
Команда
15 лет опыта в бизнесе – занимался чем-то совсем не по тематике стартапа.
Экс-Google – работал 6 месяцев младшим аккаунтом.
Свое агентство/студия – будет и дальше отвлекаться от стартапа на заказы.
COO – этот фаундер не придумал, чем будет заниматься.
Планы
Готовы отдать до 10% – мы сами не знаем, сколько стоим, но чувствуем, что много.
Выход на точку безубыточности через 4 года – если в финмодель заложить бесконечный рост среднего чека и конверсии, то вроде бы когда-то это способно окупиться.
Нужны деньги на проверку гипотез – пока ничего нужного людям не сделано.
Ищем умные деньги – хотим, чтобы инвестор научил нас зарабатывать.
Ищем тематического инвестора – не можем объяснить людям, где тут деньги.
Есть вербальные коммиты – кто-то на фуршете однажды сказал "интересно".
Планируем партнерство с Microsoft – у всех есть знакомый в Microsoft.
Американская компания Family Tree DNA — один из самых популярных в мире производителей генетических тестов. База компании содержит информацию о ДНК более миллиона пользователей, преимущественно из США. И вот новость: теперь поиск по этой базе доступен сотрудникам ФБР. При расследовании тяжелых преступлений, таких как убийство или изнасилование, ФБР может использовать образцы ДНК с места преступления для поиска по базе Family Tree DNA. Причём не обязательно, чтобы преступник был клиентом компании — расследованию могут помочь даже дальние родственные связи. "Здравствуйте, миссис Джонс. Это агент ФБР Смит. У меня к вам несколько вопросов. Когда вы в последний раз видели своего двоюродного брата, проживающего в штате Кентукки?" — ну и далее в таком роде.
Пока это не массовая практика — если верить компании, случаев такого сотрудничества было не более десяти. Но пользователи, конечно, недовольны: предоставляя свой биоматериал компании, они не давали согласия на включение себя и своих родственников в биометрический поисковик спецслужб. С другой стороны, ничто не мешает расследователям воспользоваться генеалогическим поиском, купив услуги компании как обычный пользователь. Так что у руководства компании есть отмазка: мол, ФБРовцы получают не больше информации, чем все остальные. Ну а пользователям придётся смириться. Да и опросы показывают, что большинство ДНК-энтузиастов не возражают против такого использования их ДНК.
TLDR: Если вы серийный убийца, лучше не пользуйтесь генетическими тестами.
Пока это не массовая практика — если верить компании, случаев такого сотрудничества было не более десяти. Но пользователи, конечно, недовольны: предоставляя свой биоматериал компании, они не давали согласия на включение себя и своих родственников в биометрический поисковик спецслужб. С другой стороны, ничто не мешает расследователям воспользоваться генеалогическим поиском, купив услуги компании как обычный пользователь. Так что у руководства компании есть отмазка: мол, ФБРовцы получают не больше информации, чем все остальные. Ну а пользователям придётся смириться. Да и опросы показывают, что большинство ДНК-энтузиастов не возражают против такого использования их ДНК.
TLDR: Если вы серийный убийца, лучше не пользуйтесь генетическими тестами.
BuzzFeed News
One Of The Biggest At-Home DNA Testing Companies Is Working With The FBI
The move is sure to raise privacy concerns as law enforcement gains the ability to match DNA from crime scenes to a vast library of possible relatives.