
Amazon EKS + AWS KMS
Теперь куберовские секреты можно шифровать с помощью KMS:
https://aws.amazon.com/blogs/containers/using-eks-encryption-provider-support-for-defense-in-depth/
Давно востребованный и важный для различных compliance требований функционал.
#EKS #KMS
Теперь куберовские секреты можно шифровать с помощью KMS:
https://aws.amazon.com/blogs/containers/using-eks-encryption-provider-support-for-defense-in-depth/
Давно востребованный и важный для различных compliance требований функционал.
#EKS #KMS
Amazon
Using EKS encryption provider support for defense-in-depth | Amazon Web Services
Gyuho Lee, Rashmi Dwaraka, and Michael Hausenblas When we announced that we plan to natively support the AWS Encryption Provider in Amazon EKS, the feedback we got from you was pretty clear: can we have it yesterday? Now we’re launching EKS support for the…
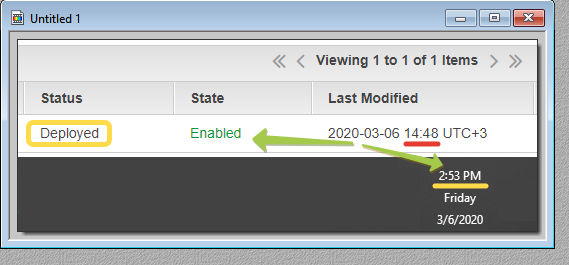
Amazon CloudFront = 5 минут!
Вы пробовали создать-обновить CloudFront? Попробуйте, он стал быстр, как м̶о̶л̶н̶и̶я̶ ̶г̶е̶п̶а̶р̶д̶ ̶л̶а̶н̶ь̶ — просто очень быстр! Всего 5 минут вместо 25-30 (а то и 40-50) минут раньше. Это ж просто праздник какой-то!
В реальности под капотом большинство endpoints обновляется вообще за секунды и условно пять минут нужно ждать подтверждения от 100%
Не знаю, когда расскажут про эти выдающиеся результаты команды CloudFront официально, но это отличное завершение недели и есть повод за них выпить во всех смыслах. Браво!
#CloudFront
Вы пробовали создать-обновить CloudFront? Попробуйте, он стал быстр, как м̶о̶л̶н̶и̶я̶ ̶г̶е̶п̶а̶р̶д̶ ̶л̶а̶н̶ь̶ — просто очень быстр! Всего 5 минут вместо 25-30 (а то и 40-50) минут раньше. Это ж просто праздник какой-то!
В реальности под капотом большинство endpoints обновляется вообще за секунды и условно пять минут нужно ждать подтверждения от 100%
Edge locations, которых становится всё больше.Не знаю, когда расскажут про эти выдающиеся результаты команды CloudFront официально, но это отличное завершение недели и есть повод за них выпить во всех смыслах. Браво!
#CloudFront
{kind=link}
Все сервисы AWS на одной странице-табличке вместе с ссылками на них:
https://www.awsgeek.com/AWS-Periodic-Table/
#info
https://www.awsgeek.com/AWS-Periodic-Table/
#info
Ответы на викторину по S3 + torrents — правда или ложь
Кто знает или читает историю AWS - тому ответ был известен заранее. :) А правильный ответ — да, S3 умеет торренты, соответствующий раздел в документации по ссылке с очевидным урлом:
https://docs.aws.amazon.com/AmazonS3/latest/dev/S3Torrent.html
#ответы
Кто знает или читает историю AWS - тому ответ был известен заранее. :) А правильный ответ — да, S3 умеет торренты, соответствующий раздел в документации по ссылке с очевидным урлом:
https://docs.aws.amazon.com/AmazonS3/latest/dev/S3Torrent.html
#ответы
Telegram
aws_history
Вы знали, что Amazon S3 поддерживает торренты? Нет? Ну, так вот пожалуйста, статья из 2006-го:
https://geekdom.net/blog/archives/2006/08/17/fun_with_torrents_and_amazon_s3.html
И для пущей убедительности официальная документация:
https://docs.aws.amaz…
https://geekdom.net/blog/archives/2006/08/17/fun_with_torrents_and_amazon_s3.html
И для пущей убедительности официальная документация:
https://docs.aws.amaz…
Disaster Tolerance vs Disaster Recovery
Длинная подробная статья о Disaster Tolerance подходе:
https://medium.com/cloudpegboard/disaster-tolerance-patterns-using-aws-serverless-services-fdfbe4163d84
Если заходит речь о бэкапах и каких-то их аспектов в частности или даже о Backup Strategy в общем, то всегда нужно помнить, что бэкап, который вы никогда не проверяли — бессмысленный бэкап, дающий лишь обманчивое ощущение защищённости.
Когда спрашивают "Что у нас с бэкапами?", всегда переводите вопрос в контекст "Что у нас с Disaster Recovery?" — бэкапы должны (периодически) проверяться путём подъёма полной версии вашего приложения/окружения в рамках DR плана.
В статье же рассматривается продолжение и развитие этого подхода — на вариант Disaster Tolerance, когда вы сразу закладываете в архитектуру устойчивость к проблемам падения региональных сервисов, так сказать, такой себе Netflix way.
Полезный и правильный взгляд, особенно если у вас Serverless проект, рекомендуется к прочтению.
#DR
Длинная подробная статья о Disaster Tolerance подходе:
https://medium.com/cloudpegboard/disaster-tolerance-patterns-using-aws-serverless-services-fdfbe4163d84
Если заходит речь о бэкапах и каких-то их аспектов в частности или даже о Backup Strategy в общем, то всегда нужно помнить, что бэкап, который вы никогда не проверяли — бессмысленный бэкап, дающий лишь обманчивое ощущение защищённости.
Когда спрашивают "Что у нас с бэкапами?", всегда переводите вопрос в контекст "Что у нас с Disaster Recovery?" — бэкапы должны (периодически) проверяться путём подъёма полной версии вашего приложения/окружения в рамках DR плана.
В статье же рассматривается продолжение и развитие этого подхода — на вариант Disaster Tolerance, когда вы сразу закладываете в архитектуру устойчивость к проблемам падения региональных сервисов, так сказать, такой себе Netflix way.
Полезный и правильный взгляд, особенно если у вас Serverless проект, рекомендуется к прочтению.
#DR
Medium
Disaster Tolerance Patterns Using AWS Serverless Services
Details for practical implementation and uncovering gotchas so you don’t have to
Amazon S3 Website Endpoints - ищем логику
Многие попадаются при написании своих скриптов для работы с S3 Website Endpoints:
https://docs.aws.amazon.com/general/latest/gr/s3.html#s3_website_region_endpoints
Когда выясняется, что
После тщетных попыток понять задумку разработчиков всего этого, вырывается очевидный восклик: «Где логика?!?»
Давайте поищем её в истории AWS. Возьмём даты анонсов AWS регионов и упорядочим по времени их появления. В результате получится табличка - см. картинку.
Видно, что до 2013-го года использовался вариант
Всё просто и логично. Почему с 2014-го стали использовать отдельный поддомен для региона — уже совсем другая история.
#s3
Многие попадаются при написании своих скриптов для работы с S3 Website Endpoints:
https://docs.aws.amazon.com/general/latest/gr/s3.html#s3_website_region_endpoints
Когда выясняется, что
s3-website в одних регионах является поддоменом и пишется через точку, а в других через тире вместе с идентификатором региона:s3-website.region.amazonaws.coms3-website-region.amazonaws.comПосле тщетных попыток понять задумку разработчиков всего этого, вырывается очевидный восклик: «Где логика?!?»
Давайте поищем её в истории AWS. Возьмём даты анонсов AWS регионов и упорядочим по времени их появления. В результате получится табличка - см. картинку.
Видно, что до 2013-го года использовался вариант
s3-website-region.amazonaws.com, начиная с Франкфурта - используется s3-website.region.amazonaws.com.Всё просто и логично. Почему с 2014-го стали использовать отдельный поддомен для региона — уже совсем другая история.
#s3
{kind=link}
Полезное видео для понимания тонкостей работы S3.
AWS re:Invent 2017: Deep Dive on Amazon S3 & Amazon Glacier Infrastructure, with spe (STG301)
Ссылка на начало видео, где немного рассказывается, как работает Amazon S3 под капотом (на картинке).
#s3 #video
AWS re:Invent 2017: Deep Dive on Amazon S3 & Amazon Glacier Infrastructure, with spe (STG301)
Ссылка на начало видео, где немного рассказывается, как работает Amazon S3 под капотом (на картинке).
#s3 #video
{kind=link}
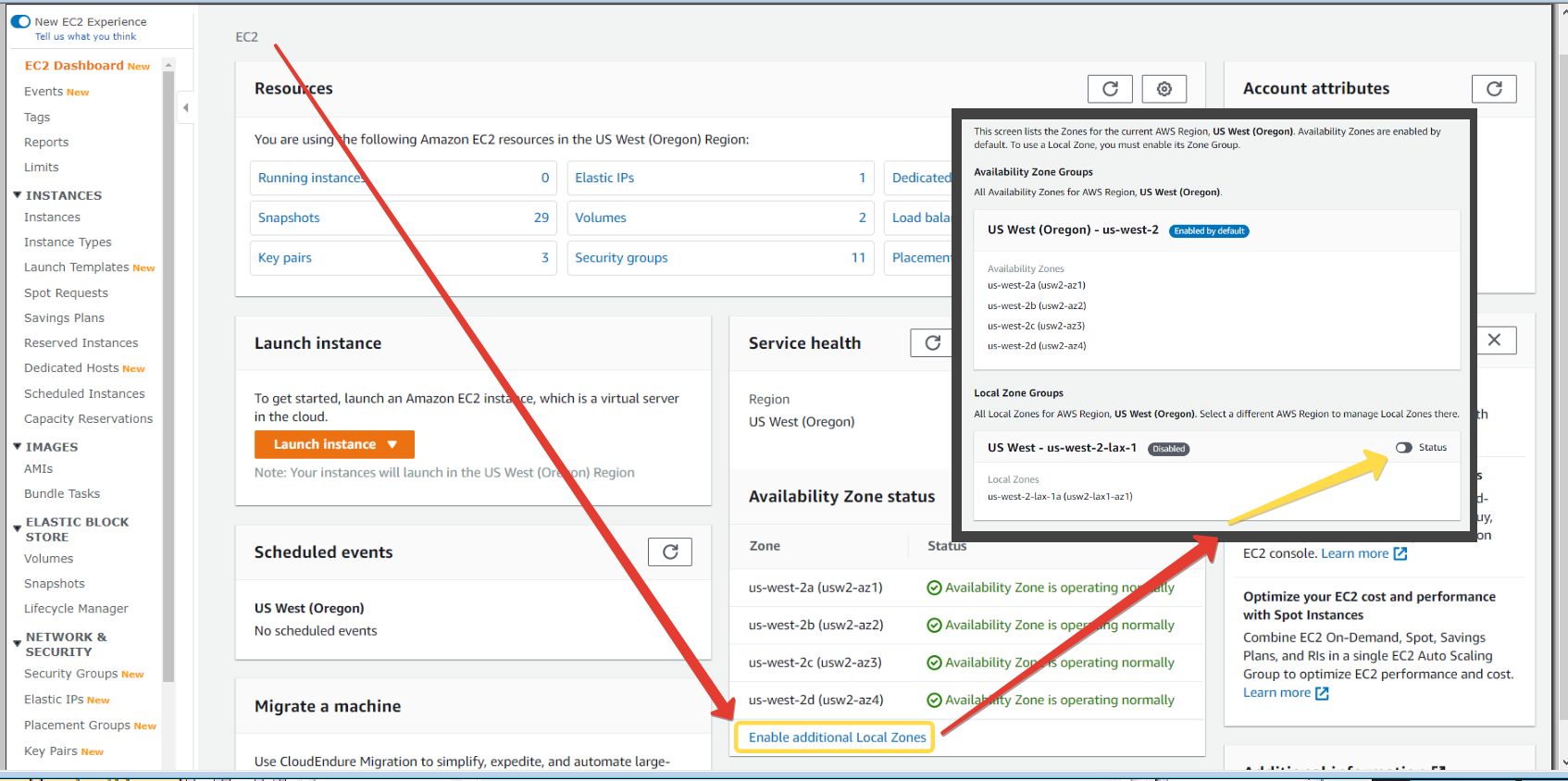
EC2 Local Zone Settings
Для региона Oregon, где имеется Local Zone (кто пропустил - почитайте про первую локальную зону в Лос-Анжелесе - если коротко, то это подзона с задержками в единицы миллисекунд для, например, игр в виртуальной реальности и прочих вещей, требовательных к latency), теперь можно её включить в консоли.
Сделать это не так просто - нужно найти плохозаметную кнопку Enable additional Local Zones на дашборде EC2 консоли (см. картинку) и после изменить статус на
Актуально только (пока) для Oregon (где есть локальная зона). Включить можно, а выключить лишь через поддержку. Потому, в общем случае, если вы не планируете её использовать напрямую, лучше не включать, чтобы случайно не поломать какие-то ваши скрипты подзоной в виде
#AWS_Console #EC2
Для региона Oregon, где имеется Local Zone (кто пропустил - почитайте про первую локальную зону в Лос-Анжелесе - если коротко, то это подзона с задержками в единицы миллисекунд для, например, игр в виртуальной реальности и прочих вещей, требовательных к latency), теперь можно её включить в консоли.
Сделать это не так просто - нужно найти плохозаметную кнопку Enable additional Local Zones на дашборде EC2 консоли (см. картинку) и после изменить статус на
Enable.Актуально только (пока) для Oregon (где есть локальная зона). Включить можно, а выключить лишь через поддержку. Потому, в общем случае, если вы не планируете её использовать напрямую, лучше не включать, чтобы случайно не поломать какие-то ваши скрипты подзоной в виде
us-west-2-lax-1.#AWS_Console #EC2
{kind=link}
Новые тесты AWS Graviton 2
https://www.anandtech.com/show/15578/cloud-clash-amazon-graviton2-arm-against-intel-and-amd
Если коротко, Graviton 2 рвёт AMD и Intel как тузик грелку прямо везде. Правда с поправкой на то, что все тесты синтетические (нет реальных бенчмарков), сравнивать 64 ядра Гравитона 2 с 32 ядра + 32 потока у старенького AMD первого поколения Zen — так себе практика (почему не Zen2 и что там делает Intel с 24 ядрами + 24 потоками — промолчим).
Но если отбросить подобные придирки — выглядит устрашающе и наверняка достойно, чтоб хотя бы попробовать лично и сделать собственный вывод.
#Graviton
https://www.anandtech.com/show/15578/cloud-clash-amazon-graviton2-arm-against-intel-and-amd
Если коротко, Graviton 2 рвёт AMD и Intel как тузик грелку прямо везде. Правда с поправкой на то, что все тесты синтетические (нет реальных бенчмарков), сравнивать 64 ядра Гравитона 2 с 32 ядра + 32 потока у старенького AMD первого поколения Zen — так себе практика (почему не Zen2 и что там делает Intel с 24 ядрами + 24 потоками — промолчим).
Но если отбросить подобные придирки — выглядит устрашающе и наверняка достойно, чтоб хотя бы попробовать лично и сделать собственный вывод.
#Graviton
AnandTech
Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
It’s been a year and a half since Amazon released their first-generation Graviton Arm-based processor core, publicly available in AWS EC2 as the so-called 'A1' instances. While the processor didn’t impress all too much in terms of its performance, it was…
EKS + Kubernetes 1.15
https://docs.aws.amazon.com/eks/latest/userguide/update-cluster.html
Грустный комментарий, но это нужно зафиксировать — спустя релиза 1.15 прошло 9 месяцев. Значит, получается, 1.16 нужно ждать в июне.
Выдержка и ещё раз выдержка. Важное свойство для успешной работы с некоторыми сервисами AWS.
#EKS
https://docs.aws.amazon.com/eks/latest/userguide/update-cluster.html
Грустный комментарий, но это нужно зафиксировать — спустя релиза 1.15 прошло 9 месяцев. Значит, получается, 1.16 нужно ждать в июне.
Выдержка и ещё раз выдержка. Важное свойство для успешной работы с некоторыми сервисами AWS.
#EKS
{kind=link}
Если вам (не) нравилась CoreOS, то попробуйте амазоновский вариант операционной системы для работы с контейнерами Bottlerocket OS:
https://aws.amazon.com/blogs/aws/bottlerocket-open-source-os-for-container-hosting/
На текущий момент она подразумевает работу с EC2 инстансами на Амазоне, но являясь открытой, в будущем будет возможность поднимать Bottlerocket OS на своём железе.
https://github.com/bottlerocket-os/bottlerocket
Кроме того, в процессе реализации поддержка ECS, а после и Firecracker:
https://github.com/orgs/bottlerocket-os/projects/1
В общем, можно сказать, что Амазон реагирует на критику в свой адрес и в результате всё активней движется в сторону Open Source.
#Bottlerocket
https://aws.amazon.com/blogs/aws/bottlerocket-open-source-os-for-container-hosting/
На текущий момент она подразумевает работу с EC2 инстансами на Амазоне, но являясь открытой, в будущем будет возможность поднимать Bottlerocket OS на своём железе.
https://github.com/bottlerocket-os/bottlerocket
Кроме того, в процессе реализации поддержка ECS, а после и Firecracker:
https://github.com/orgs/bottlerocket-os/projects/1
В общем, можно сказать, что Амазон реагирует на критику в свой адрес и в результате всё активней движется в сторону Open Source.
#Bottlerocket
Amazon
Bottlerocket – Open Source OS for Container Hosting | Amazon Web Services
It is safe to say that our industry has decided that containers are now the chosen way to package and scale applications. Our customers are making great use of Amazon Elastic Container Service (Amazon ECS) and EKS, with over 80% of all cloud-based containers…
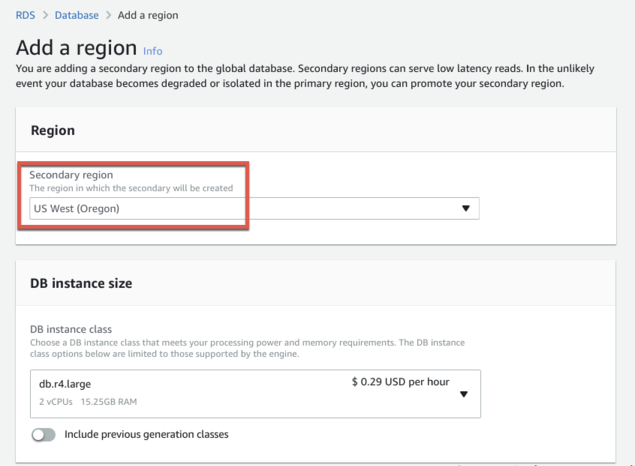
Aurora PostgreSQL глобализировалась:
https://aws.amazon.com/about-aws/whats-new/2020/03/amazon-aurora-with-postgresql-compatibility-supports-amazon-aurora-global-database/
На текущий момент поддерживается лишь версия Aurora PostgreSQL 10.11, которую нужно создать или восстановить из снэпшота версии PostgreSQL 10.7 на инстансх
#Aurora
https://aws.amazon.com/about-aws/whats-new/2020/03/amazon-aurora-with-postgresql-compatibility-supports-amazon-aurora-global-database/
На текущий момент поддерживается лишь версия Aurora PostgreSQL 10.11, которую нужно создать или восстановить из снэпшота версии PostgreSQL 10.7 на инстансх
db.r4 или db.r5 типа, а после создания добавить регионы (до четырёх штук - на картинке), получив таким образом глобальную работу.#Aurora
{kind=link}
CodeBuild и ECS
Когда из CodeBuild нужно работать с другим аккаунтом, и потребуется переключаться в роль с помощью флажка
Это потому, что вместо обычного:
В секции профиля файла
И всё заработает.
Почему? Получается, видимо, потому, что CodeBuild под капотом использует ECS.
В принципе, логично, хоть и не видел подобного в документации (что тоже логично).
#CodeBuild
Когда из CodeBuild нужно работать с другим аккаунтом, и потребуется переключаться в роль с помощью флажка
--profile, учтите , что обычный вариант не сработает и будет давать ошибку:Error when retrieving credentials from Ec2InstanceMetadata: No credentials found in credential_source referenced in profile ***Это потому, что вместо обычного:
credential_source = Ec2InstanceMetadataВ секции профиля файла
~/.aws/config нужно использовать:credential_source = EcsContainerИ всё заработает.
Почему? Получается, видимо, потому, что CodeBuild под капотом использует ECS.
В принципе, логично, хоть и не видел подобного в документации (что тоже логично).
#CodeBuild
Telegram
aws_notes
Чтобы запустить #aws_cli команду для другого аккаунта, нужно сначала добавить в ~/.aws/config профиль типа:
[profile devops-codecommit]
role_arn = arn:aws:iam::123456789012:role/codecommit-role
credential_source = Ec2InstanceMetadata
Параметры:
devops-codecommit…
[profile devops-codecommit]
role_arn = arn:aws:iam::123456789012:role/codecommit-role
credential_source = Ec2InstanceMetadata
Параметры:
devops-codecommit…
Allow + NotPrincipal
Стоит быть внимательным и не допускать использования связки
Где вы как бы хотите запретить доступ в бакет каким-то юзерам из каких-то аккаунтов.
В результате они (эти два юзера из примера выше) туда, действительно, не получат доступа. Однако кроме этого, незаметно, в бакет
https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_notprincipal.html#specifying-notprincipal-allow
Потому в общем случае всегда нужно использовать связку запретить+кроме (
#s3 #bucket_policy
Стоит быть внимательным и не допускать использования связки
Allow + NotPrincipal при написании S3 Bucket Policy, например, типа такого варианта:{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"NotPrincipal": {"AWS": [
"arn:aws:iam::111111111111:user/SomeUser1",
"arn:aws:iam::222222222222:user/SomeUser2"
]},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::my-bucket",
"arn:aws:s3:::my-bucket/*"
]
}]
}Где вы как бы хотите запретить доступ в бакет каким-то юзерам из каких-то аккаунтов.
В результате они (эти два юзера из примера выше) туда, действительно, не получат доступа. Однако кроме этого, незаметно, в бакет
my-bucket получат доступ не просто другие ваши пользователи, но и вообще все, включая гостей (anonymous users) из интернета!https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_notprincipal.html#specifying-notprincipal-allow
Потому в общем случае всегда нужно использовать связку запретить+кроме (
Deny+NotPrincipal).#s3 #bucket_policy
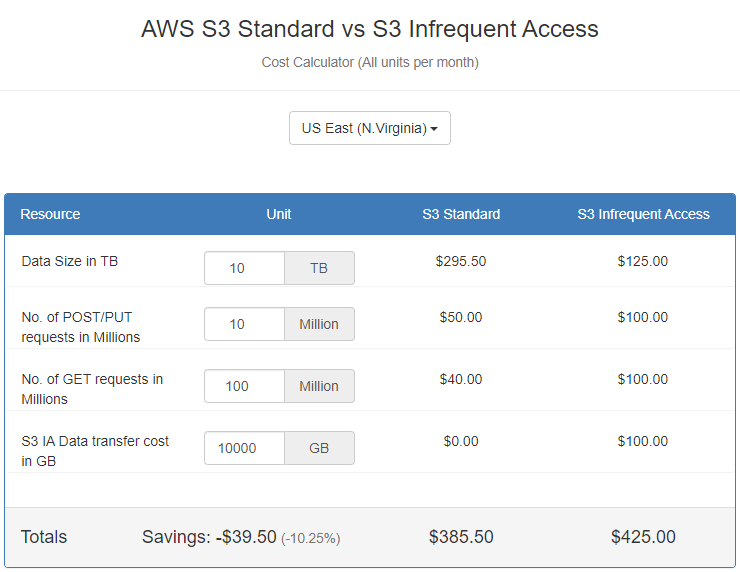
Когда вы желаете сэкономить на хранении данных в S3 с помощью перевода данных на S3 IA (Infrequent Access), который в два раза дешевле обычного (S3 Standard), обязательно учитывайте, что за получение данных из S3 IA взимается плата (1 цент каждый гигабайт в отличие от бесплатного трафика для S3 Standard).
Иначе может получиться как здесь:
https://fudless.xyz/aws/boom/
Для подсчёта выгодности - можно использовать специальный калькулятор S3 Standard vs S3 Infrequent Access:
https://www.gulamshakir.com/apps/s3calc/index.html
Аналогично в случае использования S3 Intelligent-Tiering — там сам Амазон автоматически переведёт данные из S3 IA в S3 Standard при первом же доступе к ним (и не получится так плачевно, как по первой ссылке), однако как раз и нужно учитывать, что транзит из одного типа в другой (Lifecycle Transition) также стоит денег:
https://aws.amazon.com/s3/pricing/
Итого: Амазон предлагает много разных и действенных способов сэкономить на хранилище данных в S3. Однако всё нужно применять, понимая, что делаешь.
И не стоит забывать, что лучший способ действительно сэкономить - удалить нафиг всё ненужное. Почти всегда это даёт на порядки большую экономию, чем высчитываение центов на калькуляторах типов хранения.
#s3 #cost_optimization
Иначе может получиться как здесь:
https://fudless.xyz/aws/boom/
Для подсчёта выгодности - можно использовать специальный калькулятор S3 Standard vs S3 Infrequent Access:
https://www.gulamshakir.com/apps/s3calc/index.html
Аналогично в случае использования S3 Intelligent-Tiering — там сам Амазон автоматически переведёт данные из S3 IA в S3 Standard при первом же доступе к ним (и не получится так плачевно, как по первой ссылке), однако как раз и нужно учитывать, что транзит из одного типа в другой (Lifecycle Transition) также стоит денег:
https://aws.amazon.com/s3/pricing/
Итого: Амазон предлагает много разных и действенных способов сэкономить на хранилище данных в S3. Однако всё нужно применять, понимая, что делаешь.
И не стоит забывать, что лучший способ действительно сэкономить - удалить нафиг всё ненужное. Почти всегда это даёт на порядки большую экономию, чем высчитываение центов на калькуляторах типов хранения.
#s3 #cost_optimization
{kind=link}
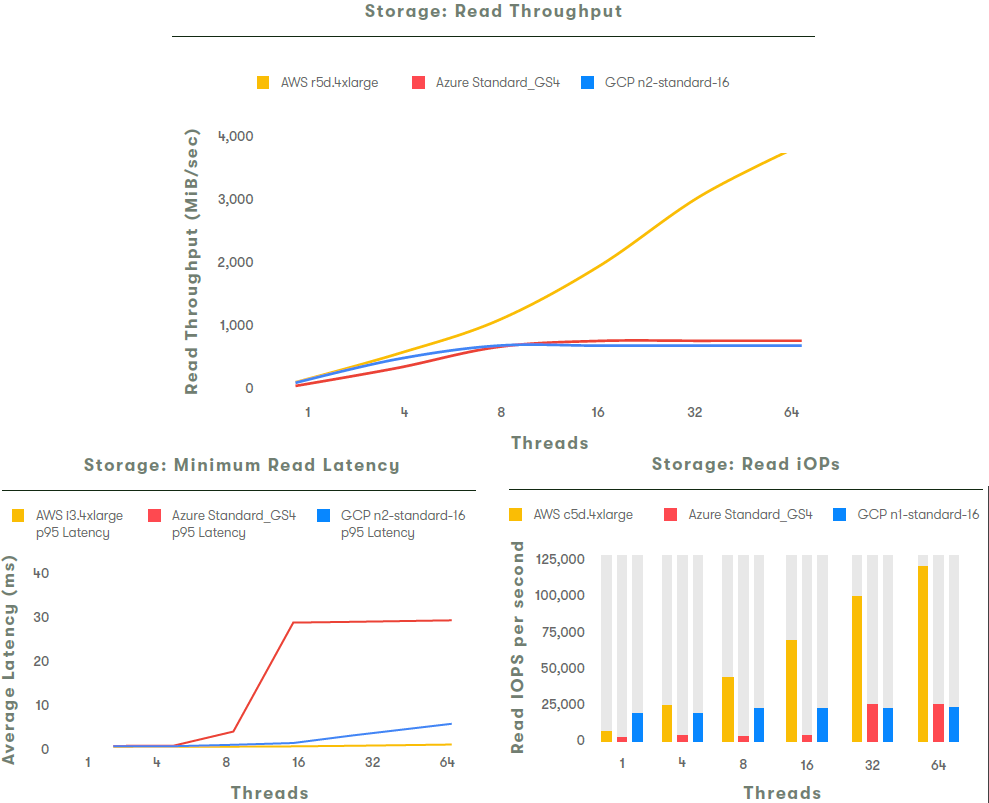
Тестов много не бывает - комплексное сравнение производительности различных подсистем AWS, Azure и GCP
у @tech_b0lt_Genona.
Если коротко, то AWS хорош, Azure неплох, а GCP растёт над собой.
#info #comparison
у @tech_b0lt_Genona.
Если коротко, то AWS хорош, Azure неплох, а GCP растёт над собой.
#info #comparison
{kind=link}
Простое понятно всем, а известное известно всем. Спойлер — нет, это не так.
Когда разбираешься с какой-то совсем новой для тебя темой, стараешься максимально подробно записывать, что делаешь, что непонятно и неочевидно. По опыту знаешь, что когда разберёшься — не сможешь и близко вспомнить, что же тут непонятного и неочевидного — вот же, так, здесь, смотри сюда, читай туда, делай так. Но ведь до этого, даже имея большой опыт подобных начинаний — было непонятно!
Когда варишься в какой-то области много лет, то кажется, что — ну, вы, конечно, знаете, это же всем известно, общеизвестный факт. Что значит, впервые слышите??? Как никогда? А как же вы проектировали свою систему, использовали этот сервис, настраивали безопасности, проводили аудит, занимались оптимизацией и не знали?!?
Первая часть — непонятность понятного — за много лет приучила, с одной стороны, рассказывать подробно и с нуля. А с другой, как было упомянуто выше — записывать всё во время освоения новой темы.
Комбинация этих двух вещей позволяет, в частности, появляться здесь материалам в бесконечном цикле. Ведь это просто отражение того, что записываю для себя, чтобы было а) больше шансов запомнить, б) больше шансов потом здесь же найти (т.к. всё запомнить невозможно).
Со второй частью сложней. Постоянно рассказывая про "известное всем" можно, с одной стороны, быстро вызвать раздражение у тех, кто это знает и тоже считает, что это "известно всем", "гуглится в один клик" и "есть на главной странице".
С другой стороны, когда кто-то впервые здесь прочитает, что такое есть, заинтересуется и узнает, поймёт, прокачается или успешно сдаст экзамен — как бы хорошо. Получается, что и этот вариант правильный.
К чему это я? Пытался найти баланс между технической детализацией, интересной самому по части AWS и "общеизвестными вещами", полезными тем, кто хочет узнать и разобраться или даже просто узнать, стоит ли разбираться.
Для этого, кто пропустил — здесь были опросы по уровню знаний AWS. Кто не нажимал — нажмите и/или посмотрите, как нажимали другие. В результате обычно, на теперь, получается, что более технически узкие и сложные вещи пишу в чате, а здесь уже главное-основное, что может заинтересовать большинство (хотя это не строгое правило).
В общем, с учётом вдруг осознанной важности донести известное всем до известности всех — впредь тут будет больше очевидного. Как-то так.
#пятничное
Когда разбираешься с какой-то совсем новой для тебя темой, стараешься максимально подробно записывать, что делаешь, что непонятно и неочевидно. По опыту знаешь, что когда разберёшься — не сможешь и близко вспомнить, что же тут непонятного и неочевидного — вот же, так, здесь, смотри сюда, читай туда, делай так. Но ведь до этого, даже имея большой опыт подобных начинаний — было непонятно!
Когда варишься в какой-то области много лет, то кажется, что — ну, вы, конечно, знаете, это же всем известно, общеизвестный факт. Что значит, впервые слышите??? Как никогда? А как же вы проектировали свою систему, использовали этот сервис, настраивали безопасности, проводили аудит, занимались оптимизацией и не знали?!?
Первая часть — непонятность понятного — за много лет приучила, с одной стороны, рассказывать подробно и с нуля. А с другой, как было упомянуто выше — записывать всё во время освоения новой темы.
Комбинация этих двух вещей позволяет, в частности, появляться здесь материалам в бесконечном цикле. Ведь это просто отражение того, что записываю для себя, чтобы было а) больше шансов запомнить, б) больше шансов потом здесь же найти (т.к. всё запомнить невозможно).
Со второй частью сложней. Постоянно рассказывая про "известное всем" можно, с одной стороны, быстро вызвать раздражение у тех, кто это знает и тоже считает, что это "известно всем", "гуглится в один клик" и "есть на главной странице".
С другой стороны, когда кто-то впервые здесь прочитает, что такое есть, заинтересуется и узнает, поймёт, прокачается или успешно сдаст экзамен — как бы хорошо. Получается, что и этот вариант правильный.
К чему это я? Пытался найти баланс между технической детализацией, интересной самому по части AWS и "общеизвестными вещами", полезными тем, кто хочет узнать и разобраться или даже просто узнать, стоит ли разбираться.
Для этого, кто пропустил — здесь были опросы по уровню знаний AWS. Кто не нажимал — нажмите и/или посмотрите, как нажимали другие. В результате обычно, на теперь, получается, что более технически узкие и сложные вещи пишу в чате, а здесь уже главное-основное, что может заинтересовать большинство (хотя это не строгое правило).
В общем, с учётом вдруг осознанной важности донести известное всем до известности всех — впредь тут будет больше очевидного. Как-то так.
#пятничное
{kind=link}
Есть места, где люди делятся своими страшными ошибками. И почти всегда это ужасно смешно.
---
eric gisse
what i'm doing here is hugely dangerous
needs to be done so w/e
oh. i have the best mistake for this channel
DO. NOT. DELETE. AN. RDS. NETWORK. INTERFACE.
you will put your RDS instance in an unrecoverable state
it is unknown if support can fix that
ajeffree
wait the network interface?
you mean the subnet group?
eric gisse
no, network interface
i stopped the db and got the galaxy brain idea to go on a resource purge because we have stuff that builds up but doesn't throw away
===
Итого - не переусердствуйте в стремлении максимально вычистить ресурсы. Не нужно (пожалуйста) удалять сетевой интерфейс остановленной RDS базы данных.
#субботничное
---
eric gisse
12:48 AMwhat i'm doing here is hugely dangerous
needs to be done so w/e
oh. i have the best mistake for this channel
DO. NOT. DELETE. AN. RDS. NETWORK. INTERFACE.
you will put your RDS instance in an unrecoverable state
it is unknown if support can fix that
ajeffree
1:17 AMwait the network interface?
you mean the subnet group?
eric gisse
1:18 AMno, network interface
i stopped the db and got the galaxy brain idea to go on a resource purge because we have stuff that builds up but doesn't throw away
===
Итого - не переусердствуйте в стремлении максимально вычистить ресурсы. Не нужно (пожалуйста) удалять сетевой интерфейс остановленной RDS базы данных.
#субботничное
{kind=link}