
EC2 Local Zone Settings
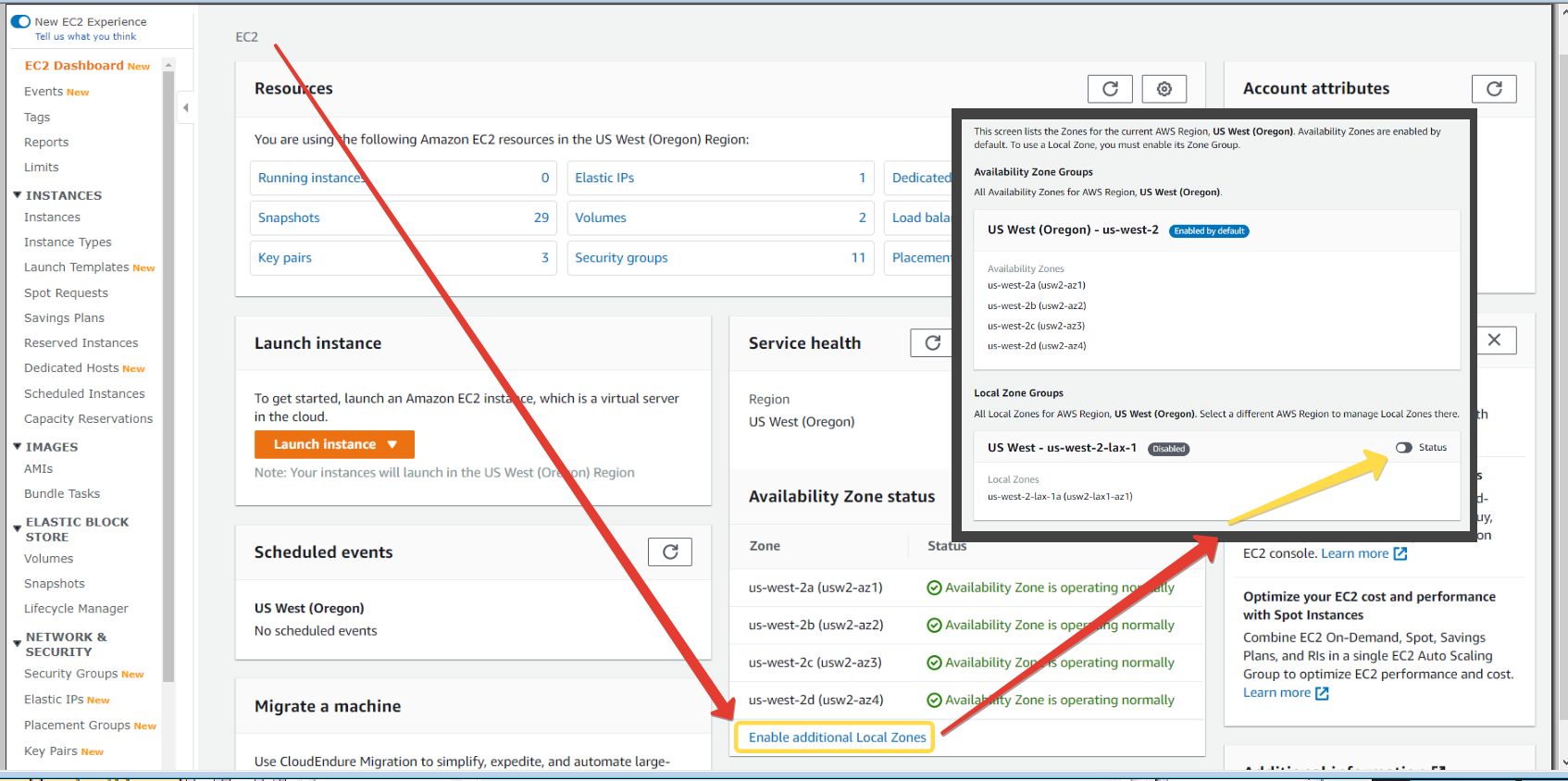
Для региона Oregon, где имеется Local Zone (кто пропустил - почитайте про первую локальную зону в Лос-Анжелесе - если коротко, то это подзона с задержками в единицы миллисекунд для, например, игр в виртуальной реальности и прочих вещей, требовательных к latency), теперь можно её включить в консоли.
Сделать это не так просто - нужно найти плохозаметную кнопку Enable additional Local Zones на дашборде EC2 консоли (см. картинку) и после изменить статус на
Актуально только (пока) для Oregon (где есть локальная зона). Включить можно, а выключить лишь через поддержку. Потому, в общем случае, если вы не планируете её использовать напрямую, лучше не включать, чтобы случайно не поломать какие-то ваши скрипты подзоной в виде
#AWS_Console #EC2
Для региона Oregon, где имеется Local Zone (кто пропустил - почитайте про первую локальную зону в Лос-Анжелесе - если коротко, то это подзона с задержками в единицы миллисекунд для, например, игр в виртуальной реальности и прочих вещей, требовательных к latency), теперь можно её включить в консоли.
Сделать это не так просто - нужно найти плохозаметную кнопку Enable additional Local Zones на дашборде EC2 консоли (см. картинку) и после изменить статус на
Enable.Актуально только (пока) для Oregon (где есть локальная зона). Включить можно, а выключить лишь через поддержку. Потому, в общем случае, если вы не планируете её использовать напрямую, лучше не включать, чтобы случайно не поломать какие-то ваши скрипты подзоной в виде
us-west-2-lax-1.#AWS_Console #EC2
{kind=link}
Новые тесты AWS Graviton 2
https://www.anandtech.com/show/15578/cloud-clash-amazon-graviton2-arm-against-intel-and-amd
Если коротко, Graviton 2 рвёт AMD и Intel как тузик грелку прямо везде. Правда с поправкой на то, что все тесты синтетические (нет реальных бенчмарков), сравнивать 64 ядра Гравитона 2 с 32 ядра + 32 потока у старенького AMD первого поколения Zen — так себе практика (почему не Zen2 и что там делает Intel с 24 ядрами + 24 потоками — промолчим).
Но если отбросить подобные придирки — выглядит устрашающе и наверняка достойно, чтоб хотя бы попробовать лично и сделать собственный вывод.
#Graviton
https://www.anandtech.com/show/15578/cloud-clash-amazon-graviton2-arm-against-intel-and-amd
Если коротко, Graviton 2 рвёт AMD и Intel как тузик грелку прямо везде. Правда с поправкой на то, что все тесты синтетические (нет реальных бенчмарков), сравнивать 64 ядра Гравитона 2 с 32 ядра + 32 потока у старенького AMD первого поколения Zen — так себе практика (почему не Zen2 и что там делает Intel с 24 ядрами + 24 потоками — промолчим).
Но если отбросить подобные придирки — выглядит устрашающе и наверняка достойно, чтоб хотя бы попробовать лично и сделать собственный вывод.
#Graviton
AnandTech
Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
It’s been a year and a half since Amazon released their first-generation Graviton Arm-based processor core, publicly available in AWS EC2 as the so-called 'A1' instances. While the processor didn’t impress all too much in terms of its performance, it was…
EKS + Kubernetes 1.15
https://docs.aws.amazon.com/eks/latest/userguide/update-cluster.html
Грустный комментарий, но это нужно зафиксировать — спустя релиза 1.15 прошло 9 месяцев. Значит, получается, 1.16 нужно ждать в июне.
Выдержка и ещё раз выдержка. Важное свойство для успешной работы с некоторыми сервисами AWS.
#EKS
https://docs.aws.amazon.com/eks/latest/userguide/update-cluster.html
Грустный комментарий, но это нужно зафиксировать — спустя релиза 1.15 прошло 9 месяцев. Значит, получается, 1.16 нужно ждать в июне.
Выдержка и ещё раз выдержка. Важное свойство для успешной работы с некоторыми сервисами AWS.
#EKS
{kind=link}
Если вам (не) нравилась CoreOS, то попробуйте амазоновский вариант операционной системы для работы с контейнерами Bottlerocket OS:
https://aws.amazon.com/blogs/aws/bottlerocket-open-source-os-for-container-hosting/
На текущий момент она подразумевает работу с EC2 инстансами на Амазоне, но являясь открытой, в будущем будет возможность поднимать Bottlerocket OS на своём железе.
https://github.com/bottlerocket-os/bottlerocket
Кроме того, в процессе реализации поддержка ECS, а после и Firecracker:
https://github.com/orgs/bottlerocket-os/projects/1
В общем, можно сказать, что Амазон реагирует на критику в свой адрес и в результате всё активней движется в сторону Open Source.
#Bottlerocket
https://aws.amazon.com/blogs/aws/bottlerocket-open-source-os-for-container-hosting/
На текущий момент она подразумевает работу с EC2 инстансами на Амазоне, но являясь открытой, в будущем будет возможность поднимать Bottlerocket OS на своём железе.
https://github.com/bottlerocket-os/bottlerocket
Кроме того, в процессе реализации поддержка ECS, а после и Firecracker:
https://github.com/orgs/bottlerocket-os/projects/1
В общем, можно сказать, что Амазон реагирует на критику в свой адрес и в результате всё активней движется в сторону Open Source.
#Bottlerocket
Amazon
Bottlerocket – Open Source OS for Container Hosting | Amazon Web Services
It is safe to say that our industry has decided that containers are now the chosen way to package and scale applications. Our customers are making great use of Amazon Elastic Container Service (Amazon ECS) and EKS, with over 80% of all cloud-based containers…
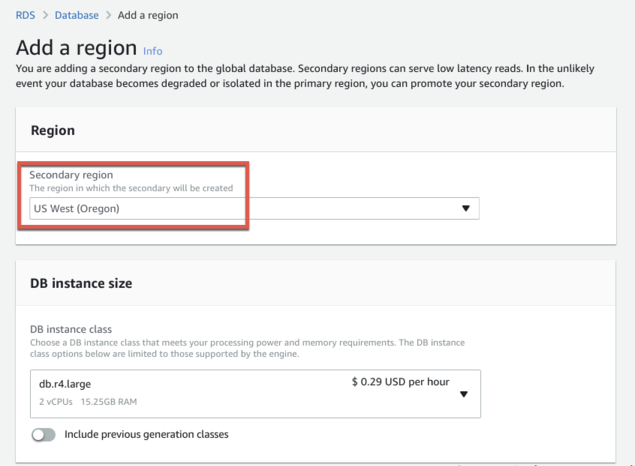
Aurora PostgreSQL глобализировалась:
https://aws.amazon.com/about-aws/whats-new/2020/03/amazon-aurora-with-postgresql-compatibility-supports-amazon-aurora-global-database/
На текущий момент поддерживается лишь версия Aurora PostgreSQL 10.11, которую нужно создать или восстановить из снэпшота версии PostgreSQL 10.7 на инстансх
#Aurora
https://aws.amazon.com/about-aws/whats-new/2020/03/amazon-aurora-with-postgresql-compatibility-supports-amazon-aurora-global-database/
На текущий момент поддерживается лишь версия Aurora PostgreSQL 10.11, которую нужно создать или восстановить из снэпшота версии PostgreSQL 10.7 на инстансх
db.r4 или db.r5 типа, а после создания добавить регионы (до четырёх штук - на картинке), получив таким образом глобальную работу.#Aurora
{kind=link}
CodeBuild и ECS
Когда из CodeBuild нужно работать с другим аккаунтом, и потребуется переключаться в роль с помощью флажка
Это потому, что вместо обычного:
В секции профиля файла
И всё заработает.
Почему? Получается, видимо, потому, что CodeBuild под капотом использует ECS.
В принципе, логично, хоть и не видел подобного в документации (что тоже логично).
#CodeBuild
Когда из CodeBuild нужно работать с другим аккаунтом, и потребуется переключаться в роль с помощью флажка
--profile, учтите , что обычный вариант не сработает и будет давать ошибку:Error when retrieving credentials from Ec2InstanceMetadata: No credentials found in credential_source referenced in profile ***Это потому, что вместо обычного:
credential_source = Ec2InstanceMetadataВ секции профиля файла
~/.aws/config нужно использовать:credential_source = EcsContainerИ всё заработает.
Почему? Получается, видимо, потому, что CodeBuild под капотом использует ECS.
В принципе, логично, хоть и не видел подобного в документации (что тоже логично).
#CodeBuild
Telegram
aws_notes
Чтобы запустить #aws_cli команду для другого аккаунта, нужно сначала добавить в ~/.aws/config профиль типа:
[profile devops-codecommit]
role_arn = arn:aws:iam::123456789012:role/codecommit-role
credential_source = Ec2InstanceMetadata
Параметры:
devops-codecommit…
[profile devops-codecommit]
role_arn = arn:aws:iam::123456789012:role/codecommit-role
credential_source = Ec2InstanceMetadata
Параметры:
devops-codecommit…
Allow + NotPrincipal
Стоит быть внимательным и не допускать использования связки
Где вы как бы хотите запретить доступ в бакет каким-то юзерам из каких-то аккаунтов.
В результате они (эти два юзера из примера выше) туда, действительно, не получат доступа. Однако кроме этого, незаметно, в бакет
https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_notprincipal.html#specifying-notprincipal-allow
Потому в общем случае всегда нужно использовать связку запретить+кроме (
#s3 #bucket_policy
Стоит быть внимательным и не допускать использования связки
Allow + NotPrincipal при написании S3 Bucket Policy, например, типа такого варианта:{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"NotPrincipal": {"AWS": [
"arn:aws:iam::111111111111:user/SomeUser1",
"arn:aws:iam::222222222222:user/SomeUser2"
]},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::my-bucket",
"arn:aws:s3:::my-bucket/*"
]
}]
}Где вы как бы хотите запретить доступ в бакет каким-то юзерам из каких-то аккаунтов.
В результате они (эти два юзера из примера выше) туда, действительно, не получат доступа. Однако кроме этого, незаметно, в бакет
my-bucket получат доступ не просто другие ваши пользователи, но и вообще все, включая гостей (anonymous users) из интернета!https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_notprincipal.html#specifying-notprincipal-allow
Потому в общем случае всегда нужно использовать связку запретить+кроме (
Deny+NotPrincipal).#s3 #bucket_policy
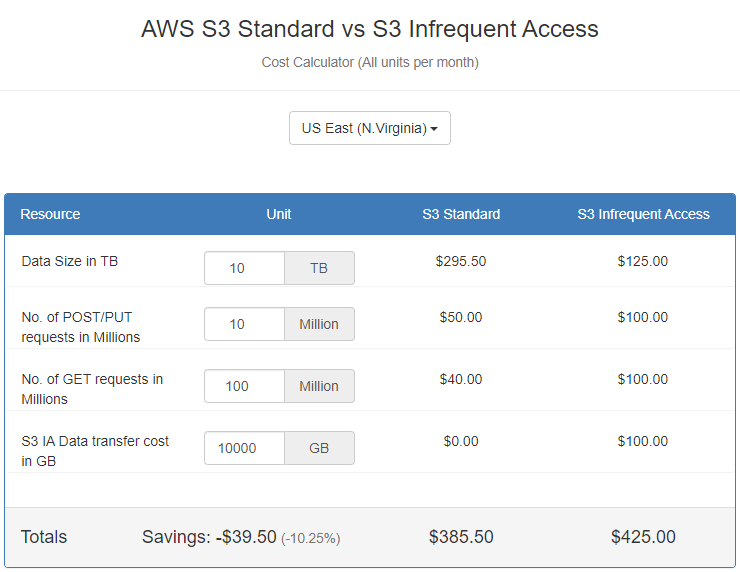
Когда вы желаете сэкономить на хранении данных в S3 с помощью перевода данных на S3 IA (Infrequent Access), который в два раза дешевле обычного (S3 Standard), обязательно учитывайте, что за получение данных из S3 IA взимается плата (1 цент каждый гигабайт в отличие от бесплатного трафика для S3 Standard).
Иначе может получиться как здесь:
https://fudless.xyz/aws/boom/
Для подсчёта выгодности - можно использовать специальный калькулятор S3 Standard vs S3 Infrequent Access:
https://www.gulamshakir.com/apps/s3calc/index.html
Аналогично в случае использования S3 Intelligent-Tiering — там сам Амазон автоматически переведёт данные из S3 IA в S3 Standard при первом же доступе к ним (и не получится так плачевно, как по первой ссылке), однако как раз и нужно учитывать, что транзит из одного типа в другой (Lifecycle Transition) также стоит денег:
https://aws.amazon.com/s3/pricing/
Итого: Амазон предлагает много разных и действенных способов сэкономить на хранилище данных в S3. Однако всё нужно применять, понимая, что делаешь.
И не стоит забывать, что лучший способ действительно сэкономить - удалить нафиг всё ненужное. Почти всегда это даёт на порядки большую экономию, чем высчитываение центов на калькуляторах типов хранения.
#s3 #cost_optimization
Иначе может получиться как здесь:
https://fudless.xyz/aws/boom/
Для подсчёта выгодности - можно использовать специальный калькулятор S3 Standard vs S3 Infrequent Access:
https://www.gulamshakir.com/apps/s3calc/index.html
Аналогично в случае использования S3 Intelligent-Tiering — там сам Амазон автоматически переведёт данные из S3 IA в S3 Standard при первом же доступе к ним (и не получится так плачевно, как по первой ссылке), однако как раз и нужно учитывать, что транзит из одного типа в другой (Lifecycle Transition) также стоит денег:
https://aws.amazon.com/s3/pricing/
Итого: Амазон предлагает много разных и действенных способов сэкономить на хранилище данных в S3. Однако всё нужно применять, понимая, что делаешь.
И не стоит забывать, что лучший способ действительно сэкономить - удалить нафиг всё ненужное. Почти всегда это даёт на порядки большую экономию, чем высчитываение центов на калькуляторах типов хранения.
#s3 #cost_optimization
{kind=link}
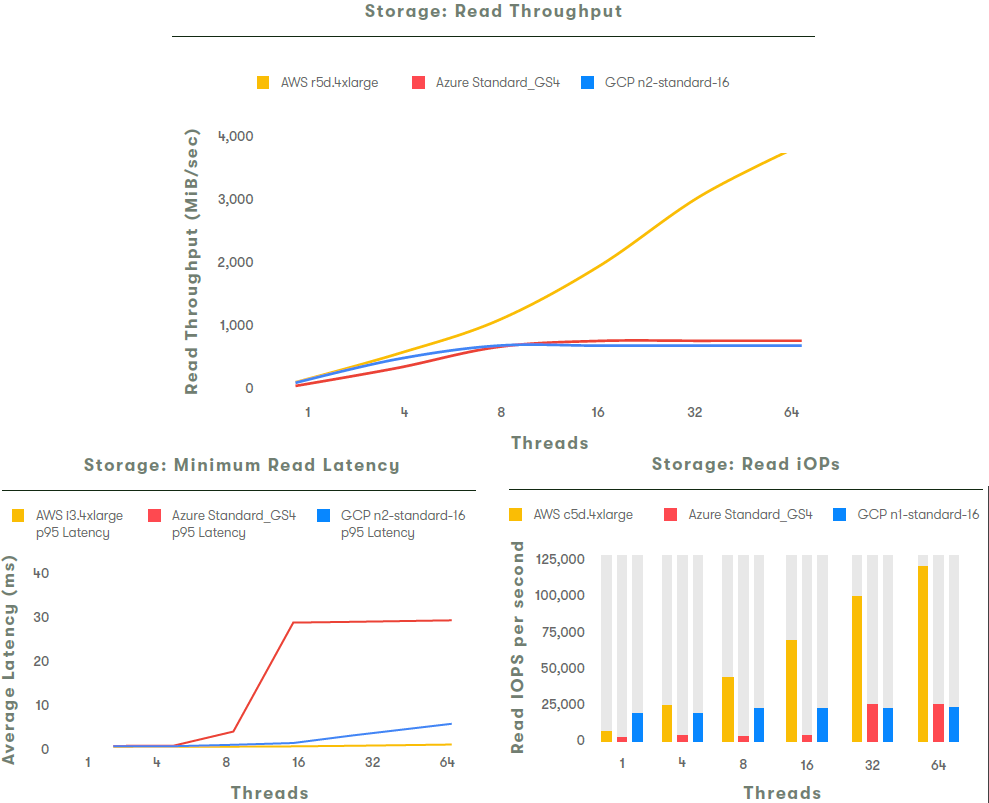
Тестов много не бывает - комплексное сравнение производительности различных подсистем AWS, Azure и GCP
у @tech_b0lt_Genona.
Если коротко, то AWS хорош, Azure неплох, а GCP растёт над собой.
#info #comparison
у @tech_b0lt_Genona.
Если коротко, то AWS хорош, Azure неплох, а GCP растёт над собой.
#info #comparison
{kind=link}
Простое понятно всем, а известное известно всем. Спойлер — нет, это не так.
Когда разбираешься с какой-то совсем новой для тебя темой, стараешься максимально подробно записывать, что делаешь, что непонятно и неочевидно. По опыту знаешь, что когда разберёшься — не сможешь и близко вспомнить, что же тут непонятного и неочевидного — вот же, так, здесь, смотри сюда, читай туда, делай так. Но ведь до этого, даже имея большой опыт подобных начинаний — было непонятно!
Когда варишься в какой-то области много лет, то кажется, что — ну, вы, конечно, знаете, это же всем известно, общеизвестный факт. Что значит, впервые слышите??? Как никогда? А как же вы проектировали свою систему, использовали этот сервис, настраивали безопасности, проводили аудит, занимались оптимизацией и не знали?!?
Первая часть — непонятность понятного — за много лет приучила, с одной стороны, рассказывать подробно и с нуля. А с другой, как было упомянуто выше — записывать всё во время освоения новой темы.
Комбинация этих двух вещей позволяет, в частности, появляться здесь материалам в бесконечном цикле. Ведь это просто отражение того, что записываю для себя, чтобы было а) больше шансов запомнить, б) больше шансов потом здесь же найти (т.к. всё запомнить невозможно).
Со второй частью сложней. Постоянно рассказывая про "известное всем" можно, с одной стороны, быстро вызвать раздражение у тех, кто это знает и тоже считает, что это "известно всем", "гуглится в один клик" и "есть на главной странице".
С другой стороны, когда кто-то впервые здесь прочитает, что такое есть, заинтересуется и узнает, поймёт, прокачается или успешно сдаст экзамен — как бы хорошо. Получается, что и этот вариант правильный.
К чему это я? Пытался найти баланс между технической детализацией, интересной самому по части AWS и "общеизвестными вещами", полезными тем, кто хочет узнать и разобраться или даже просто узнать, стоит ли разбираться.
Для этого, кто пропустил — здесь были опросы по уровню знаний AWS. Кто не нажимал — нажмите и/или посмотрите, как нажимали другие. В результате обычно, на теперь, получается, что более технически узкие и сложные вещи пишу в чате, а здесь уже главное-основное, что может заинтересовать большинство (хотя это не строгое правило).
В общем, с учётом вдруг осознанной важности донести известное всем до известности всех — впредь тут будет больше очевидного. Как-то так.
#пятничное
Когда разбираешься с какой-то совсем новой для тебя темой, стараешься максимально подробно записывать, что делаешь, что непонятно и неочевидно. По опыту знаешь, что когда разберёшься — не сможешь и близко вспомнить, что же тут непонятного и неочевидного — вот же, так, здесь, смотри сюда, читай туда, делай так. Но ведь до этого, даже имея большой опыт подобных начинаний — было непонятно!
Когда варишься в какой-то области много лет, то кажется, что — ну, вы, конечно, знаете, это же всем известно, общеизвестный факт. Что значит, впервые слышите??? Как никогда? А как же вы проектировали свою систему, использовали этот сервис, настраивали безопасности, проводили аудит, занимались оптимизацией и не знали?!?
Первая часть — непонятность понятного — за много лет приучила, с одной стороны, рассказывать подробно и с нуля. А с другой, как было упомянуто выше — записывать всё во время освоения новой темы.
Комбинация этих двух вещей позволяет, в частности, появляться здесь материалам в бесконечном цикле. Ведь это просто отражение того, что записываю для себя, чтобы было а) больше шансов запомнить, б) больше шансов потом здесь же найти (т.к. всё запомнить невозможно).
Со второй частью сложней. Постоянно рассказывая про "известное всем" можно, с одной стороны, быстро вызвать раздражение у тех, кто это знает и тоже считает, что это "известно всем", "гуглится в один клик" и "есть на главной странице".
С другой стороны, когда кто-то впервые здесь прочитает, что такое есть, заинтересуется и узнает, поймёт, прокачается или успешно сдаст экзамен — как бы хорошо. Получается, что и этот вариант правильный.
К чему это я? Пытался найти баланс между технической детализацией, интересной самому по части AWS и "общеизвестными вещами", полезными тем, кто хочет узнать и разобраться или даже просто узнать, стоит ли разбираться.
Для этого, кто пропустил — здесь были опросы по уровню знаний AWS. Кто не нажимал — нажмите и/или посмотрите, как нажимали другие. В результате обычно, на теперь, получается, что более технически узкие и сложные вещи пишу в чате, а здесь уже главное-основное, что может заинтересовать большинство (хотя это не строгое правило).
В общем, с учётом вдруг осознанной важности донести известное всем до известности всех — впредь тут будет больше очевидного. Как-то так.
#пятничное
{kind=link}
Есть места, где люди делятся своими страшными ошибками. И почти всегда это ужасно смешно.
---
eric gisse
what i'm doing here is hugely dangerous
needs to be done so w/e
oh. i have the best mistake for this channel
DO. NOT. DELETE. AN. RDS. NETWORK. INTERFACE.
you will put your RDS instance in an unrecoverable state
it is unknown if support can fix that
ajeffree
wait the network interface?
you mean the subnet group?
eric gisse
no, network interface
i stopped the db and got the galaxy brain idea to go on a resource purge because we have stuff that builds up but doesn't throw away
===
Итого - не переусердствуйте в стремлении максимально вычистить ресурсы. Не нужно (пожалуйста) удалять сетевой интерфейс остановленной RDS базы данных.
#субботничное
---
eric gisse
12:48 AMwhat i'm doing here is hugely dangerous
needs to be done so w/e
oh. i have the best mistake for this channel
DO. NOT. DELETE. AN. RDS. NETWORK. INTERFACE.
you will put your RDS instance in an unrecoverable state
it is unknown if support can fix that
ajeffree
1:17 AMwait the network interface?
you mean the subnet group?
eric gisse
1:18 AMno, network interface
i stopped the db and got the galaxy brain idea to go on a resource purge because we have stuff that builds up but doesn't throw away
===
Итого - не переусердствуйте в стремлении максимально вычистить ресурсы. Не нужно (пожалуйста) удалять сетевой интерфейс остановленной RDS базы данных.
#субботничное
{kind=link}
Изменение стоимости вычислительных ресурсов AWS во времени
Работая с Амазоном важно понимать особенности формирования цены на виртуалки.
На другие ресурсы (хранение, стоимость чего-то в месяц и т.п.) стоимость может меняться (падать) в, так сказать, обычном порядке — огласили снижение цена на xx%% и в конце месяца в счёт попадёт новая цена.
Стоимость же виртуалок, будучи купленными, уже не меняется (скидочные планы не в счёт). Как бы логично предполагать, что, как же так, выходят новые, более крутые процессоры, а цена не падает. А вот как раз и падает, об этом и нужно знать.
В общем случае снижение цены проходит следующим способом. Выходит новое поколение процессоров - более крутых с большими возможностями. И виртуалки аналогичного количества процессоров+памяти, только более нового поколения, стоят ч̶у̶т̶ь̶ ̶д̶о̶р̶о̶ж̶е̶ дешевле!
Возьмём конкретный пример. У вас крутится база данных PostgreSQL, логично предположить, что она может крутиться многими годам. Например, возьмём, что вы её сделали лет пять назад и тогда это был простой вариант 4 ядра + 16ГБ памяти + MultiAZ, а соответственно (тогда) это был тип
https://aws.amazon.com/rds/previous-generation/
Посмотрим стоимость такой конфигурации (
https://aws.amazon.com/rds/postgresql/pricing/
Как и было сказано ранее — цена падает. Новые виртуалки работают быстрей, эффективней и при этом дешевле!
Конечно, для того, чтобы получить такую выгоду, придётся обновить виртуалку, а рабочий прод никто трогать не хочет (плюс купленные ранее скидки не хочется терять).
Итого, факт — новое обычно дешевле и быстрей.
Или просто быстрей и стоит столько же, как, например, EC2 типы T2 и T3, которые стоят одинаково, в то время, как T3 на более новых и быстрых процессорах (а на самых мелких виртуалках у T3 два vCPU против одного у T2).
#cost_optimization
Работая с Амазоном важно понимать особенности формирования цены на виртуалки.
На другие ресурсы (хранение, стоимость чего-то в месяц и т.п.) стоимость может меняться (падать) в, так сказать, обычном порядке — огласили снижение цена на xx%% и в конце месяца в счёт попадёт новая цена.
Стоимость же виртуалок, будучи купленными, уже не меняется (скидочные планы не в счёт). Как бы логично предполагать, что, как же так, выходят новые, более крутые процессоры, а цена не падает. А вот как раз и падает, об этом и нужно знать.
В общем случае снижение цены проходит следующим способом. Выходит новое поколение процессоров - более крутых с большими возможностями. И виртуалки аналогичного количества процессоров+памяти, только более нового поколения, стоят ч̶у̶т̶ь̶ ̶д̶о̶р̶о̶ж̶е̶ дешевле!
Возьмём конкретный пример. У вас крутится база данных PostgreSQL, логично предположить, что она может крутиться многими годам. Например, возьмём, что вы её сделали лет пять назад и тогда это был простой вариант 4 ядра + 16ГБ памяти + MultiAZ, а соответственно (тогда) это был тип
db.m3.xlarge.https://aws.amazon.com/rds/previous-generation/
Посмотрим стоимость такой конфигурации (
db.m3.xlarge), как она изменялась со временем и чему равна сейчас (без скидок и в N.Virginia):https://aws.amazon.com/rds/postgresql/pricing/
db.m3.xlarge = $0.78db.m4.xlarge = $0.73db.m5.xlarge = $0.712Как и было сказано ранее — цена падает. Новые виртуалки работают быстрей, эффективней и при этом дешевле!
Конечно, для того, чтобы получить такую выгоду, придётся обновить виртуалку, а рабочий прод никто трогать не хочет (плюс купленные ранее скидки не хочется терять).
Итого, факт — новое обычно дешевле и быстрей.
Или просто быстрей и стоит столько же, как, например, EC2 типы T2 и T3, которые стоят одинаково, в то время, как T3 на более новых и быстрых процессорах (а на самых мелких виртуалках у T3 два vCPU против одного у T2).
#cost_optimization
Amazon
Amazon RDS Previous Generation Instances Pricing | AWS
AWS offers previous generation DB instances for users who have optimized their applications around these instances and have yet to upgrade. Previous generation DB instances are still fully supported and retain the same features and functionality. Previous…
SpeedTest для Amazon S3 Transfer Acceleration
https://s3-accelerate-speedtest.s3-accelerate.amazonaws.com/en/accelerate-speed-comparsion.html
Показывает отличие обычной загрузки в бакет от ускоренной:
https://docs.aws.amazon.com/AmazonS3/latest/dev/transfer-acceleration.html
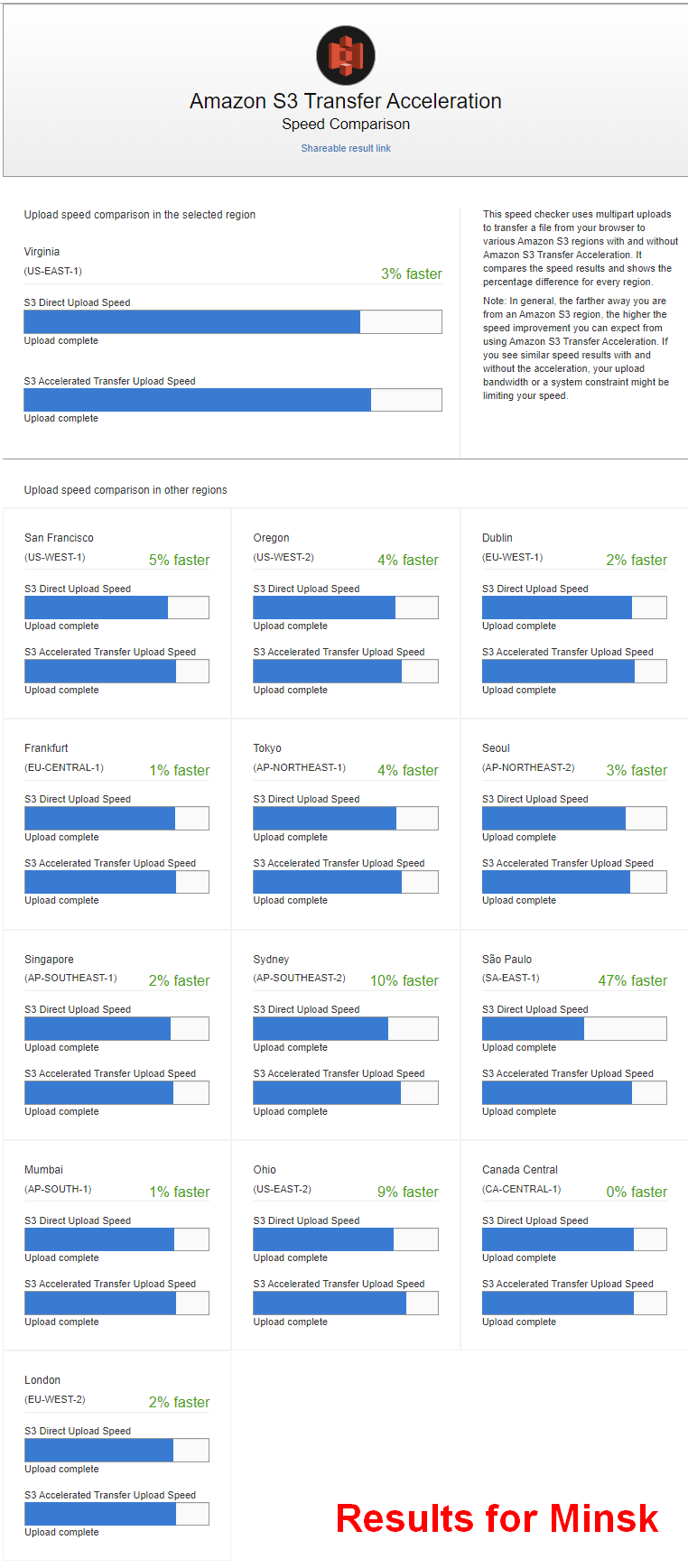
Особой ценности не представляет, т.к. чаще бакет накрыт с помощью CloudFront. Однако кому нужно - позволяет быстро понять, для каких регионов и сколько может добавить в скорости.
На картинке результаты для Минска, видно, что с большинством регионов разницы нет (единицы процентов). Однако для далёких регионов (Австралия и особенно Бразилия) - результаты хорошо показывают, что значит, когда работа идёт по инфраструктуре Амазона, а не через "весь интернет".
#s3 #info
https://s3-accelerate-speedtest.s3-accelerate.amazonaws.com/en/accelerate-speed-comparsion.html
Показывает отличие обычной загрузки в бакет от ускоренной:
https://docs.aws.amazon.com/AmazonS3/latest/dev/transfer-acceleration.html
Особой ценности не представляет, т.к. чаще бакет накрыт с помощью CloudFront. Однако кому нужно - позволяет быстро понять, для каких регионов и сколько может добавить в скорости.
На картинке результаты для Минска, видно, что с большинством регионов разницы нет (единицы процентов). Однако для далёких регионов (Австралия и особенно Бразилия) - результаты хорошо показывают, что значит, когда работа идёт по инфраструктуре Амазона, а не через "весь интернет".
#s3 #info
{kind=link}
Главное за три года на AWS
Когда вы освоили AWS в достаточной мере, имеете не один год опыта, сдали на AWS сертификацию (всё это вместе или по отдельности), то можете работать, успешно, долго, на базе уже имеющегося опыта и знаний. Следить за обновлениями, которые выходят тысячами в год, от некогда до незачем — у вас в бэклоге и так на месяцы вперёд работы, куда тут отвлекаться.
Работая в таком ритме годами, с одной стороны, вы как бы приобретаете опыт и растёте, как профессионал в своей области. С другой, если совсем не следить за изменениями — деградируете в профессиональном аспекте. На выходе такой ситуации часто рождается конфликт между "old school подходом" (когда вы на базе своего опыта реализуете всё на "проверенных временем" схемах) и "хипстерскими" стильно-модно-молодёжными технологиями, которые пытаются продвигать новички в области вашей деятельности.
Не пытаясь холиварить на эту тему (old school против хипстеров — хотя сам на стороне последних), правильней лучше выбрать и рассказать про самое важное, что произошло за последние три года на Амазоне. Из тысячи апдейтов разной степени важности, выделить обязательные к ознакомлению, которые принципиально меняют подходы, работу AWS и работу с AWS.
---
Главное на AWS за 2017-2018-2019 — деньги (скидки)
---
Начнём с денег. Чтобы экономить на оплате постоянно работающих виртуалок, вот уже больше десяти лет использовались Reserved Instances. Это когда вы покупаете скидки на 1 или 3 года на какой-то тип виртуалок в каком-то регионе, взамен на гарантию, что будете пользоваться ими (верней - оплачивать) всё это время.
Так вот, Reserved Instances (RI) — всё, они в прошлом, их заменили Savings Plans:
https://aws.amazon.com/blogs/aws/new-savings-plans-for-aws-compute-services/
RI продолжают действовать, но смысла покупать новые нет, так как справедлива следующая формула перехода:
Standard RI
Convertible RI
Для тех, кто не имел опыта с RI — теперь незачем его получать. Смело берите (ориентируйтесь на) Compute Savings Plans и читайте уже про него. Кто захочет разобраться — вот подробное видео по Savings Plans:
https://www.youtube.com/watch?v=uQ9ry-9uUvo
В этом видео ещё нет того факта, что в этом году в Compute Savings Plans добавлены и Лямбды, что делает его (Compute Savings Plans) ещё более крутым.
Итого, главное по деньгам (скидкам) на AWS за последние 3 года — Reserved Instances умерли, да здравствует Savings Plans!
#главное #cost_optimization
Когда вы освоили AWS в достаточной мере, имеете не один год опыта, сдали на AWS сертификацию (всё это вместе или по отдельности), то можете работать, успешно, долго, на базе уже имеющегося опыта и знаний. Следить за обновлениями, которые выходят тысячами в год, от некогда до незачем — у вас в бэклоге и так на месяцы вперёд работы, куда тут отвлекаться.
Работая в таком ритме годами, с одной стороны, вы как бы приобретаете опыт и растёте, как профессионал в своей области. С другой, если совсем не следить за изменениями — деградируете в профессиональном аспекте. На выходе такой ситуации часто рождается конфликт между "old school подходом" (когда вы на базе своего опыта реализуете всё на "проверенных временем" схемах) и "хипстерскими" стильно-модно-молодёжными технологиями, которые пытаются продвигать новички в области вашей деятельности.
Не пытаясь холиварить на эту тему (old school против хипстеров — хотя сам на стороне последних), правильней лучше выбрать и рассказать про самое важное, что произошло за последние три года на Амазоне. Из тысячи апдейтов разной степени важности, выделить обязательные к ознакомлению, которые принципиально меняют подходы, работу AWS и работу с AWS.
---
Главное на AWS за 2017-2018-2019 — деньги (скидки)
---
Начнём с денег. Чтобы экономить на оплате постоянно работающих виртуалок, вот уже больше десяти лет использовались Reserved Instances. Это когда вы покупаете скидки на 1 или 3 года на какой-то тип виртуалок в каком-то регионе, взамен на гарантию, что будете пользоваться ими (верней - оплачивать) всё это время.
Так вот, Reserved Instances (RI) — всё, они в прошлом, их заменили Savings Plans:
https://aws.amazon.com/blogs/aws/new-savings-plans-for-aws-compute-services/
RI продолжают действовать, но смысла покупать новые нет, так как справедлива следующая формула перехода:
Standard RI
= EC2 Instance Savings Plans (та же максимальная скидка 72%)Convertible RI
= Compute Savings Plans (та же максимальная скидка 66%)Для тех, кто не имел опыта с RI — теперь незачем его получать. Смело берите (ориентируйтесь на) Compute Savings Plans и читайте уже про него. Кто захочет разобраться — вот подробное видео по Savings Plans:
https://www.youtube.com/watch?v=uQ9ry-9uUvo
В этом видео ещё нет того факта, что в этом году в Compute Savings Plans добавлены и Лямбды, что делает его (Compute Savings Plans) ещё более крутым.
Итого, главное по деньгам (скидкам) на AWS за последние 3 года — Reserved Instances умерли, да здравствует Savings Plans!
#главное #cost_optimization
YouTube
AWS re:Invent 2019: [REPEAT 1] Dive deep on how to save with AWS Savings Plans (CMP210-R1)
Savings Plans is a new flexible pricing model that provides savings of up to 72 percent on Amazon EC2 and AWS Fargate usage. Savings Plans offers significant savings over On Demand, just like Reserved Instances, but automatically reduces your bills on compute…
RDS RI
В дополнение по RI нужно упомянуть про RDS Reserved Instances (RDS RI) — это как RI для EC2, только для RDS (спасибо, Кэп). Главное, что они разные (покупать-резервировать нужно отдельно и в разных местах, цены немножко отличаются) и по внедрению фич RDS RI отстают от EC2 RI. В частности потому RDS RI (как минимум пока) всё ещё актуальны (в отличие от EC2 RI, которые заменены на Savings Plans).
В 2017-м году RDS RI получили важное свойство (вслед за "обычными" RI) — Instance Size Flexibility:
https://aws.amazon.com/rds/reserved-instances/#Reserved_Instance_Size_Flexibility
Это если вы сейчас купите трёхлетнюю скидку на базу
1. Докупить ещё одну скидку на 1 или 3 года на такую же
2. Ничего не делать и тогда к счёту вашей будущей
Также стоит отметить важное свойство RI (справедливо и для EC2 RI, и для RDS RI, и для Savings Plans), что скидки применяются на все аккаунты вашей организации. То есть будучи купленными в мастер-аккаунте, все доступные скидки применятся и для всех подаккаунтов.
Итого по RDS RI — отдельный тип RI, скидка "самомасштабируется" по всей линейке одного семейства (одного региона) и применяется ко всем аккаунтам организации.
#главное #cost_optimization #RDS #RI
В дополнение по RI нужно упомянуть про RDS Reserved Instances (RDS RI) — это как RI для EC2, только для RDS (спасибо, Кэп). Главное, что они разные (покупать-резервировать нужно отдельно и в разных местах, цены немножко отличаются) и по внедрению фич RDS RI отстают от EC2 RI. В частности потому RDS RI (как минимум пока) всё ещё актуальны (в отличие от EC2 RI, которые заменены на Savings Plans).
В 2017-м году RDS RI получили важное свойство (вслед за "обычными" RI) — Instance Size Flexibility:
https://aws.amazon.com/rds/reserved-instances/#Reserved_Instance_Size_Flexibility
Это если вы сейчас купите трёхлетнюю скидку на базу
db.m5.xlarge, а через годик набегут клиенты и потребуется её мощность увеличить, например, до db.m5.2xlarge, то у вас будут следующие варианты:1. Докупить ещё одну скидку на 1 или 3 года на такую же
db.m5.xlarge и они вдвоём будут давать скидку на db.m5.2xlarge. То есть скидки db.m5.xlarge+db.m5.xlarge=db.m5.2xlarge2. Ничего не делать и тогда к счёту вашей будущей
db.m5.2xlarge применится скидка лишь на её половину (но применится, а не пропадёт).Также стоит отметить важное свойство RI (справедливо и для EC2 RI, и для RDS RI, и для Savings Plans), что скидки применяются на все аккаунты вашей организации. То есть будучи купленными в мастер-аккаунте, все доступные скидки применятся и для всех подаккаунтов.
Итого по RDS RI — отдельный тип RI, скидка "самомасштабируется" по всей линейке одного семейства (одного региона) и применяется ко всем аккаунтам организации.
#главное #cost_optimization #RDS #RI
Amazon
Hosted PostgreSQL - Amazon RDS for PostgreSQL - AWS
Host, scale and manage your PostgreSQL deployments in the cloud with Amazon RDS for PostgreSQL.
Anonymous Poll
16%
1-5
19%
5-10
33%
10-20
19%
20-50
7%
50-100
6%
100+
Если какие-то ваши сервисы по безопасности сканируют все регионы, то возникает вопрос — а что будет, когда, вот, вскоре, откроется новый регион Италия-Милан? Как учитывать такой факт, чтобы враги не просочились через вновь возникший новый AWS регион?
Ответ был дан год назад, когда с марта прошлого года все новые регионы отключены по умолчанию, а чтобы их включить, нужно их включать явно самому:
https://aws.amazon.com/blogs/security/setting-permissions-to-enable-accounts-for-upcoming-aws-regions/
Потому за новые регионы в этом плане можно не переживать. А чтобы запретить старые-имеющиеся — можно использовать SCP.
#security #AWS_Regions
Ответ был дан год назад, когда с марта прошлого года все новые регионы отключены по умолчанию, а чтобы их включить, нужно их включать явно самому:
https://aws.amazon.com/blogs/security/setting-permissions-to-enable-accounts-for-upcoming-aws-regions/
Потому за новые регионы в этом плане можно не переживать. А чтобы запретить старые-имеющиеся — можно использовать SCP.
#security #AWS_Regions
{kind=link}
Главное на Амазоне за 2017-2018-2019 — AWS Organizations
От денег перейдём к организационной структуре. За это время с "верхнеуровневой" частью управления компанией на Амазоне поменялось ПОЛНОСТЬЮ ВСЁ — три года назад появился сервис AWS Organizations.
https://aws.amazon.com/organizations/
И если про AWS Organizations вы не слышали или если и слышали, то не особо вникали и не пользовались, то знайте — вы совсем не понимаете, как (теперь) работает AWS.
AWS Organizations — базовый элемент для обеспечения безопасности, современный проект вряд ли пройдёт аудит без использования Organizations, а при наличии каких-то Compliance требований вообще просто без шансов. Это опуская все моменты, которые AWS Organizations даёт по работе в увеличению эффективности работы - как на уровне управления командами и проектами, так и по части эффективного использования ресурсов и их оплаты.
Тут часто упоминались и будет упоминаться термин #Multi_Account_Strategy или просто "мульти-аккаунты", который есть немного жаргонное обозначение использования AWS Organizations. Кто не видел — можно посмотреть это видео по мультиаккаунтам.
Если всё равно не ясно, для чего AWS Organizations, то приведу следующую аналогию (для кого-то грубую и спорную). Относиться к использованию мультиаккаунтов (AWS Organizations) — это примерно как многие до сих пор относятся к докерам (правильней — контейнеризации вообще). Называя это "лишним уровнем абстракции", "потерей производительности" и "прочей ленью разработчиков, неспособных разобраться с зависимостями".
Неверующие в докер не заметили, как вся индустрия де-факто переходит/перешла на использование контейнеризации чуть меньше, чем везде. И если для поддержки старых проектов понятно, то для реализации новых, без контейнеризации — это изначально закладывать отставание от других и последующую переделку.
Аналогично и AWS Organizations, не используя мульти-аккаунт подход — вы остаёте. Безопасность, эффективность, управляемость, а точней, их отсутствие (что невозможно на сегодняшнем Амазоне без AWS Organizations) — радикально уменьшают шансы на успех вашего стартапа.
Переход на мульти-аккаунт схему требует времени, ресурсов, знаний. Равно как и, в своё время, требовал затрат переход на Docker, CI/CD, IaC, Kubernetes и другие современные подходы, которые на выходе дают большую гибкость, скорость, эффективность.
Итого по организации. Три года назад завезли совсем другой Амазон. Если вы этого не заметили — разберитесь и используйте AWS Organizations. Без него сейчас никак. Он теперь такой же базовый, как S3.
#главное #Organizations
От денег перейдём к организационной структуре. За это время с "верхнеуровневой" частью управления компанией на Амазоне поменялось ПОЛНОСТЬЮ ВСЁ — три года назад появился сервис AWS Organizations.
https://aws.amazon.com/organizations/
И если про AWS Organizations вы не слышали или если и слышали, то не особо вникали и не пользовались, то знайте — вы совсем не понимаете, как (теперь) работает AWS.
AWS Organizations — базовый элемент для обеспечения безопасности, современный проект вряд ли пройдёт аудит без использования Organizations, а при наличии каких-то Compliance требований вообще просто без шансов. Это опуская все моменты, которые AWS Organizations даёт по работе в увеличению эффективности работы - как на уровне управления командами и проектами, так и по части эффективного использования ресурсов и их оплаты.
Тут часто упоминались и будет упоминаться термин #Multi_Account_Strategy или просто "мульти-аккаунты", который есть немного жаргонное обозначение использования AWS Organizations. Кто не видел — можно посмотреть это видео по мультиаккаунтам.
Если всё равно не ясно, для чего AWS Organizations, то приведу следующую аналогию (для кого-то грубую и спорную). Относиться к использованию мультиаккаунтов (AWS Organizations) — это примерно как многие до сих пор относятся к докерам (правильней — контейнеризации вообще). Называя это "лишним уровнем абстракции", "потерей производительности" и "прочей ленью разработчиков, неспособных разобраться с зависимостями".
Неверующие в докер не заметили, как вся индустрия де-факто переходит/перешла на использование контейнеризации чуть меньше, чем везде. И если для поддержки старых проектов понятно, то для реализации новых, без контейнеризации — это изначально закладывать отставание от других и последующую переделку.
Аналогично и AWS Organizations, не используя мульти-аккаунт подход — вы остаёте. Безопасность, эффективность, управляемость, а точней, их отсутствие (что невозможно на сегодняшнем Амазоне без AWS Organizations) — радикально уменьшают шансы на успех вашего стартапа.
Переход на мульти-аккаунт схему требует времени, ресурсов, знаний. Равно как и, в своё время, требовал затрат переход на Docker, CI/CD, IaC, Kubernetes и другие современные подходы, которые на выходе дают большую гибкость, скорость, эффективность.
Итого по организации. Три года назад завезли совсем другой Амазон. Если вы этого не заметили — разберитесь и используйте AWS Organizations. Без него сейчас никак. Он теперь такой же базовый, как S3.
#главное #Organizations
YouTube
Мульти-аккаунт стратегия: плюсы, минусы, подводные камни
Доклад на AWS Meetup Minsk 2019.
Использование мульти-аккаунт стратегии в реальной жизни — что даёт, что неудобно и чем грозит.
Использование мульти-аккаунт стратегии в реальной жизни — что даёт, что неудобно и чем грозит.
Amazon ElastiCache for Redis глобализировался
Теперь можно создать две дополнительные Read-реплики в других регионах:
https://aws.amazon.com/blogs/aws/now-available-amazon-elasticache-global-datastore-for-redis/
В случае проблем с регионом, где живёт Primary-кластер, любой из дополнительных кластеров Read-реплик, может стать полноценным Read-Write Primary cluster.
#ElastiCache #Redis
Теперь можно создать две дополнительные Read-реплики в других регионах:
https://aws.amazon.com/blogs/aws/now-available-amazon-elasticache-global-datastore-for-redis/
В случае проблем с регионом, где живёт Primary-кластер, любой из дополнительных кластеров Read-реплик, может стать полноценным Read-Write Primary cluster.
#ElastiCache #Redis
Amazon
Now Available: Amazon ElastiCache Global Datastore for Redis | Amazon Web Services
In-memory data stores are widely used for application scalability, and developers have long appreciated their benefits for storing frequently accessed data, whether volatile or persistent. Systems like Redis help decouple databases and backends from incoming…
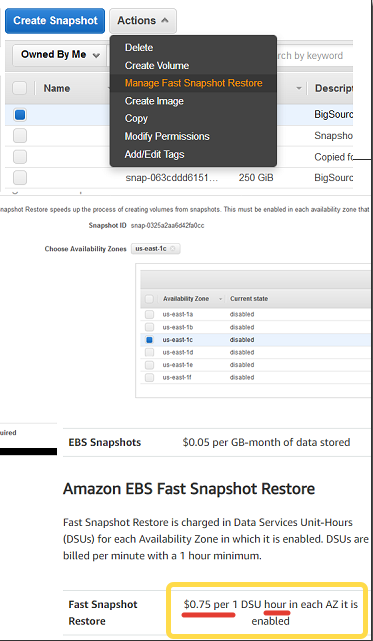
Если вы обнаружили в консоли новую фичу Amazon EBS Fast Snapshot Restore:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-fast-snapshot-restore.html
Решили потестировать и спокойно закрыли, предполагая, что раз больше не будете пользоваться, значит и денег она не ест, то нет. Ест и неслабо — 540$ в месяц!
https://aws.amazon.com/ebs/pricing/
Т.к. оплата не за штуки снэпшотов, а это почасовая фича, которая ест деньги, пока включена для каждой подзоны. Для использования рекомендуется автоматизировать процесс включения, оплаты за минимальный час (или сколько потребуется) и последующей деактивациии.
Итого — выключайте свет и незнакомые фичи, когда покидаете помещение.
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-fast-snapshot-restore.html
Решили потестировать и спокойно закрыли, предполагая, что раз больше не будете пользоваться, значит и денег она не ест, то нет. Ест и неслабо — 540$ в месяц!
https://aws.amazon.com/ebs/pricing/
Т.к. оплата не за штуки снэпшотов, а это почасовая фича, которая ест деньги, пока включена для каждой подзоны. Для использования рекомендуется автоматизировать процесс включения, оплаты за минимальный час (или сколько потребуется) и последующей деактивациии.
Итого — выключайте свет и незнакомые фичи, когда покидаете помещение.
{kind=link}