
Просто оставлю это здесь - интересная утилита, реализующая traffic mirroring:
https://github.com/buger/goreplay
Кому интересно, чуть расшифрую (не про Амазон).
Тестирование почти всегда проводится какими-то искусственными паттернами, которые должны при это дать некую гарантию, что на проде при реальной нагрузке оно не поломается. А метод traffic mirroring (или shadow traffic) дублирует реальный трафик, пришедший на прод в нужное вам (тестовое) окружение.
Это очень круто - иметь возможность тестировать "живым" трафиком. Модная тема, особенно легко реализуемая с помощью #kubernetes, так что советую как минимум знать про это - сие есть следующая инкарнация подходов Blue/Green или Canary Deployment.
https://github.com/buger/goreplay
Кому интересно, чуть расшифрую (не про Амазон).
Тестирование почти всегда проводится какими-то искусственными паттернами, которые должны при это дать некую гарантию, что на проде при реальной нагрузке оно не поломается. А метод traffic mirroring (или shadow traffic) дублирует реальный трафик, пришедший на прод в нужное вам (тестовое) окружение.
Это очень круто - иметь возможность тестировать "живым" трафиком. Модная тема, особенно легко реализуемая с помощью #kubernetes, так что советую как минимум знать про это - сие есть следующая инкарнация подходов Blue/Green или Canary Deployment.
{kind=link}
Nested Stacks
Не один год используя Nested Stacks , могу посоветовать - никогда не используйте #nested_stacks. Хуже #nested_stacks может быть лишь #nested_stacks на JSON.
Когда-то давно появление #nested_stacks казалось серьёзным шагом вперёд в попытке получения хоть какой-то модульности в #CloudFormation #templates, где до этого приходилось постоянно дублировать повторяющиеся части кода в шаблонах, отличающихся лишь малой частью ресурсов. Однако реальная эксплуатация показала, что с ростом сложности проекта, глубины и количества Nested Stacks, разрабатываться, сопровождать и обновлять его становится от сложно до невозможно.
Это потому, что для передачи параметров используется главный стэк, а запуская его на обновление, если у тебя отвалится что-то на энном обновляемом по уровню стэке, то сработает откат, который должен будет вернуть к предыдущему состоянию (успешно) обновившиеся до этого стэки, что банально не всегда возможно. Т.е. с постоянным усложнением проекта вам приходится быть как на картинке внизу.
Другая важная проблема, что из-за передачи переменных в низлежащие стэки через главный стэк, вы очень скоро можете попасть в ограничение на количество переменных, которое равно 60. Это для одного стэка кажется достаточным, но когда у вас даже пять-шесть вложенных стэков, то десяток переменных на каждого может сразу же исчерпают этот лимит.
Потому рекомендация одна - избегайте #nested_stacks. Они применимы лишь в примитивных случаях. Появление Import/Export функционала в CloudFormation практически убило какие-то реальные кейсы использования #nested_stacks. Если же вам досталась это чудо по наследству и вы попали на ограничение по количеству параметров (а вам нужно добавить новые) - используйте SSM параметры, передавая переменные через них.
Не один год используя Nested Stacks , могу посоветовать - никогда не используйте #nested_stacks. Хуже #nested_stacks может быть лишь #nested_stacks на JSON.
Когда-то давно появление #nested_stacks казалось серьёзным шагом вперёд в попытке получения хоть какой-то модульности в #CloudFormation #templates, где до этого приходилось постоянно дублировать повторяющиеся части кода в шаблонах, отличающихся лишь малой частью ресурсов. Однако реальная эксплуатация показала, что с ростом сложности проекта, глубины и количества Nested Stacks, разрабатываться, сопровождать и обновлять его становится от сложно до невозможно.
Это потому, что для передачи параметров используется главный стэк, а запуская его на обновление, если у тебя отвалится что-то на энном обновляемом по уровню стэке, то сработает откат, который должен будет вернуть к предыдущему состоянию (успешно) обновившиеся до этого стэки, что банально не всегда возможно. Т.е. с постоянным усложнением проекта вам приходится быть как на картинке внизу.
Другая важная проблема, что из-за передачи переменных в низлежащие стэки через главный стэк, вы очень скоро можете попасть в ограничение на количество переменных, которое равно 60. Это для одного стэка кажется достаточным, но когда у вас даже пять-шесть вложенных стэков, то десяток переменных на каждого может сразу же исчерпают этот лимит.
Потому рекомендация одна - избегайте #nested_stacks. Они применимы лишь в примитивных случаях. Появление Import/Export функционала в CloudFormation практически убило какие-то реальные кейсы использования #nested_stacks. Если же вам досталась это чудо по наследству и вы попали на ограничение по количеству параметров (а вам нужно добавить новые) - используйте SSM параметры, передавая переменные через них.
Если потребуется скопировать код из этого канала, а на компе телеграм не стоит, то можно использовать доступный веб-адрес:
https://t.iss.one/s/aws_notes
https://t.iss.one/s/aws_notes
Amazon Linux
Первые несколько лет своей амазоновской жизни я прочно сидел на Debian, после перебрался на Centos, продолжая вместе со многими и сейчас мужественно игнорировать Amazon Linux.
Однако со временем я стал замечать, что использовать #amazon_linux совсем не больно. Мало того, чем более "амазон-центричен" был проект, тем меньше зависимости от ОС вообще и тем более удобно использовать #amazon_linux, где есть основное, а нужное стоит из коробки (aws-cli сотоварищи).
С приходом докера использовать (в качестве образа для виртуалок) не #amazon_linux стало вообще бессмысленно - всё ОС-специфичное упаковано в докер. Потому #best_practices стало использование дефолтного последнего #amazon_linux (на текущий момент это Amazon Linux 2 LTS), где ставится минимум (идеально ничего) и который регулярно обновляется (в идеале автоматически при каждом обновлении и/или по расписанию).
Первые несколько лет своей амазоновской жизни я прочно сидел на Debian, после перебрался на Centos, продолжая вместе со многими и сейчас мужественно игнорировать Amazon Linux.
Однако со временем я стал замечать, что использовать #amazon_linux совсем не больно. Мало того, чем более "амазон-центричен" был проект, тем меньше зависимости от ОС вообще и тем более удобно использовать #amazon_linux, где есть основное, а нужное стоит из коробки (aws-cli сотоварищи).
С приходом докера использовать (в качестве образа для виртуалок) не #amazon_linux стало вообще бессмысленно - всё ОС-специфичное упаковано в докер. Потому #best_practices стало использование дефолтного последнего #amazon_linux (на текущий момент это Amazon Linux 2 LTS), где ставится минимум (идеально ничего) и который регулярно обновляется (в идеале автоматически при каждом обновлении и/или по расписанию).
Некоторые операции в AWS консоли требуют именно рута (т.е. нужно логиниться как #root_user). Чтобы не гуглить в поисках объяснения, почему у вас в консоли нет какой-то вещи, в то время, как в документации или какой-то статье она есть, то стоит периодически заходить сюда:
https://docs.aws.amazon.com/general/latest/gr/aws_tasks-that-require-root.html
Например, это будет полезно, если вы вдруг захотите включить мегазащиту MFA Delete на свой бакет с нажитыми за долгие годы бесценными логами или срочно потребуется посмотреть в консоли Account Canonical User ID (он же #s3_canonical) — всё это также должно делаться из-под рута.
https://docs.aws.amazon.com/general/latest/gr/aws_tasks-that-require-root.html
Например, это будет полезно, если вы вдруг захотите включить мегазащиту MFA Delete на свой бакет с нажитыми за долгие годы бесценными логами или срочно потребуется посмотреть в консоли Account Canonical User ID (он же #s3_canonical) — всё это также должно делаться из-под рута.
Amazon
AWS account root user - AWS Identity and Access Management
Manage the root user for an AWS account, including changing its password, and creating and removing access keys.
#ECR-репозиторий имеет ограничение в 1000 образов максимум. Когда у вас активный процесс разработки, то этот кажущийся большим лимит очень даже быстро достигается и вы получаете много удовольствия от упражнений по изучению логов под названием "ну вчера же работало".
Даже если лимит не проблема, то бардак из тьмы билдов (обычно на каждую ветку) обеспечен плюс некоторые расходы, но они минимальны (хотя, конечно, зависит от размеров образов).
Светлая мысль "с этим что-то нужно делать" помноженная на гугление в попытках что-то найти и отсортировать в AWS консоли по работе с ECR докер-образами — очень скоро приведёт вас в уныние. Не расстраивайтесь, это не вы верблюд - там действительно не работает пэйджер (фильтры применяются лишь к одной странице). Пусть вас успокаивает факт, что они страдают точно также.
В общем смысл следующий - нужно настроить ECR LifecyclePolicy. Пишем правила, какие тэги сколько живут и добавляем каждому репозиторию, в результате порядок будет поддерживаться автоматически.
Если репозиторий один, то можно и потыкать ручками, однако если десятки? Тогда используем для этого секретную менюшку Edit JSON (на картинке внизу), откуда можно скопировать натыканное и размножить для других репозиториев.
Тяжело разбираться без примеров, потому вот реально используемый вариант #LifecyclePolicy:
Даже если лимит не проблема, то бардак из тьмы билдов (обычно на каждую ветку) обеспечен плюс некоторые расходы, но они минимальны (хотя, конечно, зависит от размеров образов).
Светлая мысль "с этим что-то нужно делать" помноженная на гугление в попытках что-то найти и отсортировать в AWS консоли по работе с ECR докер-образами — очень скоро приведёт вас в уныние. Не расстраивайтесь, это не вы верблюд - там действительно не работает пэйджер (фильтры применяются лишь к одной странице). Пусть вас успокаивает факт, что они страдают точно также.
В общем смысл следующий - нужно настроить ECR LifecyclePolicy. Пишем правила, какие тэги сколько живут и добавляем каждому репозиторию, в результате порядок будет поддерживаться автоматически.
Если репозиторий один, то можно и потыкать ручками, однако если десятки? Тогда используем для этого секретную менюшку Edit JSON (на картинке внизу), откуда можно скопировать натыканное и размножить для других репозиториев.
Тяжело разбираться без примеров, потому вот реально используемый вариант #LifecyclePolicy:
{
"rules": [
{
"action": {
"type": "expire"
},
"selection": {
"countType": "sinceImagePushed",
"countUnit": "days",
"countNumber": 180,
"tagStatus": "tagged",
"tagPrefixList": [
"develop"
]
},
"description": "clean 'develop*' after 180 days",
"rulePriority": 10
},
{
"action": {
"type": "expire"
},
"selection": {
"countType": "sinceImagePushed",
"countUnit": "days",
"countNumber": 180,
"tagStatus": "tagged",
"tagPrefixList": [
"feature"
]
},
"description": "clean 'feature*' after 180 days",
"rulePriority": 20
},
{
"action": {
"type": "expire"
},
"selection": {
"countType": "sinceImagePushed",
"countUnit": "days",
"countNumber": 180,
"tagStatus": "tagged",
"tagPrefixList": [
"hotfix"
]
},
"description": "clean 'hotfix*' after 180 days",
"rulePriority": 30
},
{
"action": {
"type": "expire"
},
"selection": {
"countType": "sinceImagePushed",
"countUnit": "days",
"countNumber": 1,
"tagStatus": "untagged"
},
"description": "clean Untagged after 1 day",
"rulePriority": 40
}
]
}{kind=link}
В дополнение к предыдущему посту по #ECR #LifecyclePolicy - в идеале такое должно быть автоматизировано с помощью #CloudFormation #templates.
Это не всегда реально: например, какой-то старый проект, нельзя пересоздать репозитории. Но если можно пересоздать - чтобы репозиторием рулил CloudFormation или для нового проекта, то это получается реально удобно. Создаём репозитории с помощью шаблона типа:
https://github.com/applerom/cloudformation-examples/blob/master/ecs/ecr-repo.yml
Как видно в шаблоне - LifecyclePolicy прописывается в чистом виде (JSON). Там же для удобства добавлен шаринг для других аккаунтов, что всегда требуется в случае #multi_account_strategy (если не нужен - просто комментируем). Всё легко кастомизируется под свои значения и любимые скрипты.
Если нужно быстро — просто ручками меняем шаблон и запускаем/обновляем стэк. В любом случае это правильней, чем тыкать через консоль, т.к. контролируемо: и через год, и даже не вы, а другой — сможет повторить процесс. В том числе такой подход позволяет выявить Drift — кто чего тут натыкал, пока вас не было.
#всё_под_контролем
Это не всегда реально: например, какой-то старый проект, нельзя пересоздать репозитории. Но если можно пересоздать - чтобы репозиторием рулил CloudFormation или для нового проекта, то это получается реально удобно. Создаём репозитории с помощью шаблона типа:
https://github.com/applerom/cloudformation-examples/blob/master/ecs/ecr-repo.yml
Как видно в шаблоне - LifecyclePolicy прописывается в чистом виде (JSON). Там же для удобства добавлен шаринг для других аккаунтов, что всегда требуется в случае #multi_account_strategy (если не нужен - просто комментируем). Всё легко кастомизируется под свои значения и любимые скрипты.
Если нужно быстро — просто ручками меняем шаблон и запускаем/обновляем стэк. В любом случае это правильней, чем тыкать через консоль, т.к. контролируемо: и через год, и даже не вы, а другой — сможет повторить процесс. В том числе такой подход позволяет выявить Drift — кто чего тут натыкал, пока вас не было.
#всё_под_контролем
GitHub
cloudformation-examples/ecr-repo.yml at master · applerom/cloudformation-examples
AWS CloudFormation code examples. Contribute to applerom/cloudformation-examples development by creating an account on GitHub.
При попытке восстановить #RDS #Snapshot в #Shared_VPC получаем такую ошибку:
Пока через #AWS_Console это невозможно, т.к. нет возможности выбрать security group (её просто нет в параметрах).
Потому только через #aws_cli:
Всё из-за последней строчки, которая появилась в последних версиях aws-cli, потребовавшейся с приходом Shared VPC.
The specified VPC vpc-04bee1a347f431036 is a shared VPC, please explicitly provide an EC2 security group.Пока через #AWS_Console это невозможно, т.к. нет возможности выбрать security group (её просто нет в параметрах).
Потому только через #aws_cli:
aws rds restore-db-instance-from-db-snapshot \
--db-instance-identifier mydb \
--db-snapshot-identifier my-snapshot \
--db-instance-class db.t2.micro \
--availability-zone us-east-1c \
--db-subnet-group-name my-dbsubnetgroup \
--no-multi-az \
--no-publicly-accessible \
--auto-minor-version-upgrade \
--vpc-security-group-ids sg-0cf1206653f75d50d
Всё из-за последней строчки, которая появилась в последних версиях aws-cli, потребовавшейся с приходом Shared VPC.
Когда вы пишете условный pipeline/утилиту/скрипт, который будет работать (например, деплоить) с разными окружениями (dev/test/stage/prod), то часто возникает искушение использовать под каждое окружение свою ветку. Это кажется логичным и очевидным.
Однако это (branch-by-environment strategy) не лучший подход и вскоре вы можете столкнуться с трудностями - от неудобности внесения каких-то глобальных изменений, которые потребуют внесения одного и того же по всем веткам, до сложности что-то потестировать в отдельном окружении с последующим откатом.
Потому правильно закладывать логику разных конфигов для различных окружений (т.е. в одной ветке разные файлы/конфиги на разные окружения), при этом используя общепринятые схемы #git branching.
• https://guides.github.com/introduction/flow/
• https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
Однако это (branch-by-environment strategy) не лучший подход и вскоре вы можете столкнуться с трудностями - от неудобности внесения каких-то глобальных изменений, которые потребуют внесения одного и того же по всем веткам, до сложности что-то потестировать в отдельном окружении с последующим откатом.
Потому правильно закладывать логику разных конфигов для различных окружений (т.е. в одной ветке разные файлы/конфиги на разные окружения), при этом используя общепринятые схемы #git branching.
• https://guides.github.com/introduction/flow/
• https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
Atlassian
Gitflow Workflow | Atlassian Git Tutorial
A deep dive into the Gitflow Workflow. Learn if this Git workflow is right for you and your team with this comprehensive tutorial.
Амазоновцы таки отреагировали на народные чаяния и убрали из рекомендаций для #SSM эту жирную политику AmazonEC2RoleForSSM, переведя её в статус deprecated.
Вместо неё теперь рекомендуется использовать #IAM #ManagedPolicy AmazonSSMManagedInstanceCore, которая обеспечивает базовый функционал SSM агента, докидывая уже своё по необходимости.
#справедливость #язнал #яверил
Вместо неё теперь рекомендуется использовать #IAM #ManagedPolicy AmazonSSMManagedInstanceCore, которая обеспечивает базовый функционал SSM агента, докидывая уже своё по необходимости.
#справедливость #язнал #яверил
Telegram
aws_notes
В общем случае стоит избегать использования #IAM #ManagedPolicy, т.к. граждане в Амазоне не утруждают себя использованием ограниченных #permissions в них и запросто ставят "жирные" #policy.
Например, в AmazonEC2RoleforSSM, которое рекомендуется для работы…
Например, в AmazonEC2RoleforSSM, которое рекомендуется для работы…
Прежде, чем пилить какую-то вещь на AWS (речь в первую очередь о #CloudFormation #templates, но не только) рекомендуется проверить уже имеющиеся готовые Решения AWS.
Некоторые, пройдя по этой ссылке и покопавшись там, с большой долей вероятности смогут похоронить не один месяц своей (и не только) работы. Не сокрушайтесь, это нормально, не принимайте близко к сердцу. Просто впредь ходите туда периодически.
А чтобы не так было больно, есть испытанный метод:
https://www.youtube.com/watch?v=k2wzKVa0omU
#design #best_practices
Некоторые, пройдя по этой ссылке и покопавшись там, с большой долей вероятности смогут похоронить не один месяц своей (и не только) работы. Не сокрушайтесь, это нормально, не принимайте близко к сердцу. Просто впредь ходите туда периодически.
А чтобы не так было больно, есть испытанный метод:
https://www.youtube.com/watch?v=k2wzKVa0omU
#design #best_practices
Amazon Web Services, Inc.
Облачные решения | Проверенная техническая эталонная архитектура | AWS
Реализовать в #CloudFormation #templates зависимость значений от environment не очень сложно. Однако когда требуется переменное количество параметров (т.е. для одного окружения один набор переменных, а для другого - отличный), то для этого Амазон сделал в своё время Fn::Transform.
Однако из-за того, что это (Transform) суть костыльный костыль, реализуемый как надстройка в виде лямбды, которая запускается перед скармливанием CloudFormation конечного вида шаблона, то реальный опыт работы с Transform оказался весьма болезненный.
Потому совет: если можно не использовать Transform - лучше не использовать.
Альтернативой может быть использование #Conditions.
Например, вот реальный кейс. Потребовалось для multi environment шаблона реализовать логику различного набора переменных для #ECS #task_definition - на тестовом окружении требовалось задать другие переменные, при этом обычные не должны быть определены совсем, т.к. чувствительное приложение, написанное в давние времена, спотыкалось о них и падало.
В результате дефолтная таска была скопирована и создана ещё одна такая же, только с нужными переменными. И добавлен волшебный condition, который из двух этих тасок в сервисе подключал нужную:
https://github.com/applerom/cloudformation-examples/blob/master/ecs/task-definition-with-different-set-of-variables.yaml
По умолчанию логика ни для какого (уже ранее имеющегося) окружения не поменяется (т.к. по умолчанию UseTestVariables = 'no'), а для тестового сработает
Итого - всё работает стандартно и без трансформатора.
Однако из-за того, что это (Transform) суть костыльный костыль, реализуемый как надстройка в виде лямбды, которая запускается перед скармливанием CloudFormation конечного вида шаблона, то реальный опыт работы с Transform оказался весьма болезненный.
Потому совет: если можно не использовать Transform - лучше не использовать.
Альтернативой может быть использование #Conditions.
Например, вот реальный кейс. Потребовалось для multi environment шаблона реализовать логику различного набора переменных для #ECS #task_definition - на тестовом окружении требовалось задать другие переменные, при этом обычные не должны быть определены совсем, т.к. чувствительное приложение, написанное в давние времена, спотыкалось о них и падало.
В результате дефолтная таска была скопирована и создана ещё одна такая же, только с нужными переменными. И добавлен волшебный condition, который из двух этих тасок в сервисе подключал нужную:
https://github.com/applerom/cloudformation-examples/blob/master/ecs/task-definition-with-different-set-of-variables.yaml
По умолчанию логика ни для какого (уже ранее имеющегося) окружения не поменяется (т.к. по умолчанию UseTestVariables = 'no'), а для тестового сработает
TaskDefinition: !If [ UseTest, !Ref ecsTaskTest, !Ref ecsTask ].Итого - всё работает стандартно и без трансформатора.
Когда нужно быстро сориентироваться в вариантах решений/технологий/утилит:
https://landscape.cncf.io
Например, вот решения по части #CloudFormation - раздел Automation & Configuration, где живут #Terraform, #Pulumi, #Chef и далее по списку.
#info
https://landscape.cncf.io
Например, вот решения по части #CloudFormation - раздел Automation & Configuration, где живут #Terraform, #Pulumi, #Chef и далее по списку.
#info
CNCF Landscape
The CNCF Cloud Native Landscape is intended as a map through the previously uncharted terrain of Cloud Native technologies. It attempts to categorize projects and products in the Cloud Native space.
Мало кто задумывается, что не все сервисы Амазона имеют #SLA. В частности, его нет у #CloudFormation, так что все ваши претензии, что он "тупит", "тормозит", "зачтомыбабкиплатим" и "вытамсовсемохренели" - можно смело слать в девнулл.
Полный список AWS сервисов с SLA можно глянуть по ссылке:
https://aws.amazon.com/legal/service-level-agreements/
Однако в ходе решения каких-то вопросов (например, по теме #compliance) может потребоваться более детальная информация.
Допустим, у вас активно используется #CloudTrail и #Config и требуется знать, какие сервисы он покрывает (или наоборот). Или ваш проект секретно секретный и нужно максимально использовать те сервисы, что имеют at-rest-encryption.
Для этого вам поможет следующая ссылка:
https://summitroute.github.io/aws_research/service_support.html
#info
Полный список AWS сервисов с SLA можно глянуть по ссылке:
https://aws.amazon.com/legal/service-level-agreements/
Однако в ходе решения каких-то вопросов (например, по теме #compliance) может потребоваться более детальная информация.
Допустим, у вас активно используется #CloudTrail и #Config и требуется знать, какие сервисы он покрывает (или наоборот). Или ваш проект секретно секретный и нужно максимально использовать те сервисы, что имеют at-rest-encryption.
Для этого вам поможет следующая ссылка:
https://summitroute.github.io/aws_research/service_support.html
#info
Хронология важных патчей сервисов Амазона по датам:
https://aws.amazon.com/security/security-bulletins/
Обновляется с некоторым лагом, например, там пока нет самого свежего патча против Ping of Death, который выкатили вчера:
https://aws.amazon.com/security/security-bulletins/AWS-2019-005/
#security
https://aws.amazon.com/security/security-bulletins/
Обновляется с некоторым лагом, например, там пока нет самого свежего патча против Ping of Death, который выкатили вчера:
https://aws.amazon.com/security/security-bulletins/AWS-2019-005/
#security
Amazon
Security Bulletins
Read our latest security bulletins here.
Выбор AWS региона
Пинг (latency)
При выборе региона для окружения обычно чаще всего ориентируются на пинг:
• от вас до региона
• от заказчика до региона
• от региона до большинства клиентов
Идеально, когда они все совмещены и тогда можно просто проверить это прямо из браузера:
https://www.cloudping.info/
Иначе выбор уже определяется другими факторами.
Стоимость
Ресурсы в разных регионах стоят по-разному, иногда отличие существенное, потому это как минимум стоит учесть:
https://www.concurrencylabs.com/blog/choose-your-aws-region-wisely/
Сервисы
Не все сервисы представлены (появляются) сразу во всех регионах, если это важно, то сверяемся здесь:
https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/
===
Если же у вас нет особых предпочтений и требований, то совет:
В любой непонятной ситуации выбирай N.Virginia.
#aws_region #info
Пинг (latency)
При выборе региона для окружения обычно чаще всего ориентируются на пинг:
• от вас до региона
• от заказчика до региона
• от региона до большинства клиентов
Идеально, когда они все совмещены и тогда можно просто проверить это прямо из браузера:
https://www.cloudping.info/
Иначе выбор уже определяется другими факторами.
Стоимость
Ресурсы в разных регионах стоят по-разному, иногда отличие существенное, потому это как минимум стоит учесть:
https://www.concurrencylabs.com/blog/choose-your-aws-region-wisely/
Сервисы
Не все сервисы представлены (появляются) сразу во всех регионах, если это важно, то сверяемся здесь:
https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/
===
Если же у вас нет особых предпочтений и требований, то совет:
В любой непонятной ситуации выбирай N.Virginia.
#aws_region #info
{kind=link}
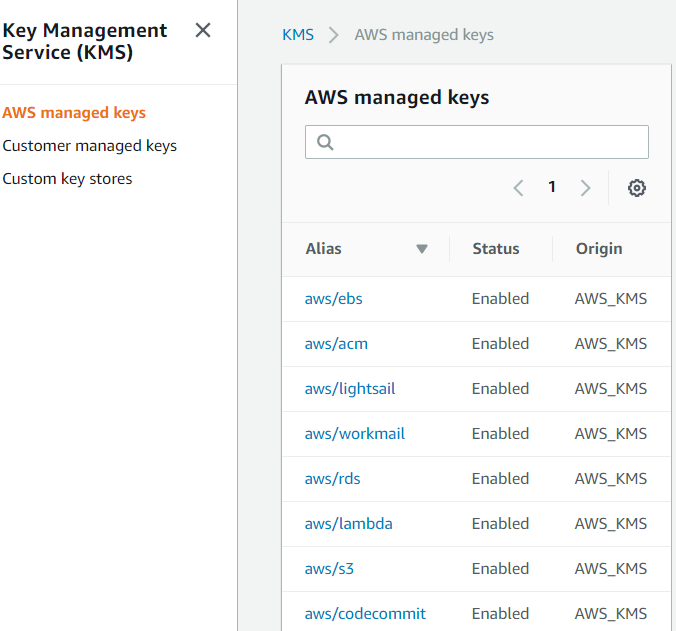
О дефолтных ключах шифрования (AWS managed keys)
Предположим, вы решили учинить разгул безопасности по всему своему проекту. Не стану отговаривать вас от этого безрассудного поступка (в следующий раз), просто предположу, что главным оружием преступления станут дефолтные ключи шифрования, мирно пасущиеся в каждом, умеющих их использовать, сервисе.
Использовать их, действительно, наиболее просто. Однако если (а скорей когда) вам потребуется расшарить зашифрованное дефолтными ключами в другой аккаунт, то будет очень больно узнать, что придётся всё переделывать.
Как правило, в первую очередь речь заходит о базах данных, т.е. #RDS #Snapshot, где в конце концов вы таки прочитаете эти печальные слова:
You can't share a snapshot that has been encrypted using the default AWS KMS encryption key of the AWS account that shared the snapshot.
Дефолтные ключи шифрования можно использовать лишь внутри одного аккаунта. Их по доброте душевной итак уже сделал Амазон, за что, видимо, нужно быть благодарным (хотя у меня, вот, тогда не получилось). А для всех #cross_account операций нужны свои ключи - Customer managed keys - которые шарятся для использования в других аккаунтах.
===
Итого, совет. Если вы никогда не планируете и не будете использовать #multi_account_strategy (мои соболезнования), то #AWS_managed_keys - реально отличное решение, стильно-модно-безопасно.
В противном случае (который является рекомендуемым) - лучше сразу закладываться на свои ключи #Customer_managed_keys. С ними будет муторней и сложней, это правда. Но с ними можно всё.
#KMS #security #encryption
Предположим, вы решили учинить разгул безопасности по всему своему проекту. Не стану отговаривать вас от этого безрассудного поступка (в следующий раз), просто предположу, что главным оружием преступления станут дефолтные ключи шифрования, мирно пасущиеся в каждом, умеющих их использовать, сервисе.
Использовать их, действительно, наиболее просто. Однако если (а скорей когда) вам потребуется расшарить зашифрованное дефолтными ключами в другой аккаунт, то будет очень больно узнать, что придётся всё переделывать.
Как правило, в первую очередь речь заходит о базах данных, т.е. #RDS #Snapshot, где в конце концов вы таки прочитаете эти печальные слова:
You can't share a snapshot that has been encrypted using the default AWS KMS encryption key of the AWS account that shared the snapshot.
Дефолтные ключи шифрования можно использовать лишь внутри одного аккаунта. Их по доброте душевной итак уже сделал Амазон, за что, видимо, нужно быть благодарным (хотя у меня, вот, тогда не получилось). А для всех #cross_account операций нужны свои ключи - Customer managed keys - которые шарятся для использования в других аккаунтах.
===
Итого, совет. Если вы никогда не планируете и не будете использовать #multi_account_strategy (мои соболезнования), то #AWS_managed_keys - реально отличное решение, стильно-модно-безопасно.
В противном случае (который является рекомендуемым) - лучше сразу закладываться на свои ключи #Customer_managed_keys. С ними будет муторней и сложней, это правда. Но с ними можно всё.
#KMS #security #encryption
{kind=link}
Если вы изучаете AWS сервисы (особенно, когда только начинаете), то кроме большого количества уже имеющихся видео, стоит помнить также про #вебинары и #конференции, которые можно найти на официальной странице:
https://aws.amazon.com/events/
У кого ещё нет аккаунта, можно посмотреть какой-нибудь онлайн вебинар и совместить полезное с приятным - получить до 100$ кредитов на эксперименты.
#халява
https://aws.amazon.com/events/
У кого ещё нет аккаунта, можно посмотреть какой-нибудь онлайн вебинар и совместить полезное с приятным - получить до 100$ кредитов на эксперименты.
#халява
Amazon
events
AWS holds events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts.
Тэги для AWS Account
C недавнего времени можно добавить #tags на весь AWS Account - это делается в консоли AWS #Organizations (см. картинку) или через командную строку. Если у вас активно используется #multi_account_strategy, то этим точно стоит воспользоваться.
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_tagging.html
C недавнего времени можно добавить #tags на весь AWS Account - это делается в консоли AWS #Organizations (см. картинку) или через командную строку. Если у вас активно используется #multi_account_strategy, то этим точно стоит воспользоваться.
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_tagging.html
{kind=link}
AWS Control Tower
То, о чём так часто тут говорилось - #multi_account_strategy - наконец-то воплотилось в рабочий сервис у амазона. Встречаем AWS #Control_Tower:
https://aws.amazon.com/blogs/aws/aws-control-tower-set-up-govern-a-multi-account-aws-environment/
Однако те, кто уже использует AWS #Organizations будут грустить, ибо получат ошибку:
Потому воспользоваться AWS Control Tower смогут лишь избранные 90%, кто до этого времени не успел ознакомиться со своим счастьем в виде AWS Organizations.
#строили_строили_и_наконец_построили
То, о чём так часто тут говорилось - #multi_account_strategy - наконец-то воплотилось в рабочий сервис у амазона. Встречаем AWS #Control_Tower:
https://aws.amazon.com/blogs/aws/aws-control-tower-set-up-govern-a-multi-account-aws-environment/
Однако те, кто уже использует AWS #Organizations будут грустить, ибо получат ошибку:
You tried to use an account that is a member of an organization in AWS Organizations. To set up your AWS Control Tower landing zone, use an account that is not a member of an organization.Потому воспользоваться AWS Control Tower смогут лишь избранные 90%, кто до этого времени не успел ознакомиться со своим счастьем в виде AWS Organizations.
#строили_строили_и_наконец_построили
Amazon
AWS Control Tower – Set up & Govern a Multi-Account AWS Environment | Amazon Web Services
Earlier this month I met with an enterprise-scale AWS customer. They told me that they are planning to go all-in on AWS, and want to benefit from all that we have learned about setting up and running AWS at scale. In addition to setting up a Cloud Center…