
Диаграмма размаха: что и к чему
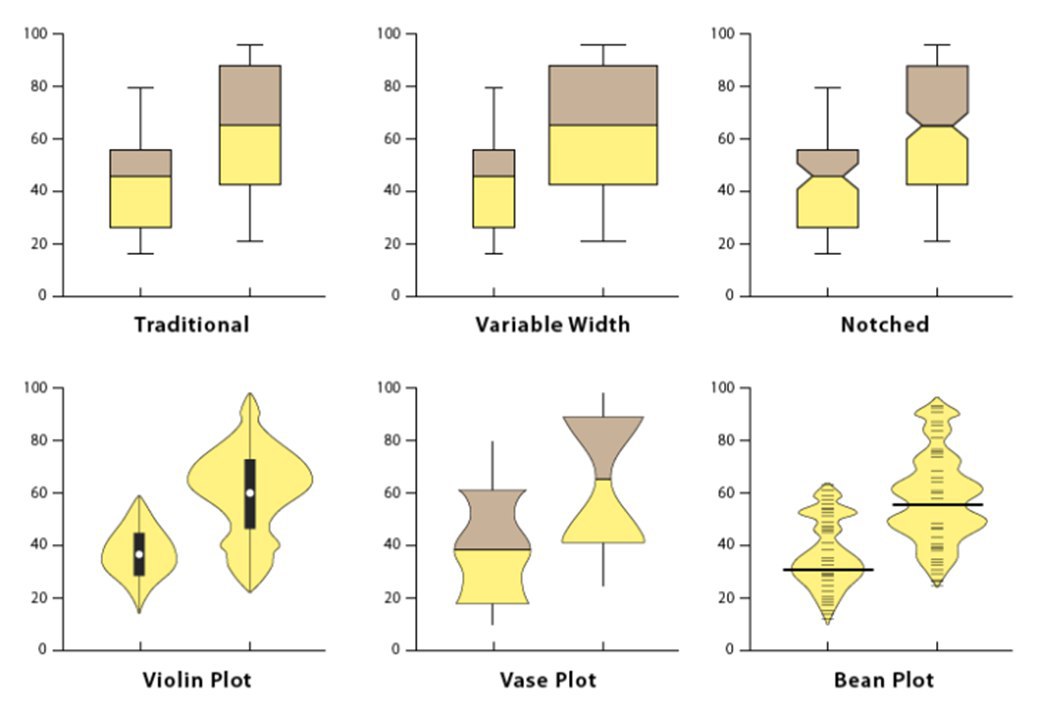
В этом посте я попробую разобрать такую распространенную диаграмму, как диаграмму размаха или ящик-с-усиками (box-and-whiskers). Она часто присутствует как стандартный инструмент визуализации во многих решениях. Но, как показывает моя практика, прочитать её могут далеко не все. Не говоря уже о использовании в отчетах.
В этом примере я сравниваю продолжительность жизни небольшого неслучайного набора животных. Есть два основополагающих подхода к формированию диаграммы размаха: базовый (техника Mary Spear) - и продвинутый (техника John Tukey)
Базовый подход
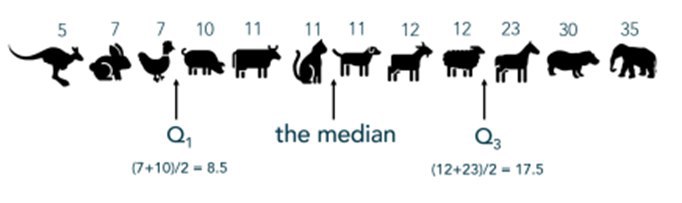
Шаг 1. Рассчитать квартили.
Квартили разбивают набор данных на 4 отрезка. Q1, медиану, Q3 (приблизительно) расположены на 25-м, 50-м и 75-м процентилях соответственно. Нахождение медианы требует нахождения среднего числа, когда значения упорядочены от наименьшего к наибольшему. При наличии четного количества точек данных два числа в середине усредняются.
Здесь медиана - средняя продолжительность жизни кошки и собаки.
ПРИМЕЧАНИЕ. Если при четном наборе значений два в середине будут разными, нижнее из двух значений будет в 50-м процентиле и не будет таким же показателем, как медиана.
Как только медиана будет найдена, найдите другие квартили таким же образом: среднее значение в нижнем наборе значений (Q1), затем среднее значение в верхнем наборе (Q3)
В этом посте я попробую разобрать такую распространенную диаграмму, как диаграмму размаха или ящик-с-усиками (box-and-whiskers). Она часто присутствует как стандартный инструмент визуализации во многих решениях. Но, как показывает моя практика, прочитать её могут далеко не все. Не говоря уже о использовании в отчетах.
В этом примере я сравниваю продолжительность жизни небольшого неслучайного набора животных. Есть два основополагающих подхода к формированию диаграммы размаха: базовый (техника Mary Spear) - и продвинутый (техника John Tukey)
Базовый подход
Шаг 1. Рассчитать квартили.
Квартили разбивают набор данных на 4 отрезка. Q1, медиану, Q3 (приблизительно) расположены на 25-м, 50-м и 75-м процентилях соответственно. Нахождение медианы требует нахождения среднего числа, когда значения упорядочены от наименьшего к наибольшему. При наличии четного количества точек данных два числа в середине усредняются.
Здесь медиана - средняя продолжительность жизни кошки и собаки.
ПРИМЕЧАНИЕ. Если при четном наборе значений два в середине будут разными, нижнее из двух значений будет в 50-м процентиле и не будет таким же показателем, как медиана.
Как только медиана будет найдена, найдите другие квартили таким же образом: среднее значение в нижнем наборе значений (Q1), затем среднее значение в верхнем наборе (Q3)
{kind=link}
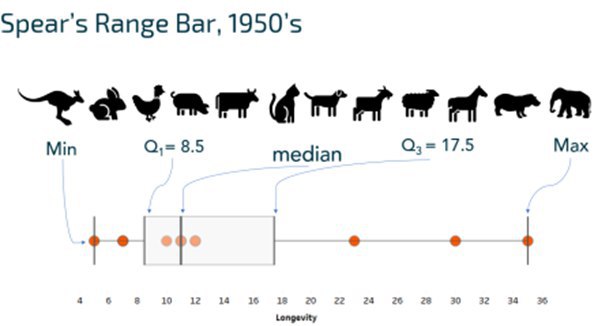
Шаг 2. Используя эти 5 точек сформировать диаграмму.
Весьма простой подход, который дает быстрый результат и, обычно, не требует больших затрат сил и времени. Именно такой подход мы часто видим, когда эту диаграмму используют не задумываясь, для красоты.
Весьма простой подход, который дает быстрый результат и, обычно, не требует больших затрат сил и времени. Именно такой подход мы часто видим, когда эту диаграмму используют не задумываясь, для красоты.
{kind=link}
Продвинутый подход.
Шаг 1. Определить IQR или межквартильный диапазон.
Межквартильный диапазон - это разница или разброс между третьим и первым квартилем, отражающий средние 50% набора данных. IQR строит «коробочную» часть коробочного графика.
Шаг 1. Определить IQR или межквартильный диапазон.
Межквартильный диапазон - это разница или разброс между третьим и первым квартилем, отражающий средние 50% набора данных. IQR строит «коробочную» часть коробочного графика.
{kind=link}
{kind=link}
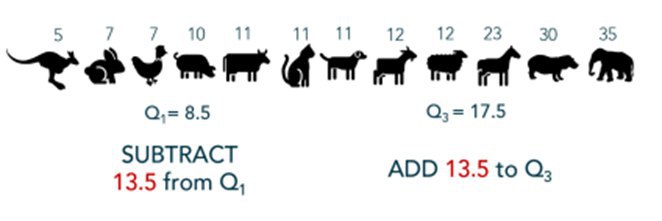
Шаг 3. Определяем границы усиков.
1,5 x IQR затем вычитается из нижнего квартиля и добавляется в верхний квартиль для определения границы.
1,5 x IQR затем вычитается из нижнего квартиля и добавляется в верхний квартиль для определения границы.
{kind=link}
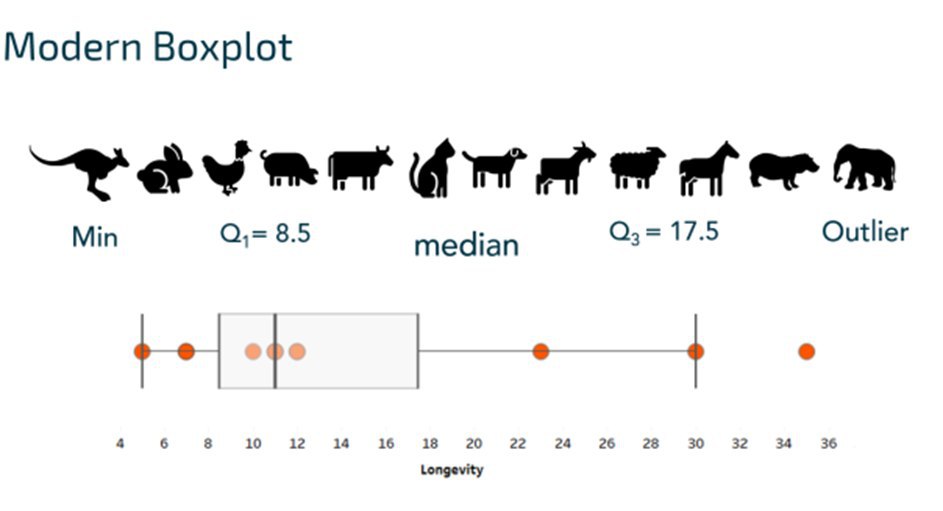
Шаг 4. Анализируем участников числового ряда, которые не попали в заданные границы.
Поскольку продолжительность жизни ни одного животного не ниже -5 лет, в этом конкретном наборе данных невозможно выделить участников набора, которые не вошли по нижней границе; однако, одно животное в этом наборе данных живет за пределами 31 года, а это выходит за границы диаграммы.
Поскольку продолжительность жизни ни одного животного не ниже -5 лет, в этом конкретном наборе данных невозможно выделить участников набора, которые не вошли по нижней границе; однако, одно животное в этом наборе данных живет за пределами 31 года, а это выходит за границы диаграммы.
{kind=link}
{kind=link}
Преимущества диаграммы размаха:
▪️ визуально суммирует вариации в больших наборах данных
▪️ показывает тех участников, которые не вошли в выборку
▪️ сравнивает несколько распределений
▪️ указывает симметрию и асимметрию в некоторой степени
▪️ можно быстро набросать
▪️ прикольное название (особенно вариант «коробка-с-усиками»)
▪️ визуально суммирует вариации в больших наборах данных
▪️ показывает тех участников, которые не вошли в выборку
▪️ сравнивает несколько распределений
▪️ указывает симметрию и асимметрию в некоторой степени
▪️ можно быстро набросать
▪️ прикольное название (особенно вариант «коробка-с-усиками»)
{kind=link}
Недостатки диаграммы:
▪️ скрывает мультимодальность и другие особенности распределений
▪️ запутывает некоторых пользователей
▪️ определение аутсайдеров очень жесткое
Ниже наглядный пример неудачного использования этой диаграммы
▪️ скрывает мультимодальность и другие особенности распределений
▪️ запутывает некоторых пользователей
▪️ определение аутсайдеров очень жесткое
Ниже наглядный пример неудачного использования этой диаграммы
{kind=link}
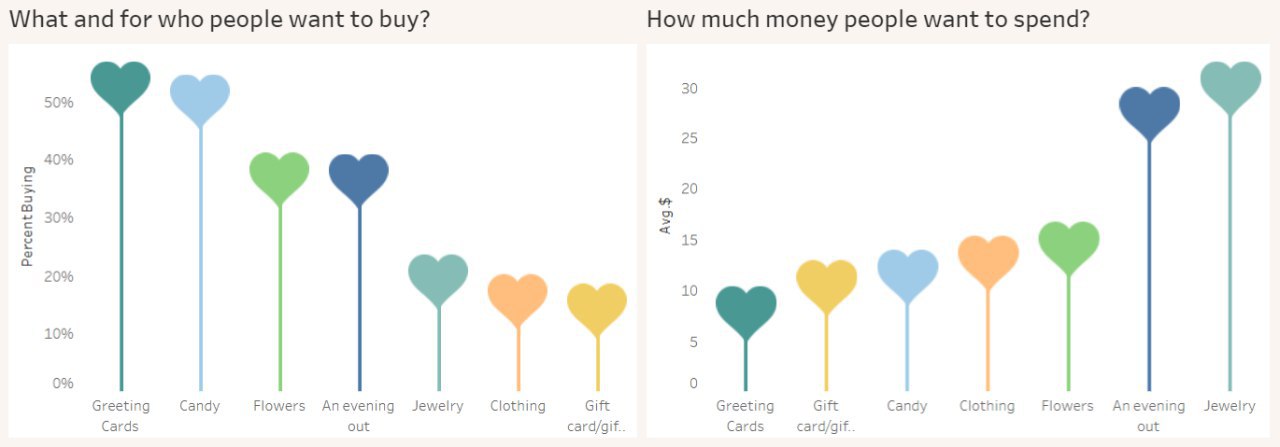
Праздничная аналитика
Так как наш бизнес-аналитик ушёл на встречу с другими бизнес-аналитиками, сегодня не будет классификаций диаграмм и источников данных. Вместо этого мы порадуем вас анализом расходов (правда, только американских) на подарки в честь того самого Дня.
Оказалось, что желания не всегда совпадают с реальностью. Хочется дарить валентинки, конфеты и цветы, а приходится ювелирные украшения.
Так как наш бизнес-аналитик ушёл на встречу с другими бизнес-аналитиками, сегодня не будет классификаций диаграмм и источников данных. Вместо этого мы порадуем вас анализом расходов (правда, только американских) на подарки в честь того самого Дня.
Оказалось, что желания не всегда совпадают с реальностью. Хочется дарить валентинки, конфеты и цветы, а приходится ювелирные украшения.
{kind=link}
Топ 5: #навыки, которыми необходимо овладеть в 2019
(в сфере #BigData, конечно же)
Вдумайтесь 🤔. У нас есть 33 буквы в алфавите и 10 основных цифр. Тем не менее, каким-то образом, ежедневно генерируеться более 2,5 квинтиллионнов байтов данных. Это, по сути, миллион в пятой степени.
Учитывая тот факт, что ценной информации теперь более чем достаточна для всех, сейчас идеальное время, чтобы точно узнать, как ее использовать. И чтобы помочь вам в этом, мы рассмотрим основные типы инструментов, которые вы можете использовать.
1️⃣ Data Visualization – Tableau, PowerBI, Qlik. – инструменты front-end, которыми легко пользоваться, и которые представляют информацию в простой и доступной форме.
2️⃣ Data Engineering – Python. Python особенно удобен, поскольку предоставляет множество библиотек для настройки необработанных данных. Он может взаимодействовать с такими источниками, как Hive, Cloudera Impala, списки MS SharePoint, файлы MS Excel, PostgreSQL, Teradata, MS SQL Server и различными текстовыми файлами, чтобы обеспечить агрегирование данных, изменение формы, разнородное вложение источников, а также автоматизацию.
3️⃣ Data Analytics – SQL. Также известный как язык структурированных запросов, это система, которая используется не только для разработки программного обеспечения, но и для управления данными для реляционных баз данных. Его функциональные возможности делают его исключительно эффективным при чтении, обработке и корректировке данных. Учитывая все вышесказанное, сильная сторона SQL заключается в его способности выполнять широкий спектр агрегаций на обширных наборах данных плюс многочисленные таблицы одновременно.
4️⃣ Big Data – HIVE. Xотя обширная база данных считается активом, так уж сложилось, что она также может стать серьезной проблемой, когда речь заходит об управлении. И именно поэтому они придумали такие инструменты для работы с большими данными, как Hive.
5️⃣ Advanced Analytics – SparkSQL. SparkSQL является чрезвычайно выдающимся инструментом, когда речь заходит о продвинутой аналитике. Разработанный для обработки структурированных и полуструктурированных данных, SparkSQL - это интерфейс spark, который не только служит механизмом распределенных SQL-запросов, но и облегчает абстрагирование сценариев в DataFrames.
(в сфере #BigData, конечно же)
Вдумайтесь 🤔. У нас есть 33 буквы в алфавите и 10 основных цифр. Тем не менее, каким-то образом, ежедневно генерируеться более 2,5 квинтиллионнов байтов данных. Это, по сути, миллион в пятой степени.
Учитывая тот факт, что ценной информации теперь более чем достаточна для всех, сейчас идеальное время, чтобы точно узнать, как ее использовать. И чтобы помочь вам в этом, мы рассмотрим основные типы инструментов, которые вы можете использовать.
1️⃣ Data Visualization – Tableau, PowerBI, Qlik. – инструменты front-end, которыми легко пользоваться, и которые представляют информацию в простой и доступной форме.
2️⃣ Data Engineering – Python. Python особенно удобен, поскольку предоставляет множество библиотек для настройки необработанных данных. Он может взаимодействовать с такими источниками, как Hive, Cloudera Impala, списки MS SharePoint, файлы MS Excel, PostgreSQL, Teradata, MS SQL Server и различными текстовыми файлами, чтобы обеспечить агрегирование данных, изменение формы, разнородное вложение источников, а также автоматизацию.
3️⃣ Data Analytics – SQL. Также известный как язык структурированных запросов, это система, которая используется не только для разработки программного обеспечения, но и для управления данными для реляционных баз данных. Его функциональные возможности делают его исключительно эффективным при чтении, обработке и корректировке данных. Учитывая все вышесказанное, сильная сторона SQL заключается в его способности выполнять широкий спектр агрегаций на обширных наборах данных плюс многочисленные таблицы одновременно.
4️⃣ Big Data – HIVE. Xотя обширная база данных считается активом, так уж сложилось, что она также может стать серьезной проблемой, когда речь заходит об управлении. И именно поэтому они придумали такие инструменты для работы с большими данными, как Hive.
5️⃣ Advanced Analytics – SparkSQL. SparkSQL является чрезвычайно выдающимся инструментом, когда речь заходит о продвинутой аналитике. Разработанный для обработки структурированных и полуструктурированных данных, SparkSQL - это интерфейс spark, который не только служит механизмом распределенных SQL-запросов, но и облегчает абстрагирование сценариев в DataFrames.
{kind=link}
Архивирование Big Data
Есть три задачи, с которыми должен справляться современный архив:
1️⃣ масштабирование, вызванное ростом объёма данных (от терабайтов к петабайтам)
2️⃣ необходимость не только хранить, но и использовать архивные данные
3️⃣ автоматизация процесса и его перевод в SaaS-сферу
Достаточно успешно с Big Data на украинском рынке работает продукт Megapolis.DocNet – система внутреннего электронного документооборота.
DocNet позволяет обрабатывать и хранить до 100 ТБ данных в течение 10-ти лет. Пока нет ни одного клиента, который бы превысил этот рубеж, достигнутый максимум – 80 ТБ.
Налажен мгновенный поиск любого документа. Скорость поиска достигается хранением атрибутов документов в СУБД, при этом сами документы сохраняются на выбранном блочном устройстве, в простейшем случае - в файловой системе.
При необходимости масштабирования и отказоустойчивости используются либо специализированные файловые системы (zfs, btrfs), либо программно-аппаратные комплексы, например, Dell EMC.
Есть три задачи, с которыми должен справляться современный архив:
1️⃣ масштабирование, вызванное ростом объёма данных (от терабайтов к петабайтам)
2️⃣ необходимость не только хранить, но и использовать архивные данные
3️⃣ автоматизация процесса и его перевод в SaaS-сферу
Достаточно успешно с Big Data на украинском рынке работает продукт Megapolis.DocNet – система внутреннего электронного документооборота.
DocNet позволяет обрабатывать и хранить до 100 ТБ данных в течение 10-ти лет. Пока нет ни одного клиента, который бы превысил этот рубеж, достигнутый максимум – 80 ТБ.
Налажен мгновенный поиск любого документа. Скорость поиска достигается хранением атрибутов документов в СУБД, при этом сами документы сохраняются на выбранном блочном устройстве, в простейшем случае - в файловой системе.
При необходимости масштабирования и отказоустойчивости используются либо специализированные файловые системы (zfs, btrfs), либо программно-аппаратные комплексы, например, Dell EMC.
{kind=link}
The Oscars
Фильм Зелёная книга был признан лучшим фильмом года Американской Киноакадемией. Номинатов же было восемь.
Lindsey Poulter (@datavizlinds) собрала данные об их общем количестве номинаций (не только Оскар), успешности в домашнем прокате и рейтинге на Rotten Tomatoes, чтобы ответить на несколько вопросов:
1️⃣ Выбирают ли разные жюри одних и тех же победителей?
2️⃣ Повышает ли награда за лучшую актрису/актёра второго плана шансы на звание лучшего фильма или же награды распределяются равномерно?
3️⃣ Влияют ли кассовые сборы или рейтинг Rotten Tomatoes на конечный результат? (спойлер - нет)
А вы довольны результатами Оскара?
Фильм Зелёная книга был признан лучшим фильмом года Американской Киноакадемией. Номинатов же было восемь.
Lindsey Poulter (@datavizlinds) собрала данные об их общем количестве номинаций (не только Оскар), успешности в домашнем прокате и рейтинге на Rotten Tomatoes, чтобы ответить на несколько вопросов:
1️⃣ Выбирают ли разные жюри одних и тех же победителей?
2️⃣ Повышает ли награда за лучшую актрису/актёра второго плана шансы на звание лучшего фильма или же награды распределяются равномерно?
3️⃣ Влияют ли кассовые сборы или рейтинг Rotten Tomatoes на конечный результат? (спойлер - нет)
А вы довольны результатами Оскара?
{kind=link}
Наши читатели - компания N-iX - поделились интересной вакансией.
Команда приглашает BigData-гуру присоединиться к необычному проекту GOGO, цель которого состоит в предоставлении сервиса Wi-Fi-доступа на борту самолетов.
Уже сейчас сервис доступен на более 2900 коммерческих и более 6600 бизнес-самолетов! ✈️
N-iX сотрудничает в таких направлениях как BigData, Business Intelligence, Data Analysis и ищет таланты, которые могут внести свой вклад в развитие проекта.
Если есть опыт работы с Apache Spark, Python и Scala, у тебя хорошее понимание методологий разработки программного обеспечения и хороший английский, работал с Hadoop architecture и AWS (S3, EMR cluster, Lambda, Kinesis), тогда ты идеальный кандидат!
Команда приглашает BigData-гуру присоединиться к необычному проекту GOGO, цель которого состоит в предоставлении сервиса Wi-Fi-доступа на борту самолетов.
Уже сейчас сервис доступен на более 2900 коммерческих и более 6600 бизнес-самолетов! ✈️
N-iX сотрудничает в таких направлениях как BigData, Business Intelligence, Data Analysis и ищет таланты, которые могут внести свой вклад в развитие проекта.
Если есть опыт работы с Apache Spark, Python и Scala, у тебя хорошее понимание методологий разработки программного обеспечения и хороший английский, работал с Hadoop architecture и AWS (S3, EMR cluster, Lambda, Kinesis), тогда ты идеальный кандидат!
{kind=link}
Топ 9 статей о BigData за февраль:
1️⃣ arXiv.org для ИИ
2️⃣ Какие должности скоро хахватит ИИ
3️⃣ 6 способов как аналитикой сократить расходы
4️⃣ Архитектура Apache Kafka
5️⃣ Роль аналитики в Product Development
6️⃣ Как квантовые компьютеры могут изменить все
7️⃣ Как машинное обучение дополняет бизнес-аналитику
8️⃣ Инфографика: нехватка Data Scientist
9️⃣ 8 шагов для того чтобы стать Data Scientist
1️⃣ arXiv.org для ИИ
2️⃣ Какие должности скоро хахватит ИИ
3️⃣ 6 способов как аналитикой сократить расходы
4️⃣ Архитектура Apache Kafka
5️⃣ Роль аналитики в Product Development
6️⃣ Как квантовые компьютеры могут изменить все
7️⃣ Как машинное обучение дополняет бизнес-аналитику
8️⃣ Инфографика: нехватка Data Scientist
9️⃣ 8 шагов для того чтобы стать Data Scientist
Несколько советов аналитику.
Ниже я приведу несколько советов, которые сохранили бы мне много времени в прошлом и, возможно, сохранят ваше время (и нервы) в будущем.
8️⃣ Не собирайте комитет экспертов. Если вы увидите картину, как группа людей сидит и рисует графики (или дэшборды) на доске, при этом даже не приступив к ознакомлению с базами данных… 🏃🏻♂️ Бегите!
7️⃣ Не делайте дэшборд по «ТЗ». Если вам прислали наброски графиков и больше ничего – готовьтесь к тому, что вы провалите задание. Спрашивайте не «что рисовать?», а «что показать?» или «что объяснить?».
6️⃣ Не стройте ничего на сводных таблицах. Присланный файл excel с 18 листами, которые, по сути, являются сводными таблицами – не пойдёт. Просите источник. Эти 18 листов будут вам сниться еще очень долго.
5️⃣ Не дублируйте excel. Вот и всё. Повторить таблицы и графики, которые кто-то разработал на заре 90-ых – это не задача для вас. 😎 Вы выше этого.
4️⃣ Не используйте ВСЕ данные мира. Толку мало – а отчёт «тормозит».
3️⃣ Не требуйте от диаграммы слишком многого. Это всего лишь график, который ответит на пару вопросов. Он не должен отвечать на вопрос жизни, вселенной и вообще.
2️⃣ Не устраивайте Рождество. Если это возможно – избегайте цветовой схемы «зелёный-красный». Тяжелый и кричащий дэшборд, да ещё и непонятный дальтоникам.
1️⃣ Забудьте всё, что описано выше, если вам и вашим пользователям по душе то, как вы работаете и что из этого выходит.
Ниже я приведу несколько советов, которые сохранили бы мне много времени в прошлом и, возможно, сохранят ваше время (и нервы) в будущем.
8️⃣ Не собирайте комитет экспертов. Если вы увидите картину, как группа людей сидит и рисует графики (или дэшборды) на доске, при этом даже не приступив к ознакомлению с базами данных… 🏃🏻♂️ Бегите!
7️⃣ Не делайте дэшборд по «ТЗ». Если вам прислали наброски графиков и больше ничего – готовьтесь к тому, что вы провалите задание. Спрашивайте не «что рисовать?», а «что показать?» или «что объяснить?».
6️⃣ Не стройте ничего на сводных таблицах. Присланный файл excel с 18 листами, которые, по сути, являются сводными таблицами – не пойдёт. Просите источник. Эти 18 листов будут вам сниться еще очень долго.
5️⃣ Не дублируйте excel. Вот и всё. Повторить таблицы и графики, которые кто-то разработал на заре 90-ых – это не задача для вас. 😎 Вы выше этого.
4️⃣ Не используйте ВСЕ данные мира. Толку мало – а отчёт «тормозит».
3️⃣ Не требуйте от диаграммы слишком многого. Это всего лишь график, который ответит на пару вопросов. Он не должен отвечать на вопрос жизни, вселенной и вообще.
2️⃣ Не устраивайте Рождество. Если это возможно – избегайте цветовой схемы «зелёный-красный». Тяжелый и кричащий дэшборд, да ещё и непонятный дальтоникам.
1️⃣ Забудьте всё, что описано выше, если вам и вашим пользователям по душе то, как вы работаете и что из этого выходит.
{kind=link}
Работа с #BI и статистические вычисления.
Мы все знаем инструменты бизнес аналитики. Многие из нас сталкивались с математической статистикой или эконометрикой. Что, если я скажу вам, что эти два инструмента могут работать вместе, более того - дополнять друг друга?
От выдумки к реальности, дополняя друг друга, эти два инструмента могут творить неимоверные вещи, такие как:
▪️ определение статистических выбросов в наборе данных
▪️ построение различных кластеров
▪️ прогнозирование будущих периодов различными моделями
▪️ применение статистических критериев (тестов)
▪️ выведение показателей вероятностти на дэшборд
▪️ построение графика сети взаимосвязей
Те из вас, кто работает, скажем, c R или Python скажут "пффф! это есть и так, без какого-либо BI!". И будут правы. Но! ☝🏼 Представьте результаты вашей модели в форме интерактивного дешборда, да ещё и с интерактивными параметрами, которые можно менять на лету. 💥 То-то же :)
Это целый мир новых возможностей. Ниже ссылка на краткий обзор возможносте на примере Tableau, R и Python. Надеюсь, что он вас вдохновит :)
Мы все знаем инструменты бизнес аналитики. Многие из нас сталкивались с математической статистикой или эконометрикой. Что, если я скажу вам, что эти два инструмента могут работать вместе, более того - дополнять друг друга?
От выдумки к реальности, дополняя друг друга, эти два инструмента могут творить неимоверные вещи, такие как:
▪️ определение статистических выбросов в наборе данных
▪️ построение различных кластеров
▪️ прогнозирование будущих периодов различными моделями
▪️ применение статистических критериев (тестов)
▪️ выведение показателей вероятностти на дэшборд
▪️ построение графика сети взаимосвязей
Те из вас, кто работает, скажем, c R или Python скажут "пффф! это есть и так, без какого-либо BI!". И будут правы. Но! ☝🏼 Представьте результаты вашей модели в форме интерактивного дешборда, да ещё и с интерактивными параметрами, которые можно менять на лету. 💥 То-то же :)
Это целый мир новых возможностей. Ниже ссылка на краткий обзор возможносте на примере Tableau, R и Python. Надеюсь, что он вас вдохновит :)
{kind=link}
Tableau и R
Сегодняшний пост будет крайне краток, но (надеюсь) информативен. 💡
Вдохновленный прошлым постом, я решил сделать краткую инструкцию/обзор на интеграцию Tableau и R.
Ccылка ниже или жмакайте тут, приятного просмотра 🎥
Сегодняшний пост будет крайне краток, но (надеюсь) информативен. 💡
Вдохновленный прошлым постом, я решил сделать краткую инструкцию/обзор на интеграцию Tableau и R.
Ccылка ниже или жмакайте тут, приятного просмотра 🎥
YouTube
Интеграция R в Tableau
Интеграция R в Tableau. Инструкция и пример применения.
Каталог данных
Каталог данных - это инструмент управления метаданными, призваный упростить и ускорить работу с #BigData.
Ниже представлю вам руководство по внедрению подобного каталога. Основные шаги при таком внедрении:
1️⃣ Определить и описать пилотный проект
2️⃣ Привлечь нужных сотрудников
3️⃣ Выбрать и подключить источники данных
4️⃣ Обучить сотрудников и стимулировать использование инструмента
5️⃣ Определить и измерить рзультат
Этот отчёт - хороший пример того, как ваш бизнес может планировать, создавать, развёртывать, управлять и расширять каталог данных.
Каталог данных - это инструмент управления метаданными, призваный упростить и ускорить работу с #BigData.
Ниже представлю вам руководство по внедрению подобного каталога. Основные шаги при таком внедрении:
1️⃣ Определить и описать пилотный проект
2️⃣ Привлечь нужных сотрудников
3️⃣ Выбрать и подключить источники данных
4️⃣ Обучить сотрудников и стимулировать использование инструмента
5️⃣ Определить и измерить рзультат
Этот отчёт - хороший пример того, как ваш бизнес может планировать, создавать, развёртывать, управлять и расширять каталог данных.