Data Science Machine Learning Data Analysis
Photo
# 📚 PyTorch Tutorial for Beginners - Part 2/6: Deep Neural Networks & Training Techniques
#PyTorch #DeepLearning #MachineLearning #NeuralNetworks #Training
Welcome to Part 2 of our comprehensive PyTorch series! This lesson dives deep into building and training neural networks, covering architectures, activation functions, optimization, and more.
---
## 🔹 Recap & Setup
---
## 🔹 Deep Neural Network (DNN) Architecture
### 1. Key Components
| Component | Purpose | PyTorch Implementation |
|--------------------|-------------------------------------------------------------------------|------------------------------|
| Input Layer | Receives raw features |
| Hidden Layers | Learn hierarchical representations | Multiple
| Output Layer | Produces final predictions |
| Activation | Introduces non-linearity |
| Loss Function | Measures prediction error |
| Optimizer | Updates weights to minimize loss |
### 2. Building a DNN
---
## 🔹 Activation Functions
### 1. Common Choices
| Activation | Formula | Range | Use Case | PyTorch |
|-----------------|----------------------|------------|------------------------------|------------------|
| ReLU | max(0, x) | [0, ∞) | Hidden layers |
| Leaky ReLU | max(0.01x, x) | (-∞, ∞) | Avoid dead neurons |
| Sigmoid | 1 / (1 + e^(-x)) | (0, 1) | Binary classification |
| Tanh | (e^x - e^(-x)) / ... | (-1, 1) | RNNs, some hidden layers |
| Softmax | e^x / sum(e^x) | (0, 1) | Multi-class classification |
### 2. Visual Comparison
---
#PyTorch #DeepLearning #MachineLearning #NeuralNetworks #Training
Welcome to Part 2 of our comprehensive PyTorch series! This lesson dives deep into building and training neural networks, covering architectures, activation functions, optimization, and more.
---
## 🔹 Recap & Setup
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
# Check GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
---
## 🔹 Deep Neural Network (DNN) Architecture
### 1. Key Components
| Component | Purpose | PyTorch Implementation |
|--------------------|-------------------------------------------------------------------------|------------------------------|
| Input Layer | Receives raw features |
nn.Linear(input_dim, hidden_dim) || Hidden Layers | Learn hierarchical representations | Multiple
nn.Linear + Activation || Output Layer | Produces final predictions |
nn.Linear(hidden_dim, output_dim) || Activation | Introduces non-linearity |
nn.ReLU(), nn.Sigmoid(), etc. || Loss Function | Measures prediction error |
nn.MSELoss(), nn.CrossEntropyLoss() || Optimizer | Updates weights to minimize loss |
optim.SGD(), optim.Adam() |### 2. Building a DNN
class DNN(nn.Module):
def __init__(self, input_size, hidden_sizes, output_size):
super().__init__()
layers = []
# Hidden layers
prev_size = input_size
for hidden_size in hidden_sizes:
layers.append(nn.Linear(prev_size, hidden_size))
layers.append(nn.ReLU())
prev_size = hidden_size
# Output layer (no activation for regression)
layers.append(nn.Linear(prev_size, output_size))
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x)
# Example: 3-layer network (input=10, hidden=[64,32], output=1)
model = DNN(10, [64, 32], 1).to(device)
print(model)
---
## 🔹 Activation Functions
### 1. Common Choices
| Activation | Formula | Range | Use Case | PyTorch |
|-----------------|----------------------|------------|------------------------------|------------------|
| ReLU | max(0, x) | [0, ∞) | Hidden layers |
nn.ReLU() || Leaky ReLU | max(0.01x, x) | (-∞, ∞) | Avoid dead neurons |
nn.LeakyReLU() || Sigmoid | 1 / (1 + e^(-x)) | (0, 1) | Binary classification |
nn.Sigmoid() || Tanh | (e^x - e^(-x)) / ... | (-1, 1) | RNNs, some hidden layers |
nn.Tanh() || Softmax | e^x / sum(e^x) | (0, 1) | Multi-class classification |
nn.Softmax() |### 2. Visual Comparison
x = torch.linspace(-5, 5, 100)
activations = {
"ReLU": nn.ReLU()(x),
"LeakyReLU": nn.LeakyReLU(0.1)(x),
"Sigmoid": nn.Sigmoid()(x),
"Tanh": nn.Tanh()(x)
}
plt.figure(figsize=(12, 4))
for i, (name, y) in enumerate(activations.items()):
plt.subplot(1, 4, i+1)
plt.plot(x.numpy(), y.numpy())
plt.title(name)
plt.tight_layout()
plt.show()
---
🔥2👍1
Data Science Machine Learning Data Analysis
Photo
## 🔹 Loss Functions
### 1. Common Loss Functions
| Task | Loss Function | PyTorch Implementation |
|-----------------------|----------------------------|------------------------------|
| Regression | Mean Squared Error (MSE) |
| Binary Classification | Binary Cross Entropy (BCE) |
| Multi-class | Cross Entropy |
| Imbalanced Data | Focal Loss | Custom implementation |
### 2. Custom Loss Example
---
## **🔹 Optimization Techniques**
### 1. Optimizers Comparison
| Optimizer | Key Features | Use Case |
|-----------------|-------------------------------------------|------------------------------|
| SGD | Simple, can get stuck in local minima | Basic models |
| SGD+Momentum| Accumulates velocity for smoother updates | Most scenarios |
| Adam | Adaptive learning rates | Default for many problems |
| RMSprop | Adapts learning rates per parameter | RNNs, some CNN architectures |
### 2. Learning Rate Scheduling
---
## 🔹 Batch Normalization & Dropout
### 1. Batch Normalization
Normalizes layer inputs to reduce internal covariate shift.
### 2. Dropout
Randomly deactivates neurons to prevent overfitting.
---
## 🔹 Data Loading & Preprocessing
### 1. Using DataLoader
### 2. Custom Dataset
---
### 1. Common Loss Functions
| Task | Loss Function | PyTorch Implementation |
|-----------------------|----------------------------|------------------------------|
| Regression | Mean Squared Error (MSE) |
nn.MSELoss() || Binary Classification | Binary Cross Entropy (BCE) |
nn.BCELoss() || Multi-class | Cross Entropy |
nn.CrossEntropyLoss() || Imbalanced Data | Focal Loss | Custom implementation |
### 2. Custom Loss Example
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
BCE_loss = nn.BCEWithLogitsLoss(reduction='none')(inputs, targets)
pt = torch.exp(-BCE_loss)
loss = self.alpha * (1-pt)**self.gamma * BCE_loss
return loss.mean()
---
## **🔹 Optimization Techniques**
### 1. Optimizers Comparison
| Optimizer | Key Features | Use Case |
|-----------------|-------------------------------------------|------------------------------|
| SGD | Simple, can get stuck in local minima | Basic models |
| SGD+Momentum| Accumulates velocity for smoother updates | Most scenarios |
| Adam | Adaptive learning rates | Default for many problems |
| RMSprop | Adapts learning rates per parameter | RNNs, some CNN architectures |
# Example optimizers
optimizer_SGD = optim.SGD(model.parameters(), lr=0.01)
optimizer_momentum = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer_Adam = optim.Adam(model.parameters(), lr=0.001)
### 2. Learning Rate Scheduling
# Step LR scheduler
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# Cosine annealing
scheduler_cosine = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100)
# Usage in training loop
for epoch in range(100):
# Training steps...
scheduler.step()
---
## 🔹 Batch Normalization & Dropout
### 1. Batch Normalization
Normalizes layer inputs to reduce internal covariate shift.
class DNNWithBN(nn.Module):
def __init__(self, input_size, hidden_sizes, output_size):
super().__init__()
layers = []
prev_size = input_size
for hidden_size in hidden_sizes:
layers.extend([
nn.Linear(prev_size, hidden_size),
nn.BatchNorm1d(hidden_size),
nn.ReLU()
])
prev_size = hidden_size
layers.append(nn.Linear(prev_size, output_size))
self.net = nn.Sequential(*layers)
### 2. Dropout
Randomly deactivates neurons to prevent overfitting.
self.net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.5), # 50% dropout
nn.Linear(256, 10)
)
---
## 🔹 Data Loading & Preprocessing
### 1. Using DataLoader
from torchvision import datasets, transforms
# Transformations
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# Load MNIST
train_data = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_data = datasets.MNIST('./data', train=False, transform=transform)
# Create DataLoaders
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False)
### 2. Custom Dataset
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, X, y, transform=None):
self.X = X
self.y = y
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
sample = self.X[idx], self.y[idx]
if self.transform:
sample = self.transform(sample)
return sample
---
🔥2❤1
Data Science Machine Learning Data Analysis
Photo
## 🔹 Complete Training Pipeline
### 1. Training Loop
### 2. Evaluation Function
### 3. Full Execution
---
## 🔹 Debugging & Visualization
### 1. Gradient Checking
### 2. Weight Histograms
---
## 🔹 Advanced Techniques
### 1. Weight Initialization
### 2. Early Stopping
---
## 🔹 Best Practices
1. Always normalize input data (e.g., scale to [0,1] or standardize)
2. Use batch normalization for deeper networks
3. Start with Adam optimizer (lr=0.001) as default
4. Monitor training with validation set to detect overfitting
5. Visualize weight distributions periodically
6. Use GPU for training (
---
### 📌 What's Next?
In Part 3, we'll cover:
➡️ Convolutional Neural Networks (CNNs)
➡️ Transfer Learning
➡️ Image Augmentation Techniques
➡️ Visualizing CNNs
#PyTorch #DeepLearning #MachineLearning 🚀
### 1. Training Loop
def train(model, train_loader, criterion, optimizer, epochs=10):
model.train()
losses = []
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
epoch_loss = running_loss / len(train_loader)
losses.append(epoch_loss)
print(f'Epoch {epoch+1}/{epochs}, Loss: {epoch_loss:.4f}')
return losses
### 2. Evaluation Function
def evaluate(model, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Test Accuracy: {accuracy:.2f}%')
return accuracy
### 3. Full Execution
# Hyperparameters
input_size = 784 # MNIST images (28x28)
hidden_sizes = [128, 64]
output_size = 10 # Digits 0-9
lr = 0.001
epochs = 10
# Initialize
model = DNN(input_size, hidden_sizes, output_size).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# Flatten MNIST images
train_loader.dataset.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
transforms.Lambda(lambda x: x.view(-1)) # Flatten
])
# Train and evaluate
losses = train(model, train_loader, criterion, optimizer, epochs)
evaluate(model, test_loader)
# Plot training curve
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.show()
---
## 🔹 Debugging & Visualization
### 1. Gradient Checking
# After loss.backward()
for name, param in model.named_parameters():
if param.grad is not None:
print(f"{name} gradient mean: {param.grad.mean().item():.6f}")
### 2. Weight Histograms
def plot_weights(model):
for name, param in model.named_parameters():
if 'weight' in name:
plt.figure()
plt.hist(param.detach().cpu().numpy().flatten(), bins=50)
plt.title(name)
plt.show()
---
## 🔹 Advanced Techniques
### 1. Weight Initialization
def init_weights(m):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.zeros_(m.bias)
model.apply(init_weights)
### 2. Early Stopping
best_loss = float('inf')
patience = 3
trigger_times = 0
for epoch in range(100):
# Training...
val_loss = validate(model, val_loader, criterion)
if val_loss < best_loss:
best_loss = val_loss
trigger_times = 0
torch.save(model.state_dict(), 'best_model.pth')
else:
trigger_times += 1
if trigger_times >= patience:
print("Early stopping!")
break---
## 🔹 Best Practices
1. Always normalize input data (e.g., scale to [0,1] or standardize)
2. Use batch normalization for deeper networks
3. Start with Adam optimizer (lr=0.001) as default
4. Monitor training with validation set to detect overfitting
5. Visualize weight distributions periodically
6. Use GPU for training (
model.to(device))---
### 📌 What's Next?
In Part 3, we'll cover:
➡️ Convolutional Neural Networks (CNNs)
➡️ Transfer Learning
➡️ Image Augmentation Techniques
➡️ Visualizing CNNs
#PyTorch #DeepLearning #MachineLearning 🚀
❤2🔥2
Data Science Machine Learning Data Analysis
Photo
Practice Exercise:
1. Modify the DNN to have 4 hidden layers [256, 128, 64, 32]
2. Try different activation functions (LeakyReLU, Tanh)
3. Implement learning rate scheduling
4. Add dropout and compare results
5. Plot accuracy vs. epoch during training
1. Modify the DNN to have 4 hidden layers [256, 128, 64, 32]
2. Try different activation functions (LeakyReLU, Tanh)
3. Implement learning rate scheduling
4. Add dropout and compare results
5. Plot accuracy vs. epoch during training
# Sample solution for exercise 1
model = DNN(784, [256, 128, 64, 32], 10).to(device)
❤2🔥1
Data Science Machine Learning Data Analysis
Photo
# 📚 PyTorch Tutorial for Beginners - Part 3/6: Convolutional Neural Networks (CNNs) & Computer Vision
#PyTorch #DeepLearning #ComputerVision #CNNs #TransferLearning
Welcome to Part 3 of our PyTorch series! This comprehensive lesson dives deep into Convolutional Neural Networks (CNNs), the powerhouse behind modern computer vision applications. We'll cover architecture design, implementation tricks, transfer learning, and visualization techniques.
---
## 🔹 Introduction to CNNs
### Why CNNs for Images?
Traditional fully-connected networks (DNNs) fail for images because:
- Parameter explosion: A 256x256 RGB image → 196,608 input features
- No spatial awareness: DNNs treat pixels as independent features
- Translation variance: Objects in different positions require re-learning
### CNN Key Innovations
| Concept | Purpose | Visual Example |
|--------------------|-------------------------------------------------------------------------|-----------------------------|
| Local Receptive Fields | Processes small regions at a time (e.g., 3x3 windows) |  |
| Weight Sharing | Same filters applied across entire image (reduces parameters) | |
| Hierarchical Features | Early layers detect edges → textures → object parts → whole objects |  |
---
## 🔹 Core CNN Components
### 1. Convolutional Layers
### 2. Pooling Layers
### 3. Normalization Layers
### 4. Dropout
---
## 🔹 Building a CNN from Scratch
### Complete Architecture
### Shape Calculation Formula
For a layer with:
- Input size: (Hᵢₙ, Wᵢₙ)
- Kernel: K
- Padding: P
- Stride: S
Output dimensions:
---
#PyTorch #DeepLearning #ComputerVision #CNNs #TransferLearning
Welcome to Part 3 of our PyTorch series! This comprehensive lesson dives deep into Convolutional Neural Networks (CNNs), the powerhouse behind modern computer vision applications. We'll cover architecture design, implementation tricks, transfer learning, and visualization techniques.
---
## 🔹 Introduction to CNNs
### Why CNNs for Images?
Traditional fully-connected networks (DNNs) fail for images because:
- Parameter explosion: A 256x256 RGB image → 196,608 input features
- No spatial awareness: DNNs treat pixels as independent features
- Translation variance: Objects in different positions require re-learning
### CNN Key Innovations
| Concept | Purpose | Visual Example |
|--------------------|-------------------------------------------------------------------------|-----------------------------|
| Local Receptive Fields | Processes small regions at a time (e.g., 3x3 windows) |  |
| Weight Sharing | Same filters applied across entire image (reduces parameters) | |
| Hierarchical Features | Early layers detect edges → textures → object parts → whole objects |  |
---
## 🔹 Core CNN Components
### 1. Convolutional Layers
import torch.nn as nn
# 2D convolution (for images)
conv = nn.Conv2d(
in_channels=3, # Input channels (RGB=3, grayscale=1)
out_channels=16, # Number of filters
kernel_size=3, # 3x3 filter
stride=1, # Filter movement step
padding=1 # Preserves spatial dimensions (with stride=1)
)
# Shape transformation: (batch, channels, height, width)
x = torch.randn(32, 3, 64, 64) # 32 RGB images of 64x64
print(conv(x).shape) # → torch.Size([32, 16, 64, 64])
### 2. Pooling Layers
# Max pooling (common for downsampling)
pool = nn.MaxPool2d(kernel_size=2, stride=2)
print(pool(conv(x)).shape) # → torch.Size([32, 16, 32, 32])
# Adaptive pooling (useful for varying input sizes)
adaptive_pool = nn.AdaptiveAvgPool2d((7, 7))
print(adaptive_pool(x).shape) # → torch.Size([32, 3, 7, 7])
### 3. Normalization Layers
# Batch Normalization
bn = nn.BatchNorm2d(16) # num_features = out_channels
x = conv(x)
x = bn(x)
# Layer Normalization (for NLP/sequences)
ln = nn.LayerNorm([16, 64, 64])
### 4. Dropout
# Spatial dropout (drops entire channels)
dropout = nn.Dropout2d(p=0.25)
---
## 🔹 Building a CNN from Scratch
### Complete Architecture
class CNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
# Block 2
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
# Block 3
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.classifier = nn.Sequential(
nn.Linear(128 * 4 * 4, 512), # Adjusted based on input size
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # Flatten all dimensions except batch
x = self.classifier(x)
return x
# Usage
model = CNN().to(device)
print(model)
### Shape Calculation Formula
For a layer with:
- Input size: (Hᵢₙ, Wᵢₙ)
- Kernel: K
- Padding: P
- Stride: S
Output dimensions:
Hₒᵤₜ = ⌊(Hᵢₙ + 2P - K)/S⌋ + 1
Wₒᵤₜ = ⌊(Wᵢₙ + 2P - K)/S⌋ + 1
---
Data Science Machine Learning Data Analysis
Photo
## 🔹 Transfer Learning
### 1. Why Transfer Learning?
- Leverages pre-trained models on large datasets (ImageNet)
- Requires less data for new tasks
- Faster training convergence
### 2. Using Pretrained Models
### 3. Feature Extraction Pipeline
---
## 🔹 Data Augmentation
### 1. Common Techniques
### 2. Advanced Augmentations (Albumentations)
---
## 🔹 Training Tricks for CNNs
### 1. Learning Rate Finder
### 2. Mixed Precision Training
### 3. Gradient Clipping
---
## 🔹 Visualization Techniques
### 1. Feature Maps Visualization
### 1. Why Transfer Learning?
- Leverages pre-trained models on large datasets (ImageNet)
- Requires less data for new tasks
- Faster training convergence
### 2. Using Pretrained Models
from torchvision import models
# Load pretrained ResNet18
resnet = models.resnet18(pretrained=True)
# Freeze all layers
for param in resnet.parameters():
param.requires_grad = False
# Replace final layer
num_ftrs = resnet.fc.in_features
resnet.fc = nn.Linear(num_ftrs, 10) # New task with 10 classes
# Only new FC layer will be trained
optimizer = optim.Adam(resnet.fc.parameters(), lr=0.001)
### 3. Feature Extraction Pipeline
from torchvision import transforms
# Preprocessing for pretrained models
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], # ImageNet stats
std=[0.229, 0.224, 0.225]
)
])
# Create dataset
train_data = datasets.ImageFolder('data/train', transform=preprocess)
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
---
## 🔹 Data Augmentation
### 1. Common Techniques
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
### 2. Advanced Augmentations (Albumentations)
import albumentations as A
from albumentations.pytorch import ToTensorV2
transform = A.Compose([
A.RandomRotate90(),
A.Flip(),
A.Transpose(),
A.GaussNoise(p=0.2),
A.OneOf([
A.MotionBlur(p=0.2),
A.MedianBlur(blur_limit=3, p=0.1),
A.Blur(blur_limit=3, p=0.1),
], p=0.2),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2()
])
---
## 🔹 Training Tricks for CNNs
### 1. Learning Rate Finder
from torch_lr_finder import LRFinder
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-7)
lr_finder = LRFinder(model, optimizer, criterion, device='cuda')
lr_finder.range_test(train_loader, end_lr=10, num_iter=100)
lr_finder.plot() # Identify optimal lr from plot
lr_finder.reset()
### 2. Mixed Precision Training
from torch.cuda.amp import GradScaler, autocast
scaler = GradScaler()
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
### 3. Gradient Clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
---
## 🔹 Visualization Techniques
### 1. Feature Maps Visualization
def visualize_feature_maps(model, image):
# Hook to get intermediate features
features = []
def hook(module, input, output):
features.append(output.detach())
# Register hook to first conv layer
handle = model.features[0].register_forward_hook(hook)
# Forward pass
model(image.unsqueeze(0))
handle.remove()
# Plot first 16 filters
fig, axes = plt.subplots(4, 4, figsize=(12, 12))
for i, ax in enumerate(axes.flat):
ax.imshow(features[0][0, i].cpu(), cmap='viridis')
ax.axis('off')
plt.show()
Data Science Machine Learning Data Analysis
Photo
### 2. Grad-CAM (Class Activation Maps)
---
## 🔹 Advanced Architectures
### 1. Residual Connections (ResNet)
### 2. Inception Module
---
class GradCAM:
def __init__(self, model, target_layer):
self.model = model
self.target_layer = target_layer
self.gradients = None
self.activations = None
# Hook setup
target_layer.register_forward_hook(self.save_activations)
target_layer.register_backward_hook(self.save_gradients)
def save_activations(self, module, input, output):
self.activations = output.detach()
def save_gradients(self, module, grad_input, grad_output):
self.gradients = grad_output[0].detach()
def __call__(self, x, class_idx=None):
# Forward pass
output = self.model(x)
if class_idx is None:
class_idx = output.argmax(dim=1)
# Backward pass for specific class
self.model.zero_grad()
one_hot = torch.zeros_like(output)
one_hot[0][class_idx] = 1
output.backward(gradient=one_hot)
# Grad-CAM calculation
weights = self.gradients.mean(dim=(2, 3), keepdim=True)
cam = (weights * self.activations).sum(dim=1, keepdim=True)
cam = torch.relu(cam)
cam = F.interpolate(cam, x.shape[2:], mode='bilinear', align_corners=False)
cam = cam - cam.min()
cam = cam / cam.max()
return cam.squeeze().cpu().numpy()
# Usage
target_layer = model.features[-3] # Last conv layer
gradcam = GradCAM(model, target_layer)
cam = gradcam(input_image)
plt.imshow(cam, cmap='jet', alpha=0.5)
plt.imshow(input_image.squeeze().permute(1,2,0), alpha=0.5)
plt.show()
---
## 🔹 Advanced Architectures
### 1. Residual Connections (ResNet)
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# Shortcut connection
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out)))
out += self.shortcut(x)
out = F.relu(out)
return out
### 2. Inception Module
class InceptionModule(nn.Module):
def __init__(self, in_channels):
super().__init__()
# 1x1 branch
self.branch1x1 = nn.Conv2d(in_channels, 64, kernel_size=1)
# 3x3 branch
self.branch3x3 = nn.Sequential(
nn.Conv2d(in_channels, 96, kernel_size=1),
nn.Conv2d(96, 128, kernel_size=3, padding=1)
)
# 5x5 branch
self.branch5x5 = nn.Sequential(
nn.Conv2d(in_channels, 16, kernel_size=1),
nn.Conv2d(16, 32, kernel_size=5, padding=2)
)
# Pool branch
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, 32, kernel_size=1)
)
def forward(self, x):
return torch.cat([
self.branch1x1(x),
self.branch3x3(x),
self.branch5x5(x),
self.branch_pool(x)
], dim=1)
---
❤1
Data Science Machine Learning Data Analysis
Photo
## 🔹 Best Practices for CNN Development
1. Start with pretrained models when possible
2. Use progressive resizing (start with small images, then increase)
3. Monitor class activation maps to debug model focus areas
4. Apply test-time augmentation (TTA) for better inference
5. Use label smoothing for classification tasks
6. Implement learning rate warmup for large batch training
---
### 📌 What's Next?
In Part 4, we'll cover:
➡️ Recurrent Neural Networks (RNNs/LSTMs)
➡️ Sequence Modeling
➡️ Attention Mechanisms
➡️ Transformer Architectures
#PyTorch #DeepLearning #ComputerVision 🚀
Practice Exercises:
1. Modify the CNN to use depthwise separable convolutions
2. Implement a ResNet-18 from scratch
3. Apply Grad-CAM to visualize model decisions
4. Train on CIFAR-100 with CutMix augmentation
5. Compare Adam vs. SGD with momentum performance
https://t.iss.one/DataScienceM🌟
1. Start with pretrained models when possible
2. Use progressive resizing (start with small images, then increase)
3. Monitor class activation maps to debug model focus areas
4. Apply test-time augmentation (TTA) for better inference
5. Use label smoothing for classification tasks
6. Implement learning rate warmup for large batch training
# Label smoothing example
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
# Learning rate warmup
def warmup_lr(epoch, warmup_epochs=5, base_lr=0.001):
return base_lr * (epoch + 1) / warmup_epochs if epoch < warmup_epochs else base_lr
---
### 📌 What's Next?
In Part 4, we'll cover:
➡️ Recurrent Neural Networks (RNNs/LSTMs)
➡️ Sequence Modeling
➡️ Attention Mechanisms
➡️ Transformer Architectures
#PyTorch #DeepLearning #ComputerVision 🚀
Practice Exercises:
1. Modify the CNN to use depthwise separable convolutions
2. Implement a ResNet-18 from scratch
3. Apply Grad-CAM to visualize model decisions
4. Train on CIFAR-100 with CutMix augmentation
5. Compare Adam vs. SGD with momentum performance
# Depthwise separable convolution example
class DepthwiseSeparableConv(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3,
stride=stride, padding=1, groups=in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.pointwise(self.depthwise(x))
https://t.iss.one/DataScienceM
Please open Telegram to view this post
VIEW IN TELEGRAM
Telegram
Data Science Machine Learning Data Analysis
ads: @HusseinSheikho
This channel is for Programmers, Coders, Software Engineers.
1- Data Science
2- Machine Learning
3- Data Visualization
4- Artificial Intelligence
5- Data Analysis
6- Statistics
7- Deep Learning
This channel is for Programmers, Coders, Software Engineers.
1- Data Science
2- Machine Learning
3- Data Visualization
4- Artificial Intelligence
5- Data Analysis
6- Statistics
7- Deep Learning
❤2
Data Science Machine Learning Data Analysis
Photo
# 📚 PyTorch Tutorial for Beginners - Part 4/6: Sequence Modeling with RNNs, LSTMs & Attention
#PyTorch #DeepLearning #NLP #RNN #LSTM #Transformer
Welcome to Part 4 of our PyTorch series! This comprehensive lesson dives deep into sequence modeling, covering recurrent networks, attention mechanisms, and transformer architectures with practical implementations.
---
## 🔹 Introduction to Sequence Modeling
### Key Challenges with Sequences
1. Variable Length: Sequences can be arbitrarily long (sentences, time series)
2. Temporal Dependencies: Current output depends on previous inputs
3. Context Preservation: Need to maintain long-range relationships
### Comparison of Approaches
| Model Type | Pros | Cons | Typical Use Cases |
|------------------|---------------------------------------|---------------------------------------|---------------------------------|
| RNN | Simple, handles sequences | Struggles with long-term dependencies | Short time series, char-level NLP |
| LSTM | Better long-term memory | Computationally heavier | Machine translation, speech recognition |
| GRU | LSTM-like with fewer parameters | Still limited context | Medium-length sequences |
| Transformer | Parallel processing, global context | Memory intensive for long sequences | Modern NLP, any sequence task |
---
## 🔹 Recurrent Neural Networks (RNNs)
### 1. Basic RNN Architecture
### 2. The Vanishing Gradient Problem
RNNs struggle with long sequences due to:
- Repeated multiplication of small gradients through time
- Exponential decay of gradient information
Solutions:
- Gradient clipping
- Architectural changes (LSTM, GRU)
- Skip connections
---
## 🔹 Long Short-Term Memory (LSTM) Networks
### 1. LSTM Core Concepts

Key Components:
- Forget Gate: Decides what information to discard
- Input Gate: Updates cell state with new information
- Output Gate: Determines next hidden state
### 2. PyTorch Implementation
#PyTorch #DeepLearning #NLP #RNN #LSTM #Transformer
Welcome to Part 4 of our PyTorch series! This comprehensive lesson dives deep into sequence modeling, covering recurrent networks, attention mechanisms, and transformer architectures with practical implementations.
---
## 🔹 Introduction to Sequence Modeling
### Key Challenges with Sequences
1. Variable Length: Sequences can be arbitrarily long (sentences, time series)
2. Temporal Dependencies: Current output depends on previous inputs
3. Context Preservation: Need to maintain long-range relationships
### Comparison of Approaches
| Model Type | Pros | Cons | Typical Use Cases |
|------------------|---------------------------------------|---------------------------------------|---------------------------------|
| RNN | Simple, handles sequences | Struggles with long-term dependencies | Short time series, char-level NLP |
| LSTM | Better long-term memory | Computationally heavier | Machine translation, speech recognition |
| GRU | LSTM-like with fewer parameters | Still limited context | Medium-length sequences |
| Transformer | Parallel processing, global context | Memory intensive for long sequences | Modern NLP, any sequence task |
---
## 🔹 Recurrent Neural Networks (RNNs)
### 1. Basic RNN Architecture
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden=None):
# x shape: (batch, seq_len, input_size)
out, hidden = self.rnn(x, hidden)
# Only use last output for classification
out = self.fc(out[:, -1, :])
return out
# Usage
rnn = VanillaRNN(input_size=10, hidden_size=20, output_size=5)
x = torch.randn(3, 15, 10) # (batch=3, seq_len=15, input_size=10)
output = rnn(x)
### 2. The Vanishing Gradient Problem
RNNs struggle with long sequences due to:
- Repeated multiplication of small gradients through time
- Exponential decay of gradient information
Solutions:
- Gradient clipping
- Architectural changes (LSTM, GRU)
- Skip connections
---
## 🔹 Long Short-Term Memory (LSTM) Networks
### 1. LSTM Core Concepts

Key Components:
- Forget Gate: Decides what information to discard
- Input Gate: Updates cell state with new information
- Output Gate: Determines next hidden state
### 2. PyTorch Implementation
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,
batch_first=True, dropout=0.2 if num_layers>1 else 0)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# Initialize hidden state and cell state
h0 = torch.zeros(self.lstm.num_layers, x.size(0),
self.lstm.hidden_size).to(x.device)
c0 = torch.zeros_like(h0)
out, (hn, cn) = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
# Bidirectional LSTM example
bidir_lstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2,
bidirectional=True, batch_first=True)
Data Science Machine Learning Data Analysis
Photo
### 3. Practical Tips for LSTMs
- Initialization: Orthogonal initialization for recurrent weights
- Dropout: Use
- Sequence Packing: For variable-length sequences:
---
## 🔹 Gated Recurrent Units (GRUs)
### Simplified Alternative to LSTM
GRU vs LSTM:
- GRU combines forget and input gates into update gate
- GRU merges cell state and hidden state
- Typically faster to train with comparable performance
---
## 🔹 Attention Mechanisms
### 1. Why Attention?
- Addresses information bottleneck in encoder-decoder architectures
- Allows dynamic focus on relevant parts of input
- Enables interpretability (visualize attention weights)
### 2. Basic Attention Implementation
### 3. Visualizing Attention
---
## 🔹 Transformer Architectures
### 1. Core Components
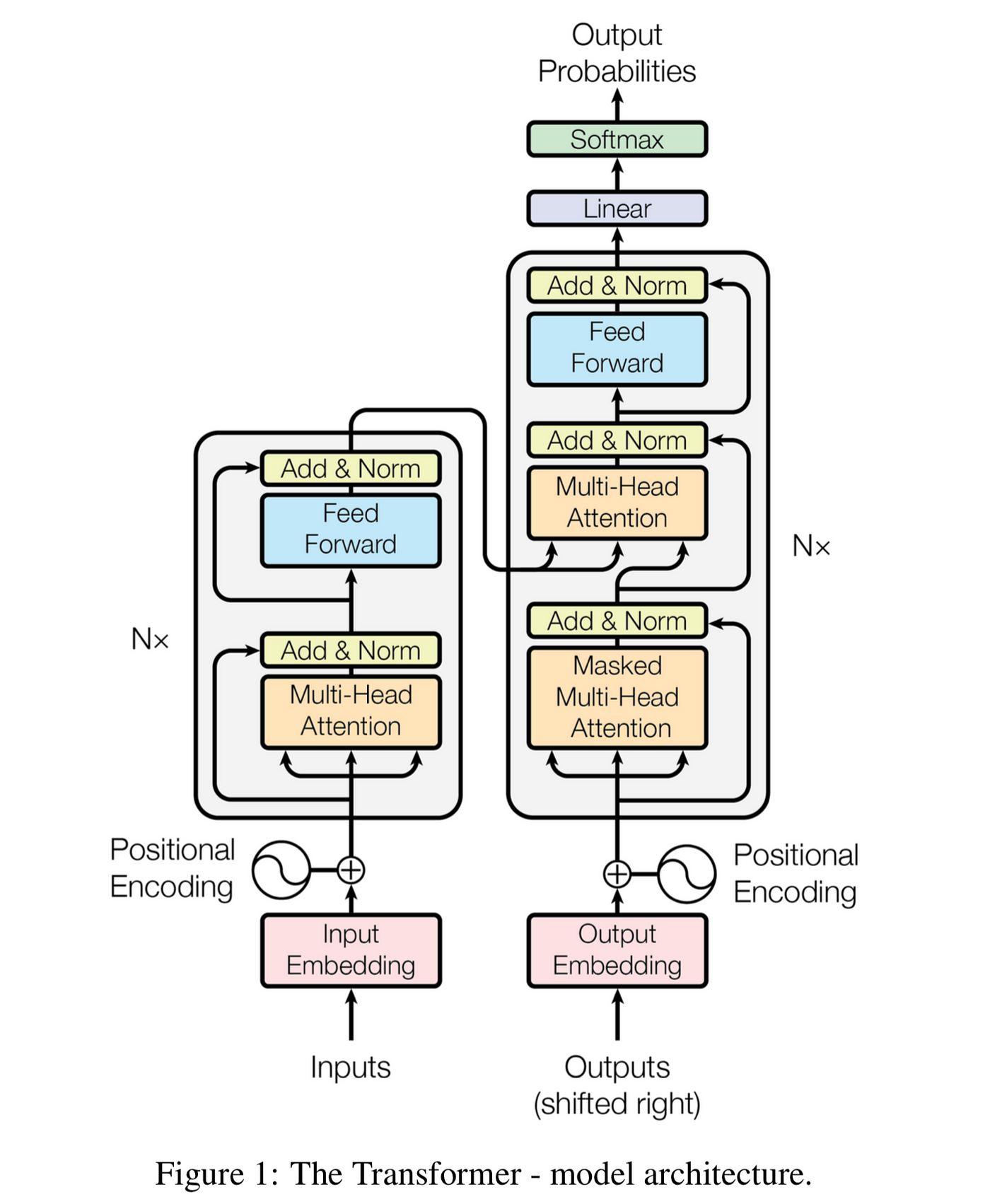
Key Innovations:
- Self-Attention: Captures relationships between all sequence positions
- Positional Encoding: Injects sequence order information
- Layer Normalization: Stabilizes training
- Feed-Forward Networks: Applied position-wise
- Initialization: Orthogonal initialization for recurrent weights
- Dropout: Use
dropout between LSTM layers (not on last layer)- Sequence Packing: For variable-length sequences:
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
# Assume 'lengths' contains original sequence lengths
packed_input = pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=False)
packed_output, (hn, cn) = lstm(packed_input)
output, _ = pad_packed_sequence(packed_output, batch_first=True)
---
## 🔹 Gated Recurrent Units (GRUs)
### Simplified Alternative to LSTM
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.gru = nn.GRU(input_size, hidden_size, num_layers,
batch_first=True, dropout=0.2)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, hn = self.gru(x)
out = self.fc(out[:, -1, :])
return out
GRU vs LSTM:
- GRU combines forget and input gates into update gate
- GRU merges cell state and hidden state
- Typically faster to train with comparable performance
---
## 🔹 Attention Mechanisms
### 1. Why Attention?
- Addresses information bottleneck in encoder-decoder architectures
- Allows dynamic focus on relevant parts of input
- Enables interpretability (visualize attention weights)
### 2. Basic Attention Implementation
class Attention(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.attention = nn.Linear(hidden_size, hidden_size)
self.context = nn.Parameter(torch.randn(hidden_size))
def forward(self, hidden_states):
# hidden_states shape: (batch, seq_len, hidden_size)
# Compute attention scores
energies = torch.tanh(self.attention(hidden_states))
scores = torch.matmul(energies, self.context)
alphas = torch.softmax(scores, dim=1)
# Compute context vector
context = torch.sum(hidden_states * alphas.unsqueeze(-1), dim=1)
return context, alphas
# Integrated with RNN
class AttnRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.rnn = nn.GRU(input_size, hidden_size, batch_first=True)
self.attention = Attention(hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
context, alphas = self.attention(out)
return self.fc(context), alphas
### 3. Visualizing Attention
def plot_attention(input_text, alphas):
fig, ax = plt.subplots(figsize=(12, 4))
ax.imshow(alphas.cpu().numpy(), cmap='viridis')
ax.set_xticks(range(len(input_text.split())))
ax.set_xticklabels(input_text.split(), rotation=45)
ax.set_yticks([0])
ax.set_yticklabels(['Attention'])
plt.tight_layout()
plt.show()
---
## 🔹 Transformer Architectures
### 1. Core Components

Key Innovations:
- Self-Attention: Captures relationships between all sequence positions
- Positional Encoding: Injects sequence order information
- Layer Normalization: Stabilizes training
- Feed-Forward Networks: Applied position-wise
❤1
Data Science Machine Learning Data Analysis
Photo
### 2. Implementing Multi-Head Attention
### **3. Complete Transformer Block**
### 4. Positional Encoding
---
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super().__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert self.head_dim * heads == embed_size, "Embed size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask=None):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split embedding into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# Attention scores
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
### **3. Complete Transformer Block**
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super().__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
### 4. Positional Encoding
class PositionalEncoding(nn.Module):
def __init__(self, embed_size, max_len=100):
super().__init__()
pe = torch.zeros(max_len, embed_size)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-math.log(10000.0) / embed_size)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1)]
---
Data Science Machine Learning Data Analysis
Photo
## 🔹 Practical Sequence Modeling Tasks
### 1. Text Classification Pipeline
### 2. Sequence-to-Sequence (Seq2Seq) Model
---
## 🔹 Best Practices for Sequence Modeling
1. Always use packed sequences for variable-length inputs
2. Gradient clipping is essential for RNNs/LSTMs (1-5 norm)
3. Teacher forcing helps seq2seq models converge faster
4. Bidirectional RNNs significantly improve performance
5. Layer normalization stabilizes transformer training
6. Warmup learning rate for transformer models
### 1. Text Classification Pipeline
from torchtext.legacy import data
# Define fields
TEXT = data.Field(tokenize='spacy', lower=True, include_lengths=True)
LABEL = data.LabelField(dtype=torch.float)
# Load dataset (e.g., IMDB)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
# Build vocabulary
TEXT.build_vocab(train_data, max_size=25000,
vectors="glove.6B.100d", unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
# Create iterators
train_loader, test_loader = data.BucketIterator.splits(
(train_data, test_data),
batch_size=64,
sort_within_batch=True,
sort_key=lambda x: len(x.text),
device=device
)
# Model definition
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim, n_layers):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.LSTM(embed_dim, hidden_dim, n_layers,
bidirectional=True, dropout=0.5)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
self.dropout = nn.Dropout(0.5)
def forward(self, text, text_lengths):
embedded = self.dropout(self.embedding(text))
packed_embedded = nn.utils.rnn.pack_padded_sequence(
embedded, text_lengths.cpu(), batch_first=False, enforce_sorted=False
)
packed_output, (hidden, cell) = self.rnn(packed_embedded)
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1))
return self.fc(hidden)
### 2. Sequence-to-Sequence (Seq2Seq) Model
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cell
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout)
self.fc = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc(output.squeeze(0))
return prediction, hidden, cell
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
trg_len = trg.shape[0]
batch_size = trg.shape[1]
trg_vocab_size = self.decoder.fc.out_features
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
hidden, cell = self.encoder(src)
input = trg[0,:]
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputs
---
## 🔹 Best Practices for Sequence Modeling
1. Always use packed sequences for variable-length inputs
2. Gradient clipping is essential for RNNs/LSTMs (1-5 norm)
3. Teacher forcing helps seq2seq models converge faster
4. Bidirectional RNNs significantly improve performance
5. Layer normalization stabilizes transformer training
6. Warmup learning rate for transformer models
❤1
Data Science Machine Learning Data Analysis
Photo
# Learning rate scheduler for transformers
def lr_schedule(step, d_model=512, warmup_steps=4000):
arg1 = step ** -0.5
arg2 = step * (warmup_steps ** -1.5)
return (d_model ** -0.5) * min(step ** -0.5, step * warmup_steps ** -1.5)
---
### **📌 What's Next?
In **Part 5, we'll cover:
➡️ Generative Models (GANs, VAEs)
➡️ Reinforcement Learning with PyTorch
➡️ Model Optimization & Deployment
➡️ PyTorch Lightning Best Practices
#PyTorch #DeepLearning #NLP #Transformers 🚀
Practice Exercises:
1. Implement a character-level language model with LSTM
2. Add attention visualization to a sentiment analysis model
3. Build a transformer from scratch for machine translation
4. Compare teacher forcing ratios in seq2seq training
5. Implement beam search for decoder inference
# Character-level LSTM starter
class CharLSTM(nn.Module):
def __init__(self, vocab_size, hidden_size, n_layers):
super().__init__()
self.embed = nn.Embedding(vocab_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size, n_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden=None):
x = self.embed(x)
out, hidden = self.lstm(x, hidden)
return self.fc(out), hidden
{kind=link}
🔥2❤1
Data Science Machine Learning Data Analysis
Photo
# 📚 PyTorch Tutorial for Beginners - Part 5/6: Generative Models & Advanced Topics
#PyTorch #DeepLearning #GANs #VAEs #ReinforcementLearning #Deployment
Welcome to Part 5 of our PyTorch series! This comprehensive lesson explores generative modeling, reinforcement learning, model optimization, and deployment strategies with practical implementations.
---
## 🔹 Generative Adversarial Networks (GANs)
### 1. GAN Core Concepts

Key Components:
- Generator: Creates fake samples from noise (typically a transposed CNN)
- Discriminator: Distinguishes real vs. fake samples (CNN classifier)
- Adversarial Training: The two networks compete in a minimax game
### 2. DCGAN Implementation
### 3. GAN Training Loop
#PyTorch #DeepLearning #GANs #VAEs #ReinforcementLearning #Deployment
Welcome to Part 5 of our PyTorch series! This comprehensive lesson explores generative modeling, reinforcement learning, model optimization, and deployment strategies with practical implementations.
---
## 🔹 Generative Adversarial Networks (GANs)
### 1. GAN Core Concepts

Key Components:
- Generator: Creates fake samples from noise (typically a transposed CNN)
- Discriminator: Distinguishes real vs. fake samples (CNN classifier)
- Adversarial Training: The two networks compete in a minimax game
### 2. DCGAN Implementation
class Generator(nn.Module):
def __init__(self, latent_dim, img_channels, features_g):
super().__init__()
self.net = nn.Sequential(
# Input: N x latent_dim x 1 x 1
nn.ConvTranspose2d(latent_dim, features_g*8, 4, 1, 0, bias=False),
nn.BatchNorm2d(features_g*8),
nn.ReLU(),
# 4x4
nn.ConvTranspose2d(features_g*8, features_g*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(features_g*4),
nn.ReLU(),
# 8x8
nn.ConvTranspose2d(features_g*4, features_g*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(features_g*2),
nn.ReLU(),
# 16x16
nn.ConvTranspose2d(features_g*2, img_channels, 4, 2, 1, bias=False),
nn.Tanh()
# 32x32
)
def forward(self, x):
return self.net(x)
class Discriminator(nn.Module):
def __init__(self, img_channels, features_d):
super().__init__()
self.net = nn.Sequential(
# Input: N x img_channels x 32 x 32
nn.Conv2d(img_channels, features_d, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2),
# 16x16
nn.Conv2d(features_d, features_d*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(features_d*2),
nn.LeakyReLU(0.2),
# 8x8
nn.Conv2d(features_d*2, features_d*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(features_d*4),
nn.LeakyReLU(0.2),
# 4x4
nn.Conv2d(features_d*4, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
return self.net(x)
# Initialize
gen = Generator(latent_dim=100, img_channels=3, features_g=64).to(device)
disc = Discriminator(img_channels=3, features_d=64).to(device)
# Loss and optimizers
criterion = nn.BCELoss()
opt_gen = optim.Adam(gen.parameters(), lr=0.0002, betas=(0.5, 0.999))
opt_disc = optim.Adam(disc.parameters(), lr=0.0002, betas=(0.5, 0.999))
### 3. GAN Training Loop
def train_gan(gen, disc, loader, num_epochs):
fixed_noise = torch.randn(32, 100, 1, 1).to(device)
for epoch in range(num_epochs):
for batch_idx, (real, _) in enumerate(loader):
real = real.to(device)
noise = torch.randn(real.size(0), 100, 1, 1).to(device)
fake = gen(noise)
# Train Discriminator
disc_real = disc(real).view(-1)
loss_disc_real = criterion(disc_real, torch.ones_like(disc_real))
disc_fake = disc(fake.detach()).view(-1)
loss_disc_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
loss_disc = (loss_disc_real + loss_disc_fake) / 2
disc.zero_grad()
loss_disc.backward()
opt_disc.step()
# Train Generator
output = disc(fake).view(-1)
loss_gen = criterion(output, torch.ones_like(output))
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
# Visualization
with torch.no_grad():
fake = gen(fixed_noise)
save_image(fake, f"gan_samples/epoch_{epoch}.png", normalize=True)
❤1
Data Science Machine Learning Data Analysis
Photo
### 4. GAN Training Challenges & Solutions
| Problem | Solution | Implementation Tips |
|-----------------------|-----------------------------------|---------------------------------------|
| Mode Collapse | Mini-batch discrimination | Use
| Vanishing Gradients | Wasserstein GAN with GP | Clip critic weights or use gradient penalty |
| Unstable Training | Two Time-Scale Update Rule (TTUR) | Different learning rates for G/D |
| Poor Image Quality | Spectral Normalization |
---
## 🔹 Variational Autoencoders (VAEs)
### 1. VAE Core Concepts

Key Components:
- Encoder: Maps input to latent space distribution parameters (μ, σ)
- Reparameterization Trick: Allows backpropagation through sampling
- Decoder: Reconstructs input from latent samples
### 2. VAE Implementation
### 3. Conditional VAE (CVAE)
---
| Problem | Solution | Implementation Tips |
|-----------------------|-----------------------------------|---------------------------------------|
| Mode Collapse | Mini-batch discrimination | Use
torch.cat for batch statistics || Vanishing Gradients | Wasserstein GAN with GP | Clip critic weights or use gradient penalty |
| Unstable Training | Two Time-Scale Update Rule (TTUR) | Different learning rates for G/D |
| Poor Image Quality | Spectral Normalization |
torch.nn.utils.spectral_norm layers |---
## 🔹 Variational Autoencoders (VAEs)
### 1. VAE Core Concepts

Key Components:
- Encoder: Maps input to latent space distribution parameters (μ, σ)
- Reparameterization Trick: Allows backpropagation through sampling
- Decoder: Reconstructs input from latent samples
### 2. VAE Implementation
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super().__init__()
# Encoder
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU()
)
# Latent space parameters
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_var = nn.Linear(hidden_dim, latent_dim)
# Decoder
self.decoder = nn.Sequential(
nn.Linear(latent_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_var(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# Loss function
def vae_loss(recon_x, x, mu, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
### 3. Conditional VAE (CVAE)
class CVAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim, num_classes):
super().__init__()
self.label_emb = nn.Embedding(num_classes, num_classes)
# Encoder now takes both image and label
self.encoder = nn.Sequential(
nn.Linear(input_dim + num_classes, hidden_dim),
nn.ReLU()
)
# Rest remains similar to VAE...
---
Data Science Machine Learning Data Analysis
Photo
## 🔹 Reinforcement Learning with PyTorch
### 1. Deep Q-Network (DQN)
### 2. Policy Gradient Methods
---
## 🔹 Model Optimization & Deployment
### 1. Quantization
### 1. Deep Q-Network (DQN)
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, output_dim)
)
def forward(self, x):
return self.fc(x)
# Experience Replay
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)
# Training loop
def train_dqn(env, model, target_model, optimizer, buffer,
batch_size=64, gamma=0.99):
if len(buffer) < batch_size:
return
transitions = buffer.sample(batch_size)
batch = list(zip(*transitions))
states = torch.FloatTensor(np.array(batch[0])).to(device)
actions = torch.LongTensor(batch[1]).unsqueeze(1).to(device)
rewards = torch.FloatTensor(batch[2]).unsqueeze(1).to(device)
next_states = torch.FloatTensor(np.array(batch[3])).to(device)
dones = torch.FloatTensor(batch[4]).unsqueeze(1).to(device)
current_q = model(states).gather(1, actions)
next_q = target_model(next_states).max(1)[0].detach().unsqueeze(1)
target_q = rewards + (gamma * next_q * (1 - dones))
loss = nn.functional.mse_loss(current_q, target_q)
optimizer.zero_grad()
loss.backward()
optimizer.step()
### 2. Policy Gradient Methods
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, output_dim),
nn.Softmax(dim=-1)
)
def forward(self, x):
return self.fc(x)
def train_policy_gradient(env, model, optimizer, num_episodes):
for episode in range(num_episodes):
state = env.reset()
log_probs = []
rewards = []
while True:
state = torch.FloatTensor(state).unsqueeze(0).to(device)
probs = model(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
next_state, reward, done, _ = env.step(action.item())
log_probs.append(action_dist.log_prob(action))
rewards.append(reward)
state = next_state
if done:
break
# Calculate discounted rewards
discounted_rewards = []
R = 0
for r in reversed(rewards):
R = r + gamma * R
discounted_rewards.insert(0, R)
# Normalize rewards
discounted_rewards = torch.FloatTensor(discounted_rewards).to(device)
discounted_rewards = (discounted_rewards - discounted_rewards.mean()) / \
(discounted_rewards.std() + 1e-9)
# Calculate loss
policy_loss = []
for log_prob, reward in zip(log_probs, discounted_rewards):
policy_loss.append(-log_prob * reward)
optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
optimizer.step()
---
## 🔹 Model Optimization & Deployment
### 1. Quantization
# Dynamic quantization
model = nn.Sequential(
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
# Post-training static quantization
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)
# Calibrate with sample data
torch.quantization.convert(model, inplace=True)
❤1
Data Science Machine Learning Data Analysis
Photo
### 2. Pruning
### 3. ONNX Export
### 4. TorchScript
---
## 🔹 PyTorch Lightning Best Practices
### 1. LightningModule Structure
### 2. Advanced Lightning Features
---
## 🔹 Best Practices Summary
1. For GANs: Use spectral norm, progressive growing, and TTUR
2. For VAEs: Monitor both reconstruction and KL divergence terms
3. For RL: Properly normalize rewards and use experience replay
4. For Deployment: Quantize, prune, and export to optimized formats
5. For Maintenance: Use PyTorch Lightning for reproducible experiments
---
### 📌 What's Next?
In Part 6 (Final), we'll cover:
➡️ Advanced Architectures (Graph NNs, Neural ODEs)
➡️ Model Interpretation Techniques
➡️ Production Deployment (TorchServe, Flask API)
➡️ PyTorch Ecosystem (TorchVision, TorchText, TorchAudio)
#PyTorch #DeepLearning #GANs #ReinforcementLearning 🚀
Practice Exercises:
1. Implement WGAN-GP with gradient penalty
2. Train a VAE on MNIST and visualize latent space
3. Build a DQN agent for CartPole environment
4. Quantize a pretrained ResNet and compare accuracy/speed
5. Convert a model to TorchScript and serve with Flask
parameters_to_prune = (
(model.conv1, 'weight'),
(model.fc1, 'weight'),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.2
)
# Remove pruning reparameterization
for module, param in parameters_to_prune:
prune.remove(module, param)
### 3. ONNX Export
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(
model,
dummy_input,
"model.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={
"input": {0: "batch_size"},
"output": {0: "batch_size"}
}
)
### 4. TorchScript
# Tracing
example_input = torch.rand(1, 3, 224, 224)
traced_script = torch.jit.trace(model, example_input)
traced_script.save("traced_model.pt")
# Scripting
scripted_model = torch.jit.script(model)
scripted_model.save("scripted_model.pt")
---
## 🔹 PyTorch Lightning Best Practices
### 1. LightningModule Structure
import pytorch_lightning as pl
class LitModel(pl.LightningModule):
def __init__(self, learning_rate=1e-3):
super().__init__()
self.save_hyperparameters()
self.model = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = nn.functional.cross_entropy(y_hat, y)
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = nn.functional.cross_entropy(y_hat, y)
self.log('val_loss', loss)
def configure_optimizers(self):
return optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
# Training
trainer = pl.Trainer(gpus=1, max_epochs=10)
model = LitModel()
trainer.fit(model, train_loader, val_loader)
### 2. Advanced Lightning Features
# Mixed Precision
trainer = pl.Trainer(precision=16)
# Distributed Training
trainer = pl.Trainer(gpus=2, accelerator='ddp')
# Callbacks
early_stop = pl.callbacks.EarlyStopping(monitor='val_loss')
checkpoint = pl.callbacks.ModelCheckpoint(monitor='val_loss')
trainer = pl.Trainer(callbacks=[early_stop, checkpoint])
# Logging
trainer = pl.Trainer(logger=pl.loggers.TensorBoardLogger('logs/'))
---
## 🔹 Best Practices Summary
1. For GANs: Use spectral norm, progressive growing, and TTUR
2. For VAEs: Monitor both reconstruction and KL divergence terms
3. For RL: Properly normalize rewards and use experience replay
4. For Deployment: Quantize, prune, and export to optimized formats
5. For Maintenance: Use PyTorch Lightning for reproducible experiments
---
### 📌 What's Next?
In Part 6 (Final), we'll cover:
➡️ Advanced Architectures (Graph NNs, Neural ODEs)
➡️ Model Interpretation Techniques
➡️ Production Deployment (TorchServe, Flask API)
➡️ PyTorch Ecosystem (TorchVision, TorchText, TorchAudio)
#PyTorch #DeepLearning #GANs #ReinforcementLearning 🚀
Practice Exercises:
1. Implement WGAN-GP with gradient penalty
2. Train a VAE on MNIST and visualize latent space
3. Build a DQN agent for CartPole environment
4. Quantize a pretrained ResNet and compare accuracy/speed
5. Convert a model to TorchScript and serve with Flask
# WGAN-GP Gradient Penalty
def compute_gradient_penalty(D, real_samples, fake_samples):
alpha = torch.rand(real_samples.size(0), 1, 1, 1).to(device)
interpolates = (alpha * real_samples + (1 - alpha) * fake_samples).requires_grad_(True)
d_interpolates = D(interpolates)
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=torch.ones_like(d_interpolates),
create_graph=True,
retain_graph=True,
only_inputs=True
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
MATLAB Tutorial for Computer Vision - Part 1/4 (Beginner's Guide)
This is the first part of a comprehensive 4-part tutorial series on using MATLAB for computer vision. Designed for absolute beginners, this tutorial will cover the fundamentals with practical examples.
Table of Contents:
1. Introduction to MATLAB for Computer Vision
2. Basic Image Operations
3. Image Visualization Techniques
4. Color Space Conversions
5. Basic Image Processing
6. Conclusion & Next Steps
let's start: https://codeprogrammer.notion.site/MATLAB-Tutorial-for-Computer-Vision-Part-1-4-Beginner-s-Guide-23bcd3a4dba9803b81bded6c392b5e04
This is the first part of a comprehensive 4-part tutorial series on using MATLAB for computer vision. Designed for absolute beginners, this tutorial will cover the fundamentals with practical examples.
Table of Contents:
1. Introduction to MATLAB for Computer Vision
2. Basic Image Operations
3. Image Visualization Techniques
4. Color Space Conversions
5. Basic Image Processing
6. Conclusion & Next Steps
let's start: https://codeprogrammer.notion.site/MATLAB-Tutorial-for-Computer-Vision-Part-1-4-Beginner-s-Guide-23bcd3a4dba9803b81bded6c392b5e04
✉️ Our Telegram channels: https://t.iss.one/addlist/0f6vfFbEMdAwODBk📱 Our WhatsApp channel: https://whatsapp.com/channel/0029VaC7Weq29753hpcggW2A
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3👍1🔥1
MATLAB Computer Vision Tutorial - Part 2/4 (Intermediate Techniques)
Table of Contents:
1. Image Filtering and Enhancement
2. Morphological Operations
3. Feature Detection
4. Basic Object Recognition
5. Next Steps
Let's start:
https://codeprogrammer.notion.site/MATLAB-Computer-Vision-Tutorial-Part-2-4-Intermediate-Techniques-23bcd3a4dba980eb8813ec3c8c3322ef
Table of Contents:
1. Image Filtering and Enhancement
2. Morphological Operations
3. Feature Detection
4. Basic Object Recognition
5. Next Steps
Let's start:
https://codeprogrammer.notion.site/MATLAB-Computer-Vision-Tutorial-Part-2-4-Intermediate-Techniques-23bcd3a4dba980eb8813ec3c8c3322ef
✉️ Our Telegram channels: https://t.iss.one/addlist/0f6vfFbEMdAwODBk📱 Our WhatsApp channel: https://whatsapp.com/channel/0029VaC7Weq29753hpcggW2A
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥3👍2❤1
MATLAB Computer Vision Mastery - Part 3/4 (Advanced Techniques with Comprehensive Exercises)
Table of Contents:
1. Geometric Transformations & Image Warping
2. Advanced Image Registration
3. Hough Transform & Shape Detection
4. Feature Extraction & Matching
5. Practical Exercises & Projects
6. Performance Optimization
7. Next Steps & Roadmap
Let's start: https://codeprogrammer.notion.site/MATLAB-Computer-Vision-Mastery-Part-3-4-Advanced-Techniques-with-Comprehensive-Exercises-23bcd3a4dba98017b0b4ea2e2e8da8f5
Table of Contents:
1. Geometric Transformations & Image Warping
2. Advanced Image Registration
3. Hough Transform & Shape Detection
4. Feature Extraction & Matching
5. Practical Exercises & Projects
6. Performance Optimization
7. Next Steps & Roadmap
Let's start: https://codeprogrammer.notion.site/MATLAB-Computer-Vision-Mastery-Part-3-4-Advanced-Techniques-with-Comprehensive-Exercises-23bcd3a4dba98017b0b4ea2e2e8da8f5
✉️ Our Telegram channels: https://t.iss.one/addlist/0f6vfFbEMdAwODBk📱 Our WhatsApp channel: https://whatsapp.com/channel/0029VaC7Weq29753hpcggW2A
Please open Telegram to view this post
VIEW IN TELEGRAM
1❤4👍3🔥2